

8. Охарактерізуваті архітектуру numa.
Для вирішення проблем, що виникають в симетричних багатопроцесорних системах, було вирішено пожертвувати однорідністю і організувати неоднорідний доступ до пам'яті (Non-Unifom Memory Access, NUMA) при збереженні єдиного для всіх процесорів адресного простору.
С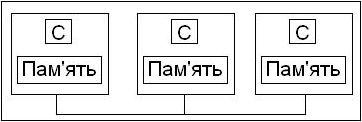 истема
состоит из однородных базовых модулей
(плат), состоящих из небольшого числа
процессоров. C каждым модулем обычно
связан один или несколько блоков памяти.
Модули объединены с помощью высокоскоростного
коммутатора. Поддерживается единое
адресное пространство для всех модулей.
Аппаратно поддерживается доступ к
удаленной памяти, т. е. к блокам памяти
приписанным другим модулям. Скорость
доступа из модуля к блокам памяти
приписанным данному модулю в несколько
раз быстрее, чем к остальным блокам
памяти.
истема
состоит из однородных базовых модулей
(плат), состоящих из небольшого числа
процессоров. C каждым модулем обычно
связан один или несколько блоков памяти.
Модули объединены с помощью высокоскоростного
коммутатора. Поддерживается единое
адресное пространство для всех модулей.
Аппаратно поддерживается доступ к
удаленной памяти, т. е. к блокам памяти
приписанным другим модулям. Скорость
доступа из модуля к блокам памяти
приписанным данному модулю в несколько
раз быстрее, чем к остальным блокам
памяти.
У випадку, якщо апаратний підтримується когерентність кешів у всій системі (звичайно це так), говорять про архітектуру cc-NUMA (cache-coherent NUMA).
Масштабованість NUMA-систем обмежується об'ємом адресного простору, можливостями апаратури піддіжі когерентності кешів і можливостями операційної системи по управлінню великим числом процесорів. На справжній момент, максимальне число процесорів в NUMA-системах складає 256 (Origin2000). Іншим представником даного класу багатопроцесорних систем є IBM pSeries 690.
9. Охарактеризувати кластерні системи.
Кластер — зв'язаний набір повноцінних комп'ютерів, використовуваний як єдиний обчислювальний ресурс.
З точки зору простоти збірки і простоти використання кластер володіє великим числом переваг перед MPP системами.
Кластер також легко масштабований по числу процесорних вузлів як і MPP системи. (За винятком проблем пов'язаних з об'ємом енергії, що виділяється і споживаної.)
Для управління кластером не потрібно ставити спеціальну операційну систему.
Комунікаційне середовище зазвичай реалізоване поверх відомих і достатньо популярних мережевих технологій.
Для створення кластерів зазвичай використовуються як «прості» однопроцесорні персональні комп'ютери, так і багатопроцесорні сервери SMP(NUMA). При цьому не накладаються ніяких обмежень на склад і архітектуру вузлів. Кожен з вузлів функціонує під управлінням своєї власної операційної системи. Найчастіше використовуються распростаненные ОС: Linux, FREEBSD, Solaris, AIX, Windows NT.
Види кластерів:
Гетерогенні (різне АЗ а іноді і ПЗ)
Гомогенні (однакове Пз та АЗ)
Мережеві технології для кластера:
Gigabit Ethernet.
Технології, розроблені спеціально для кластера: SCI фірми Scali Computer (~100 MB/s) і Mirynet (~120 MB/ s); (SUN, HP, Silicon Graphics).
Як правило програмування для подібних систем, здійснюється в рамках моделі передачі повідомлень. Як реалізація моделі передачі повідомлень використовується одна з доступних реалізацій MPI. Наприклад: OPENMPI, mpich, INTEL-MPI, Scali MPI, рої для устаткування від IBM.
Переваги:
Можуть бути утворені на базі окремих комп'ютерів, що вже існують у споживачів, або ж сконструйовані з типових комп'ютерних елементів;
Підвищення обчислювальної потужності окремих процесорів дозволяє будувати кластери з порівняно невеликої кількості окремих комп'ютерів (lowly parallel processing)
Для паралельного виконання в алгоритмах досить виділяти тільки крупні незалежні частини розрахунків (coarse granularity).
Недоліки:
Організація взаємодії обчислювальних вузлів кластера за допомогою передачі повідомлень зазвичай приводить до значних тимчасових затримок
Додаткові обмеження на тип паралельних алгоритмів, що розробляються, і програм (низька інтенсивність потоків передачі даних)