

Операции ввода/вывода
На рис. 4.14 представлена схема выполнения операций ввода/вывода с пользованием буферного кэша. Важной особенностью этой подсистемы является то, что она обеспечивает независимое выполнение операций чтения или записи данных процессом как результат соответствующие системных вызовов, а также фактический обмен данными с периферийным устройством.
Когда процессу требуется прочитать или записать данные он использует системные вызовы read(2) или write(2), направляя тем самым запрос файловой подсистеме. В свою очередь файловая подсистема транслирует этот запрос в запрос на чтение или запись соответствующих дисковых блоков файла и направляет его в буферный кэш. Прежде всего кэш просматривается предмет наличия требуемого блока в памяти. Если соответствующий буфер найден, его содержимое копируется в адресное пространство процесса в случае чтения и наоборот при записи, и операция завершается. Если блок в кэше не найден, ядро размещает буфер, связывает его с дисковым блоком с помощью заголовка buf и направляет запрос на чтение драйверу устройства. Обычно используется схема чтения вперед (read-ahead), когда считываются не только запрашиваемые блоки, но и блоки, которые с высокой вероятностью могут потребоваться в ближайшее время (рис. 4.14, а). Таким образом, последующие вызовы read(2) скорее всего не потребуют дискового ввода/вывода, а будут включать лишь копирование данных из буферов в память процесса, — операция, которая, как отмечалось, обладает на несколько порядков большей производительностью (рис. 4.14, б—в). При запросе на модификацию блока изменения также затрагивают только буфер кэша. При этом ядро помечает буфер как "грязный" в заголовке buf (рис. 4.14, г). Перед освобождением такого буфера для повторного использования, содержимое должно быть предварительно сохранено на диске (рис. 4.14, д).
Перед фактическим использованием буфера, например при чтении или записи буфера процессом, или при операции дискового ввода/вывода, доступ к нему для других процессов должен быть заблокирован. При обращении к уже заблокированному буферу процесс переходит в состояние сна, пока данный ресурс не станет доступным.
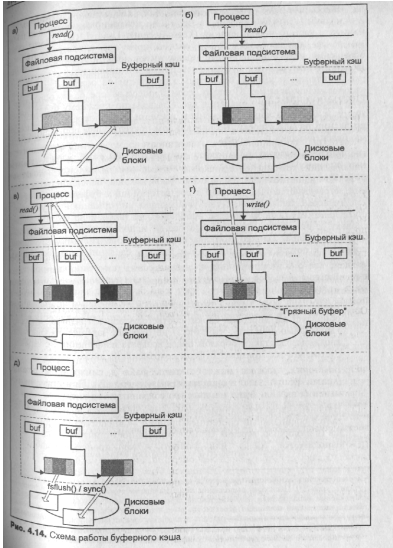
Не заблокированные буферы помечаются как свободные и помещаются в специальный список. Буферы в этом списке располагаются в порядке наименее частого использования (Least Recently Used, LRU). Таким образом, когда ядру необходим буфер, оно выбирает тот, к которому не было обращений в течение наиболее продолжительного промежутка времени. После того как работа с буфером завершена, он помещается в конец списка и является наименее вероятным кандидатом на освобождение и повторное использование. Поэтому, если процесс вскоре опять обратится к тому же блоку данных, операция ввода/вывода по-прежнему будет происходить с буфером кэша. С течением времени буфер перемещается в направлении начала очереди, но при каждом последующем обращении к нему, будет помещен в ее конец.
Основной проблемой, связанной с буферным кэшем, является «старение» информации, хранящейся в дисковых блоках, образы которых находятся в буферном кэше. Как следует из схемы работы кэша, большинство изменений затрагивают только данные в соответствующих буферах, в то время как дисковые блоки хранят уже устаревшую информацию. Разумеется в нормально работающей системе проблемы как таковой не возникает, поскольку в операциях ввода/вывода всегда используются свежие данные буферного кэша. Однако при аварийном останове системы, это может привести к потере изменений данных файлов, сделанных процессами непосредственно перед остановом.
Для уменьшения вероятности таких потерь в UNIX имеется несколько возможностей:
Во-первых, может использоваться системный вызов sync(2), который обновляет все дисковые блоки, соответствующие "грязным" буфера. Необходимо отметить, что sync(2) не ожидает завершения операции ввода/вывода, таким образом после возврата из функции не гарантируется, что все "грязные" буферы сохранены на диске3.
Во-вторых, процесс может открыть файл в синхронном режиме (указав флаг О_SYNC в системном вызове ореn(2)). При этом все изменения в файле будут немедленно сохраняться на диске.
Наконец, через регулярные промежутки времени в системе пробуждается специальный системный процесс — диспетчер буферного кэша (в различных версиях UNIX его названия отличаются, чаще используется fsflush или bdflush). Этот процесс освобождает "грязные" буферы, сохраняя их содержимое в соответствующих дисковых блоках4 (рис. 4.14, д).
В распоряжении администратора имеется командный интерфейс к системному вызову – утилита sync(lM). Поскольку выполнение команды еще не свидетельствует о фактическом завершении ввода/вывода, администраторы практикуют вызов sync(lM) несколько раз. Повторные вызовы повышают вероятность того, что ввод/вывод будет завершен прежде, чем будет введена другая команда или остановлена система, поскольку набор команды занимает определенное время. Тот же эффект может быть достигнут просто ожидая скольких секунд после ввода sync(lM), но набор команды позволяет «скрасить ожидание».
Работа диспетчера буферного кэша зависит от версии UNIX и конкретных настроек ядра системы. Например, в SCO UNIX для этого используются несколько параметров. Параметр BDFLUSHR задает интервал между последовательными пробуждениями bdflush, его значение по умолчанию составляет 30 секунд. Параметр NAUTOUP задает промежуток времени, который буфер должен оставаться "грязным", прежде чем bdflush сохранит его на диске.
Кэширование в SVR4
Центральной концепцией в архитектуре виртуальной памяти SVR4 является изображение файлов. При этом подходе все адресное пространство может 6ьггь представлено набором отображений различных файлов в память. Действительно, в страницы памяти, содержащие кодовые сегменты, отображаются соответствующие секции исполняемых файлов. Процесс может задать отображение с помощью системного вызова mmap(2), при этом страницам памяти будут соответствовать определенные участки отображаемого файла. Даже области памяти, содержимое которых изменяется и не связано ни с каким файлом файловой системы, т. н. анонимные страницы, можно отобразить на определенные участки специального файла устройства, отвечающего за область свопинга (именно там сохраняются анонимные объекты памяти). При этом фактический обмен данными между памятью и устройствами их хранения, инициируется возникновением страничной ошибки. Такая архитектура позволяет унифицировать операции ввода/вывода практически для всех случаев.
При этом подходе, когда процесс выполняет вызовы read(2) или write(2), ядро устанавливает отображение части файла, адресованного этими вызовами, в собственное адресное пространство. Затем эта область копируется в адресное пространство процесса. При копировании возникают страничные ошибки, приводящие в фактическому считыванию дисковых блоков файла в память. Поскольку все операции кэширования данных в этом случае обслуживаются подсистемой управления памятью, необходимость в буферном кэше, как отдельной подсистеме, отпадает.
Целостность файловой системы
Значительная часть файловой системы находится в оперативной памяти. А именно, в оперативной памяти расположены суперблок примонтированной системы, метаданные активных файлов (в виде системно-зависимых inode и соответствующих им vnode) и даже отдельные блоки хранения данных файлов, временно находящиеся в буферном кэше.
Для операционной системы рассогласование между буферным кэшем и блоками хранения данных отдельных файлов, не приведет к катастрофическим последствиям даже в случае внезапного останова системы, хотя с точки зрения пользователя все может выглядеть иначе. Содержимое отдельных файлов не вносит существенных нарушений в целостность файловой системы.
Другое дело, когда подобные несоответствия затрагивают метаданные файла или другую управляющую информацию файловой системы, например, суперблок. Многие файловые операции затрагивают сразу несколько объектов файловой системы, и если на диске будут сохранены изменения только для части этих объектов, целостность файловой систем может быть существенно нарушена.
Рассмотрим пример создания жесткой связи для файла. Для этого файловой подсистеме необходимо выполнить следующие операции:
Создать новую запись в необходимом каталоге, указывающую на inode файла.
Увеличить счетчик связей в inode.
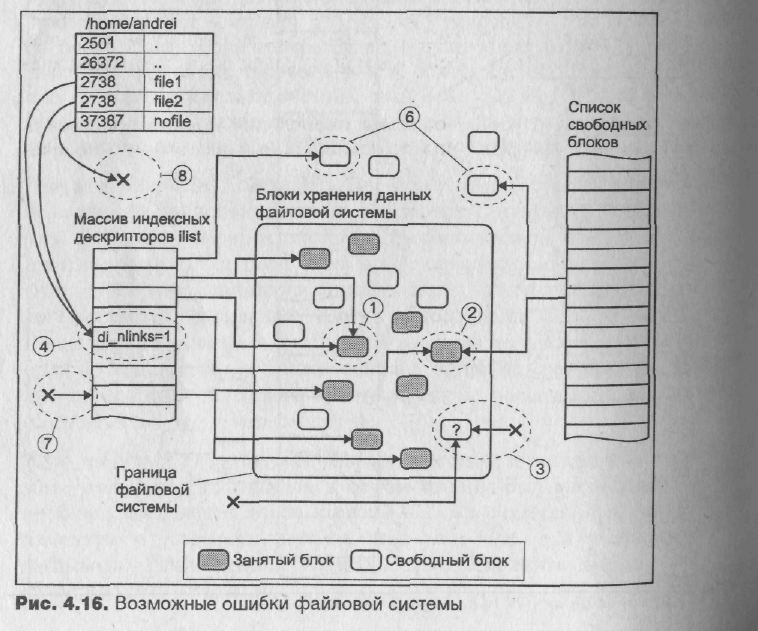
Предположим, что аварийный останов системы произошел между первой и второй операциями. В этом случае после запуска в файловой системе будут существовать два имени файла (две записи каталогов), адресующие inode со счетчиком связей di_nlinks, равным 1. Эта ситуация показам на рис. 4.15 (а). Если теперь будет удалено одно из имен, это приведет удалению файла как такового, т. е. к освобождению блоков хранения данных и inode, поскольку счетчик связей di_nlinks станет равным 0. Оставшаяся запись каталога будет указывать на неразмещенный индексный дескриптор, или inode, адресующий уже другой файл (рис. 4.15, б).
Порядок операций с метаданными может иметь существенное влияние на целостность файловой системы. Рассмотрим, например, предыдущий пример. Допустим, порядок операций был изменен и, как и прежде, останов произошел между первой и второй операциями. После запуска файл будет иметь лишнюю жесткую связь, но существующая запись каталога останется правильной. Тем не менее при удалении имени файла фактически файл удален не будет, поскольку число связей останется равным 1 (рис. 4.15, в). Хотя это также является ошибкой, результатом которой является засорение дискового пространства, ее последствия все же менее катастрофичны, чем в первом случае.
Ядро выбирает порядок совершения операций с метаданными таким образом, чтобы вред от ошибок в случае аварии был минимальным. Однако проблема нарушения этого порядка все же остается, т. к. изменять очередность выполнения запросов для оптимизации ввода/вывода. Единственной возможностью сохранить выбранный порядок является синхронизация операций со стороны файловой подсистемы.
В нашем примере файловая подсистема будет ожидать, пока на диск будет записаано содержимое индексного дескриптора, и только после этого произведет изменения каталога.

Отсутствие синхронизации между образом файловой системы в памяти и ее данными на диске в случае аварийного останова может привести к появлению следующих ошибок:
Один блок адресуется несколькими inode (принадлежит нескольким файлам).
Блок помечен как свободный, но в то же время занят (на него ссылается inode).
Блок помечен как занятый, но в то же время свободен (ни один inode на него не ссылается).
Неправильное число ссылок в inode (недостаток или избыток ссылающихся записей в каталогах).
Несовпадение между размером файла и суммарным размером адресуемых inode блоков.
Недопустимые адресуемые блоки (например, расположенные за пределами файловой системы).
"Потерянные" файлы (правильные inode, на которые не ссылаются записи каталогов).
Недопустимые или неразмещенные номера inode в записях каталогов.
Эти ошибки схематически показаны на рис. 4.16.
Если нарушение все же произошло, на помощь может прийти утилита fsck(1M), производящая исправление файловой системы. Запуск этой утилиты может производиться автоматически каждый раз при запуске системы, или администратором, с помощью команды:
fsck [options] filesystem
где filesystem — специальный файл устройства, на котором находится файловая система.
Проверка и исправление должны производиться только на размонтированной файловой системе. Это связано с необходимостью исключения синхронизации таблиц в памяти (ошибочных) с их дисковыми эквивалентами (исправленными). Исключение составляет корневая файловая система, которая не может быть размонтирована. Для ее исправления необходимо использовать опцию -b, обеспечивающую немедленный перезапуск системы после проведения проверки.