

Трансляция имен
Прикладные процессы, запрашивая услуги файловой системы, обычно имеют дело с именем файла или файловым дескриптором, полученным в результате определенных системных вызовов. Однако ядро системы для обеспечения работы с файлами использует не имена, а индексные дескрипторы. Таким образом, необходима трансляция имени файла, передаваемого, например, в качестве аргумента системному вызову ореп(2), в номер соответствующего vnode.
В табл. 4.6 приведены системные вызовы, для выполнения которых требуется трансляция имени файла.

Говоря формально, полное имя файла представляет собой последовательность слов, разделенных символом '/'. Каждый компонент имени, кроме собственного является именем каталога. Последний компонент определяет собственное имя файла. При этом полное имя может быть абсолютным или относительным. Если полное имя начинается с символа '/', представляющего корневой каталог общего логического дерева файловой системы, то оно является абсолютным, однозначно определяющим файл из любого места файловой системы. В противном случае, имя является относительным и адресует файл относительно текущего каталога. Примером относительного имени может служить include/sys/user.h, а абсолютное имя этого файла – /usr/include/sys/user.h. Как следует из этих рассуждений, два каталога играют ключевую роль при трансляции имени: корневой каталог и текущий каталог. Каждый процесс адресует эти каталоги двумя полями структуры u_area:
struct vnode *u_cdir Указатель на vnode текущего каталога
struct vnode *u_rdir Указатель на vnode корневого каталога
В зависимости от имени файла трансляция начинается с vnode, адресованного либо полем u_cdir, либо u_rdir. Трансляция имени осуществляется покомпонентно, при этом для vnode текущего каталога вызываете соответствующая ему операция vn_lookup(), в качестве аргумента которой передается имя следующего компонента. В результате операции возвращается vnode, соответствующий искомому компоненту.
Если для vnode каталога установлен указатель vn_vfsmountedhere, то данный каталог является точкой монтирования. Если имя файла требует дальнейшего спуска по дереву файловой системы (т. е. пересечения точки монтирования), то операция vn_lookup() следует указателю vn_vfsmountedhere для перехода в подключенную файловую систем и вызывает для нее операцию vfs_root() для получения ее корневого vnode. Трансляция имени затем продолжается с этого места.
Пересечение границы файловых систем возможно и при восхождении по дереву, например, если имя файла задано указанием родительского каталога – ../../myfile.txt. Если при движении в этом направлении по пути встречается корневой vnode подключенной файловой системы (установлен флаг VROOT в поле v_flag), то операция vn_lookup() следует указателю vfs_vnodecovered, расположенному в записи vfs этой файловой системы. При этом происходит пересечение границы файловых систем, и дальнейшая трансляция продолжается с точки монтирования.
Если искомый файл является символической связью, и системный вызов от имени которого происходит трансляция имени, "следует" символической связи, операция vn_lookup() вызывает vn_readlink() для получения имени целевого файла. Если оно является абсолютным (т.е. начинается с "/"), то трансляция начинается с vnode корневого каталога, адресованного полем u_rdir области и_агеа.
Процесс трансляции имени продолжается, пока не просмотрены все компоненты имени или не обнаружена ошибка (например, отсутствие прав доступа). В случае удачного завершения возвращается vnode файла.
Доступ к файловой системе
Как было показано в главе 2, процесс совершает операции с файлами, адресуя их при помощи файловых дескрипторов – целых чисел, имеющих локальное для процесса значение. Это значит, что файловый дескриптор одного процесса может адресовать совершенно другой файл, нежели файловый дескриптор с таким же номером, используемый другим процессом. Процесс получает файловый дескриптор с помощью ряда системных вызовов, например, open(2) или create(2), выполняющих операцию трансляции имени, в результате которой выделяемый файловый дескриптор адресует определенный inode (или vnode) и, соответственно, файл файловой системы.
На рис. 4.12 показаны основные структуры ядра, необходимые для доступа к файлу.
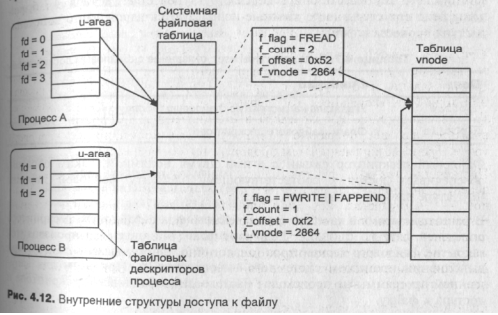
Файловый дескриптор, используемый для доступа процесса к файлу, является индексом таблицы файловых дескрипторов (file descriptor table). Каждый процесс имеет собственную таблицу файловых дескрипторов, которая расположена в его u-area. На рис. 4.12 показаны два процесса, каждый из которых использует таблицу файловых дескрипторов.
Каждая активная запись этой таблицы, представляющая открытый файл, адресует запись системной файловой таблицы (system file table), в которой хранятся такие параметры, как режим доступа к файлу (запись, чтение, добавление и т.д.), текущее смещение в файле (файловый указатель), а также указатель на vnode этого файла. Системная файловая таблица одна и совместно используется всеми процессами.
Как следует из рис. 4.12, несколько записей системной файловой таблицы могут адресовать один и тот же файл, который представлен единственной записью в таблице vnode.
Файловые дескрипторы
Файловый дескриптор представляет собой неотрицательное целое число, возвращаемое системными вызовами, такими как creat(2), open(2) или pipe(2). После получения файлового дескриптора процесс может использовать его для дальнейшей работы с файлом, например с помощью системных вызовов read(2), write(2), close(2) или fcntl(2).
Ядро обеспечивает работу процесса с файлами, используя различные структуры данных, часть из которых расположена в u-area процесса. Напомним, что эта область описывается структурой user. В табл. 4.7 приведены поля структуры user, которые используются ядром для обеспечения доступа процесса к файлу.

Файловый дескриптор связан с этими двумя полями и, таким образом, обеспечивает доступ к соответствующему элементу файловой таблицы (структуре данных file).
В настоящее время в качестве единственного флага файлового дескриптора определен флаг FD_CLOEXEC. Если этот флаг установлен, то производится закрытие файлового дескриптора (аналогично явному вызову close(2) при выполнении процессом системного вызова ехес(2)). При этом для запущенной программы не происходит наследования файлового дескриптора доступа к файлу.
Более старые версии UNIX используют статическую таблицу дескрипторов, которая целиком хранится в u-area. Номер дескриптора является индексом этой таблицы. Таким образом, размер таблицы, которая обычно содержит 64 элемента, накладывает ограничение на число одновременно открытых процессом файлов. В современных версиях таблица размещается динамически и может увеличиваться при необходимости. Следует, однако иметь в виду, что и в этом случае максимальное число одновременно открытых файлов регламентируется пределом RLIMIT_NOFILE, которая рассматривался в разделе "Ограничения" главы 2. В некоторых версиях например, Solaris 2.5, данные файловых дескрипторов хранятся не в таблицы, а в виде блоков структур uf_entry, поля которой аналогичны приведенным в табл. 4.7.
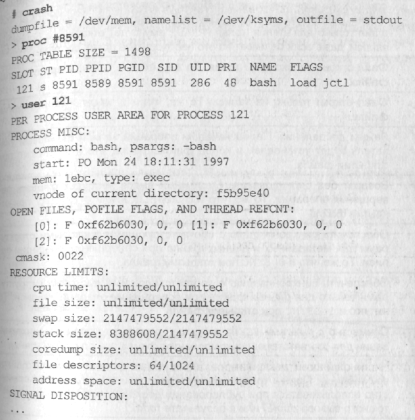
Содержимое таблицы дескрипторов процесса можно посмотрено с помощью утилиты crash(lM). Команда user покажет содержимое u-area процесса. Например, для текущего командного интерпретатора мы получим следующую информацию:
Файловая таблица
Поля файлового дескриптора u_ofile и u_pofile содержат начальную информацию, необходимую для доступа процесса к данным файла. Дополнительная информация находится в системной файловой таблице и таблице индексных дескрипторов. Для обеспечения доступа процесса к данным файла ядро должно полностью создать цепочку от файлового дескриптора до vnode и, соответственно, до блоков хранения данных, как показано на рис. 4.12.
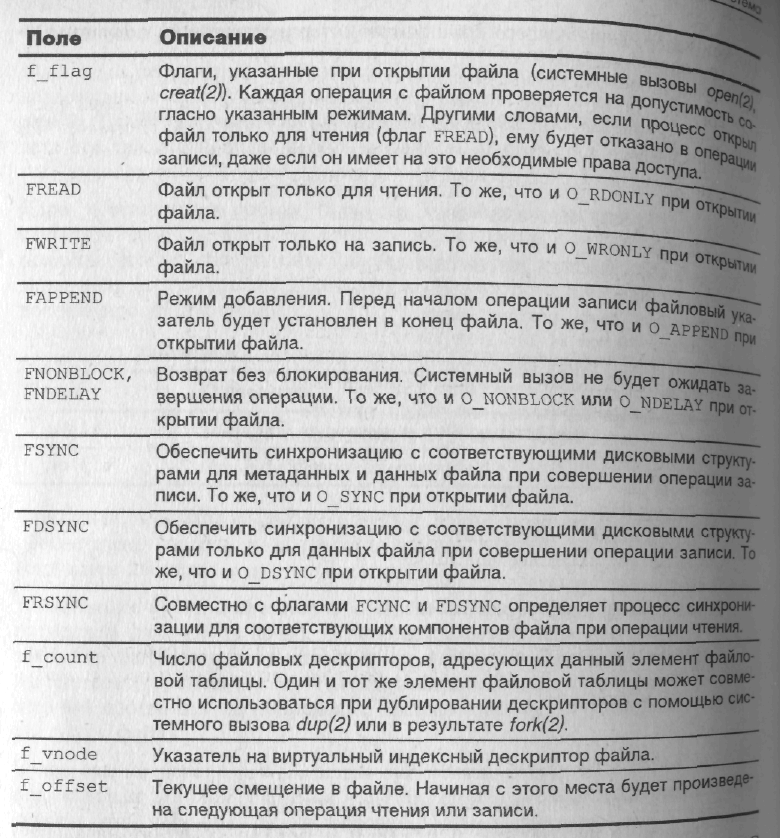
Каждый элемент файловой таблицы содержит информацию, необходимую для управления работой с файлом. Если несколько процессов открывают один и тот же файл, каждый из них получает собственный элемент файловой таблицы, хотя все они будут работать с одним и тем же файлом. Важнейшие поля элемента файловой таблицы приведены ниже:
Для иллюстрации обсуждения продолжим работу с утилитой crash(1М). С помощью команды user в предыдущем разделе были получены адреса элементов файловой таблицы для стандартного ввода (fd=0), вывода (fd=1) и вывода сообщений об ошибках (fd=2). Заметим, что все они указывают на один и тот же элемент. С помощью команды file исследуем его содержимое:

Поскольку это специальный файл устройства (об этом свидетельствует поле TYPE эдемента файловой таблицы), поле v_data (vdata) vnode указывает на inode файловой системы ufs, а на snode – индексный дескриптор логической файловой системы specfs, обслуживающей специальные файлы устройств. Более подробно этот интерфейс будет рассматриваться в следующей главе. Таким образом, для продолжения путешествия по структурам данных ядра, следует обратиться к snode, адрес которого указан в поле VDATA.

Поле s_realvp (REALVP) указывает на vnode файла реальной файловой системы (в данном случае ufs). Поэтому далее поиск аналогичен проделанному при исследовании таблицы монтирования.

В результате мы определили имя специального файла устройства (в данном случае – это псевдотерминал), на которое производится ввод и вывод командного интерпретатора.
Блокирование доступа к файлу
Традиционно архитектура файловой подсистемы UNIX разрешает нескольким процессам одновременный доступ к файлу для чтения и записи. Хотя операции записи и чтения, осуществляемые с помощью системных вызовов read(2) или write(2), являются атомарными, в UNIX по умолчанию отсутствует синхронизация между отдельными вызовами. Другими словами, между двумя последовательными вызовами read(2) одного процесса другой может модифицировать данные файла. Это, в частности, может привести к несогласованным операциям с файлом, и как следствие, к нарушению целостности его данных. Такая ситуация является неприемлемой для многих приложений.
UNIX позволяетляет обеспечить блокирование заданного диапазона байтов файла или записи файла. Для этого служат базовый системный вызов управления файлом fcntl(2) и библиотечная функция lockf(3C), предназначенная специально для управления блокированием. При этом фактической файловой операцией (чтения или записи) процесс устанавливает блокирование соответствующего типа (для чтения или для записи). Если блокирование завершилось успешно, это означает, что требуемая файловая операция не создаст конфликта или нарушения целостности данных, например, при одновременной записи в файл несколькими процессами.
По умолчанию блокирование является рекомендательным (advisory lock). Это означает, что кооперативно работающие процессы могут руководствоваться созданными блокировками, однако ядро не запрещает чтение или запись в заблокированный участок файла. При работе с рекомендательными блокировками процесс должен явно проверять их наличие с помощью тех же функций fcntl(2) и lockf(3C).
Мы уже встречались с использованием системного вызова fcntl(2) для блокирования записей файла в главе 2. Там же была упомянута структура flock, служащая для описания блокирования. Поля этой структуры описаны в табл. 4.8.

Как следует из описания поля l_type структуры flock, существуют два типа блокирования записи: для чтения (f_rdlck) и для записи (F_WRLCK). Правила блокирования таковы, что может быть установлено несколько блокирований для чтения на конкретный байт файла, при этом в установке блокирования для записи на этот байт будет отказано. Напротив, блокирование для записи на конкретный байт должно быть единственным, при этом в установке блокирования для чтения будет отказано.
Приведем фрагмент программы, использующей возможность блокирования записей:

В отличие от рекомендательного в UNIX существует обязательное блокирование (mandatory lock), при котором ограничение на доступ к записям файла накладывается самим ядром. Реализация обязательных блокировок может быть различной. Например, в SCO UNIX (SVR3) снятие бита х для группы и установка бита SGID для группы приводит к тому, что блокировки, установленные fcntl(2) или lockf(3C)t станут обязательными. UNIX SVR4 поддерживает установку блокирования отдельно для записи и для чтения, обеспечивая тем самым доступ для чтения многим, а для записи — только одному процессу. Эти установки также осуществляются с помощью системного вызова fcntl(2). Следует иметь в виду, что использование обязательного блокирования таит потенциальную опасность. Например, если процесс блокирует доступ к жизненно важному системному файлу и по каким-либо причинам теряет контроль, это может привести к аварийному останову операционной системы.
Буферный кэш
Во введении отмечалось, что работа файловой подсистемы тесно связана с обменом данными с периферийными устройствами. Для обычных файлов и каталогов — это устройство, на котором размещается соответствующая файловая система, для специальных файлов устройств – это принтер, терминал, или сетевой адаптер. Не вдаваясь в подробности подсистемы ввода/вывода, рассмотрим, как во многих версиях UNIX организован обмен данными с дисковыми устройствами — традиционным местом хранения подавляющего большинства файлов1.
На самом деле файловые системы могут располагаться на удаленных компьютерах ( например, в случае NFS). Хотя при работе с такими файловыми системами дисковый ввод/вывод отсутствует, тем не менее и в этом случае кэширование блоков данных значительно повышает производительность.
Не секрет, что операции дискового ввода/вывода являются медленными по сравнению, например, с доступом к оперативной или сверхоперативной памяти. Время чтения данных с диска и копирования тех же данных в памяти может различаться в несколько тысяч раз.
Поскольку основные данные хранятся на дисковых накопителях, дисковый ввод/вывод является узким местом операционной системы.
Для повышения производительности дискового ввода/вывода и, соответственно, всей системы в целом, в UNIX используется кэширование дисковых блоков в памяти.
Для этого используется выделенная область оперативной памяти, где кэшируются дисковые блоки файлов, к которым наиболее часто осуществляется доступ. Эта область памяти и связанный с ней процедурный интерфейс носят название буферного кэша, и через него проходит большинство операций файлового ввода/вывода.
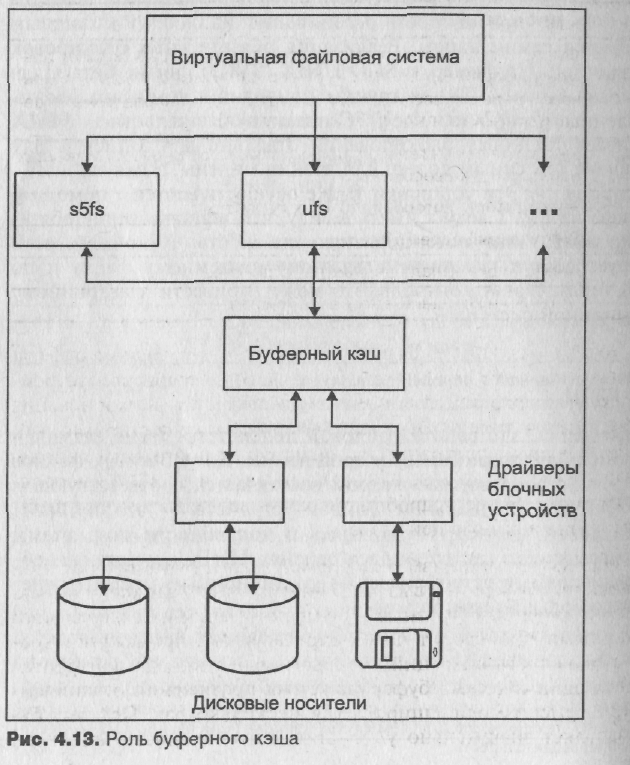
Схема взаимодействия различных подсистем ядра с буферным кэшем приведена на рис. 4.13.
Внутренняя структура буферного кэша
Буферный кэш состоит из буферов данных, размер которых достаточен для размещения одного дискового блока.
С каждым блоком данных связан заголовок буфера, представленный структурой buf, с помощью которого ядро производит управление кэшем, включая идентификацию и поиск буферов, а также синхронизацию доступа.
Заголовок также используется при обмене данными с драйвером устройства для выполнения фактической операции ввода/вывода. Когда возникает необходимость чтения или записи буфера на диск, ядро заносит параметры операции ввода/вывода в заголовок и передает его функции драйвера устройства. После завершения операции ввода/вывода заголовок содержит информацию о ее результатах.
Основные поля структуры buf приведены в табл. 4.9.

Поле b_flags хранит различные флаги связанного с заголовком буфера. Часть флагов используется буферным кэшем, а часть — драйвером устройств. Например, с помощью флага b_busy осуществляется синхронизация доступа к буферу. Флаг b_delwri отмечает буфер как модифицированный, или «грязный», требующий сохранения на диске перед повторным использованием. Флаги b_read, b_write, b_async, b_done и b_error используются драйвером диска. Более подробно операция ввода/вывода для драйвера будет рассмотрена в следующей главе.
Буферный кэш использует механизм отложенной записи (write-behind), при котором модификация буфера не вызывает немедленной записи на диск. Такие буферы отмечаются как "грязные", а синхронизация их содержимого с дисковыми данными происходит через определенные промежутки времени. Примерно одна треть операций дискового ввода/вывода приходится на запись, причем один и тот же буфер может на протяжении ограниченного промежутка времени модифицироваться несколько раз. Поэтому буферный кэш позволяет значительно уменьшить интенсивность записи на диск2 и реорганизовать последовательность записи отдельных буферов и повышения производительности ввода/вывода (например, уменьшая время поиска, группируя запись соседних дисковых блоков). Однако механизм имеет свои недостатки, поскольку может привести к нарушению целостности файловой системы в случае неожиданного останова операционной системы.
Использование буферного кэша позволяет избежать 95% операций чтения с операций записи на диск для типичной конфигурации операционной систем