


2.3 Анализ
Подготовка
В принципе, данные можно поначалу записывать и в привычном “Экселе”. Самое главное — помнить о том, как обычно организованы данные для исследования:
Панельные Каждая колонка — отдельная переменная, например: пол, возраст, образование. Каждая строка — отдельный объект (человек, страна, фирма: Аня, Петя, Вася).
Имя |
Пол |
Возраст |
Образование |
|
|
|
|
Аня |
Ж |
14 |
незаконченное среднее |
|
|
|
|
Петя |
М |
15 |
незаконченное среднее |
|
|
|
|
Вася |
М |
24 |
высшее |
|
|
|
|
Временные ряды Каждая колонка — отдельная дата. В строках — переменные. Показываем, как они изменялись с течением времени (к примеру, цена акций).
Акция |
12.02. |
14.02. |
16.02 |
|
|
|
|
Газпром |
23 |
25 |
23 |
|
|
|
|
Лукойл |
1 |
1,5 |
0.6 |
|
|
|
|
Роснефть |
126 |
175 |
145 |
|
|
|
|
Теперь таблицу без особых проблем можно вставить в Stata. Одна проблема — она не поддерживает запятую для отделения десятичной части. Решается вопрос так:
destring (список переменных), replace dpcomma
Если вы вводили все категориальные переменные (вроде пола, образование и прочего, что имеет несколько категорий) словами (лучше, кстати, использовать английский), то их обязательно нужно переделать в численные таким образом:
encode (список переменных)
Мы не будем рассматривать здесь, как работать в “Стате” и как там все организовано — для этого есть туториалы и книги, указанные выше. Будем считать, что вы уже там освоились и понимаете, что строки выше — это команды.
9

Регрессионный анализ
В этом разделе мы рассмотрим самые основы регрессионного анализа в Stata — базовые навыки, которые помогут подготовить самое простейшее исследование с помощью метода контроля переменных. Используем данные по автомобилям, встроенные в Stata:
sysuse auto.dta
Некоторые полезные команды:
Команда |
Что делает |
|
|
describe |
Описывает данные: какие переменные, |
|
сколько наблюдений |
|
|
list |
Перечисляет наблюдения по заданным |
|
условиям |
|
|
codebook |
Выдает разные характеристики |
|
переменных |
|
|
summarize |
То же самое — мин, макс, среднее, |
|
стандартное отклонение |
|
|
histogram |
Рисует гистограмму для переменной |
|
|
kdensity |
Рисует график плотности для |
|
переменной (более наглядно) |
|
|
graph box |
Рисует boxplot (“усатый график”) для |
|
переменной |
|
|
stem |
Рисует график “ветви и листья” для |
|
переменной |
|
|
count |
Считает число наблюдений по |
|
заданным условиям |
|
|
graph matrix |
Рисует матричный график для |
|
выбранных переменных |
|
|
С помощью команды regress (регрессия) посмотрим, как цена автомобиля зависит от объема багажника, места производства (иномарка/отечественная), веса, длины и максимальной скорости.
regress price trunk foreign weight length mpg
Получим вот такую таблицу:
10
Source |
|
SS |
df |
|
MS |
|
|
Num er of obs |
|
|
74 |
||
T t |
635065396 |
73. |
69755446978699 |
|
Probt |
MSE524 |
68) |
= |
20944921. |
||||
ResiduModeal |
348777232 |
5 |
|
|
.5 |
|
F( |
5, |
16.57 |
||||
|
|
|
|
> F |
|
|
0000 |
||||||
286288164 |
68 |
4210120.06 |
|
R-squared |
|
|
.5 |
61 |
|||||
ice |
- . |
|
. |
|
- |
|
|
Adj-174R-squared. |
|
|
|||
fore |
355 |
08 |
2 |
3934 |
|
5. |
0.000 |
|
|
|
|
7 851 |
|
Статистикаwlpticonsunkmpggnhtth |
R squared9010.70950153Coef47521.. 47.23 |
( Std82367254312)21320244866.показывает,Err276. 02 t5741399 |
насколькоP>|t|89985332815 [95%3542235.6366наше.Conf625484018.7683.уравнениеInterval]-487153.76..85.5.3211.34783 |
||||||||||
|
|
2 |
|
|
|
0 |
|
|
8 |
|
|
|
|
описывает вариацию данных Лучше всего, если он близок к единице. Coef. показывает коэффициент, стоящий при переменной в регрессионном уравнении. Самая важная для нас часть — P>|t| Если она меньше принятого нами уровня значимости (обычно 0.05), то переменная не оказывает никакого воздействия на наш Y (то есть цену). В данном случае мы видим, что цена зависит от места производства (выше если иномарка), веса и длины автомобиля. Коэффициент, кстати, уже показывает воздействие при фиксированных остальных переменных.
После построения регрессии можно вывести в отдельную переменную предсказанные по уравнению значения:
predict имя_новой_переменной |
|
|
|
Или остатки: |
|
|
|
predict имя_новой_переменной, residual |
|
||
Можно построить точечный график зависимости нашего Y от какого- |
|||
нибудь Х, например, веса автомобиля: |
|
|
|
scatter price weight |
|
|
|
К нему можно добавить линию предсказанных значений: |
|||
twoway (scatter price weight) (lfit price weight) |
|||
Получим такой вот график: |
|
|
|
15,000 |
|
|
|
10,000 |
|
|
|
5,000 |
|
|
|
0 |
|
|
|
2,000 |
3,000 |
4,000 |
5,000 |
|
Weight (lbs.) |
|
|
Price |
Fitted values |
11
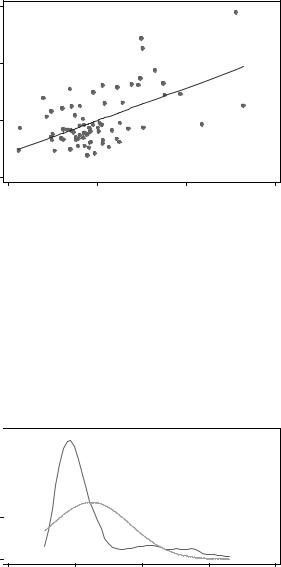
Наглядно видим, что цена действительно зависит от веса, хотя |
|||
разброс значений довольно большой. Кроме того, можно построить |
|||
график частичной корреляции цены от веса (при фиксированных |
|||
остальных переменных): |
|
|
|
avplot weight |
|
|
|
10000 |
|
|
|
) 5000 |
|
|
|
e( price | X |
|
|
|
0 |
|
|
|
-5000 |
0 |
500 |
1000 |
-500 |
|||
|
e( weight | X ) |
|
|
coef = 5.7095013, se = 1.0247599, t = 5.57 |
|
|
|
Трансформация переменных
Чтобы регрессионное уравнение имело смысл, желательно, чтобы переменные были нормально распределены. Посмотрим, что у нас происходит с ценой автомобиля:
kdensity price, normal
Получим вот такой вот график, где отображено частотное распределение цены и соответствующее нормальное распределение:
Density 0 .0001 .0002 .0003
Kernel density estimate
0 |
5000 |
10000 |
15000 |
20000 |
|||
|
|
|
|
Price |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Kernel density estimate |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
Normal density |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
kernel = epanechnikov, bandwidth = 605.6424 |
|
|
|
||||
На нормальное не очень похоже. Или можно построить вот такой тестовый график:
12
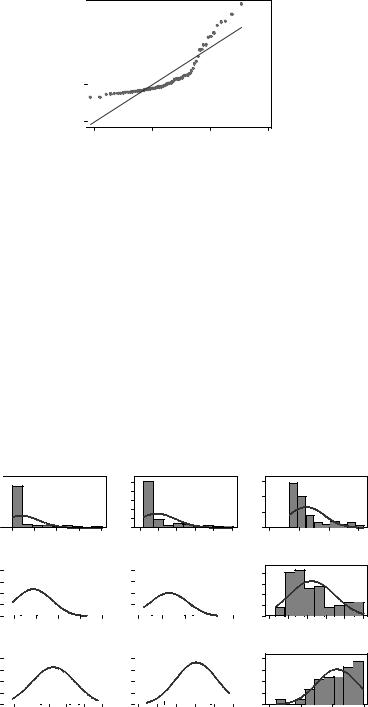
qnorm price
Price 0 5,000 10,000 15,000
0 |
5,000 |
10,000 |
15,000 |
Inverse Normal
Если бы распределение было нормальным, точки располагались бы вдоль линии. Желательно преобразовать эту переменную в другую — логарифмировать ее или возвести в степень. Выбрать лучший способ поможет следующая команда:
|
ladder price |
|
|
|
|
|
|
Она выдает такую вот таблицу: |
|
|
|
|
|
||
|
|
|
|
|
|
||
|
Transformation |
formulaprice^ |
chi2(2) |
P(chi2) |
|||
|
square |
log(price)ice^ |
6 |
77 |
37 |
разделить на |
|
1/ |
|
0.000 |
|||||
|
|
1/ |
21.7 |
||||
Смотрим,cubicidentityloginve(squasquarecubicse oote root)где самаяsqrt(price)t(price)маленькая32 23) |
статистика44335041 984962157chi2 — один41695 |
||||||
цену в квадрате. Проверим графически: gladder price
05.0e1-.130e1-.125e2-.120e-12
|
cubic |
square |
0 1.0e-204.0e-304.0e-04 |
|
50.0e1.-0e91.-5e082.-0e82.-5e08-08 |
|
|
0 |
1.00e+12.00e+123.00e+124.00e+12 |
0 5.00e+071.00e+081.50e+082.00e+082.50e+08 |
0 |
identity |
|
|
5000 |
10000 |
15000 |
sqrt
Density |
.01.02 .03 04. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
60 |
80 |
100 |
120 |
140 |
|||||||||
|
0 2000400060008000 |
|
|
|
|
|
inverse |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-.0003-.00025-.0002-.00015-.0001-.00005
log
2 |
|
|
|
|
|
|
|
|
|
|
|
|
1.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
8.5 |
9 |
9.5 |
10 |
||||||||
05.60e+1.e+071.75e+2.0e+07 |
|
|
|
1/square |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-1.00e--807.00e--608.00e--408.00e--208.00e-08 0
|
1/sqrt |
|
50100150200 |
|
|
0 |
|
|
|
-.018 -.016 -.014 -.012 -.01 -.008 |
|
02.0e+104.0e+106.0e+108.0e+10 |
1/cubic |
|
|
|
|
-3.00e-11-2.00e-11-1.00e-11 |
0 |
|
Price
Histograms by transformation
13
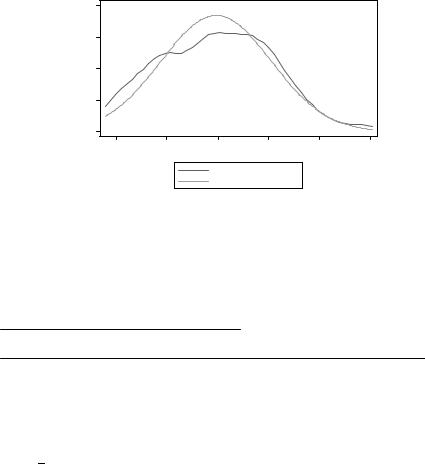
Не совсем очевидно, но преобразование вроде бы подходит. |
||||
Создаем новую переменную и проверяем ее на нормальность: |
||||
generate price2 = 1/(price^2) |
|
|
||
kdensity price2, normal |
|
|
|
|
Действительно, все гораздо лучше: |
|
|
|
|
Density 5000000100000001500000020000000 |
Kernel density estimate |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
0 |
2.000e-08 4.000e-08 |
6.000e-08 |
8.000e-08 |
1.000e-07 |
|
price2 |
|
|
|
Kernel density estimate
Normal density
kernel = epanechnikov, bandwidth = 8.236e-09
Снова прогоняем регрессию, заменив price нa price2:
regress price2 trunk foreign weight length mpg |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
Num er of obs |
|
|
74 |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||||
Source |
|
SS |
df |
|
MS |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
||||||||
ResiduMode |
1.598196 -14 |
68 |
2.35236396 -1 |
|
|
|
F( |
b5, 68) |
= |
1 .47 |
|
||||
5 |
|
-squared |
|
|
0.0000322 |
|
|||||||||
T t |
3 |
8 |
5 |
3 |
841e |
|
|
> F |
|
|
5 |
- |
|
||
|
73 |
4 |
|
|
|
Probt MSE |
|
|
1 |
8 |
|||||
al |
2 4 |
1 |
|
1 |
|
48 |
|
4 |
|
|
36e |
1 |
|||
|
|
|
|
|
6 |
|
AdjR |
R-squared |
|
497808 |
|
||||
|
4 6 |
|
66 |
|
0 |
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
|
|
|
price2 |
|
|
|
|
|
|
|
618 |
- .1 e-00 |
- . |
|
- |
|
||
|
|
|
3e- |
|
- . |
|
|
0.00 |
|
[95%1381 значимость67009976e42Conf08981 . Interval]7296 83027480eкак297 пе- |
|||||
|
|
- |
. 5e |
|
|
|
|
|
|
||||||
|
- . |
4e |
|
|
|
|
|
|
|
||||||
Интересныеfowltrunkeignhtconsmpgth 4319 0130728новости:Co4 f0808.1 Std647254 1957430длина. Err09082. потеряла632 t722503 P>|t|47336свою0 |
|||||||||||||||
ременная. Для более тщательного контроля стоит проверить на нормальность все переменные.
Диагностика регрессии
Хорошая множественная линейная регрессия должна удовлетворять следующим требованиям:
Линейность Зависимость между Y и X должна быть линейной.
Нормальность Ошибки (остатки) должны быть нормально, одинаково и независимо распределенны.
14
Гомоскедастичность Или однородность дисперсии: дисперсия ошибок должна быть постоянной.
Независимость Ошибки одного наблюдения не должны коррелировать с ошибками другого.
Ошибки в переменных Все иксы должны быть измерены без ошибок.
Спецификация модели Модель должна быть правильной — включать все значимые переменные и не включать незначимые. Впрочем, если по вашей теории незначимая переменная там должна быть, пусть она там будет.
Бонус Желательно, если в данных не будет непонятных выбросов (далеких точек, которые портят всю картину) и отсутствует мультиколлинеарность (когда один X зависит от другого).
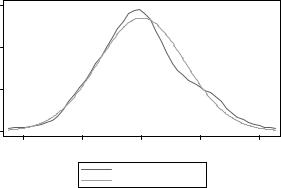
Итак, начнем с нормальности остатков. Генерируем их в переменную r и проверяем уже привычной командой:
predict r, resid kdensity r, normal
|
30000000 |
Kernel density estimate |
|
||
|
|
|
|
|
|
Density |
10000000 20000000 |
|
|
|
|
|
0 |
|
|
|
|
|
-4.000e-08 |
-2.000e-08 |
0 |
2.000e-08 |
4.000e-08 |
|
|
|
Residuals |
|
|
Kernel density estimate
Normal density
kernel = epanechnikov, bandwidth = 5.185e-09
Выглядит неплохо, но не идеально. Проверяем еще одной командой:
pnorm r
15

1.00 |
|
|
|
|
0.75 |
|
|
|
|
Normal F[(r-m)/s] 0.50 |
|
|
|
|
0.25 |
|
|
|
|
0.00 |
|
|
|
|
0.00 |
0.25 |
0.50 |
0.75 |
1.00 |
|
|
Empirical P[i] = i/(N+1) |
|
|
Аналогично. Наконец, воспользуемся тестом Шапиро-Уилка:
swilk r
Поскольку величина Prob>z весьма велика (0.81124), то распределение можно назвать нормальным. Хороший знак для нашей регрессии.
Теперь проверяем остатки на гомоскедастичность:
rvfplot, yline(0)
Residuals -4.00e-08 -2.00e-08 0 2.00e-08 4.00e-08
0
2.00e-08 |
4.00e-08 |
6.00e-08 |
8.00e-08 |
|
Fitted values |
|
|
Остатки разбросаны вокруг линии совершенно случайно, так что вряд ли здесь есть гетероскедастичность. На всякий случай прогоняем формальный тест:
estat imtest
Heteroskedasticity |
. |
16 df1925 |
. |
SkewnesKurtSourceT sistal |
25chi2.39 |
0.p1482 |
Поскольку величина велика, можно смело заключить, что с регрессией все в порядке.
Тепеь проверяем на мультиколлинеарность. Команда очень короткая (сокращение от variance inflation factor):
vif
ПравилоMeanVariableforeignlwtrunkVIFthhtmpg очень115VIF23.8506114044простое:0.0461/VIF32669092287379816706если VIF больше 10, значит где-то тут
мультиколлинеарность. Действительно, если приглядеться, то можно понять, что длина и ширина автомобиля действительно связаны — а раз длина у нас незначимая переменная, то ее можно без особых проблем выкинуть из регрессии.
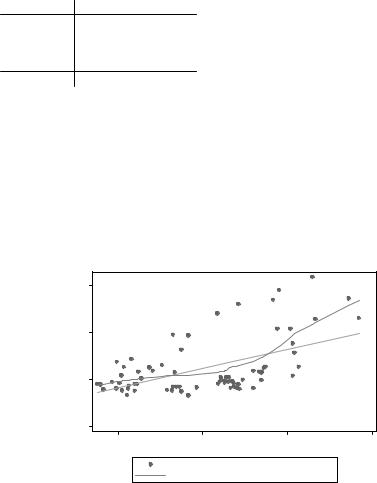
Займемся линейностью (lowess — это процедура “локальнолинейного сглаживания”):
twoway (scatter price weight) (lfit price weight) (lowess price weight)
15,000 |
|
|
|
10,000 |
|
|
|
5,000 |
|
|
|
0 |
|
|
|
2,000 |
3,000 |
4,000 |
5,000 |
|
Weight (lbs.) |
|
|
Price |
|
Fitted values |
|
lowess price weight
Из графика видно, что на самом деле зависимость не такая уж и линейная. Впрочем, если заменить price на новый price2, то все выглядит несколько лучше. Однако эта методика подходит, когда в нашей регрессии только один Х. Если регрессия множественная, нужно воспользоваться следующим методом:
acprplot weight, lowess
17
plus residual |
0 2.00e-08 |
|
|
|
component -2.00e-08 |
|
|
|
|
Augmented |
-4.00e-08 |
|
|
|
|
-6.00e-08 |
3,000 |
4,000 |
5,000 |
|
2,000 |
|||
|
|
Weight (lbs.) |
|
|
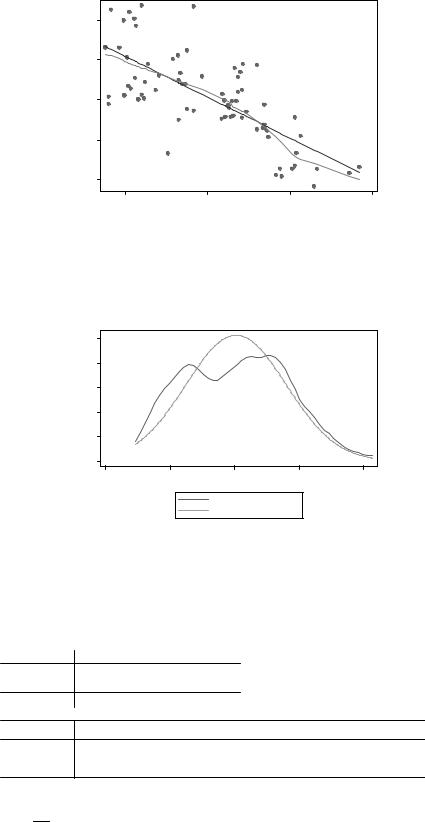
Снова видны отклонения от линейности. Возможно, пробема в том, что вес автомобиля у нас распределено не нормально. Проверим:
kdensity weight, normal
Kernel density estimate
.0005 |
|
|
|
|
.0004 |
|
|
|
|
Density 0002 .0003 |
|
|
|
|
. |
|
|
|
|
.0001 |
|
|
|
|
0 |
|
|
|
|
1000 |
2000 |
3000 |
4000 |
5000 |
|
|
Weight (lbs.) |
|
|
Kernel density estimate
Normal density
kernel = epanechnikov, bandwidth = 295.7504
Действительно, у нас имеются два ярко выраженных “горба” — два класса автомобилей. Возможно, для каждого из них лучше делать собственную регрессию.
Теперь посмотрим на спецификацию модели:
linktest
Source |
|
SS |
df |
|
MS |
|
|
Num er of obs |
= |
|
74 |
||
ResiduMode |
1.598196 -14 |
2 |
2.2216 |
-1 |
|
F( b1, |
72) |
81.91 |
|||||
|
-squared |
|
|
0.0000322 |
|||||||||
T t |
3 |
8 |
1 |
1 |
8198 |
4 |
|
Probt |
> F |
|
|
.12 |
- 8 |
|
3 |
4 |
6841e |
.0 |
.000 |
MSE |
|
|
|||||
al |
|
4 Coe4e |
7 |
|
|
6 |
|
AdjR |
R-squared |
|
|
5257 |
|
price2hatsqcons |
(omitt-5.63e-fd)17. |
Std.41104898.67e.Err-09. -1890 t50 |
P>|t|01 |
-[95%.97797426.32eConf-09 . |
Interval]19 23 0257e-09 |
||||||||