

Литература: Концептуальное моделирование. Пример построения модели "сущность-связь"
Готовая модель "сущность-связь" представлена на следующем рисунке:

рис.17.Правила порождения реляционных отношений из модели "сущность-связь"
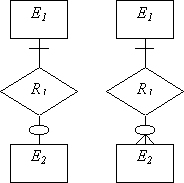
2.Бинарные связи
|
Тип связи |
Пример связи |
Правило построения отношений |
Отношения |
|
(1,1):(1,1) |
|
Требуется только одно отношение. Первичным ключом данного отношения может быть ключ любой из сущностей. |
|
|
(1,1):(0,1) (1,1):(0,n) |
|
Для каждой сущности создается свое отношение, при этом ключи сущностей служат ключами соответствующих отношений. Кроме того, ключ сущности с обязательным классом принадлежности добавляется в качестве внешнего ключа в отношение, созданное для сущности с необязательным классом принадлежности. |
|
|
(0,1):(0,1) |
|
Необходимо использовать три отношения: по одному для каждой сущности (ключи сущностей служат первичными ключами отношений) и одно отношение для связи. Отношение, выделенное для связи, имеет два атрибута - внешних ключа - по одному от каждой сущности. |
|
|
(0,1):(0,n) (0,1):(1,n) |
|
Формируются три отношения: по одному для каждой сущности, причем ключ каждой сущности служит первичным ключом соттветствующего отношения, и одно отношение для связи. Отношение, выделенное для связи, имеет два атрибута - внешних ключа - по одному от каждой сущности. |
|
|
n : m |
|
В этом случае всегда используются три отношения: по одному для каждой сущности, причем ключ каждой сущности служит первичным ключом соттветствующего отношения, и одно отношение для связи. Послденее отношение должно иметь среди своих атрибутов внешние ключи, по одному от каждой сущности. |
|









3.N - арные связи.
Общее правило: для представления n-сторонней связи всегда требуется n+1 отношение. Например, в случае трехсторонней связи необходимо использовать четыре отношения, по одному для каждой сущности (причем ключ сущности служит первичным ключом соответствующего отношения), и одно для связи. Отношение, порождаемой для связи, будет иметь среди своих атрибутов ключи от каждой сущности.

Рис.18.Отношения и связи
4.Иерархические связи.
Возможны два варианта построения реляционных отношений. Согласно первому для иерархической структуры создается одно отношение, которое содержит атрибуты связи и всех сущностей.
По второму способу генерируется по одному отношению для каждой дочерней сущности. Каждое из этих отношений включает атрибуты родительской сущности и связи кроме атрибутов - дискриминантов. Недостатком данного способа является невозможность получить в одном запросе список всех заказчиков.
Оба описанных способа представлены на рисунке:
Рис.19.Способы
построения реляционных отношений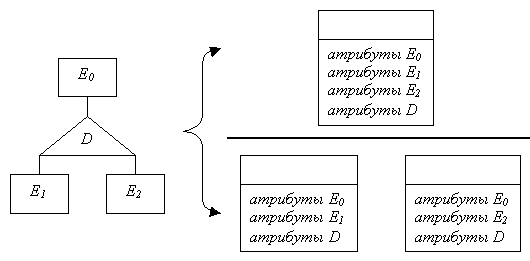
Следует отметить, что построенные таким образом реляционные отношения, не являются окончательной схемой базы данных. Их необходимо проверить на избыточные функциональные зависимости и привести к NFBK или нормальной форме более высокого порядка.
Применив все эти правила к модели "сущность-связь" базы данных publications, построенной в предыдущем параграфе, получим следующую реляционную структуру:

Рис.20.Реляционная структура Синим цветом на диаграмме выделены первичные ключи, красным - внешние. Отношения, созданные для представления связей, обозначены серыми прямоугольниками, для сущностей - желтыми прямоугольниками.
5.Диаграмма "сущность-связь".
Очень важным свойством модели "сущность-связь" является то, что она может быть представлена в виде графической схемы. Это значительно облегчает анализ предметной области. Существует несколько вариантов обозначения элементов диаграммы "сущность-связь", каждый из которых имеет свои положительные черты. Здесь мы будем использовать некий гибрид нотаций Чена (обозначение сущностей, связей и атрибутов) и Мартина (обозначение степеней и кардинальностей связей). В таблице 2.1 приводится список используемых здесь обозначений.
Таблица 2.1
|
Обозначение |
Значение |
|
|
Набор независимых сущностей |
|
|
Набор зависимых сущностей |
|
|
Атрибут |
|
|
Ключевой атрибут |
|
|
Набор связей |

Рис.21. Пример диаграммы «сущность-связь»
Лекция 10
Организация физической структуры БД
Цель: изучить организацию физической структуры БД.
Ключевые слова: организация файла, метод доступа, неупорядоченные файлы, упорядоченные и хешированные файлы, динамическое хеширование.
Литература. [4, 569-601; 5, 434-451]
Организация файла. Физическое распределение данных файла по записям и страницам на вторичном устройстве хранения.
Существуют следующие основные типы организации файлов.
• Неупорядоченная организация файла предусматривает произвольное неупорядоченное размещение записей на диске.
• Упорядоченная (последовательная) организация предполагает размещение записей в соответствии со значением указанного поля.
• В хешированием файле записи хранятся в соответствии со значением некоторой хеш-функции,
Для каждого типа организации файлов используется соответствующий набор методов доступа.
Метод доступа. Действия, выполняемые при сохранении или извлечении записей из файла.
Поскольку некоторые методы доступа могут применяться только к файлам с определенным типом организации (например, нельзя применять индексный метод доступа к файлу, не имеющему индекса), термины организация файла и метод доступа часто рассматриваются как эквивалентные. Дальше в этом приложении описаны основные типы структуры файлов и соответствующие им методы доступа. В главе 16 представлена методология физического проектирования базы данных для реляционных систем вместе с рекомендациями по выбору наиболее подходящей структуры файлов и индексов.
Неупорядоченные файлы
Неупорядоченный файл (который иногда называют кучей) имеет простейшую структуру. Записи размещаются в файле в том порядке, в котором они в него вставляются. Каждая новая запись помещается на последнюю страницу файла, а если на последней странице для нее не хватает места, то в файл добавляется новая страница. Это позволяет очень эффективно выполнять операции вставки. Но поскольку файл подобного типа не обладает никаким упорядочением по отношению к значениям полей, для доступа к его записям требуется выполнять линейный поиск. При линейном поиске все страницы файла последовательно считываются до тех пор, пока не будет найдена нужная запись. Поэтому операции извлечения данных из неупорядоченных файлов, имеющих несколько страниц, выполняются относительно медленно, за исключением тех случаев, когда извлекаемые записи составляют значительную часть всех записей файла.
Для удаления записи сначала требуется извлечь нужную страницу, потом удалить нужную запись, а после этого снова сохранить страницу на диске. Поскольку пространство удаленных записей повторно не используется, производительность работы по мере удаления записей уменьшается. Это означает, что неупорядоченные файлы требуют периодической реорганизации, которая должна выполняться администратором базы данных (АБД) с целью освобождения неиспользуемого пространства, образовавшегося на месте удаленных записей.
Неупорядоченные файлы лучше всех остальных типов файлов подходят для выполнения массовой загрузки данных в таблицы, поскольку записи всегда вставляются в конец файла, что исключает какие-либо дополнительные действия по вычислению адреса страницы, в которую следует поместить ту или иную запись.
Упорядоченные файлы
Записи в файле можно отсортировать по значениям одного или нескольких полей и таким образом образовать набор данных, упорядоченный по некоторому ключу. Поле (или набор полей), по которому сортируется файл, называется полем упорядочения. Если поле упорядочения является также ключом доступа к файлу и поэтому гарантируется наличие в каждой записи уникального значения этого поля, оно называется ключом упорядочения для данного файла.
Для примера рассмотрим файл с кортежами, причем для простоты предположим, что на каждой странице находится по одной записи. Тогда упорядоченный файл будет выглядеть, как показано на рис. В.1. При этом процедура бинарного поиска будет включать следующие этапы.
Выборка средней страницы файла. Проверка наличия искомой записи между первой и последней записями на этой странице. Если это так, то выборка страниц прекращается, поскольку требуемая запись находится на данной странице.
2. Если значение ключевого поля в первой записи этой страницы больше, чем искомое значение, то искомая запись (если она существует) находится на одной из предыдущих страниц. Затем приведенная выше процедура поиска повторяется для левой половины обрабатываемой части файла. Если значение ключевого поля в последней записи страницы меньше, чем искомое значение, то искомое значение находится на последующих страницах. После этого указанная выше процедура поиска повторяется для правой половины обрабатываемой части файла. Таким образом, после каждой попытки извлечения страницы область поиска сокращается наполовину.

Рис.22.Бинарный поиск в упорядоченном файле
В данном случае средней является страница 3, но запись на этой странице (SG14) не является искомой (SG37). Значение ключевого поля записи на странице 3 меньше требуемого значения, поэтому вся левая половина файла исключается из области поиска. Теперь следует извлечь среднюю страницу из оставшейся части файла (его правой половины), т.е. страницу 5. На этот раз значение ключевого поля (SL21) больше искомого значения (SG37), что позволяет исключить из текущей области поиска ее правую половину. После извлечения средней страницы из оставшейся на данный момент части файла можно убедиться в том, что именно она и является искомой.
В общем случае бинарный поиск эффективнее линейного, однако этот метод чаще применяется для поиска данных в первичной, а не во вторичной памяти.
Операции вставки и удаления записей в отсортированном файле усложняются в связи с необходимостью поддерживать установленный порядок записей. Для вставки новой записи нужно определить ее расположение в указанном порядке, а затем найти свободное место для вставки. Если на нужной странице достаточно места для размещения новой записи, то потребуется переупорядочить записи только на этой странице, после чего вывести ее на диск. Если же свободного места недостаточно, то потребуется переместить одну или несколько записей на следующую страницу. На следующей странице также может не оказаться достаточно свободного места, и из нее потребуется переместить некоторые записи на следующую страницу и т.д.
Таким образом, вставка записи в начало большого файла может оказаться очень длительной процедурой. Для решения этой проблемы часто используется временный неотсортированный файл, который называется файлом переполнения (overflow file) или файлом транзакции (transaction file). При этом все операции вставки выполняются в файле переполнения, содержимое которого периодически .объединяется с основным отсортированным файлом. Следовательно, операции вставки выполняются более эффективно, но выполнение операций извлечения данных немного замедляется. Если запись не найдена во время бинарного поиска в отсортированном файле, то приходится выполнять линейный поиск в файле переполнения. И наоборот, при удалении записи необходимо реорганизовать файл, чтобы удалить пустующие места.
Упорядоченные файлы редко используются для хранения информации баз данных, за исключением тех случаев, когда для файла организуется первичный индекс.
Хешированные файлы
В хешировании файле записи не обязательно должны вводиться в файл последовательно. Вместо этого для вычисления адреса страницы, на которой должна находиться запись, используется хеш-функция (hash function), параметрами которой являются значения одного или нескольких полей этой записи. Подобное поле называется полем хеширования (hash field), а если поле является также ключевым полем файла, то оно называется хеш-ключом (hash key). Записи в хешированием файле распределены произвольным образом по всему доступному для файла пространству.. По этой причине копированные файлы иногда называют файлами с произвольным или прямым доступом (random file или direct file).
Хеш-функция выбирается таким образом, чтобы записи внутри файла были распределены наиболее равномерно. Один из методов создания хеш-функции называется сверткой (folding) и основан на выполнении некоторых арифметических действий над различными частями поля хеширования. При этом символьные строки преобразуются в целые числа с использованием некоторой кодировки (на основе расположения букв в алфавите или кодов символов ASCII). Например, можно преобразовать в целое число первые два символа поля табельного номера сотрудника (атрибут staffNo), а затем сложить полученное значение с остальными цифрами этого номера. Вычисленная сумма используется в качестве адреса дисковой страницы, на которой будет храниться данная запись. Более популярный альтернативный метод основан на хешировании с применением остатка от деления. В этом методе используется функция MOD, которой передается значение поля. Функция делит полученное значение на некоторое заранее заданное целое число, после чего остаток от деления используется в качестве адреса на диске.
Недостатком большинства хеш-функций является то, что они не гарантируют получение уникального адреса, поскольку количество возможных значений поля хеширования может быть гораздо больше количества адресов, доступных для записи. Каждый вычисленный хеш-функцией адрес соответствует некоторой странице, или сегменту (bucket), с несколькими ячейками (слотами), предназначенными для нескольких записей. В пределах одного сегмента записи размещаются в слотах в порядке поступления. Тот случай, когда один и тот же адрес генерируется для двух или более записей, называется конфликтом (collision), a подобные записи - синонимами. В этой ситуации новую запись необходимо вставить в другую позицию, поскольку место с вычисленным для нее хеш-адресом уже занято. Разрешение конфликтов усложняет сопровождение хеширо-ванных файлов и снижает общую производительность их работы.
Для разрешения конфликтов можно использовать следующие методы:
• открытая адресация;
• несвязанная область переполнения;
• связанная область переполнения;
• многократное хеширование.
Динамическое хеширование
Перечисленные выше методы хеширования являются статическими, в том смысле, что пространство хеш-адресов задается непосредственно при создании файла. Считается, что пространство файла уже насыщено, когда оно уже почти полностью заполнено и администратор базы данных вынужден реорганизовать его хеш-структуру. Для этого может потребоваться создать новый файл большего размера, выбрать новую хеш-функцию и переписать старый файл во вновь отведенное место. В альтернативном подходе, получившем название динамического хеширования, допускается динамическое изменение размера файла с целью его постоянной модификации в соответствии с уменьшением или увеличением размеров базы данных.
Основной принцип динамического хеширования заключается в обработке числа, выработанного хеш-функцией в виде последовательности битов, и распределении записей по сегментам на основе так называемой прогрессирующей оцифровки (progressive digitization) этой последовательности. Динамическая хеш-функция вырабатывает значения в широком диапазоне, а именно Jb-битовые двоичные целые числа, где Ь обычно равно 32. Рассмотрим кратко один тип динамического хеширования, который называется расширяемым хешированием.
Сегменты создаются по мере необходимости. Вначале записи добавляются только в первый сегмент, и так продолжается до тех пор, пока он не будет полностью заполнен. В этот момент сегмент расщепляется на части, количество которых зависит от числа i битов в хеш-значении, где о < ± < Ь. Эти биты, количество которых равно используются в качестве смещения в таблице адресов сегмента (Bucket Address Table - ВАТ) или в каталоге. Значение i изменяется в зависимости от размера базы данных. Каталог имеет заголовок, в котором хранится текущее значение i (называемое глубиной) вместе с 2Ч указателями. Аналогично, для каждого сегмента существует индикатор локальной глубины, который содержит значение i, используемое для определения адреса этого сегмента. На рис. В.5 приведен пример применения технологии расширяемого хеширования. Предполагается, что каждый сегмент имеет пространство для двух записей, .а хеш-функция предусматривает использование числовой части табельного номера сотрудника staffNo.
Если в результате удаления записей сегмент освобождается, он может быть удален вместе с его указателем в каталоге. В некоторых схемах возможно слияние малых сегментов и уменьшение вдвое размера самого каталога.

Рис.23. Пример использования технологии расширяемого хеширования: а) после вставки записей S1,21 и SG37; б) после вставки записи SG14; в) после вставки записи SA9
Ограничения, свойственные методу хеширования
Использование метода хеширования для извлечения записей основано на полностью известном значении хеш-поля. Поэтому, как правило, хеширование не подходит для операций извлечения данных по заданному образцу или диапазону значений. Например, для поиска значений хеш-поля в заданном диапазоне потребуется использовать хеш-функцию, сохраняющую упорядочение, другими словами, если rmin, и rmax являются минимальным и максимальным пределами диапазона, то потребуется такая хеш-функция для которой соблюдается неравенство h(rmin) < h(rmax). Более того, хеширование не подходит для поиска и извлечения данных по любому другому полю, отличному от поля хеширования. Например, если таблица Staff хранится как хешированная по полю staffNo, то такой хеширований файл не может быть использован для поиска записи по значению поля IName. В этом случае потребуется выполнить линейный поиск для поиска нужной записи или использовать поле IName в качестве вторичного индекса
Лекция 11
Использование индексации при организации файлов
Цель: научиться использовать индексацию при организации файлов.
Ключевые слова: индекс, типы индексов, индексно-последовательные файлы, вторичные индексы, многоуровневые индексы.
Литература. [4, 569-601; 5, 434-451]
Индекс. Структура данных, которая помогает СУБД быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей.
Индекс в базе данных аналогичен предметному указателю в книге. Это - вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге с предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. При использовании индексов в базе данных искомым объектом может быть одна или несколько записей файла. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения.
Хотя индексы, строго говоря, не являются обязательным компонентом СУБД, они могут существенным образом повысить ее производительность. Как и в случае с предметным указателем книги, читатель может найти определение интересующего его понятия, просмотрев всю книгу, но это потребует слишком много времени. А предметный указатель, ключевые слова в котором расположены в .алфавитном порядке, позволяют сразу же перейти на нужную страницу.
Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, - индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Типы индексов
Для ускорения доступа к данным применяется несколько типов индексов. Основные из них перечислены ниже.
• Первичный индекс. Файл данных последовательно упорядочивается по полю ключа упорядочения [см. раздел В.З), а на основе поля ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи.
• Индекс кластеризации. Файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации.
Вторичный индекс. Индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение.
Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов. Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс содержит индексные записи только для некоторых значений ключа поиска в данном файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в данном файле. Ключ поиска для индекса может состоять из нескольких полей. На рис. В.6 показаны четыре плотных индекса, которые определены на таблице Staff (здесь она приведена в сокращенном виде). Первый индекс основан на столбце salary, второй - на столбце branchNo, третий - на составном ключе (salary, branchNo), a четвертый - на составном ключе (branchNo, salary).
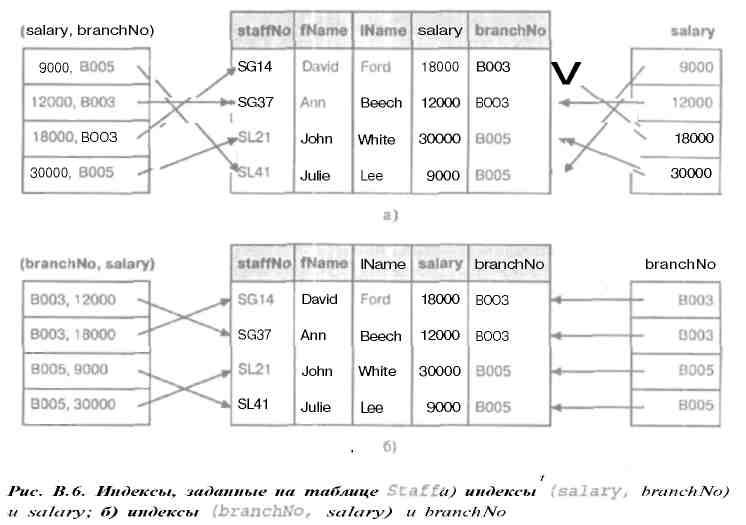
Рис.24.Индексы, заданные на таблице Staff а) индексы (salary, branchNo) и salary б) индексы (branchNo, salary) и branceNo
Индексно-последовательные файлы
Отсортированный файл данных с первичным индексом называется индексированным последовательным файлом, или индексно-последовательным файлом., Эта структура является компромиссом между файлами с полностью последовательной и полностью произвольной организацией. В таком файле записи могут обрабатываться как последовательно, так и выборочно, с произвольным доступом, осуществляемым на основе поиска по заданному значению ключа с использованием индекса. Индексированный последовательный файл имеет более универсальную структуру, которая обычно включает следующие компоненты:
• первичная область хранения;
• отдельный индекс или несколько индексов;
• область переполнения.
Подобная организация файлов используется в методе индексно-последовательного доступа (Indexed Sequential Access Method - ISAM), разработанном компанией IBM, который тесно связан с характеристиками используемого оборудования. Для поддержания высокой эффективности работы файлов такого типа их следует периодически подвергать реорганизации. Позже на базе метода доступа ISAM был разработан метод виртуального последовательного доступа (Virtual Sequential Access Method - VSAM), обладающий полной независимостью от особенностей аппаратного обеспечения. В нем не предусмотрено использование специальной области переполнения, но в области данных выделено пространство, предназначенное для расширения. По мере роста или сокращения; •размера файла этот процесс управляется динамически, без необходимости периодического выполнения реорганизации. На рис. 25, а показан пример плотного индекса для отсортированного файла с записями таблицы Staff. Но поскольку записи в файле данных отсортированы, размер индекса можно сократить и вместо плотного индекса использовать разреженный, пример которого показан на рис. 25, б.

Рис.25. Пример плотного и разреженного индексов