

Статистика / Дискриминантный анализ
.docПостановка задачи дискриминантного анализа
Пусть имеется n наблюдений, характеризующихся набором из к признаков. Тогда каждое наблюдение представляет собой случайный вектор x=(x1 x2 ...,xk )T. Задача дискриминации состоит в разбивке всего множества реализаций рассматриваемой многомерной величины на некоторое число групп (областей) Ri (i=1, 2, ...,l) и последующем отнесении нового наблюдения к одной из них, используя некое решающее правило. При этом информация об истинной принадлежности объекта считается недоступной или требует чрезмерных материальных и временных затрат.
Правило дискриминации выбирается в соответствии с определенным принципом оптимальности — минимизации средних потерь от неправильной классификации, исходя из априорных вероятностей рi извлечения объекта из группы Ri. Решающее правило считается наилучшим в определенном смысле слова, если никакое другое правило не может дать меньшей величины функции потерь.
Априорные вероятности могут быть известны заранее и заданы пользователем непосредственно при работе в модуле либо получены определенным образом (пропорционально объему групп, равные для всех групп). В качестве средних потерь чаще всего принимают вероятность ложной классификации наблюдения.
Построение решающего правила также можно рассматривать как задачу поиска / непересекающихся областей R... Дискриминантные функции в этом случае дают определение этих областей путем задания их границ в многомерном пространстве. В рассматриваемом модуле реализовано два направления проведения дискриминантного анализа: линейный и пошаговый. В первом случае в модель включаются все переменные и процедура аналогична построению множественной регрессии, где в качестве зависимой переменной выступает группа, а все остальные независимые; во втором — они проходят специальный отбор, то есть на каждом шаге просматриваются все переменные и находится та из них, которая вносит наибольший вклад в различие между совокупностями (она включается в модель в первую очередь), затем вторая и т.д. (пошаговый метод с включением). В анализе используется и обратная процедура: сначала включаются все переменные в модель, а затем на каждом шаге устраняют переменные, вносящие наименьший вклад в дискриминацию (пошаговый с исключением).
В ходе процедуры автоматически вычисляются функции классификации, предназначенные для определения той группы, к которой наиболее вероятно принадлежит новый объект. Количество функций классификации равно числу имеющихся групп. Наблюдение считается принадлежащим той группе (совокупности), для которой получено наивысшее значение функции классификации или наивысшее значение апостериорной вероятности (вероятности, с которой новое наблюдение принадлежит к этому классу, вычисленное на основе априорной вероятности и расстояния Махаланобиса).
Так же для каждого наблюдения можно вычислить расстояния Махаланобиса до центроидов имеющихся групп. В качестве центроида может быть взят вектор средних значений наблюдений группы. Наблюдение признается принадлежащим к той группе, к которой он ближе, т.е. когда расстояние Махаланобиса до нее минимально.
Более подробно описываемые процедуры будут рассмотрены в ходе знакомства с модулем Дискриминантный анализ.
Стартовая панель модуля Дискриминантный анализ.

Задание входных параметров
Для того чтобы войти в модуль Дискриминантный анализ, следует нажать на кнопку переключателя модулей и выбрать нужную строку. На экране появится стартовая панель:
Рассмотрим основные этапы проведения дискриминантного анализа в системе STATISTICA на следующем примере. На рисунке 6.2 приведена электронная таблица с данными условной классификации 12 стран мира по уровню медицинского обеспечения населения. Страны условно разбиты на три группы в соответствии с высоким, удовлетворительным и низким уровнем медицинского обеспечения на основе следующих показателей:
-
ВВП — ВВП, определенное на основе паритета покупательной способности, в % к США;
-
РАСХЗДРА — расходы на здравоохранение, в % к ВВП;
-
ЧИСВРАЧ — число врачей на 10 тыс. чел. населения;
-
СМЕРТНОС — смертность населения по причине болезней органов кровообращения на 100 тыс. чел. населения.
В первую группу с высоким уровнем медицинского обеспечения вошли промышленно развитые страны Запада: Австралия, Австрия, Бельгия, Великобритания, Германия. Вторую группу с удовлетворительным уровнем составили: Болгария, Венгрия, Белоруссия. Третья группа образована кавказскими и среднеазиатскими странами бывшего СССР: Армения, Азербайджан, Киргизия, Грузия «низкий» уровень)
Задача состоит в том, чтобы на основе аналогичных показателей классифицировать страны: Россию, Грецию, Данию и Казахстан.
Рассмотрим входные параметры стартовой панели модуля.
При проведении анализа прежде всего следует выбрать переменные. Зададим их с помощью кнопки Переменные. На экране откроется диалоговое окно, предлагающее выбрать группирующую перемененную и список независимых:
В нашем примере группирующей переменной является УРОМЕДОБ — уровень медицинского обеспечения, а независимыми — ВВП, РАСХЗДРА, ЧИСВРАЧ и СМЕРТНОС.
Кнопка Коды для группирующей переменной позволяет задать коды для каждой группы наблюдений. Обработка пропусков имеет два режима: игнорирование наблюдений, содержащих пропущенные данные в любой из переменных (пропущенные данные удаляются построчно), и замена пропущенных данных средними значениями по соответствующим показателям.
После настройки нужных параметров, нажав ОК, перейдем в следующее диалоговое окно Определение модели.
В окошке Метод можно выбрать один из трех методов анализа: стандартный, пошаговый с включением и пошаговый с исключением.
Если выбран Стандартный метод, то все выбранные переменные будут одновременно включены в модель.
В методе Пошаговый с включением на каждом шаге в модель выбирается переменная с наибольшим F-значением, при этом пользователь должен установить его минимальную величину. Процедура заканчивается, когда все переменные, имеющие F-значение больше значения, указанного в поле F-включить, вошли в модель.
Если выбран Пошаговый анализ с исключением, то в уравнение будут включены все выбранные пользователем независимые переменные, которые затем удаляются в зависимости от величины F-значения. Переменная с наименьшим значением исключается из модели первой. Шаги заканчиваются, когда нет переменных, имеющих F-значение меньше определенного пользователем в поле F-исключить. Заметим, что значение F-включить всегда должно быть больше, чем значение F-исключить.
Если при проведении анализа пользователь хочет включить все переменные, то следует установить в поле F-включить очень маленькую величину, например 0.0001, а в поле F-исключить — 0.0.
Если же требуется исключить все переменные, то в поле F-включить устанавливается большое значение, например 0.9999, а в F-исключить немногим меньшее значение того же порядка, например 9998.
Поле Число шагов определяет максимальное число шагов анализа, по достижении которых процедура закончится, даже если еще не все переменные прошли отбор на основе их F-значений.
Поле Толерантность позволяет исключить из модели неинформативные переменные. Значение толерантности вычисляется как 1 минус квадрат множестственного коэффициента корреляции переменной со всеми другими переменными в модели. Если i толерантность имеет значение меньшее, чем значение по умолчанию 0.01 (или установленное специально пользователем), то эта переменная признается неинформативной и не включается в модель, поскольку не несет дополнительной информации по сравнению с остальными переменными.
В отличие от стандартной для пошаговых процедур предусмотрено два режима вывода результатов анализа: на каждом шаге и на заключительном шаге. В первом случае программа выводит на экран диалоговое окно полных результатов на каждом шаге, начиная с нулевого.
Р ежим
на заключительном
шаге выводит
окно с результатами
только на последнем шаге, однако оно
содержит опцию для просмотра
основных итоговых статистик и для
пошаговой процедуры.
ежим
на заключительном
шаге выводит
окно с результатами
только на последнем шаге, однако оно
содержит опцию для просмотра
основных итоговых статистик и для
пошаговой процедуры.
Опция Корреляции, статистики и графики для групп вызывает на экран диалоговое окно Описательные статистики, которое дает пользователю возможность просмотреть средние значения, стандартные отклонения, дисперсии и корреляции используемых переменных.
Средние значения и стандартные отклонения можно посмотреть для всех групп вместе и для каждой группы. Кроме того, имеется возможность вычислить объединенные внутригрупповые или полные корреляции.
6.3. Анализ результатов Стандартного метода классификации
Рассмотрим результаты дискриминантного анализа, полученные с помощью установки Стандартный метод. В верхней информационной части окна содержатся основные параметры вычислительной процедуры: число переменных в модели, значение лямбды Уилкса (0,0015060), приближенное значение статистики F-критерия, соответствующее лямбде Уилкса, — F (8,12) = 37,15298 и рассчитанный для него уровень значимости (р<0,000).
Опция Переменные в модели выводит таблицу результатов, содержащую следующую статистику для переменных, присутствующих в модели.
Статистика лямбда Уилкса, принимающая значения в диапазоне от 0 до 1, служит для проверки качества дискриминации, Причем, чем ближе к 0, тем меньше вероятность ошибочного разделения. Значение статистики, равное 1, свидетельствует о “плохом” качестве модели.
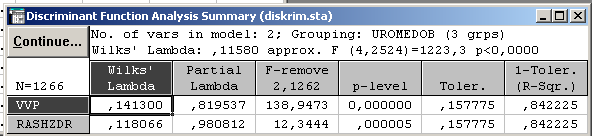
Опция Расстояния между группами выводит таблицу результатов, содержащую квадраты расстояний Махаланобиса между центроидами групп. Расстояние Махаланобиса отличается от Евклидова расстояния тем, что учитывает корреляции между Переменными. По таблице видно, что Венгрия, Болгария и Белоруссия по рассматриваемым показателям стоят ближе к
ранам с низким уровнем, чем к развитым странам; расстояния между ними — 33,2774 и 497,4671 соответственно.
Вместе с таблицей расстояний Махаланобиса выводятся две Другие: одна со значениями F-критерия, а другая — с соответствующими уровнями значимости (р-уровнями).

Дополнительно можно просмотреть результаты канонического анализа, нажав кнопку
Канонический анализ и графики,
если для анализа были выбраны, по крайней мере, три группы и есть хотя бы две переменные в модели.
В выводимом на экран окне опция Диаграмма рассеяния для значений строит график рассеяния канонических значений для канонических корней. С его помощью можно определить вклад, который вносит каждая дискриминантная функция в разделение между группами.
Определить принадлежность классифицируемых наблюдений к определенному классу можно, воспользовавшись опцией Функции классификации.
Таким образом, наблюдение приписывается к той группе, для которой оно имеет максимальное классификационное значение. Как и следовало ожидать, уровень медицинского обеспечения в Дании и Греции ближе к развитым европейским странам (они вошли в группу с высоким уровнем), а Россия и Казахстан попали в группу «низкий» уровень.
Следующая рассматриваемая опция Матрица классификации выводит информацию о количестве и проценте корректно классифицированных наблюдений в каждой группе.
После нажатия на кнопку Классификация наблюдений на экране появляются результаты классификации каждого наблюдения, используемого в анализе. Первый столбец таблицы показывает принадлежность наблюдения к группе, для которой апостериорная вероятность имеет наивысшее значение. Строки, помеченные звездочкой (*), соответствуют наблюдениям, которые не удалось классифицировать.
Кнопка Квадраты расстояний Махаланобиса выполняет функцию представления тех же результатов классификации, но только в другом виде:
Таблица содержит вычисленные квадраты расстояний Махаланобиса от наблюдений до центров тяжести групп. Наименьшее расстояние определяет групповую принадлежность наблюдения.
Рассмотрим следующую опцию — Апостериорные вероятности.
Апостериорная вероятность показывает рассчитанную на основе расстояния Махаланобиса вероятную принадлежность конкретного наблюдения к какому-либо классу. Апостериорную вероятность следует отличать от априорной. Под последней понимается вероятность отнесения наблюдения к какой-либо группе на основе экспериментальных данных. В системе STATISTICA имеются три способа задания априорной вероятности: пропорционально размерам групп, одинаковые для всех групп и заданные пользователем.
При выборе конкретного способа следует учесть, что априорные вероятности могут существенно повлиять на точность классификации. Если неодинаковое число наблюдений в различных группах является отражением истинного распределения в совокупности, то следует задать априорные вероятности пропорциональными объемам групп. Если же это только случайный результат процедуры отбора, то положить априорные вероятности одинаковыми для каждой группы.
Апостериорные вероятности определяются исходя из априорных и расстояний Махаланобиса. Их практическое назначение состоит в том, чтобы отнести наблюдение к конкретной группе, для которой они имеют максимальное значение. Действительно, чем дальше наблюдение расположено от центра группы, тем менее вероятно, что наблюдение принадлежит к ней.
Значение апостериорной вероятности равное 1 говорит о том, что наблюдение с вероятностью 100% принадлежит к этому классу. В нашем случае для ряда стран получены ненулевые значения вероятностей принадлежности одновременно к нескольким группам, например Болгария с вероятностью 0,999989 относится к группе с удовлетворительным значением и с 0,000011 — к группе с низким. Конечно, эти величины несравнимы и можно утверждать, что получено высокое качество классификации, однако для других задач это может быть и не так.
Результаты проведенной классификации для каждого наблюдения, квадраты расстояний Махаланобиса и апостериорные вероятности можно сохранить с помощью опции Сохранить классификации/расстояния/вероятности. Ниже приводится диалоговое окно параметров сохранения:
Пошаговые методы дискриминантного анализа
Выше мы рассмотрели стандартную процедуру проведения дискриминантного анализа. Теперь обратимся к пошаговым методам. Надо сказать, что если классификация осуществлена методически верно, то оба метода дают одинаковые конечные результаты.
Зададим в диалоговом окне Определение модели метод анализа Пошаговый с исключением, а в окошке Вывод результатов — На каждом шаге.
После нажатия ОК на экран компьютера будет выведена таблица результатов на нулевом шаге процедуры. Перейти к следующему шагу можно с помощью кнопки Далее. Эта кнопка появляется в таблице результатов, только если пользователь находится в пошаговом анализе и запросил вывод результатов На каждом шаге. Кроме того, стала активной опция Переменные вне модели, которая выводит таблицу результатов, содержащую суммарную статистику для всех переменных, в настоящий момент не присутствующих в модели.
Рассмотрим классификационные функции на заключительном шаге.
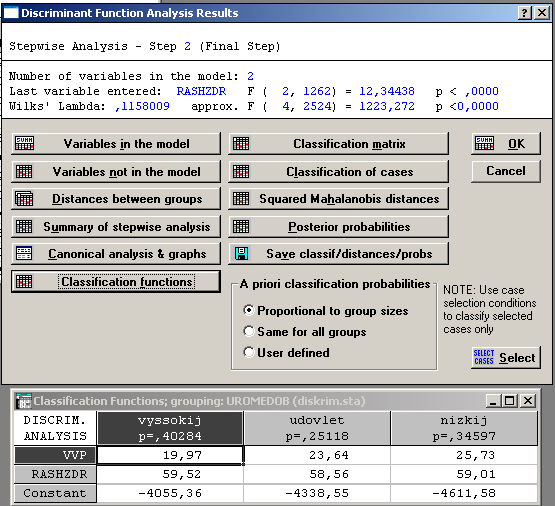
Как видим, они отличаются от полученных с помощью стандартной процедуры: из модели исключены переменные, характеризующие численность врачей и смертность.
Выполнив классификацию новых наблюдений с помощью разных опций, удостоверимся в том, что их классовая принадлежность не изменилась. Следовательно, результаты можно принять как окончательные.