

Розділ 1 аналіз гібридних інтелектуальних систем
1.1. Аналіз та порівняльні дослідження методів та підходів для вирішення задач інтелектуального аналізу даних
Більшість підприємств накопичують під час своєї діяльності величезні обсяги даних, але єдине, що вони хочуть від них одержати – це корисна інформація. Звичайно ж, підприємство, що довго знаходиться на ринку і знає своїх клієнтів вже інформована про багато моделей, які спостерігалися протягом декількох останніх періодів. Технології інтелектуального аналізу можуть не тільки підтвердити ці емпіричні спостереження, але і знайти нові, невідомі раніше моделі. Спочатку це може дати користувачеві лише невелику перевагу. Але така перевага, якщо її об’єднати по кожному товару і кожному клієнту, дає істотний відрив від тих, хто не використовує технології Data Mining. З іншого боку, за допомогою методів data mining можна знайти таку модель, що приведе до значного поліпшення у фінансовому і ринковому становищі організації.
Дану проблематику досліджувати такі вчені як: В. Д. Дербенцев, Д. Є. Семьонов та О.Д. Шарапов, зокрема, розглядали основні етапи, характерні для будь-якого дослідження за допомогою методів виявлення знань у базах даних.
Як справедливо відмічають ці автори, «Залежно від задачі кількість етапів, а також обсяг виконуваних на кожному з них дій, можуть змінюватися, але загалом вони необхідні і так чи інакше належать до процесу інтелектуального аналізу даних» [66, с. 64-65]. На наш погляд, схема інтелектуального аналізу практично не відрізняється від звичайної схеми використання
Інформаційно-аналітичне забезпечення підприємницької діяльності інформаційних потоків у розробці проектів і прийнятті ефективних управлінських рішень.
Питання в іншому – у використовуваній при цьому інформації та методах її дослідження.
При цьому не слід підміняти інтелектуальний аналіз звичайним розрахунком економічних показників. При використанні класичних інструментів показники, які підлягають аналізу, мають бути визначені попередньо. Однак звичайні звіти не розраховані на пошук нетрадиційних правил чи нелогічних закономірностей – тобто на генерацію нових знань.
Для вирішення зазначених завдань і призначена система інтелектуального аналізу даних (Business Intelligence), яка повинна допомагати користувачам корпоративної інформаційної системи на основі автоматизованого перетворення даних знаходити швидкі відповіді на нетрадиційні питання, моделювати виходи із нетрадиційних ситуацій.
На українському ринку технології інтелектуальних обчислень роблять лише перші кроки. Це можна пояснити їх високою вартістю, але, як показує історія розвитку інших галузей комп’ютерного ринку України, сам по собі цей фактор навряд чи є визначальним. Скоріше тут виявляється дія деяких специфічних для України негативних чинників, що різко зменшують ефективність застосування аналітичних технологій. Постараємося визначити ці фактори, проаналізувати ступінь притаманних їм різних класів систем інтелектуального аналізу даних та обчислень, а також виділити властивості таких систем, що полегшують українським покупцям їхнє застосування.
Засоби інтелектуальних обчислень знаходження нового знання та аналізу даних припускають надання допомоги організаціям у знаходженні прихованих залежностей у даних. Однак, засоби інтелектуальних обчислень не можуть працювати без супроводу користувачів, що добре розуміють ділову область, самі дані і загальний характер використовуваних аналітичних методів. Результат застосування методів знаходження нового знання може виявлятися в широкому спектрі, від збільшення доходів, до зменшення витрат.
Підприємці зазначають, що засоби інтелектуальних обчислень – це реальний спосіб підвищення ефективності роботи. Питання не в тому, чи потрібні нові технології, а в тому, як їх застосувати в кожному конкретному випадку. Витрати на постановку задачі і супровід інтелектуальних систем можуть на порядок перевищувати вартість окремого пакета програм. Очевидно, що варто витратити частину грошей на навчання фахівців – у підсумку вийде дешевше й ефективніше. Зростає роль спеціалізованих консалтингових фірм, що здійснюють комплексний супровід проектів, включаючи діагностику задачі, аналіз методів рішення, вироблення рекомендацій, реалізацію обраного підходу, супровід, оптимізацію.
Великий обсяг інформації з однієї сторони, дозволяє отримати більш точні розрахунки та аналіз, з іншої – перетворює пошук рішення в складне завдання. В результаті з’явився цілий клас систем, які дозволяють виконати аналіз всього обсягу інформації та спростити процес прийняття рішення. Такі системи називають системами підтримки прийняття рішень. Основне завдання систем підтримки прийняття рішень – надати аналітикам інструмент для виконання аналізу даних. З однієї сторони, якість прийнятих рішень залежить від класифікації аналітика, з іншої – зростання об’ємів даних, висока швидкість обробки та аналізу, а також складність використання форми представлення даних стимулює до створення інтелектуальних систем. Таким чином, загальна архітектура системи підтримки прийняття рішень (СППР) може бути зображена наступним чином (рис. 1.1).

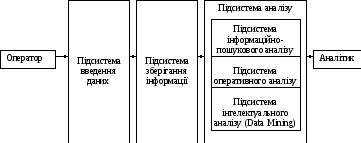
Рис. 1.1. Загальна архітектура системи підтримки прийняття рішень
Таким чином, підсистема інтелектуального аналізу даних, є однією зі складових, що дозволяє виконувати пошук функціональних та логічних закономірностей в накопичуваних даних.
Складність і різноманітність методів Data Mining вимагають створення спеціалізованих засобів для вирішення типових завдань аналізу інформації в конкретних галузях. Оскільки ці засоби використовуються в складі складних багатофункціональних систем підтримки прийняття рішень, вони повинні легко інтегруватися в подібні системи.
D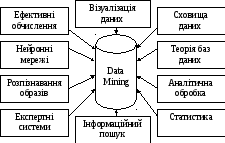 ata
Mining є мультидисциплінарною галуззю, що
виникла і розвивається на базі досягнень
прикладної статистики, розпізнавання
образів, методів штучного інтелекту,
теорії баз даних тощо (рис. 1.2), тобто
методи Data Mining знаходяться на стику
різних напрямків інформаційних
технологій.
ata
Mining є мультидисциплінарною галуззю, що
виникла і розвивається на базі досягнень
прикладної статистики, розпізнавання
образів, методів штучного інтелекту,
теорії баз даних тощо (рис. 1.2), тобто
методи Data Mining знаходяться на стику
різних напрямків інформаційних
технологій.
Рис. 1. 2. Мультидисциплінарна галузь Data Mining
Саме тому, існує така велика кількість методів і алгоритмів, реалізованих у різних системах Data Mining [12 – 14]. Багато з таких систем інтегрують в собі відразу кілька підходів. Інтеграція таких підходів і називається гібридними інтелектуальними системами.
Різні методи Data Mining характеризуються певними властивостями, які можуть бути визначальними при виборі методу аналізу даних. Методи можна порівнювати між собою, оцінюючи характеристики їх властивостей.
Серед основних властивостей і характеристик методів Data Mining розглянемо наступні: точність, масштабованість, інтерпретованість, перевірюваність, трудомісткість, гнучкість, швидкість і популярність.
Масштабованість – властивість обчислювальної системи, яка забезпечує передбачуване зростання системних характеристик, наприклад, швидкості реакції, загальної продуктивності та ін., при додаванні до неї обчислювальних ресурсів.
У додатку А подано порівняльну характеристику деяких поширених методів, що мають свої сильні і слабкі сторони, але жоден метод, яким би не була його оцінка з точки зору властивих йому характеристик, не може забезпечити вирішення усіх завдань Data Mining.
З появою і ускладненням інтелектуальних систем очевидну значущість мають підходи до побудови систем з використанням, так званих шарів (рівнів). Багаторівневий підхід – це модель взаємодії, в якій набір інтелектуальних систем або їх складових компонентів взаємодіє і обмінюється знаннями в деякому внутрішньому представленні.
Також важливу роль відграє концепція рівнів це – одна з моделей, що використовуються для розділення складних систем, на більш прості частини. При такому підході виділяють верхній рівень, що описує систему в цілому, під ним розташовується більш низький рівень, на якому робиться опис, використовуваний верхнім рівнем. Таким чином, якщо дивитися знизу вгору, то виходить, що кожен рівень, що знаходиться нижче забезпечує функціональність, яку використовує вище розміщений для забезпечення методів більш високого рівня.
Розподіл системи на рівні надає цілий ряд переваг:
– окремий рівень можна сприймати як єдине самодостатнє ціле, яке не залежить від наявності інших рівнів;
– можливий вибір альтернативної реалізації базового рівня;
– залежність між рівнями зводитися до мінімуму;
– створений рівень може служити основою для кількох різних рівнів.
Схема розподілу володіє і певними недоліками:
– рівні здатні вдало інкапсулюватися, проте існують обмеження (модифікація одного рівня пов’язана з необхідністю внесення каскадних змін до інших рівнів);
– наявність надлишкових рівнів нерідко знижує продуктивність системи. При переході з рівня на рівень модельовані сутності зазвичай піддаються перетворенням з одного подання до іншого. Незважаючи на це, інкапсуляція нижчих функцій часто дозволяє досягти досить істотної переваги.
Проте найважче при використанні рівнів – це визначення вмісту та меж відповідальності кожного рівня.
Побудова структури гібридної інтелектуальної системи (ГІС) пов’язана в першу чергу з побудовою моделі системи, в якій повинні бути визначені як традиційні елементи системи, так і моделі обробки знань, що реалізуються інтелектуальною системою. В інтелектуальній системі новими елементами в порівнянні з традиційною системою є всі інтелектуальні перетворення або елементи управління знаннями, які пов’язані з реалізацією штучного інтелекту, тобто з використанням технологій експертних систем, бази знань, прийняття рішень, асоціативної пам’яті, нечіткої логіки.
Отже, складність і різноманітність існуючих методологій софт-інженерії стають непридатними у вирішенні актуальних комплексних питань з багатьма компонентами та підзадачами, кожна з яких потребує різних типів процедур. Сьогодення потребує від нас інших програмних продуктів: стійких, гнучких, розподілених, відкритих систем.