

ГОСЫ / Bilety
.pdfЭто значит, что алгоритм содержит возможность выполнять одновременно несколько одинаковых или различных операций, если вычислительная система состоит из множества процессоров, которые одновременно могут выполнять хотя бы одну операцию. Процессоры могут взаимодействовать между собой, вычислительные операции внутри каждого процесса выполняется последовательно.
В качестве примеров рассмотрим распараллеливание простых алгоритмов.
Пример 1. Поэлементное сложение векторов - функция axpy(Z, a, X, Y) выполняет следующее действие: Z = a*X+Y, где a – скаляр с плавающей точкой, X, Y и Z – векторы размера n. Для получения результата можно разработать параллельный алгоритм, в котором вычисления выполняются над распределенными по процессам частями векторов X, Y и Z.
Рассмотрим понятие полной параллельности на примере функции axpy(Z, a, X, Y). Очевидно, эта функция может быть выполнена на p-процессорах абсолютно параллельно, если каждый процесс будет иметь в своей памяти соответствующую компоненту векторов X, Y и результирующего вектора Z.
В случае Р<n (число процессов меньше длины векторов), можно сгруппировать компоненты векторов так, чтобы на каждом процессе оказалось k Pn компонент векторов (для простоты
предполагаем, что n – кратно P). Тогда, выполняя вычисления k компонент на каждом процессе, мы получим ускорение в Р раз. В общем случае ускорение на P-процессорной ЭВМ составит min(P,n).
Идентичность результата этой функции. Здесь обратим внимание, на то, что при параллельном выполнении функции результат будет точно таким же, как и при её последовательном исполнении
(т.е. при P=1).
Пример 2. Скалярное произведение векторов - функция vecvec_dot (a, X, Y) выполняет следующее действие a = X*Y где a – скаляр и X и Y – векторы размера n..
n 1
По определению скалярного произведения – это ( X iYi ) X 0Y0 X1Y1 ... X n 1Yn 1 . Предположим,
i 0
что компоненты векторов распределены по n процессам и результатом (значением а) должен обладать, только 0 процесс, в отличие от примера 1, где результат хранится как распределенный вектор Z на каждом процессе.
Распараллелить вычисление этой функции можно выполнив независимо |
k |
n |
операций |
|
P |
||||
|
|
|
умножения с соответствующим сложением во временные переменные tmp_a, на каждом процессе. Потом, соответственно, просуммировать эти k временных переменных для получения окончательного результата на процессе 0.
Неполная параллельность этой функции.
Этот алгоритм также распараллеливаем, но уже не является абсолютно параллельным. Т.к. для получения конечного результата необходимо выполнить еще одну операцию - сложение промежуточных результатов на нулевом процессе.
Отсюда следуют следующие два свойства параллельных алгоритмов.
Свойство 4 – параллельные алгоритмы включают издержки, связанные с распространением информации, обусловленные сбором некоторых данных на одном процессе, либо обмен данными между несколькими или всеми процессами.
Свойство 5 – незначительное отличие численного результата у последовательного и
параллельного алгоритмов.
Это связано с чувствительностью к порядку выполнения арифметических операций и, возможно, различным порядком вычислений над плавающими числами в последовательном и параллельном алгоритмах. Например, выполняя арифметические операции в последовательном режиме на одном
91
процессоре и в параллельном варианте на множестве процессоров, получим разные результаты. Поскольку при записи в 64-х разрядную переменную (ячейку памяти), происходит потеря части значения результата, расположенного на сумматоре (процессорный регистр, в который заносится результат арифметической операции), из-за того, что сумматор современных процессоров длиннее и составляет 80 разрядов. При распараллеливании нам приходится использовать несколько процессоров, а следовательно несколько сумматоров. Дополнительно нам придется обмениваться данными, а это возможно только через явную передачу значений ячеек памяти, поэтому значения, полученные каждым отдельным процессором теряют свою точность. При дальнейшем суммировании этих частичных сумм каким-либо из процессоров, также возможна потеря точности результата, в отличие от чисто последовательного порядка вычислений одним процессором.
Общие особенности выбора способов распараллеливания.
Во-первых, для ускорения счета часто разрабатывается другой параллельный алгоритм, эквивалентный исходному последовательному аналогу только по конечному результату вычислений.
Во-вторых, не всегда высоко параллельный алгоритм, столь же экономичен, чем менее параллельный, иногда последовательный алгоритм выполняется быстрее параллельного.
Итог. Параллельный алгоритм, сложность которого растет пропорционально увеличению числа задействованных процессоров, бессмыслен.
92
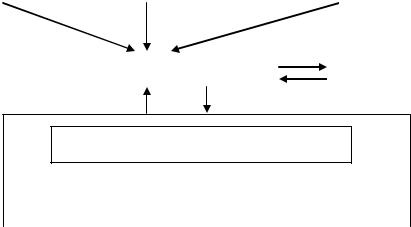
7. Планирование выполнения заданий. Общая схема параллельных вычислений при обслуживании потока заявок.
Задачей систем запуска является обеспечить планирование выполнения заданий, т.е. создание очереди заданий с последующим их запуском на исполнение по определенным критериям и сохранение результата выполнения каждого задания. Система запуска заданий имеет определенный набор команд, позволяющих выполнять запуск задания (постановку задачи в очередь), задать путь (определить каталог) для записи выходных файлов ошибок и выходной информации выполнения задачи. Получить информацию о текущем состоянии задачи, удалить задачу из очереди, получить информацию о конфигурации ВС и ее загрузке, т.е. увидеть занятые и свободные вычислительные узлы.
Постановка в очередь заданий осуществляется автоматически при выполнении пользователем необходимой команды. Если задание поставлено в очередь пользователю возвращается информация об уникальном номере задачи в очереди (идентификатор задачи), который присваивается системой запуска. Используя идентификатор, задание можно удалить из очереди, получить информацию о его текущем состоянии и т.д.
Критериями выбора заданий из очереди и их исполнения являются:
1)наличие свободных узлов, количество которых не меньше указанного для выполнения задачи,
2)при равных условиях по количеству заданных узлов, приоритетной считается задача с меньшим заданным временем исполнения,
3)если все критерии у задач равны, то выбирается первая из очереди. Поставленное в очередь задание может иметь наивысший приоритет, в этом случае оно будет исполнено сразу после появления достаточного количества свободных вычислительных узлов.
Прежде чем отправить задачу на ВС для выполнения необходимо сформировать заявку. Заявка – это текстовый файл, который содержит набор макроинструкций, которые определяют требуемые для решения задачи ресурсы. Обязательными являются
1)max время выполнения задачи (процессорное время), по истечении которого задача будет удалена и процесс решения прекращен, не зависимо от того, решена задача или нет. 2) объем требуемой оперативной памяти на узле. Каждый вычислительный узел состоит из нескольких процессоров, с определенным объемом оперативной памяти. Задача может использовать всю совокупную ОП на выделенном для нее узле или ее часть.
3)задание конфигурации использования вычислительного узла. Обычно эта информация задается в следующем виде: кол-во узлов : кол-во процессоров на узле.
Будем рассматривать ВС кластерного типа с поддержкой удаленного доступа от множества терминальных устройств локальной сети (рабочих мест), с которых в ВС поступают заявки на решение одной или более задач. Кроме того, на ВС могут выполняться фоновые задачи, например задачи функционирования ОС.
Каждая кластерная ВС состоит из управляющего (инструментального) сервера и вычислительных мультипроцессорных узлов. Запуск задания выполняет управляющий сервер, на котором и установлена система запуска заданий. Современные ВС имеют смонтированную (присоединенную) файловую систему очень большого объема, расположенную на отдельном файловом сервере. Как правило, ресурсы файловой системы распределены между пользователями и таким образом ограничены. Но их вполне достаточно для выполнения расчетных работ.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
терминалы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
заявки |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Инструментальный сервер |
|
|
|
|
Очередь заявок |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Вычислительный узел 1 (процессоры) 93

Вычислительный узел 2 (процессоры)
….
Вычислительный узел N (процессоры)
Инструментальный (управляющий) сервер содержит компиляторы и интерпретаторы языков программирования, сервисные программы, документацию и т.д.
На нем выполняется трансляция и получение исполняемого кода параллельных программ, формирование файла-задания на исполнение программы, запуск и постановка в очередь заданий и выполнение задания по запрошенным ресурсам, т.е. решение задачи.
Рассмотрим в общих чертах, как происходит выборка заданий из очереди. Выполняет эту функцию программа диспетчер очереди заданий.
Диспетчер активизируется при наступлении одного из трех событий:
1.по признаку "конец задания",
2.по признаку "процессор свободен" и
3.по прерыванию в моменты времени kτ, k = 0, 1, 2 ....
Признак "конец задания" возникает в случае окончания выполнения каждого задания, занимающего процессоры.
Признак "процессор свободен" возникает в случае, когда выполнение задания на данном процессоре, прервано внешним прерыванием.
При входе в диспетчер, проверяется, наступил ли момент времени kτ, k = 0, 1, ....
для переконфигурации ВС в плане определения свободных узлов. Если время наступило, то выполняется переконфигурация. Если время не наступило, то проверяется, произведено ли включение диспетчера по признакам "конец задания" или "процессор свободен". Если на данном процессоре выполнялось задание, и его выполнение было приостановлено (по разным причинам, например, обработка более приоритетного процесса ОС), то производится восстановление задания и процесс его выполнения продолжается. Если ранее прерванных заданий нет, а это признак "конец задания", то идет обращение к очереди заданий с выборкой очередного задания на исполнения.
Очевидно, что одновременно обратиться к очереди заданий может только один процессор, поэтому при каждом обращении проверяется, есть ли блокировка обращения к очереди в результате выполнения диспетчера на других процессорах. Если такая блокировка установлена, то диспетчер на данном процессоре находится в режиме ожидания, циклически проверяя, установлен ли признак блокировки обращения к очереди. При отсутствии признака блокировки, она устанавливается.
Если задание завершилось и процессор свободен, то при наличии заданий в очереди на процессор поступает новое задание, исходя из рассмотренных нами критериев. Выполненное задание исключается из списка выполняемых на данном процессоре. Новое задание, выбранное для исполнения, заносится в список выполняемых заданий. Снимается блокировка обращения к очереди, и если процессор свободен, то начинается выполнение задания. В противном случае продолжается циклическое обращение к диспетчеру до получения готовых к выполнению заданий.
94
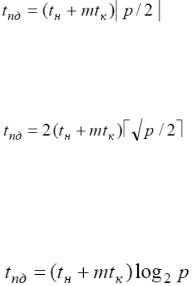
9. Анализ трудоемкости основных операций передачи данных на примере выполнения парных межпроцессорных обменов и коллективной операции широковещательной передачи данных.
1) Передача неделимых данных от одного процессора всем остальным процессорам сети
Операция передачи данных от одного процесса всем является одним из наиболее часто выполняемых коммуникационных действий. В зависимости от объема данных процессы могут выполнять передачу неделимых (атомарных) блоков информации или передачу в виде пакета блоков. Рассмотрим временные характеристики выполнения широковещательной передачи данных для неделимых блоков и пакета блоков на примере некоторых топологий сети.
Обозначим через
m - объем передаваемых данных в некоторых единицах, например в байтах, р - количество процессоров,
tн - время начальной подготовки сообщения для передачи, который включает поиск маршрута в сети, формирование буфера передачи и т.д.;
tс - время передачи служебных данных между двумя соседними процессорами (т.е. для
процессоров, между которыми имеется физический канал передачи данных); к служебным данным может относиться заголовок сообщения, информацию для обнаружения ошибок передачи и т.д.;
tк - время передачи единицы данных по одному каналу передачи, длительность подобной передачи определяется пропускной способностью сети.
Передача сообщений для кольцевой топологии Процессор-источник рассылки может передать данных сразу двум своим соседям, которые, в свою очередь, приняв сообщение, организуют пересылку далее по кольцу. Время выполнения рассылки в этом случае будет определяться как
Для топологии решетки-тора, рассылка может быть выполнена в 2 этапа. На первом этапе выполняется передача сообщения всем процессорам сети, располагающимся на той же горизонтали решетки, что и процессор-источник; на втором этапе процессоры, получившие копию данных, рассылают сообщения по своим соответствующим вертикалям. Время выполнения рассылки в этом случае будет определяться как
Для гиперкуба рассылка может быть выполнена в N- этапной процедуры передачи. На первом этапе процессор-источник передает данные одному из своих соседей (например, по первой размерности) – в результате после первого этапа имеется два процессора, имеющих копию пересылаемых данных. На втором этапе два процессора, получившие данные, пересылают сообщение своим соседям по второй размерности и т.д. Время выполнения рассылки в этом случае будет определяться как
Лучшие показатели имеет топология типа гиперкуба.
2) Передача пакетов данных от одного процессора всем остальным процессорам сети
Для топологии кольца алгоритм рассылки может быть получен путем логического представления кольцевой структуры сети в виде гиперкуба. На первом этапе, процессор-источник сообщения передает данные процессору, находящемуся на расстоянии p/2 от исходного процессора. На втором этапе оба процессора, уже имеющие рассылаемые данные после первого этапа, передают сообщения процессорам, находящиеся на расстоянии p/4 и т.д. Время выполнения рассылки в этом случае будет определяться как
95
(при достаточно больших сообщениях, временем передачи служебных данных можно пренебречь).
Для топологии решетки-тора алгоритм рассылки аналогичен методу передачи неделимых сообщений. Время выполнения рассылки в этом случае будет определяться как
Для гиперкуба алгоритм рассылки алгоритм рассылки также аналогичен методу передачи неделимых сообщений.
3) Передача неделимых данных от всех процессоров всем процессорам сети
Операция передачи данных от всех процессоров всем процессорам сети (allgather, broadcast) является обобщением двухточечной операции передачи. Подобные операции широко используются при реализации матричных вычислений.
Множественную рассылку можно реализовать выполнением соответствующего набора двухточечных операций. Однако это не оптимальный подход для многих топологий сети, поскольку часть операций двухточечных передачи может быть выполнена параллельно.
При выполнении передачи сообщений для кольцевой топологии каждый процессор может выполнять рассылку своего сообщения одновременно (в выбранном направлении по кольцу). В любой момент времени каждый процессор выполняет прием и передачу данных; завершение операции множественной рассылки произойдет через (p-1) цикл передачи данных. Время выполнения операции рассылки равно:
Для топологии типа решетки-тора множественная рассылка сообщений может быть выполнена обобщением алгоритма, передачи данных для кольцевой структуры сети по следующей схеме. На первом этапе выполняется передача сообщений раздельно по всем процессорам сети, располагающимся на одних и тех же горизонталях решетки (в результате на каждом процессоре
одной и той же горизонтали формируются укрупненные сообщения размера 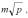 , объединяющие все сообщения горизонтали). Время выполнения этапа
, объединяющие все сообщения горизонтали). Время выполнения этапа
На втором этапе рассылка данных выполняется по процессорам сети, образующим вертикали решетки. Длительность этого этапа
Общая длительность операции рассылки определяется соотношением:
Для гиперкуба алгоритм множественной рассылки сообщений может быть получен путем обобщения алгоритма передачи данных для топологии типа реше тки на размерность гиперкуба N. В этом случае, схема коммуникации состоит в следующем. На каждом этапе i, 1≤ i≤N, выполнения алгоритма используются все процессоры сети, которые обмениваются своими данными со своими соседями по i размерности и формируют объединенные сообщения. Время операции рассылки может быть получено при помощи выражения
4) Передача пакетов данных от всех процессоров всем процессорам сети.
Применение более эффективного для кольцевой структуры и топологии решетки-тора метода передачи данных не приводит к улучшению времени выполнения операции множественной рассылки, поскольку обобщение алгоритмов выполнения операции двухточечных обменов на
96
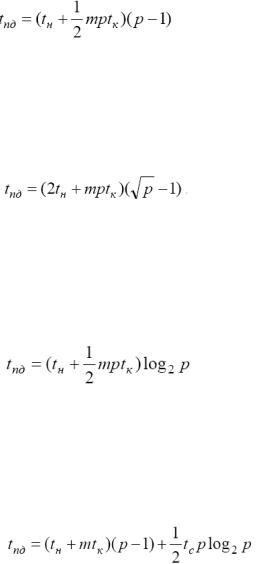
случай множественной рассылки приводит к перегрузке каналов передачи данных (т.е. к существованию ситуаций, когда в один и тот же момент времени для передачи по одной и той линии передачи имеется несколько ожидающих пересылки пакетов данных). Перегрузка каналов приводит к задержкам при пересылках данных, что и не позволяет проявиться всем преимуществам метода передачи пакетов.
Анализ трудоемкости основных операций межпроцессорных обменов на примере выполнения коллективных операций передачи данных по схеме “от всех – всем” с рассмотрением обобщенного варианта.
Обобщенная передача данных (all to all) от всех процессоров всем процессорам сети представляет собой общий случай коммуникационных действий. Необходимость в выполнении подобных операций возникает в параллельных алгоритмах быстрого преобразования Фурье, транспонирования матриц и др.
Рассмотрим способы выполнения обобщенной множественной рассылки для разных методов передачи данных.
1) Передача неделимых сообщений.
Для кольцевой топологии каждый процессор выполняет передачу исходных сообщений своему соседу (в выбранном направлении по кольцу). Затем процессоры выполняют прием пришедших к ним данных, где среди принятой информации выбирают свои сообщения, после чего выполняет дальнейшую рассылку оставшейся части данных. В этом случае время выполнения передач данных равна:
Для топологии решетки-тора на первом этапе выполняется передача сообщений раздельно по всем процессорам сети на одной горизонтали решетки, при этом каждому процессору по горизонтали передаются только те исходные сообщения, что должны быть направлены процессорам соответствующей вертикали решетки. В результате, на каждом процессоре собираются p сообщений, предназначенных для рассылки по одной из вертикалей решетки. На втором этапе передача данных выполняется по процессорам вертикали решетки. Время выполнения передач данных равно:
Для гиперкуба алгоритм передачи сообщений можно рассматривать как обобщение выполнения передачи данных для топологии решетки на размерность гиперкуба N. Здесь схема коммуникации состоит в следующем. На каждом этапе i, 1≤i≤N, выполнения алгоритма все процессоры сети, обмениваются своими данными с соседними по i размерности процессорами и формируют объединенные сообщения. При этом, каждый процессор такой пары посылает только те сообщения, которые предназначены для соседних процессоров.
Время выполнения передач данных равна:
2) Передача пакетов.
Использование метода передачи пакетов не приводит к улучшению временных характеристик для операции обобщенной передачи данных. Например, для топологии гиперкуб передача может быть выполнена за p-1 последовательных итераций. На каждой итерации все процессоры разбиваются на взаимодействующие пары процессоров. Разбиение на пары может быть выполнено таким образом, чтобы передаваемые между разными парами процессоров сообщения не использовали одни и те же пути передачи данных. В этом случае время выполнения передач данных равно:
Оценка трудоемкости операций передачи данных для кластерных систем
97

Топология кластерных вычислительных систем представляет собой полный граф, в котором, имеются определенные ограничения на одновременность выполнения коммуникационных операций. Например, при использовании концентраторов передача данных одновременно может выполняться только между двумя процессорными узлами; переключатели могут обеспечивать взаимодействие нескольких непересекающихся пар процессоров.
В кластерных системах в качестве основного способа выполнения коммуникационных операций используется метод передачи пакетов (реализуемый, как правило, на основе протокола TCP/IP).
1. Для кластерной системы с топологией в виде полного графа и пакетным способом передачи сообщений, трудоемкость операции коммуникации между двумя процессорными узлами равна (модель А)
оценка подобного вида следует из соотношений для метода передачи пакетов при единичной длине пути передачи данных, т.е. при l = 1. Это модель, в которой предполагается, что время подготовки
данных 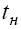 - постоянно (не зависит от объема передаваемых данных), время передачи служебных
- постоянно (не зависит от объема передаваемых данных), время передачи служебных
данных  не зависит от количества передаваемых пакетов и т.п.
не зависит от количества передаваемых пакетов и т.п.
Однако эти предположения не соответствуют действительности и временные оценки, получаемые в результате использования модели, могут не обладать необходимой точностью.
2. Поэтому более точная формула будет иметь следующий вид (модель В):
,
где  - количество пакетов, на которое разбивается передаваемое сообщение, величина
- количество пакетов, на которое разбивается передаваемое сообщение, величина 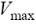 определяет максимальный размер пакета, который может быть передан по сети (по
определяет максимальный размер пакета, который может быть передан по сети (по
умолчанию для операционной системы MS Windows в сети Fast Ethernet =1500 байт), а 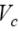 - объем служебных данных в каждом из пересылаемых пакетов (для протокола TCP/IP, ОС Windows 2000 и
- объем служебных данных в каждом из пересылаемых пакетов (для протокола TCP/IP, ОС Windows 2000 и
сети Fast Ethernet =78 байт). Величина |
характеризует |
аппаратную составляющую |
|
латентности и зависит от параметров используемого сетевого оборудования, значение |
задает |
||
время подготовки одного байта данных для |
передачи по |
сети. Величина |
латентности |
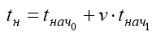 увеличивается линейно в зависимости от объема передаваемых данных. При этом предполагается, что подготовка данных для передачи второго и всех последующих пакетов может быть совмещена с пересылкой по сети предшествующих пакетов и латентность, тем самым, не может превышать величины
увеличивается линейно в зависимости от объема передаваемых данных. При этом предполагается, что подготовка данных для передачи второго и всех последующих пакетов может быть совмещена с пересылкой по сети предшествующих пакетов и латентность, тем самым, не может превышать величины
Помимо латентности, в приведенных формулах оценки времени коммуникационной операции можно уточнить также правило вычисления времени передачи данных
что позволяет теперь учитывать эффект увеличения объема передаваемых данных при росте числа пересылаемых пакетов за счет добавления служебной информации (заголовков пакетов).
98
Проектирование информационных систем Логунова
1. Определение жизненного цикла программного обеспечения. Этапы ЖЦПО. Модели ЖЦПО.
Информационная система (ИС) - это совокупность взаимодействующих и взаимодополняющих подсистем, обеспечивающих сбор, хранение и обработку информации
Кподсистемам ИС относятся:
Технические средства;
Средства связи;
Программное обеспечение.
Технические средства - средства, на физическом уровне обеспечивающие ввод, хранение, обработку и вывод информации. Состав: модемы, Hub`ы, сетевые карты, винчестеры, CD, DVD, сканеры, принтеры, плоттеры, клавиатуры и т.д. Особенности: в большинстве своем технические средства унифицированы и не подлежат настройке под конкретную ИС
Средства связи - локальные, глобальные соединения технических средств с целью передачи информации.
Состав(по способу передачи информации): проводные, оптоволоконные, спутниковые, инфракрасные, радиопередающие и т.д. Особенности: в большинстве своем средства связи унифицированы и не подлежат настройке под конкретную ИС. Однопользовательские ИС не требуют средств связи.
Программное обеспечение (ПО) - совокупность компьютерных программ, необходимых и достаточных для осуществления взаимодействия технических средств и средств связи с целью ввода, хранения и обработки информации. ПО подразделяется на следующие группы:
Системное ПО (операционная система, драйверы технических средств и средств связи)
Системы управления базами данных СУБД (Microsoft SQL Server, InterBase, Firebird и
другие);
База данных-БД;
Клиентское ПО (программа или совокупность программ, обеспечивающих ввод, извлечение, обработку информации из БД, а также ее представление в необходимом виде).
Особенности: Системное ПО и СУБД унифицированы и не подлежат внутреннему перепроектированию под конкретную ИС. Клиентское ПО и БД проектируются и настраиваются на решение специфических задач отдельных ИС.
Жизненный цикл программного обеспечения (ЖЦ ПО) представляет собой набор этапов, частных работ и операций в последовательности их выполнения и взаимосвязи, регламентирующих ведение работ от подготовки технического задания до завершения испытаний ряда версий и окончания эксплуатации ПО или информационной системы (ИС).
ЖЦ ПО – это период времени от момента принятия решения о создании ПО до полного изъятия его из эксплуатации.
Этапы ЖЦПО:
1)Анализ требований заказчика.
2)Анализ рынка.
3)Анализ рисков.
4)Формализация требований.
5)Проектирование.
6)Разработка.
7)Тестирование.
8)Отладка.
9)Ввод в действие.
10)Эксплуатация и сопровождение.
99
ЖЦ образуется в соответствии с принципом нисходящего проектирования и, как правило, носит итерационный характер: реализованные этапы, начиная с самых ранних, циклически повторяются в соответствии с изменениями требований и внешних условий, введением ограничений и т.п. На каждом этапе ЖЦ порождается определенный набор документов и технических решений, при этом для каждого этапа исходными являются документы и решения, полученные на предыдущем этапе. Каждый этап завершается верификацией порожденных документов и решений с целью проверки их соответствия исходным.
Главная особенность индустрии ПО состоит в концентрации сложности на начальных этапах ЖЦ (анализ, проектирование) при относительно невысокой сложности и трудоемкости последующих этапов. Более того, нерешенные вопросы и ошибки, допущенные на этапах анализа и проектирования, порождают на последующих этапах трудные, часто неразрешимые проблемы и, в конечном счете, приводят к неуспеху всего проекта. Рассмотрим эти этапы более подробно. АНАЛИЗ ТРЕБОВАНИЙ является первой фазой разработки ПО, на которой требования заказчика уточняются, формализуются и документируются. Фактически на этом этапе дается ответ на вопрос: "Что должна делать будущая система?". Список требований к разрабатываемой системе должен включать:
1.Совокупность условий, при которых предполагается эксплуатировать будущую систему (аппаратные и программные ресурсы, предоставляемые системе; внешние условия ее функционирования; состав людей и работ, имеющих к ней отношение);
2.Описание выполняемых системой функций;
3.Ограничения в процессе разработки (директивные сроки завершения отдельных этапов, имеющиеся ресурсы, организационные процедуры и мероприятия, обеспечивающие защиту информации).
Целью анализа является преобразование общих, неясных знаний о требованиях к будущей системе в точные (по возможности) определения. На этом этапе определяются:
1.Архитектура системы, ее функции, внешние условия, распределение функций между аппаратурой и ПО;
2.Интерфейсы и распределение функций между человеком и системой;
3.Требования к программным и информационным компонентам ПО, необходимые аппаратные ресурсы, требования к БД, физические характеристики
ЭТАП ПРОЕКТИРОВАНИЯ дает ответ на вопрос "Как (каким образом) система будет удовлетворять предъявленным к ней требованиям?". Задачей этого этапа является исследование структуры системы и логических взаимосвязей ее элементов, причем здесь не рассматриваются вопросы, связанные с реализацией на конкретной платформе. Проектирование определяется как итерационный процесс получения логической модели системы вместе со строго сформулированными целями, поставленными перед нею, а также написания спецификаций физической системы, удовлетворяющей этим требованиям". Обычно этот этап разделяют на два подэтапа:
1.Проектирование архитектуры ПО, включающее разработку структуры и интерфейсов компонент, согласование функций и технических требований к компонентам, методам и стандартам проектирования, производство отчетных документов;
2.Детальное проектирование, включающее разработку спецификаций каждой компоненты, интерфейсов между компонентами, разработку требований к тестам и плана интеграции компонент.
В результате деятельности на этапах анализа и проектирования должен быть получен проект системы (ПС), содержащий достаточно информации для реализации системы на его основе в рамках бюджета выделенных ресурсов и времени. (ПС - совокупность документов, содержащий необходимую и достаточную информацию для
100