

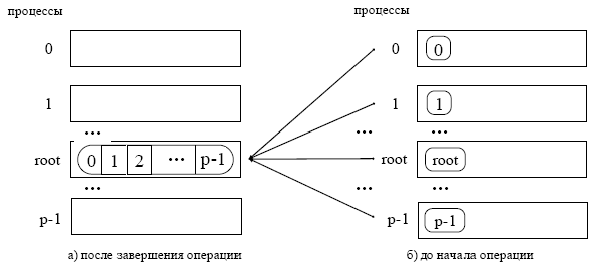
Общая схема операции рассылки данных от одного процесса всем
При выполнении операции рассылки данных корневой процесс из буфера отправки передает каждому процессу в группе, включая себя равные по размеру блоки данных. Сообщения выбираются из буфера отправки корневого процесса в порядке возрастания номеров процессов, т е. j-ый блок данных будет отправлен процессу с номером j. Каждому процессу будет отправлено sendcount элементов. Процесс с номером 0 получит блок данных буфера sendbuf из элементов с индексами от 0 до sendcount-1, процессу с номером 1 будет отправлен блок из элементов с индексами от sendcount до 2* sendcount -1 и т.д. Тем самым, общий размер отправляемого сообщения должен быть равен sendcount * p элементов, где p есть количество процессов в группе.
Буфер отправки игнорируется всеми некорневыми процессами. Значения sendcount и sendtype, должны быть одинаковыми для всех процессов, таким образом, количество посланных и полученных данных для корневого и каждого другого процесса должно попарно совпадать. Также одинаковыми на всех процессах должны быть аргументы root и comm. Корневой процесс использует все аргументы функции, остальные процессы используют только аргументы для выполнения приема: recvbuf, recvcount, recvtype, root, comm.
Коллективная операция сбора данных MPI_Gather от всех процессов в одном является обратной операцией рассылки.
Общая схема операции сбора данных от всех процессов в одном
При выполнении операции сбора данных каждый процесс, включая корневой, посылает содержимое своего буфера в корневой процесс. Корневой процесс получает сообщения, располагая их в буфере приема равными порциями в порядке возрастания номеров процессов. Сообщения на root процесс могут приходить в разном порядке (например, от процесса 0, затем 2, затем 1, затем 3), при этом MPI гарантирует, что данные, посланные процессом с номером j, помещаются в j-ый блок приёмного буфера корневого процесса. Для того, чтобы разместить все поступающие данные, размер приемного буфера recvbuf должен быть равен sendcount * p элементов, где p есть количество процессов в группе. Функция MPI_Gather также определяет коллективную операцию, и ее вызов при выполнении сбора данных должен быть выполнен в каждом процессе группы.
Значения sendcount, sendtype у процесса j должны быть такими же, как значения recvcount, recvtype корневого процесса. Таким образом, количество отправленных и полученных данных для корневого и каждого другого процессов должно попарно совпадать. В корневом процессе используются все аргументы функции, в то время как у остальных процессов используются только аргументы sendbuf, sendcount, sendtype, root, comm. Аргументы comm и root должны иметь одинаковые значения во всех процессах.
2. Реализация интерфейса передачи данных (MPICH). Общая характеристика среды выполнения MPI программ.
MPI – это библиотека функций, которые обеспечивают в первую очередь обмен данными между процессами. Для ее использования в некоторой исполнительной среде, необходим промежуточный слой, который называется реализацией MPI.
Возможны два способа построения реализаций:
1) прямая реализация для конкретной ЭВМ и
2) реализация через ADI (интерфейс абстрактного устройства).
Т.к. типов параллельных систем довольно много, то количество реализаций в первом случае будет слишком велико. Во втором случае строится реализация для абстрактного устройства, а затем архитектура ADI, используя оборудование конкретной вычислительной системы реализуется в этой системе программно. Такая двухступенчатая реализация MPI уменьшает число вариантов и обеспечивает переносимость реализаций.
В Аргоннской национальной лаборатории США подготовлены и получили широкое распространение реализации MPI, получившие название MPICH (CH взята из названия пакета Сhameleon, который ранее использовался для систем с передачей сообщений, многое из этого пакета вошло в MPIСH).
Имеется три поколения MPIСH, связанных с развитием ADI.
ADI-1 было спроектировано для компьютеров с массовым параллелизмом, где механизм обмена между процессами принадлежал системе.
ADI-2 – добавлен эффективный коммуникационный механизм с большим набором функций.
ADI-3 – обеспечило адаптацию к различным коммуникационным архитектурам, удаленный доступ и поддержку операций MPI-2, таких как динамическое управление процессами.
Для обмена сообщениями ADI должен обеспечивать четыре набора функций:
1) описания передаваемых и получаемых сообщений;
2) перемещения данных между ADI и передающей аппаратурой;
3) управления списком сообщений (как посланных, так и принимаемых);
4) получения основной информации об исполнительной среде и ее состоянии.
ADI содержит процедуры для упаковки сообщений и подключения заголовочной информации, управления буферизацией, установления cоответствия приема передач сообщений и др.
Каждая реализация библиотеки функций MPI содержит ряд собственных протоколов, устанавливающих правила выполнения основных операций передачи данных. В реализации MPIСH используются 2 протокола: Eager и Rendezvous.
Eager. При отправке данных, с адресом начала буфера MPI должен включить информацию о тэге, коммуникаторе, длине, источнике и получателе сообщения. Эту дополнительную информацию называют оболочкой (envelope), которая следует за данными. Передачу данных вместе с оболочкой реализует eager протокол.
Когда сообщение прибывает на процесс получатель, соответствующая процедура приема может быть либо уже запущена, либо нет.
Если процедура приема запущена, предоставляется место для приходящих данных, если нет, принимающий процесс должен определить, что сообщение прибыло и сохранить его. Из пришедших сообщений формируется очередь, к которой обращается функция приема сообщений MPI_Recv. Если сообщение пришло, операция приема выполняется и обмен считается завершенным. В том случае, если сообщение не может быть принято немедленно, оно буферизуется и находится в состоянии ожидания обмена.
Rendezvous. Передачу “больших” (объем сообщения превышает установленный в MPI размер буфера приема-передачи) сообщений реализует протокол Rendezvous. В этом случае процесс получает только оболочку, содержащую служебную информацию о передаваемом сообщении. Только после того, как процесс отправитель получит подтверждение на возможность приема, данные будут отправлены.
Главное преимущество протокола «рандеву» состоит в том, что он позволяет принимать произвольно большие сообщения в любом количестве, для коротких сообщений он не используется. Возможно большое количество других протоколов и их модификаций
Канальный интерфейс является одним из наиболее важных уровней иерархии ADI и может иметь множественные реализации. Например, р4 – для систем с передачей сообщений, и p2 – для систем с общей памятью. Реализация Chameleon, построена на базе интерфейса p4, который частично используется в реализации MPICH.
Для разработки, компиляции, компоновки и выполнения параллельных программ требуется специальная среда. Если для разработки и сборки параллельных приложений достаточно возможностей таких средств разработки, как Visual Studio, то запуск требует ряда дополнительных возможностей. Например, средств планирования запуска заданий, определения и захвата необходимого задаче числа процессоров и т.д.
Как правило, средства запуска параллельных программ разрабатываются и поставляются с реализацией MPI-библиотек. Для версий MPICH – это скрипт с именем mpirun которому с помощью дополнительных ключей подается обязательные параметры, такие как количество процессов, которые необходимо создать для выполнения задачи и имя файла, содержащего исполняемый код параллельной программы. Дополнительные параметры могут подаваться в случае необходимости, например, список имен используемых для выполнения задачи процессоров.
Итак, MPICH является переносимой реализацией полного описания MPI для широкого круга параллельных вычислительных сред, включая кластеры рабочих станций и массово-параллельные системы. Кроме библиотеки функций MPI, MPICH содержит программную среду, которая включает мобильный механизм запуска параллельных программ, библиотеку функций для исследования эффективности выполнения MPI программ, графическую библиотеку MPE и программные средства визуализации полученных данных при выполнении профилирования.