

lab_MODIFIED_full
.pdfПриклад 3. Нелінійне рівняння третього порядку.
Розв’язок – один дійсний корінь і два комплексних.
|
|
|
|
|
|
|
|
|
|
|
i |
|
1 |
|
|
|
|
|
|
|
|
f (x) 3.1 x3 2.05 x2 0.31 x 10 |
|
|||||||||
x |
0.5 |
|
x1r |
root (f (x) x) |
|
|
||||
|
|
|
|
|
|
f (x) |
|
|
||
x |
1 i |
x2r |
root |
|
|
x |
|
|||
x x1r |
|
|||||||||
|
|
|
|
|
|
|
f (x) |
|
||
x |
1 i |
x3r |
root |
|
|
x |
||||
(x x1r) (x x2r) |
||||||||||
x1r 1.306
x2r 0.984 1.226i
x3r 0.984 1.226i
Приклад 4. Векторне рівняння другого порядку.
Невідомі вектори – QE I QE1
x 0 |
A (1 |
2 3 ) |
|
|
B ( 7 |
12 |
10 ) |
C (6 7 8 )
F(A B C x) Ax2 B x C
QE(A B C x) root (F(A B C x) x)
QE(A B C x) ( 1 0.655 1.333 )
x 6
QE1(A B C x) root (F(A B C x) x)
QE1(A B C x) ( 6 5.345 2 )
Для розв’язку систем рівнянь будь-якого порядку зручно використовувати засоби блоку Given…Цей блок обмежений згори ключовим словом Given…, після якого розташовують вирази всіх алгебраїчних рівнянь, необхідних для розв’язку системи. Вирази необхідно записувати із спеціальним знаком «жирне дорівнює»,
який кодується комбінацією клавіш CTRL+=. Перед початком блоку слід визначити попередні наближені значення невідомих, відносно яких здійснюється розв’язок системи. Всередині блоку після виразів рівнянь зазначають область, в
якій можливий розв’язок (наприклад, |
). Далі для знаходження точних значень |
|
111 |

невідомих використовують функцію Find(x,y), яка повертає вектор значень невідомих. Якщо розв’язків декілька, повторюють визначення наближених попередніх значень невідомих і сам блок, в якому зазначають нову область пошуку
(наприклад, ).
Приклад 1. Перетин кривої другого порядку прямою лінією.
x 1 y |
|
1 |
Given |
|||||||||||||
|
||||||||||||||||
|
||||||||||||||||
|
|
|
x2 |
|
|
|
y |
2 |
|
|
6 |
|||||
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
||||||||||
|
|
|
x |
|
|
|
|
|
y |
|
|
1 |
||||
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
x1 |
x1 |
2.158 |
|
|
|
|
|
Find( x, y) |
= |
|
|
|
|
y1 |
y1 |
1.158 |
|
f( x) |
6 |
x2 |
f1( x) |
1 x |
|
|
x |
10 .. 10 |
|
|
|
|
20 |
|
|
|
|
|
|
f(x) |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
f1(x) |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
9 |
|
|
|
|
|
|
|
10 |
5 |
|
|
|
|
|
10 |
0 |
5 |
10 |
|
|
|
10 |
x |
10 |
|
|
|
Приклад 2.
x 10 10
f1(x) 0.87x2 7.54x 108.1
f2(x) 1.45x2 2.2
200 |
|
|
|
|
f1(x) 100 |
|
|
|
|
f2(x) |
|
|
|
|
0 |
|
|
|
|
100 |
5 |
|
|
|
10 |
0 |
5 |
10 |
|
|
|
x |
|
|
112

x |
5 |
y |
10 |
|
|
Given |
|
|
|
|
|
y |
f1( x) |
y |
f2( x) |
|
|
x>0 |
|
|
|
|
|
x1 |
|
|
|
x1 |
5.324 |
|
Find( x, y) |
= |
|
||
y1 |
|
|
|
y1 |
43.299 |
x |
10 |
|
y |
40 |
|
Given |
|
|
|
|
|
y |
f1( x) |
|
y |
f2( x) |
|
|
x<0 |
|
|
|
|
x2 |
|
|
x2 |
8.574 |
|
|
|
Find( x, y) |
= |
||
y2 |
|
|
y2 |
108.792 |
|
113
Хід роботи
1.Знайти номер варіанту k для виконання завдання. Для цього із залікової книжки студент вибирає дві останні цифри m (передостання) та n (остання цифра). Далі,
варіант k визначається за такою формулою:
k mod m 10 n,20
де mod(x,y) – знаходження остачі від ділення x на y, наприклад mod(7,4) = 3
2.Згідно варіанту побудувати графіки та знайти:
|
1. Розв’язки системи лінійних рівнянь: |
9.Розв’язки системи нелінійних рівнянь: |
||
- 0.15*x1 - 0.84*x2 = 4.1 |
f1(x) = 3.5*x3 - 0.1*x2 - 0.24*x – 9.7 |
|||
1.48*x1 + 2.2*x2 = 1.4 |
f2(x) = 0.53*x – 1.2 |
|
||
2. |
Корені нелінійного рівняння: |
10.Розв’язки системи нелінійних рівнянь: |
||
f(x) = 1.8*x2+0.83*x – 25.3 |
f1(x) = 1.5*x3 - 0.87*x2 - 1.24*x – 15.7 |
|||
3. |
Корені нелінійного рівняння: |
f2(x) = 7.53*x + 5.2 |
|
|
f(x) = 3.1*x2 - 4.33*x – 15.57 |
11.Розв’язки системи нелінійних рівнянь: |
|||
4. |
Корені нелінійного рівняння: |
f1(x) = 1.5*x3 - 0.87*x2 - 1.24*x – 15.7 |
||
f(x) = 1.8*x3 + 7.1*x2 - 0.23*x – 5.87 |
f2(x) = 7.53*x2 + 5.2 |
|
||
5. |
Корені нелінійного рівняння: |
12.Розв’язки системи нелінійних рівнянь: |
||
f(x) = 5.8*x3 - 1.4*x2 - 0.53*x – 32.87 |
f1(x) = 6.1*x3 - 0.17*x2 - 1.54*x – 3.1 |
|||
6. |
Розв’язки системи лінійних рівнянь: |
f2(x) = 1.57*x2 + 0.2 |
|
|
- 0.17*x1 - 0.84*x2 = 1.1 |
13.Розв’язки |
системи |
нелінійних |
|
1.45*x1 + 7.2*x2 = 1.9 |
рівнянь: |
|
|
|
7. |
Корені нелінійного рівняння: |
f1(x) = 0.1*x3 - 0.87*x2 - 7.54*x – 0.1 |
||
f(x) = 7.8*x3 - 0.4*x2 - 0.48*x – 92.7 |
f2(x) = 1.45*x2 + 7.2 |
|
||
8. |
Корені нелінійного рівняння: |
14.Розв’язки |
системи |
нелінійних |
f(x) = 3.5*x3 - 0.1*x2 - 0.24*x – 9.7 |
рівнянь: |
|
|
|
|
|
f1(x) = - 0.87*x2 - 7.54*x – 0.1 |
|
|
|
|
f2(x) = 1.45*x2 + 7.2 |
|
|
|
|
15.Розв’язки системи лінійних рівнянь: |
||
|
|
- 0.17*x1 - 0.54*x2 = 3.1 |
|
|
|
|
1.47*x1 + 7.2*x2 = 1.4 |
|
|
|
|
|
|
|
3. |
Завершити роботу, результати занести у звіт |
|
|
|
|
114 |
|
|
|
Контрольні запитання
1.Для чого застосовується блок Given?
2.В яких випадках обирають функції Find або Minerr?
3.Яке значення мають перші наближення аргументів?
4.Розв’язки систем рівнянь.
Зміст звіту
1.Титульний лист.
2.Мета роботи.
3.Короткі теоретичні відомості.
4.Результати виконаної роботи.
5.Висновок.
115
Список рекомендованої літератури.
3.Дьяконов В.П., Абраменкова И.В. MathCAD7 в математике, физике и
Internet. М. – 1998.
4.Аладьев В.З., Гершгорн Н.А. Вьічислительньіе задачи на персональном компьютере, - К., - 1991.
116
Лабораторна робота №15. Статистична обробка даних та інтерполяція в
програмі MathCAD
Мета роботи: навчитися використовувати стандартні функції для статистичної обробки масивів даних, регресивного аналізу та проведення інтерполяції засобами програми MathCAD.
Теоретичні відомості
При проведенні різноманітних експериментальних досліджень часто виникають задачі здійснення статистичної обробки даних, інтерполяції,
екстраполяції, або апроксимації.
Статистика - галузь знань, в якій розглядаються загальні питання збору,
вимірювання та аналізу масових статистичних (кількісних, або якісних) даних.
Статистика розробляє спеціальну методологію дослідження та обробки даних.
Статистичні методи - методи аналізу статистичних даних. Виділяють методи прикладної статистики, які можуть застосовуватися у всіх галузях наукових досліджень і будь-яких галузях народного господарства, та інші статистичні методи, використання яких є обмеженим тією чи іншою сферою. Маються на увазі такі методи, як статистичний приймальний контроль, статистичне регулювання технологічних процесів, надійність та випробування, планування експериментів.
Для опису даних застосовують як детерміновані так і імовірнісні методи. За допомогою детермінованих методів можна проаналізувати лише ті дані, які є в розпорядженні дослідника. В багатьох випадках статистичні дані - це значення певної ознаки, властиві досліджуваним об'єктам. Ці значення можуть бути кількісними, або вказувати на категорію до якої можна віднести об'єкт.
Застосування статистичних методів і моделей для статистичного аналізу конкретних даних тісно прив'язане до проблемами відповідної області. Теорія статистичних методів націлена на вирішення реальних завдань. Тому в ній постійно виникають нові постановки математичних завдань аналізу статистичних даних, розвиваються і обґрунтовуються нові методи. Обґрунтування часто проводиться математичними засобами, тобто шляхом доказу теорем. Велику роль відіграє методологічна складова - як саме ставити завдання, які припущення прийняти з метою подальшого математичного вивчення. Є великою роль сучасних інформаційних технологій, зокрема, комп'ютерного експерименту. Задача аналізу
117
історії статистичних методів з метою виявлення тенденцій розвитку і застосування їх для прогнозування все ще залишається актуальною.
Функції статистичної обробки даних
Більшість стандартних функцій статистичної обробки застосовуються до даних представлених у вигляді двох векторів: вектора координат точок на площині
(вісь абсцис), вектора координат по осі ординат. Ці вектори повинні мати однакову розмірність і бути наперед визначеними. Програма MathCAD містить ряд стандартних функцій для проведення статистичної обробки, таблиця 1.
Таблиця 1. Функції статистичної обробки даних
Функція |
Позначення |
|
|
|
|
Призначення |
|
|
|
|
|
|
|
|
|||||||
cvar(A, B) |
Cov |
|
Коваріація (кореляційний момент) в теорії |
|||||||
|
|
|
ймовірностей і математичній статистиці міра |
|||||||
|
|
|
лінійної залежності двох випадкових величин. |
|
||||||
|
|
|
|
|
|
|||||
stdev(A) |
Σ |
|
Середньоквадратичне |
відхилення |
в теорії |
|||||
|
|
|
ймовірностей і статистиці найбільш поширений |
|||||||
|
|
|
показник |
розсіювання |
значень |
випадкової |
||||
|
|
|
величини щодо її математичного сподівання. |
|
||||||
|
|
|
|
|||||||
mean(A) |
M |
|
Середнє значення - числова характеристика, що |
|||||||
|
|
|
для набору даних є сумою значень, поділеною на |
|||||||
|
|
|
їхню кількість. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
corr(A, B) |
R |
|
Кореляція |
|
(кореляційна |
залежність) |
- |
|||
|
|
|
статистичний взаємозв'язок двох, або кількох |
|||||||
|
|
|
випадкових величин. Математичної мірою |
|||||||
|
|
|
кореляції |
двох |
випадкових |
величин |
є |
|||
|
|
|
кореляційний зв’язок, або коефіцієнт кореляції. |
|
||||||
|
|
|
|
|||||||
var(A) |
σ2 |
|
У теорії ймовірності та статистики, дисперсія |
|||||||
|
|
|
характеризує |
розкид |
значень |
випадкової |
||||
|
|
|
величини. Це один з декількох параметрів |
|||||||
|
|
|
розподілу ймовірностей, що описують як далеко |
|||||||
|
|
|
числа знаходяться відносно середнього. |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
118 |
|
|
|
|
|
|
|
|
Функції регресивного аналізу
У статистиці, регресивний аналіз є методом моделювання залежностей між змінно Y і однією, або декількома змінними X. У лінійній регресії, за допомогою лінійної функції шляхом апроксимації створюється модель випадкової величини.
Невідомі параметри моделі визначаються на основі отриманих даних. Такі моделі називаються лінійними моделями. Як і всі форми регресивного аналізу, лінійна регресія фокусується на умовному розподілі ймовірностей, а не поєднанні розподілів ймовірності який є областю багатовимірного аналізу. Для проведення регресивного аналізу є наявними дві функції, таблиця 2.
Таблиця. 2 Функції регресивного аналізу
Функція 
 Призначення
Призначення
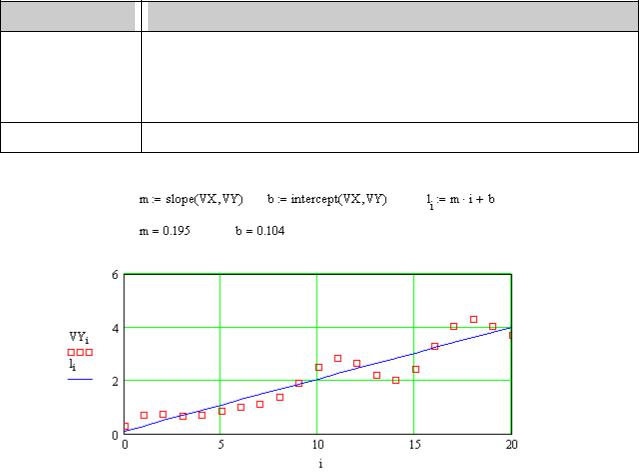
slope(VX,VY) Коефіцієнт нахилу прямої. У математиці, нахил (градієнт)
описує крутизну, або нахил прямої. Чим більшим є цей коефіцієнт тим крутіший нахил прямої.
intercept(VX,VY) Визначення точки перетину прямої з віссю ординат (Y).
Рис. 1 Результати регресивного аналізу випадкової величини VY
119

Функції для інтерполяції
Інтерполяція є способом знаходження проміжних значень величини за наявним дискретним набором вже відомих значень. Багатьом з тих, хто стикається з науковими і інженерними розрахунками, часто доводиться оперувати наборами значень, отриманих експериментальним шляхом, або методом випадкової вибірки.
Як правило, на підставі цих наборів потрібно побудувати функцію, на яку могли б з високою точністю потрапляти інші одержувані значення. Така задача називається апроксимацією кривої. Інтерполяцією називають такий різновид апроксимації, при якій крива побудованої функції проходить точно через наявні точки даних. Існує близьке до інтерполяції завдання, яке полягає в апроксимації будь-якої складної функції, більш простою функцією. Якщо деяка функція занадто складна для проведення обчислень, можна спробувати обчислити її значення в декількох точках, а на їх основі побудувати, тобто інтерполювати, більш просту функцію.
Використання спрощеної функції не дозволяє отримати такі ж точні результати, які давала б початкова функція. В деяких класах завдань досягнутий виграш в простоті і швидкості обчислень може переважити отримувану похибку в результатах.
Рис. 2 Графіки деякої величини Y: Yi – початкова залежність; Y2j – залежність отримана шляхом лінійної інтерполяції
Лінійна інтерполяція - інтерполяція алгебраїчним рівнянням виду y(x) = ax + b
функції f, заданої в двох точках x0 і x1 відрізка [a, b]. Інтерполянтом в даному випадку виступає лінійна функція. Якщо задані значення в декількох точках,
функція замінюється кусочно-лінійною функцією
120