

Metod_labs_v5
.pdf# |
LUT6 |
: |
6 |
|
|
|
|
|
# |
MUXCY |
: |
23 |
|
|
|
|
|
# |
XORCY |
: |
24 |
|
|
|
|
|
# IO Buffers |
: |
23 |
|
|
|
|
|
|
# |
IBUF |
: |
8 |
|
|
|
|
|
# |
OBUF |
: |
15 |
|
|
|
|
|
Device utilization summary: |
|
|
|
|
|
|
|
|
--------------------------- |
|
|
|
|
|
|
|
|
Selected Device : 6vlx75tff484-3 |
|
|
|
|
|
|
|
|
Slice Logic Utilization: |
|
|
|
|
|
|
|
|
|
Number of Slice LUTs: |
|
25 |
out of |
46560 |
|
0% |
|
|
Number used as Logic: |
|
25 |
out of |
46560 |
|
0% |
|
Slice Logic Distribution: |
|
|
|
|
|
|
|
|
|
Number of LUT Flip Flop pairs used: |
|
25 |
|
|
|
|
|
|
Number with an unused Flip Flop: |
|
25 |
out of |
25 |
|
100% |
|
|
Number with an unused LUT: |
|
|
0 |
out of |
25 |
0% |
|
|
Number of fully used LUT-FF pairs: |
0 |
out of |
|
25 |
0% |
||
|
Number of unique control sets: |
|
|
0 |
|
|
|
|
IO Utilization: |
|
|
|
|
|
|
|
|
|
Number of IOs: |
|
|
23 |
|
|
|
|
Number of bonded IOBs: |
|
23 |
out of |
240 |
|
9% |
||
Оптимізуємо структуру перемножувача шляхом зменшення кількості базових операцій згідно наведеного вище алгоритму.
Так, для константи 7910 = 10011112 виконаємо мінімізацію.
K = 10011112= 10100002
mM = X.L4 + X.L6 – X.L0
VHDL код для реалізації функції mM наведено нижче:
entity GVV_C_mM is
Port ( GVV_A : in STD_LOGIC_VECTOR (7 downto 0); GVV_C_mM : out STD_LOGIC_VECTOR (14 downto 0));
end GVV_C_mM;
--CONSTANT B = 1001111
--OPTIMIZED B = 1010000
--signal k : std_logic_vector(7 downto 0):=x"4F" ; architecture Behavioral of GVV_C_mM is
signal gvv_prod, gvv_p4, gvv_p6, gvv_p0:unsigned(14 downto 0); begin
gvv_p0 <= "0000000" & unsigned(GVV_A); gvv_p4 <= "000" & unsigned(GVV_A) & "0000"; gvv_p6 <= "0" & unsigned(GVV_A) & "000000";
gvv_prod <= (gvv_p4+gvv_p6)-gvv_p0; GVV_C_mM <= std_logic_vector (gvv_prod);
end Behavioral;
Нижче наведені фрагменти із звіту про результати виконання процесу синтезу оптимізованого перемножувала на константу 7910:
==============================================================
* |
|
HDL Synthesis |
|
|
|
|
|
* |
============================================================== |
||||||||
Synthesizing Unit <GVV_C_mM>. |
|
|
|
|
|
|
||
|
Related source file is |
|
|
|
|
|
|
|
"c:/users/public/gros/gvv_lab2/gvv_c_mm.vhd". |
|
|
|
|||||
|
Found 15-bit adder for signal |
|
|
|
|
|
|
|
<gvv_p4[14]_gvv_p6[14]_add_3_OUT> created at line 52. |
|
|
|
|||||
|
Found 15-bit subtractor for signal <GVV_C_mM>. |
|
|
|
||||
|
Summary: |
|
|
|
|
|
|
|
|
inferred |
2 Adder/Subtractor(s). |
|
|
|
|
|
|
Unit <GVV_C_mM> synthesized. |
|
|
|
|
|
|
||
============================================================== |
||||||||
HDL Synthesis Report |
|
|
|
|
|
|
||
Macro Statistics |
|
|
|
|
|
|
||
# Adders/Subtractors |
|
|
|
|
: 2 |
|
||
|
15-bit adder |
|
|
|
|
|
: 1 |
|
|
15-bit subtractor |
|
|
|
|
: 1 |
|
|
======================================================== |
|
|||||||
* |
|
Design Summary |
|
|
|
* |
|
|
======================================================== |
|
|||||||
Top Level Output File Name |
: GVV_C_mM.ngc |
|
|
|
||||
Primitive and Black Box Usage: |
|
|
|
|
|
|
||
------------------------------ |
|
|
|
|
|
|
||
# BELS |
|
: |
49 |
|
|
|
|
|
# |
GND |
|
: |
1 |
|
|
|
|
# |
INV |
|
: |
4 |
|
|
|
|
# |
LUT2 |
|
: |
3 |
|
|
|
|
# |
LUT3 |
|
: |
1 |
|
|
|
|
# |
LUT4 |
|
: |
1 |
|
|
|
|
# |
LUT5 |
|
: |
4 |
|
|
|
|
# |
LUT6 |
|
: |
5 |
|
|
|
|
# |
MUXCY |
|
: |
14 |
|
|
|
|
# |
VCC |
|
: |
1 |
|
|
|
|
# |
XORCY |
|
: |
15 |
|
|
|
|
# IO Buffers |
|
: |
23 |
|
|
|
|
|
# |
IBUF |
|
: |
8 |
|
|
|
|
# |
OBUF |
|
: |
15 |
|
|
|
|
Device utilization summary: |
|
|
|
|
|
|
||
--------------------------- |
|
|
|
|
|
|
||
Selected Device : 6vlx75tff484-3 |
|
|
|
|
|
|
||
Slice Logic Utilization: |
|
|
|
|
|
|
||
|
Number of Slice LUTs: |
|
18 |
out of |
46560 |
0% |
||
|
Number used as Logic: |
|
18 |
out of |
46560 |
0% |
||
Slice Logic Distribution: |
|
|
|
|
|
|
||
|
Number of LUT Flip Flop pairs used: |
|
18 |
|
|
|
||
|
Number with an unused Flip Flop: |
|
|
18 out of |
18 |
100% |
||
Number with an unused LUT: |
0 |
out of |
18 |
0% |
Number of fully used LUT-FF pairs: |
0 |
out of |
18 |
0% |
Number of unique control sets: |
0 |
|
|
|
IO Utilization: |
|
|
|
|
Number of IOs: |
23 |
|
|
|
Number of bonded IOBs: |
23 |
out of |
240 |
9% |
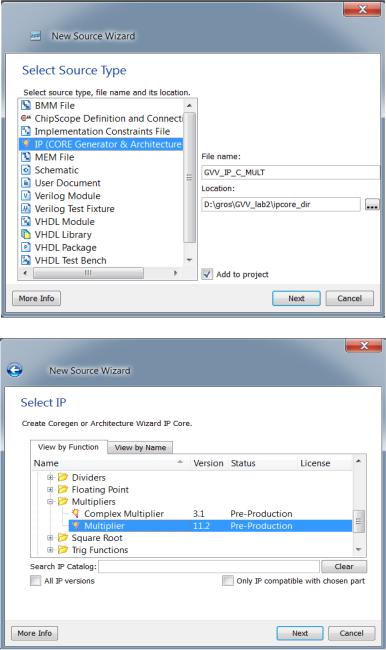
Xilinx.Ise дає можливість створювати перемножувачі на константу з допомогою Генератор системних IP-ядер (CORE Generator). Процес створення спеціалізованого перемножувала на константу 7910 = 10011112 наведений далі.
Вибираємо необхідне для проекту IP-ядро з цілого переліку готових IP-ядер і виконуємо налаштування згідно інструкцій Помічника:
Рис. 2.3 Вікно Помічник створення нового елемента
Рис. 2.4 Вибір IP-ядра перемножувача
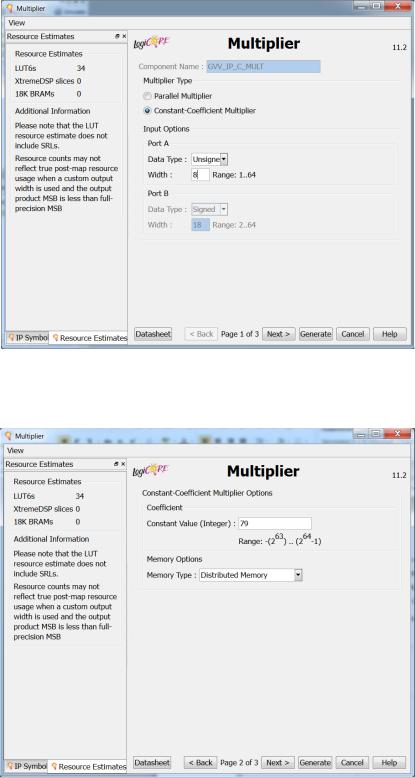
Далі розробнику надається можливість вибрати всі необхідні параметри, які повинен згенерувати Генератор системних IP-ядер. Тут необхідно вибрати тип перемножувача – перемножувач на константу, та задати тип та розрядність операнда.
Рис. 1.6 Вікно конфігурування перемножувала в Генераторі системних IP-ядер
Задаємо значення константи-множника:
Рис. 1.7 Вікно конфігурування перемножувала на константу в Генераторі системних IP-ядер
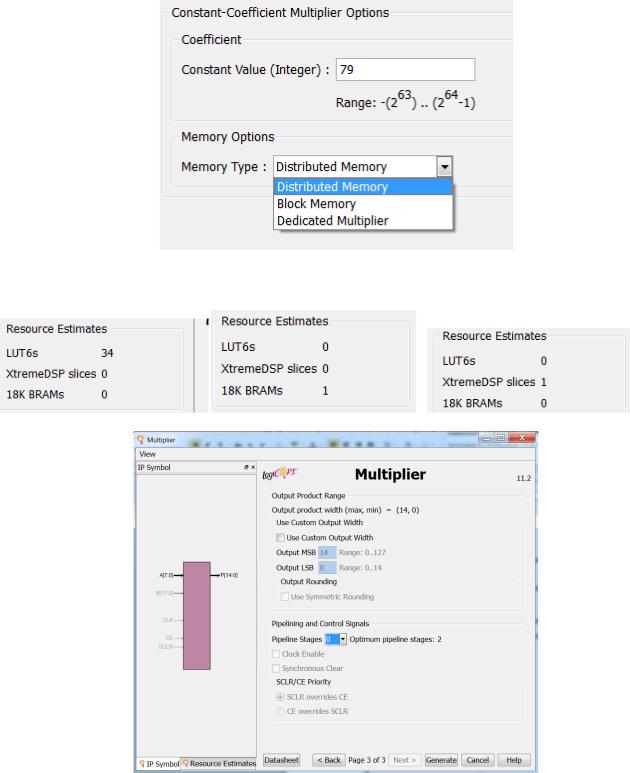
Як основний компонент реалізації спеціалізованого перемножувача можуть використовуватись розподілена пам'ять, блокова пам'ять та спеціалізовані блоки цифрового опрацювання сигналів dsp48.
Рис. 2.8 Вікно вибору компонентів реалізації перемножувача на константу
Приблизна оцінка ресурсозатрат при використанні таких елементів буде:
Рис. 2.9 Вікно конфігурування перемножувала в Генераторі системних IP-ядер
Після завершення синтезу і створення умовних графічних позначень створених компонентів розміщаємо їх на загальній схемі.
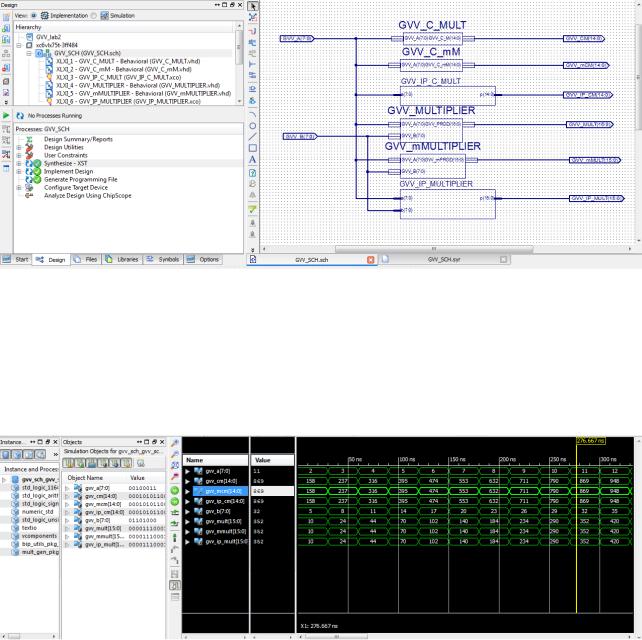
Рис.2.10 Графічні символи створених нами компонентів та їх сполучення у вікні схемного редактора
Далі виконати перевірку схеми, синтез, імплементування. Проаналізувати RTL та технологічні схеми. Виконати функціональне моделювання схеми. Для цього створити тестовий файл, в якому простимулювати вхідні сигнали.
Результатом роботи є часові діаграми моделювання розроблених перемножувачів.
Рис. 2.11 Часові діаграми моделювання розроблених перемножувачів
За результатами виконаних робіт робимо висновок.
ПОРЯДОК ВИКОНАННЯ РОБОТИ
Частина 1
1.Побудувати перемножувачі цілих чисел з послідовним та паралельним додаванням часткових добутків. Провести синтез та проаналізувати функціональну та технологічну схеми. Верифікувати (виконати часову симуляцію).
2.Проаналізувати звіти процесу синтезу перемножувачів. Зробити висновки про затрати на реалізацію кожного методу.
3.Модифікувати двійкове представлення константи з метою мінімізації кількості додавань/віднімань, тобто оптимізувати структуру перемножувача по методу мінімізації одиниць.
4.Реалізувати перемножувач цілих чисел з допомогою Генератора ядер. Виконати (верифікацію) часове симулювання.
5.Порівняти результати отримані згідно п. 2 та п. 3. За результатами зробити висновок.
Частина 2
1.Побудувати спеціалізований перемножувач на константу k (див. таб.), що
вдвійковому представленні з 32-х розрядною точністю (взявши по модулю) має,
наприклад, наступний вигляд: cos ( /32) = 0,111110100111110100000101010110110.
2.Реалізувати схему перемножувала на константу, провести синтез та проаналізувати функціональну та технологічну схеми. Верифікувати (виконати часову симуляцію).
3.Модифікувати двійкове представлення константи з метою мінімізації кількості додавань/віднімань, тобто оптимізувати структуру перемножувача по методу мінімізації одиниць.
4.Реалізувати оптимізовану структуру перемножувала. Імплементувати в ПЛІС. Виконати часове симулювання. Проаналізувати функціональні та технологічні схеми отримані в процесі проектування та затрати на реалізацію. За результатами зробити висновок.
5.Порівняти результати отримані згідно п. 1 та п. 4. Зробити висновки про затрати на реалізацію кожного методу.
6.Скласти та захистити звіт з лабораторної роботи.
|
|
|
Таблиця. Варіанти завдань. |
|
№ |
Константа k |
№ |
Константа k |
|
|
|
|
|
|
1. |
cos ( /12) |
16 |
tg ( /12) |
|
|
|
|
|
|
2. |
cos ( /22) |
17 |
sin ( /22) |
|
|
|
|
|
|
3. |
ctg( /16) |
18 |
cos ( /16) |
|
|
|
|
|
|
4. |
cos ( /20) |
19 |
cos ( /87) |
|
|
|
|
|
|
5. |
cos ( /30) |
20 |
tg ( /30) |
|
|
|
|
|
|
6. |
sin ( /35) |
21 |
sin ( /55) |
|
|
|
|
|
|
7. |
cos ( /45) |
22 |
cos ( /41) |
|
|
|
|
|
|
8. |
sin ( /25) |
23 |
cos ( /25) |
|
|
|
|
|
|
9. |
cos ( /5) |
24 |
sin ( /5) |
|
|
|
|
|
|
10. |
cos ( /36) |
25 |
cos ( /60) |
|
|
|
|
|
|
11. |
sin ( /43) |
26 |
ctg ( /43) |
|
|
|
|
|
|
12. |
cos ( /57) |
27 |
cos ( /7) |
|
13. |
tg ( /30) |
28 |
sin ( /30) |
|
|
|
|
|
|
14. |
sin ( /56) |
29 |
sin ( /6) |
|
|
|
|
|
|
15. |
cos ( /9) |
30 |
cos ( /65) |
|
ЛАБОРАТОРНА РОБОТА № 4
РОЗРОБКА КОНВЕЄРНОГО ПРОЦЕСОРА
Мета роботи: розробити конвеєрний процесор.
МЕТОДИЧНІ МАТЕРІАЛИ
Конвеєрні процесори (КП) СКС повинні обробляти інтенсивні потоки даних відповідно до швидкості їх надходження, тобто в реальному масштабі часу, причому прийом нового масиву даних здійснюється одночасно з обробкою попереднього.
Існує два типи КП: рекурсивні (КРП) та нерекурсивні (КНП). До складу КП входять : конвеєрний операційний пристрій(КОП), буферна пам’ять(БП) та блок керування(БК) [1].
За один прохід масиву в КОП КНП виконуються всі функціональні операції і-го яруса потокового графу(ПГ) алгоритму(він описує алгоритм роботи спеціалізованого пристрою). У КНП відсутні зворотні зв’язки виходів КОП та БП (рис. 1(а)), яка впорядковує дані при їх подачі на входи КОП. БК синхронізує роботу КОП та БП, формує коди операцій КОП і адреси БП.
|
х1 |
х2 |
хr |
|
К |
|
|
|
|
|
х1 |
|
х2 |
хr |
К |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
БП |
|
|
БК |
|
|
|
|
|
|
|
|
БП |
|
|
|
БК |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
КОП |
|
|
|
|
|
|
|
|
|
|
КОП |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
у1 |
у2 |
уs |
|
К |
|
|
|
|
|
у1 |
|
у2 |
уs |
К |
|||
|
|
|
|
(а) |
|
|
|
|
|
|
|
|
|
(б) |
|
|||
Рис. 1.Схема конвеєрного нерекурсивного (а) та конвеєрного рекурсивного процесорів
В КОП КРП виконуються функціональні оператори декількох ярусів ПГ алгоритму, або весь алгоритм за кілька проходів через нього масиву вхідних даних. В КРП присутні зворотні зв’язки виходів КОП та БП (рис. 1(б)).
КОП КРП у більшості випадків є багатофункціональними. Однофункціональними вони будуть тільки у випадку, коли КРП виконує алгоритм, всі функціональні оператори якого є однаковими. БК здійснює
загальну синхронізацію, адресацію БП, задає код операції КОП та організовує цикли.
Основою конвеєрних рекурсивних та нерекурсивних процесорів є конвеєрний операційний пристрій (КОП). КОП апаратно відображається шляхом послідовного з’єднання комбінаційних схем (КС). Всі КС з’єднані між собою безпосередньо або через конвеєрні регістри (КР). Структура КГАОП показана на рис. 2.
На даному рисунку використані наступні скорочення :
Хi – входи надходження даних(і = 1, 2, ..., r), r – кількість входів, Yj – виходи результатів обчислень(j = 1, 2, . . . , s), s – кількість виходів , КРД та КРК – КР відповідно даних (Д) та команд (К), m – кількість ярусів алгоритму, n – кількість ярусів конвеєра КОП.
Якщо структура КОП орієнтована на реалізацію алгоритму, який обчислює одну функцію, він називається однофункціональним, групу функцій – багатофункціональним. Універсального КОП немає, оскільки не існує універсального алгоритму. Звідси стають зрозумілими галузі застосування цього виду пристроїв – вирішення однієї або вузького кола задач.
Нехай в КОП обробляється масив чисел X = {X1, X2, . . . , Xr}, r = 1, 2, . . , N. В першому такті переднім фронтом тактового імпульсу Т в регістр КРД1 записується значення Х1. Над ним в комбінаційній схемі КС1 першого ярусу виконується операція Ф1. Переднім фронтом другого імпульсу результати цієї операції переписуються в регістр КРД2, а в регістр КРД1 запишеться значення Х2. В комбінаційних схемах КС1, КС2 над значеннями, що зберігаються відповідно в регістрах КРД1 та КРД2 виконуються операції Ф1 і Ф2. В третьому такті результати з КС2 записуються в КРД3 і т. д. На регістри ярусів конвеєра, що звільнюються, в кожному такті надсилаються нові дані оброблюваного масиву, над якими виконуються ті ж операції. При повному завантаженні конвеєра одночасно виконуються оператори всіх m ярусів алгоритму. Стан КОП в t-му такті його роботи при обробці N чисел визначається вектором А(t)=/ А0(t)
А1(t). . . Аm(t)/ де t = 1, 2, . . . , (m+N). При цьому Аm(t) = Yt , тобто в кожному такті на виході КОП з’являється результат обчислення, крім перших m тактів, коли заповнюється конвеєр.
Оскільки в різних ярусах конвеєра реалізуються операції з різною точністю, регістри ярусів мають різну розрядність, рівну розрядності вхідної інформації і-го ярусу ПГ алгоритму. Тому кожний багатофункціональний КОП повинен мати деяку кількість елементів для забезпечення налаштування на задану операцію. Зокрема, комбінаційні схеми ярусів можуть містити