

Анализ данных и знаний / 5 лаба / 5
.docСтавится задача исследовать выборки средних баллов аттестата зачисленных и незачисленных аббитуриентов на специальность «Технологии производства авиационных двигателей и энергетических установок».
#1
data=read.table("aviadvig1.csv", sep=";", dec=".", header=TRUE, row.names = 1,
col.names = c("ФИО", "Аттестат", "Физика", "Математика", "Укр.мова"))
dat = c(data[,2], data[,3], data[,4])
x11 = data[1:45,2]
x12 = data[46:84,2]
x21 = data[1:45,3]
x22 = data[46:84,3]
x31 = data[1:45,4]
x32 = data[46:84,4]
x41 = data[1:45,1]
x42 = data[46:84,1]
#2
erf1 = seq(1/45, 1, len = 45)
erf2 = seq(1/84, 1, len = 39)
x41s = sort(x41);
x42s = sort(x42)
plot(x41s, erf1, xlab = "Середній бал", ylab = "ЕФР", xlim = c(155, 200),
main = "Середній бал", type = "s", col = 2, col.main = "brown", cex.main = 1.2)
points(x42s, erf2, col = 3)
legend(175, 0.2, c("Зараховані","Незараховані"), col=c(2,3), pch=c(0, 1),
bty = "y", lty=c(1, 0))
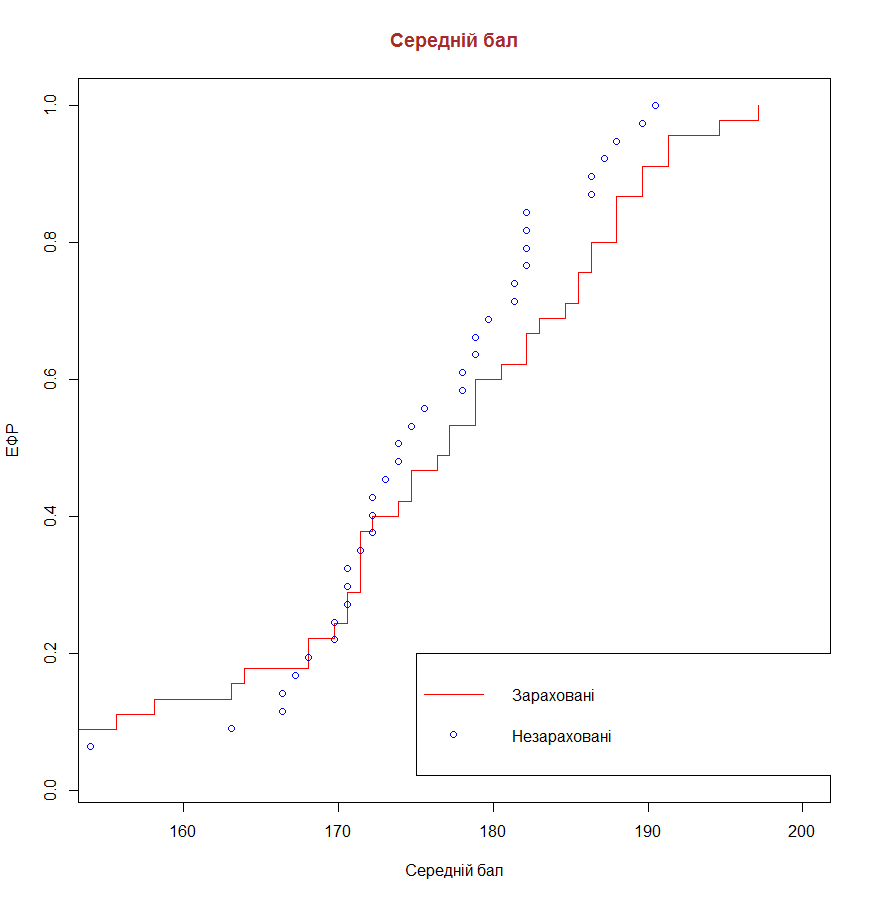
В данном графике наблюдается наличие существенной разницы между выборками, но также существуют и точки пересечения между ними.
#3
windows(width = 25, height = 12)
old.par=par(mfrow=c(1,2)) # расположение 3-гистограмм друг под другом (3 по горизонтали и 3 по вертикали)
boxplot(x11, x21, x31, x41, col = c(3:6), border = c(9:11), notch = TRUE, main = "Зараховані",
names = c("Фізика", "Математика", "УМЛ", "Середній бал"), col.main = "brown", cex.main = 1.2)
boxplot(x12, x22, x32, x42, col = c(3:6), border = c(9:11), notch = TRUE, main = "Незараховані",
names = c("Фізика", "Математика", "УМЛ", "Середній бал"), col.main = "brown", cex.main = 1.2)
par(old.par)


Из данных диаграмм можно сделать вывод, что выборки неоднородные т.к. разница между показателями достаточно велика.
#4
quantile(x41)
0% 25% 50% 75% 100%
124.90 170.55 177.19 185.49 197.11
quantile(x42)
0% 25% 50% 75% 100%
149.800 170.135 173.870 181.755 190.470
|
|
Мін |
25% |
50% |
75% |
Макс |
|
Физика, зараховані |
144.5 |
157.5 |
165.0 |
177.5 |
195.0 |
|
Физика, незараховані |
125.5 |
154.5 |
162.5 |
171.5 |
198.5 |
|
Математика, зараховані |
141.0 |
156.5 |
167.5 |
180.5 |
194.5 |
|
Математика, незараховані |
140.0 |
149. 0 |
157.5 |
169.0 |
199.0 |
|
Укр. мова, зараховані |
126.5 |
158.5 |
168.0 |
178.5 |
192.5 |
|
Укр. мова, незараховані |
125.0 |
151.5 |
161.5 |
169.5 |
198.5 |
|
Середній бал атестату, зараховані |
124.9 |
170.55 |
177.19
|
185.49 |
197.11 |
|
Середній бал атестату, незараховані |
149.8
|
170.135 |
173.87 |
181.755 |
190.47 |
Из приведённых данных можно сделать вывод, что квантели распределения средних баллов аттестатов в большинстве случаев больше, чем баллы распределения результатов ЗНО.
#5
windows(width = 20, height = 10)
old.par=par(mfrow=c(1,2))
qqnorm(x41, main = "Середній бал, зараховані", col = 2, col.main = "brown", cex.main = 1.2)
qqline(x41, col = 4)
qqnorm(x42, main = "Середній бал, незараховані", col = 3, col.main = "brown", cex.main = 1.2)
qqline(x42, col = 4)
par(old.par)
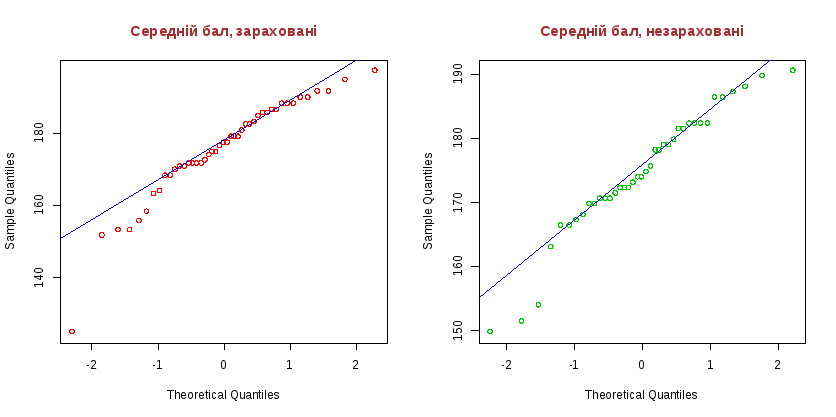 Здесь
видно, что в обоих случаях существуют
отклонения от нормального распределения.
Здесь
видно, что в обоих случаях существуют
отклонения от нормального распределения.
В таблице «Средний балл, зачисленные», это отклонения больше, чем в таблице «Средний балл, не зачисленные».
#6
shapiro.test(x41);
Shapiro-Wilk normality test
data: x41
W = 0.9195, p-value = 0.004075
shapiro.test(x42)
Shapiro-Wilk normality test
data: x42
W = 0.9479, p-value = 0.06995
ad.test(x41);
Anderson-Darling normality test
data: x41
A = 0.7744, p-value = 0.04099
ad.test(x42)
Anderson-Darling normality test
data: x42
A = 0.536, p-value = 0.1594
lillie.test(x41);
Lilliefors (Kolmogorov-Smirnov) normality test
data: x41
D = 0.1195, p-value = 0.1101
lillie.test(x42)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x42
D = 0.1023, p-value = 0.3831
|
Вибірка |
Критерії |
|||||
|
Шапіро – Уїлка |
Андерсона – Дарлінга
|
Ліллієфорса
|
||||
|
W |
p-value |
A |
p-value |
D |
p-value |
|
|
Середній бал атестату, зараховані |
0.9195 |
0.004075 |
0.7744 |
0.04099 |
0.1195 |
0.1101 |
|
Середній бал атестату, не зараховані |
0.9479 |
0.06995 |
0.536 |
0.1594 |
0.1023 |
0.3831 |
При выбранном уровне значимости 0.1 и исходя из приведённых в таблице данных можно сделать вывод, что принятие нулевой гипотезы возможно в критерии Андерсона-Дарлинга для не зачисленных абитуриентов и в критерии Лиллиефорса для зачисленных и не зачисленных абитуриентов. В случае с критериями Андерсона-Дарлинга для зачисленных абитуриентов и Шапиро-Уилка для зачисленных и не зачисленных абитуриентов, нулевая гипотеза откланяется.
#7
adhf1 = stack(data.frame(x11,x21,x31,x41))
adhf2 = stack(data.frame(x11,x21,x31,x41))
kruskal.test(values ~ ind, data=adhf1)
kruskal.test(values ~ ind, data=adhf2)
fligner.test(values ~ ind, data=adhf1)
fligner.test(values ~ ind, data=adhf2)
library(car)
leveneTest(values ~ ind, data=adhf1)
leveneTest(values ~ ind, data=adhf2)
|
Выбрка |
Критерии |
|||||
|
Краскел-Уоллес |
Левене |
Флигнер-Киллен |
||||
|
K-W |
p-value |
F |
Pr(>F) |
F-K |
p-value |
|
|
Показатели, зачисленные |
26.9876 |
5.923e-06 |
0.3127 |
0.8162 |
1.4508
|
0.6937 |
|
Показатели, не зачисленные |
62.4268 |
1.781e-13 |
0.714 |
0.545 |
2.2804 |
0.5163 |
Исходя из критерия Краскела-Уоллеса, мы отклоняем гипотезу об однородности центров, т. к. значение p-value не соответсвует заданному уровню значимости. Так же, глядя на критерии Левене и Флигнера-Киллена, мы можем сделать вывод, что значение p-value позволяет нам принять гипотезу об однородности дисперсий.