

V. Системы управления бд: общие сведения
Общие сведения о СУБД
Место БД при различной архитектуре вычислительной системы
Модели данных
Язык описания данных
Язык манипулирования данными для реляционной модели – SQL
Общие сведения о СУБД
Первыми СУБД в России начали пользоваться в конце семидесятых годов. К концу восьмидесятых годов СУБД стали основным инструментом для организации быстрого и эффективного доступа к данным. Применение СУБД не всегда увенчалось успехом. Но это было связано, главным образом, не с программными средствами, а с отсутствием хорошо нормализованных данных и психологическими причинами – не восприятие программистами таких средств.
Создавая БД, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать данные с произвольным сочетанием признаков. Сделать это очень трудно, если данные плохо формализованы или не структурированы. Неструктурированными называют данные, записанные, например, в текстовом файле. Формализованные данные – это структурированные данные, представленные, например, в закодированном виде с помощью классификаторов или без них, но записываемых по каким-либо правилам (например, есть, нет).
Централизованный характер управления данными в БД предполагает необходимость существования некоторого лица (группы лиц) – администратор БД, на которого возлагаются функции, связанные с созданием, хранением, выборкой данных.
Определим основные понятия, необходимые для построения концептуальной модели БД [http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85].
Предметная область - часть реального мира, подлежащего изучению для организации управления и, в конечном счете, автоматизации, например, предприятие, любой объект материального мира.
БД – это данные, организованные в виде набора записей определенной структуры и хранящиеся в файлах, где помимо самих данных, содержится описание их структуры и связей таблиц.
СУБД – это программно-технологический комплекс, интегрирующий аппаратные средства, БД на технических носителях, программное обеспечение управления данными в самом широком смысле этого термина (операции выборки, линейных преобразований БД и др.), а также программируемую логику и набор процедур.
DDL (Data Definition Language) – язык описания данных (ЯОД) позволяет описать базу данных в терминах, принятых в конкретной СУБД.
DML (Data Manipulation Language) – язык манипулирования данными (ЯМД) позволяет управлять данными (выбирать, сортировать, создавать и др.).
Объект (сущность) - это такое абстрактное множество предметов (экземпляров), в множестве которых все они имеют одни и те же свойства (характеристики).
Модель данных - совокупность структур данных и операций их обработки.
Таблица – основная единица хранения данных БД, состоит из имени таблицы, строк и столбцов.
Плоские файлы - набор упорядоченных однородных записей, каждая из которых содержит некоторый набор полей (атрибутов).
Схема – коллекция объектов БД, содержащая таблицы, индексы, кластеры, представления (виды), журналы репликации, линки, последовательности, синонимы, пакеты, хранимые процедуры, функции, триггеры, библиотеки внешних процедур.
Связь - это абстракция набора отношений, которые систематически возникают между различными видами предметов в реальном мире. Существуют три вида связи: «один к одному», «один ко многим» и «многие ко многим».
View-представление – это временная или «материализованная» таблица, созданная СУБД для обработки данных из одной или более таблиц. С видами можно делать те же операции, что и с таблицами (строить запросы, обновлять, удалять). Кроме того представления могут использоваться для ограничения доступа пользователей к некоторым данным.
Атрибут - это столбец с заголовком (именем) и значениями, превращающийся в последующем в поле БД, имеющий имя, тип и другие свойства.
Запрос – это транзакция “только для чтения”. Запрос генерируется с помощью команды SELECT. Различие между обычной транзакцией и запросом состоит в том, что при запросе данные не изменяются.
Кортеж – строка таблицы, превращающаяся в последующем в запись файла БД.
Кэш – область памяти для быстрого доступа к данным. С точки зрения аппаратного обеспечения – это небольшой (применительно к оперативной памяти) объем памяти, который значительно быстрее основной памяти. Этот объем памяти используется для снижения времени, необходимого на частую загрузку данных или инструкций в центральный процессор (ЦП). ЦП сам по себе содержит встроенный кэш.
Процедура – это набор SQL команд, который выполняет определенную задачу.
Репликация - процесс синхронизации в распределенной БД таблиц и представлений, на основе которых они созданы.
Транзакция – логически-завершенный фрагмент последовательности действий (одна или более SQL-команд, завершенных фиксацией или откатом). Это единицы обработки данных, обладающие свойствами, существенными с точки зрения традиционных СУБД: атомарность (выполняются либо все действия, либо ни одного), сериализуемость (разные транзакции не оказывают воздействия друг на друга) и долговечность (если транзакция зафиксирована, то ее результат не пропадет даже в случае краха системы).
Триггер – блок инструкций SQL в виде процедур, которые могут автоматически запускаться при выполнении команд INSERT, UPDATE или DELETE.
Функция – это совокупность SQL или PL/SQL-команд, которая реализует определенную задачу (например, статистические функции).
Хранимая процедура – это предопределенный SQL-запрос, хранимый в системе.
Атрибут - элементарная единица логической организации данных. Для описания атрибута используются следующие характеристики:
имя – формализованное обозначение атрибута;
тип - формат хранения атрибута (символьный, числовой, дата);
ключ – один из тематических атрибутов или специально назначенный атрибут, однозначно идентифицирующий запись;
длина - максимально возможное количество символов, которое может храниться с помощью атрибута;
точность - для числовых данных число десятичных знаков, необходимых для отображения дробной части числа.
Запись - совокупность логически связанных атрибутов.
Экземпляр записи - отдельная реализация записи, содержащая конкретные значения ее атрибутов.
Индекс - это упорядоченный список значений и ссылок на записи, в которых хранятся эти значения.
Таблица - совокупность экземпляров записей одной структуры.
При описании структуры записи файла указываются атрибуты, значения которых являются ключами: первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
Описание логической структуры записи файла содержит последовательность расположения полей записи и их основные характеристики, как это показано в табл.1.
Таблица 1 - Описание логической структуры записи файла БД
|
Имя файла | |||||
|
Атрибут |
Признак ключа |
Формат атрибута | |||
|
Имя (обозначение) |
Наименование |
Тип |
Длина |
Точность | |
|
name |
Краткое название организации |
ПК |
char |
15 |
0 |
|
Имя n |
….. |
….. |
… |
…. |
…. |
Создание БД на основе СУБД включает:
выбор архитектуры реализации БД (централизованная, распределенная, др.);
выбор модели данных;
нормализацию данных и определение таблиц, которые должны содержать БД;
определение необходимых в таблице атрибутов;
задание индивидуального значения каждому атрибуту;
определение связей между таблицами.
Место БД при различной архитектуре вычислительной системы
С
SQL
П
БД
Клиент СУБД SQL Клиент


К
SQL
Клиент
Клиент
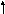
Рисунок 1 - Централизованный вариант (персональный)
Файл-сервер. При такой архитектуре предполагается выделение одной из машин сети для хранения БД (сервер файлов), которая совместно используется всеми пользователями. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользователей к БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно. Концепция файл-сервер условно отображена на рис.2. Ярким примером такой архитектуры является возможность хранения БД ACCESS на файле сервере. Производительность такой архитектуры зависит от компьютера пользователя, значительно загружается сеть для передачи данных. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает.
Р исунок
2 - Архитектура файл - сервер
исунок
2 - Архитектура файл - сервер
К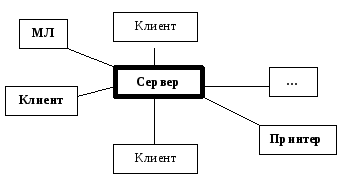 лиент-сервер.
В этой архитектуре подразумевается,
что помимо хранения централизованной
БД (сервер БД) должен обеспечивать
выполнение основного объема обработки
данных. Запрос на данные, посылаемый
клиентом (рабочей станцией), порождает
поиск и извлечение данных на сервере.
Извлеченные данные транспортируются
по сети от сервера к клиенту. Концепция
клиент-серверной архитектуры условно
изображена на рис.3.
лиент-сервер.
В этой архитектуре подразумевается,
что помимо хранения централизованной
БД (сервер БД) должен обеспечивать
выполнение основного объема обработки
данных. Запрос на данные, посылаемый
клиентом (рабочей станцией), порождает
поиск и извлечение данных на сервере.
Извлеченные данные транспортируются
по сети от сервера к клиенту. Концепция
клиент-серверной архитектуры условно
изображена на рис.3.
Рисунок 3 - Клиент серверная архитектура
В современных СУБД используется архитектура клиент – сервер, когда БД хранится на сервере, а СУБД подразделяется на две части – клиентскую и серверную.
Чтобы уменьшить объем передачи данных, которые должны подвергаться прикладной обработке, используется трехуровневая архитектура: тонкий клиент – сервер приложений – сервер БД, рис.4. Тонкий клиент обеспечивает взаимодействие с пользователем через браузер, вся прикладная обработка выносится на сервер приложений, который обеспечивает формирование запроса к БД. При этом сервер БД и сервер приложений могут функционировать в различных ОС.
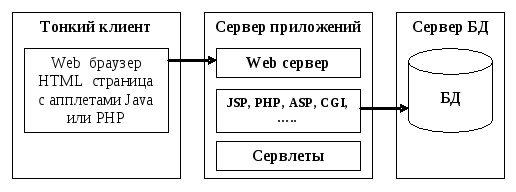
Рисунок 4 - Трехуровневая архитектура
Модели данных
Основными моделями данных являются иерархическая, сетевая, реляционная, постреляционная, многомерная модели данных или комбинация этих моделей. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными [1,2,4]. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Описание (модель) предметной области, выполненное без ориентации на используемые в дальнейшем программные и технические средства, называется концептуальной (инфологической) моделью предметной области. Концептуальная модель предметной области указывает, какая информация будет содержаться и обрабатываться в проектируемой системе, не касаясь вопросов, как это будет реализовано. Структура данных, описывающая предметную область на инфологическом уровне, является проблемно-ориентированной и системно-независимой, то есть независимой от конкретной СУБД, ОС и аппаратного обеспечения.
Иерархическая модель данных стала применяться в шестидесятых годах, строится по принципу иерархии типов объектов, т. е. один тип объекта является главным, а остальные, находящиеся на низших уровнях иерархии,— подчиненными. Иерархическая модель данных организует данные в виде иерархической древовидной структуры. Эта структура строится из узлов и ветвей. Узел представляет собой совокупность атрибутов данных, описывающих некоторый объект. Наивысший узел в иерархической древовидной структуре называется корнем. Зависимые узлы располагаются на более низких уровнях дерева. Зависимые узлы могут добавляться как в вертикальном, так и в горизонтальном направлении без всяких ограничений. Связи (соединения) между узлами уникальны, Поэтому иерархическая модель данных обеспечивает только линейные пути доступа к данным и между главными и подчиненными типами объекта устанавливается линейная взаимосвязь “один ко многим». Каждый экземпляр корневого узла образует начало записи логической БД, т.е. иерархическая БД состоит из нескольких деревьев. Примером такой модели данных является описание комплектующих автомобиля (ручки, окна, болты, др.), рис.5. Примером иерархической СУБД является СУБД «Ока».
Достоинствами иерархической модели является то, что они наиболее полно отражают семантику предметной области; имеют развитые низкоуровневые средства управления данными во внешней памяти; позволяют построить эффективные прикладные системы. Иерархическая модель более естественно для человека отражает семантику предметной области. Поэтому она проста в понимании и использовании. Схема БД не декларируется явным образом и может изменяться в процессе развития и эксплуатации информационной системы.
Недостатки иерархической модели это громоздкие структуры данных при сложных БД и, как правило, - хранение избыточных данных; доступ к БД производится на уровне записей, между которыми поддерживаются явные связи, следствиями этого являются низкоуровневый навигационный стиль программирования и сложность использования таких систем непрограммистами; отсутствует физическая и логическая независимость данных, необходимы знания об их физической организации; пользователю приходится выполнять оптимизацию доступа к БД без поддержки системы.
Рисунок 5 - Фрагмент иерархической модели данных
В сетевой модели данных (рис.6), которая начала применяться в начале восьмидесятых годов, понятия главного и подчиненных объектов несколько расширены. Любой объект может быть и главным, и подчиненным (в сетевой модели главный объект обозначается термином «владелец набора», а подчиненный — термином «член набора»). Один и тот же объект может одновременно, выступать и в роли владельца, и в роли члена набора. Это означает, что каждый объект может участвовать в любом числе взаимосвязей. БД состоит из нескольких областей. Область содержит записи. В свою очередь запись состоит из полей, а набор, который объединяет записи, может размещаться в одной или нескольких областях. Достоинство сетевой модели это простота реализации часто встречающихся в реальном мире взаимосвязей, закладываемых в БД. Основной недостаток сетевой модели состоит в сложности управления данными, в т.ч и возможная потеря независимости данных при реорганизации БД. Сетевая модель использовалась в СУБД СЕТОР.

Рисунок 6 - Фрагмент сетевой БД
Реляционная модель была предложена в семидесятых годах, но получила широкое распространение только в середине восьмидесятых годов. В реляционной модели данных (рис.7) объекты и взаимосвязи между ними представляются с помощью таблиц. Взаимосвязи рассматриваются в качестве объектов (таблиц связей). Каждая таблица представляет один объект. В терминологии реляционной модели таблица называется отношением. Каждый столбец в таблице является атрибутом. Объекты (сущности) предметной области отображаются двумерной таблицей с заголовками, состоящими из имени и типа сущности. Строки такой таблицы представляют собой перечень атрибутов сущности. Назначается один или несколько атрибутов первичным ключом для поиска информации. Значения в столбце выделяются из домена, т.е. домен суть множество значений, которые может принимать некоторый атрибут. Для каждого атрибута всех таблиц фиксирован тип и длина данных. Соединение данных из разных таблиц обеспечивается операторами языка SQL.
Первичный ключ – это столбец, значения которого во всех строках разные. Он может объединять несколько столбцов. В некоторых СУБД первичный ключ может задаваться системой (ACCESS, Oracle). Связь реализуется при помощи внешнего ключа (это столбец таблицы, значения которого совпадают со значениями первичного ключа другой таблицы). Важным моментом является также использование значения NULL в таблицах реляционной БД. NULL – это отсутствующее значение информации в поле. Это поле обрабатывается особым образом.
Р исунок
7 – Фрагмент реляционной БД
исунок
7 – Фрагмент реляционной БД
Реляционными СУБД являются DB2, Oracle, Paradox, Access, MySQL и др.
Достоинствами реляционной модели является простой и мощный математический аппарат, опирающийся на теорию множеств и математическую логику и обеспечивающий теоретический базис организации БД; обеспечение физической и логической независимости данных. Единственной конструкцией данных в реляционной модели является отношения (связи) между данными (на основании значений данных, а не физических указателей, как в ранних системах). Следствием этого является ненавигационный доступ к данным (отношения трактуются как операнды и результаты операции, а не обрабатываются поэлементно). Простота структуры данных и управления ими облегчает работу пользователей (как программистов, так и непрограммистов).
Недостатками реляционной модели являются минимальные возможности описания семантики предметной области. Рядовые реляционные системы работают медленнее систем, базирующихся на сетевой или иерархической модели данных. Рассмотрим эту модель более подробно.
Основными целями проектирования реляционной БД является сокращение избыточности хранимых данных, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможных противоречий из-за хранения в разных местах однородных сведений, обеспечение быстрого доступа к данным, обеспечение целостности данных. Целостность данных позволяет при изменении свойств одних объектов автоматически производить соответствующие изменения связанных с ними объектов.
Правила Кодда, которые необходимо использовать при создании реляционной БД:
реляционная СУБД должна управлять БД, используя связи между данными;
вся информация в реляционной БД (включая имена таблиц и столбцов) должна определяться на основе выбранных правил именования;
любое значение БД должно быть гарантированно доступным через комбинацию имени таблицы, первичного ключа и имени столбца;
СУБД должна уметь работать с пустыми значениями (пустое значение - это неизвестное, независимое, неприменимое значение, в отличие от значений по умолчанию и обычных значений);
описание БД и каталог содержимого БД должны быть определены на логическом уровне через таблицы, к которым можно применять запросы, используя язык манипулирования данными;
язык манипулирования данными должен поддерживать определение данных и манипулирование ими, правила целостности, авторизацию и транзакции;
все представления, теоретически обновляемые, могут быть обновлены через систему;
СУБД поддерживает не только запрос на данные, но и вставку, обновление и удаление;
физическая независимость данных - логика программ-приложений остается прежней при изменении физических методов доступа к данным и структур хранения;
логическая независимость данных - логика программ-приложений остается прежней, в пределах разумного, при изменении структур таблиц;
язык БД должен быть способен определять ограничения целостности, ограничения должны быть доступны из оперативного каталога и не должно быть способа их обойти;
несмешиваемость - невозможность обойти ограничения целостности, используя языки низкого уровня.
Рекомендациями по выделению сущностей. Имя сущности должно отражать суть объекта. Сущности не должны пересекаться с другими сущностями. В одной сущности должно быть не меньше двух и оптимально 8 атрибутов. У каждой сущности должен быть уникальный идентификатор. Все сущности одной БД должны быть связаны. Для всех сущностей должна быть реализована хотя бы одна функция по созданию, поиску, корректировке, удалению, архивированию и использованию значения сущности. Все изменения сущности должны фиксироваться в файле истории изменений. Все сущности должны быть нормализованы. Не дублируйте сущности из других прикладных систем.
Рекомендации по определению атрибутов. Наименование атрибута должно быть существительным единственного числа, отражающим суть обозначаемого атрибутом свойства. Наименование атрибута не должно включать в себя имя сущности. Каждый атрибут должен иметь только одно значение в каждый момент времени. В таблице должны отсутствовать повторяющиеся значения атрибутов. У всех атрибутов должны быть описаны формат, длина, допустимые значения, алгоритм получения и т.п. Проверьте, если значение атрибута является обязательным, то всегда ли известны все значения. Группировка атрибутов в таблицах должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления.
Для совершенствования таблиц реляционной модели данных применяется методология нормализации отношений. Нормализация – разбиение таблицы на две и более, обладающих лучшими свойствами при включении, изменении и удалении данных. Цель нормализации сводится к получению такого проекта БД, в котором каждый факт отображается лишь в одном месте, т.е. в проекте должна быть исключена избыточность информации. Нормализация – это формальный аппарат ограничений на формирование таблиц, который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в БД, уменьшает трудозатраты на ведение (ввод, корректировку) БД.
Каждая таблица реляционной модели данных должна удовлетворять условию, в соответствии с которым в позиции пересечения каждой строки и столбца таблицы всегда находится единственное атомарное значение (недопустимо множество таких значений). Любая таблица, удовлетворяющая этому условию, называется нормализованной. Существует несколько уровней нормализации.
Первая нормальная форма (1НФ). Таблица, находящаяся в первой нормальной форме должна отвечать следующим требованиям: таблица не должна иметь повторяющихся записей; в таблице должны отсутствовать повторяющиеся группы атрибутов. Для приведения к 1НФ можно использовать следующий алгоритм.
Определить атрибут, который можно назначить первичным ключом. Если такого атрибута нет, то надо добавить новый уникальный ключевой атрибут. Определить группы повторяющихся атрибутов. Вынести группы повторяющихся атрибутов в отдельные таблицы, в основной таблице остается один атрибут для организации связи между таблицами. Назначить первичные ключи в новых таблицах. Если ключевой атрибут имеет большой размер, предпочтительней добавлять новый атрибут. Определить тип отношения между таблицами.
Пример нормализации в 1НФ. Перечень возможных атрибутов, характеризующих заказ, включает дату заказа, ФИО клиента, телефон клиента, номер счета, название товара, цена, производитель, индекс фирмы производителя, адрес, количество товара, оплата. Поскольку один клиент может в течение одного дня сделать несколько заказов, таблица может содержать одинаковые строки. На один и тот же товар может поступить несколько заказов, и, наконец, фирма производитель может поставлять несколько товаров. Таблицы могут содержать следующие данные, табл.2, 3:
Таблица 2 - Описание заказа
|
Дата заказа |
ФИО |
Телефон |
Счет |
Наименование товара |
|
01-08-2009 |
Иванов И.И. |
1234567 |
1234567890123456789 |
Часы |
|
01-08-2009 |
Сидоров И.И. |
7654321 |
2345678901234567890 |
Ручки |
|
02-08-2009 |
Петров П.П. |
2345678 |
3456789012345678901 |
Карандаши |
|
03-08-2009 |
Владимиров В.В. |
3456789 |
4567890123456789012 |
Тетрадки |
Таблица 3 - Описание товара
|
Цена |
Производитель |
Почтовый индекс |
Адрес |
Количество |
Оплата |
|
350.00 |
«Восток» |
123456 |
Королева, 6 |
85 |
Да |
|
15.00 |
«Канцтовары» |
234567 |
Гагарина, 24 |
74 |
|
|
5.00 |
«Канцтовары» |
234567 |
Гагарина, 24 |
25 |
|
|
25.00 |
«Канцтовары» |
234567 |
Гагарина, 24 |
36 |
Да |
Приведем таблицу к 1НФ. Выделим следующие сущности: заказы, клиенты, товары, производители. Добавим в таблицу «Заказ» поле «Номер заказа», что позволит однозначно идентифицировать каждый из заказов. Таблица содержит три группы повторяющихся атрибутов. Атрибуты, характеризующие клиента «ФИО», «Телефон», «Счет», вынесем в таблицу «Клиенты». Атрибуты, характеризующие товар «Наименование товара» и «Цена», вынесем в таблицу «Товары». Атрибуты, характеризующие производителя «Производитель», «Почтовый индекс», «Адрес» вынесем в таблицу «Производители».
В таблицу «Клиенты» добавим новый атрибуте «Номер клиента», который будет однозначно идентифицировать каждую запись таблицы, в таблицу «Товары» - «Номер товара», в таблицу «Производители» - «Номер производителя».
Для организации связи между таблицами по совпадающим атрибутам, добавим в таблицу «Заказы» поля «Номер клиента» и «Номер товара», а в таблицу «Товары» - «Номер производителя» для организации связи.
Таким образом, данные из таблиц 2 и 3 примут следующий вид - таблицы 4-7.
Таблица 4 – Описание заказа
|
Заказ |
Дата |
Идентификатор клиента |
Идентификатор товара |
Идентификатор производителя |
Количество товаров |
Оплата |
|
1 |
01-08-2009 |
1 |
1 |
1 |
85 |
Да |
|
2 |
01-08-2009 |
1 |
2 |
2 |
74 |
|
|
3 |
02-08-2009 |
2 |
3 |
2 |
25 |
|
|
4 |
03-08-2009 |
3 |
4 |
2 |
36 |
Да |
Таблица 5 – Описание клиентов
|
Идентификатор клиента |
ФИО |
Телефон |
Счет |
|
1 |
Иванов И.И. |
1234567 |
1234567890123456789 |
|
2 |
Сидоров И.И. |
7654321 |
2345678901234567890 |
|
3 |
Петров П.П. |
2345678 |
3456789012345678901 |
|
4 |
Владимиров В.В. |
3456789 |
4567890123456789012 |
Таблица 6 – Описание товара
|
Идентификатор товара |
Наименование товара |
Цена |
Идентификатор производителя |
|
1 |
Часы |
350.00 |
1 |
|
2 |
Ручки |
15.00 |
2 |
|
3 |
Карандаши |
5.00 |
2 |
|
4 |
Тетрадки |
25.00 |
2 |
Таблица 7 – Описание производителей
|
Идентификатор производителя |
Производитель |
Почтовый индекс |
Адрес |
|
1 |
«Восток» |
123456 |
Королева, 6 |
|
2 |
«Канцтовары» |
234567 |
Гагарина, 24 |
Вторая нормальная форма (2НФ). Таблица, находящаяся во второй нормальной форме должна отвечать всем требованиям 1НФ, а также любое не ключевое поле однозначно идентифицируется полным набором ключевых полей. 2НФ применяется к таблицам, которые имеют составной ключ. Частично зависимое поле зависит только от части ключа.
Пример нормализации во 2НФ. Перечень возможных атрибутов, характеризующих проекты, включает название и код проекта, цель проекта, дата начала и окончания проекта, руководитель, телефон. Пусть таблица имеет составной ключ, который формируется по двум атрибутам: «Код проекта», «Код руководителя проекта». Атрибуты «Название», «Цель», «Дата начала, окончания», «Руководитель», «Телефон» являются частично зависимыми. Атрибуты «Название», «Цель», «Дата начала и окончания» зависят только от «Проекта», но не зависят от «Руководителя», т.е. однозначно идентифицируется частью ключа, а не полным набором ключевых полей. Аналогично поля «Руководитель» и «Телефон» зависят только от «Руководителя». Для приведения к 2НФ необходимо вынести все частично зависимые поля в отдельную таблицу; определить ключевые поля; установить отношения между таблицами 8 и 9.
Таблица 8 – Сведения о проектах
|
Код проекта |
Название |
Цель |
Дата начала |
Дата окончания |
Руководитель |
|
1 |
Балтика |
Исследование климата |
01-01-1990 |
31-12-1995 |
1 |
|
2 |
Баренц |
Проводка судов |
01-01-1996 |
31-12-1999 |
2 |
Таблица 9 – Сведения о руководителях проектов
|
Код руководителя |
ФИО |
Телефон |
|
1 |
Иванов И.И. |
1234567 |
|
2 |
Петров П.П. |
2345678 |
Третья нормальная форма (3НФ). Таблица, находящаяся в третьей нормальной форме должна отвечать всем требованиям 2НФ, а также ни одно из не ключевых полей не идентифицируется при помощи другого не ключевого поля. Другими словами в таблице нет полей, которые не зависят от ключа. Рассмотрим пример нормализации в 3НФ, перечень возможных атрибутов, характеризующих заказы и менеджеров, включает код заказа, покупатель, дата продажи, менеджер (табл.10).
Таблица 10 – Сведения о заказах
|
Код заказа |
Покупатель |
Дата продажи |
Менеджер |
Код менеджера |
|
1 |
Иванов И.И. |
01-11-2007 |
Сидоров С.С, |
1 |
|
2 |
Петров П.П. |
01-11-2007 |
Михайлов М.М. |
2 |
Таблица не находится в 3НФ, т.к. не ключевое поле «Менеджер» зависит от другого не ключевого поля «Код менеджера». Для приведения к 3НФ необходимо поле «Менеджер» вынести в отдельную таблицу. Таким образом, в результате создается две таблицы 11 и 12.
Таблица 11 – Сведения о заказах
|
Код заказа |
Покупатель |
Дата продажи |
Код Менеджера |
|
1 |
Иванов И.И. |
01-11-2007 |
1 |
|
2 |
Петров П.П. |
01-11-2007 |
2 |
Таблица 12 – Сведения о менеджерах
|
Код Менеджера |
Менеджер |
|
1 |
Сидоров С.С, |
|
2 |
Михайлов М.М. |