

Алгоритм Хаффмана
Алгоритм Хаффмана — это еще один алгоритм получения префиксных кодов переменной длины. В отличие от алгоритма Шеннона—Фано, который предусматривает построение кодового дерева сверху вниз, данный алгоритм подразумевает построение кодового дерева в обратном порядке, то есть снизу вверх (от листовых узлов к корневому узлу).
На первом этапе, как и в алгоритме Шеннона—Фано, исходная последовательность символов сортируется в порядке убывания частоты повторяемости символов (элементов последовательности). Для рассмотренного ранее примера со словом «авиакатастрофа» получим следующую отсортированную последовательность элементов: {а(5), т(2), в(1), и(1), к(1), с(1), р(1), о(1), ф(1)}.
Далее два последних элемента последовательности заменяются на новый элемент S1, которому приписывается повторяемость, равная сумме повторяемостей исходных элементов. Затем производится новая сортировка элементов последовательности в соответствии с их повторяемостью. В нашем случае два последних элемента o(1) и ф(1) заменяются на элемент S1(2), а вновь отсортированная последовательность примет вид: {а(5), т(2), S1(2), в(1), и(1), к(1), с(1), р(1)}.
Продолжая данную процедуру замещения двух последних элементов последовательности на новый элемент с суммарной повторяемостью и последующей пересортировкой последовательности в соответствии с повторяемостью элементов, мы придем к ситуации, когда в последовательности останется всего один элемент (рис. 4).

Рис. 4. Демонстрация алгоритма Хаффмана на примере слова «авиакатастрофа»
Одновременно с замещением элементов и пересортировкой последовательности строится кодовое бинарное дерево. Алгоритм построения дерева очень прост: операция объединения (замещения) двух элементов последовательности порождает новый узловой элемент на кодовом дереве. То есть если смотреть на дерево снизу вверх, ребра кодового дерева всегда исходят из замещаемых элементов и сходятся в новом узловом элементе, соответствующем элементу последовательности, полученному путем замещения (рис. 5). При этом левому ребру кодового дерева можно присвоить значение «0», а правому — «1». Эти значения в дальнейшем будут служить элементами префиксного кода.

Рис. 5. Построение кодового дерева в алгоритме Хаффмана (замещение элементов «o» и «ф» новым элементом S1)
Полное кодовое дерево, построенное по алгоритму Хаффмана для слова «авиакатастрофа», показано на рис. 6.
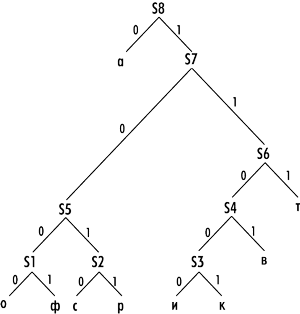
Рис. 6. Полное кодовое дерево для слова «авиакатастрофа», построенное по алгоритму Хаффмана
Пройдясь по ребрам кодового дерева сверху вниз, легко получить префиксные коды для всех символов нашего информационного алфавита:
a-{0}
т{111}
в{1101}
и{11000}
к{11001}
с{1010}
р{1011}
о{1000}
ф{1001}
Если теперь попытаться написать слово «авиакатастрофа» в кодировке Хаффмана, то получим 41-битную последовательность 0 1101 11000 0 11001 0 111 0 1010 111 1011 1000 1001 0. Интересно отметить, что при использовании префиксных кодов Шеннона—Фано мы также получим 41-битную последовательность для слова «авиакатастрофа». То есть в конкретном примере эффективность кодирования Хаффмана и Шеннона—Фано одинакова. Но если учесть, что реальный информационный алфавит — это 256 символов (а не 14, как в нашем примере), а реальные информационные последовательности — это любые по своему содержанию и длине файлы, то возникает вопрос об оптимальном префиксном коде, то есть коде, который позволяет получить минимальную по длине выходную последовательность.
Можно доказать, что система кодов, полученная с помощью алгоритма Хаффмана, —лучшая среди всех возможных систем префиксных кодов в том плане, что длина результирующей закодированной информационной последовательности получается минимальной. То есть алгоритм Хаффмана является оптимальным.
Основной недостаток алгоритма Хаффмана заключается в сложности процесса построения системы кодов. Тем не менее именно оптимальный алгоритм Хаффмана является самым распространенным алгоритмом генерации кода переменной длины и находит свое воплощение в большинстве утилит сжатия и архивации информации.