

978-5-7764-0767-3
.pdf45.Турчин В.Ф. Феномен науки: Кибернетический подход к эволюции. Изд.
2-е. – М.: ЭТС. – 2000.
46.Частиков А.П., Гаврилова Т.А., Белов Д.Л. Разработка экспертных си-
стем. Среда CLIPS. -СПб.: БХВ-Петербург, 2003. – 608 с.
47.Greisdorf H. Relevance: An Interdisciplinary and Information Science Perspective. Informing Science, 3(2): 67-72, 2000.
48.Laffey TJ.et ol Real-time knowledge-based system, AIMagaiine, 9(1), pp 2745, 1988.
49.Ohsuga S., Yamauchi H. Multi-layer logic – a predicate logic including data structure as knowledge representation language. – New generation computing, Vol.3, NO.4, 1985. – С.451-485.
50.Rijsbergen C.V. Foundation of evaluation. Journal of Documentation,
4(30):365-373, 1974.
51.Shoppcrs M.E. Universal plans for reactive robots in unpredictable environments. In Proc. of IJCAI-87, 1987.
52.V.N.Vagin,E.Yu.Golovina Knowledge Model in Semiotic System.- Seventh Internation Conference Artificial Intelligence and Information-Control Systems of Robots AIICSR'97. Second Workshop on Appli ed Semiotics. September 15, 1997 Smolenice Castle, Slovakia, р.61-66
53.A-Wern, Reactive Abduction. In Proc. of ECAl-92. pp.159-163.
131
Глава 4. Системы управления базами эволюционирующих знаний
4.1. Развитие систем управления данными
Первые вычислительные машины и устройства были ориентированы на обработку чисел. Интерпретация чисел – входной и выходной информации,
возлагалась на программиста. Одной из его задач было обеспечение число-
вых значений соответствующим параметрам действительности. В это время возможности компьютеров по хранению информации были очень ограничен-
ными. С развитием вычислительной техники появляются новые задачи, тре-
бующие обработки не отдельных числовых значений, а массивов. Появляют-
ся информационные системы, представляющие собой программно-аппарат-
ные комплексы способные выполнять следующие функции:
надежное хранение информации;
решение прикладных задач, требующих выполнения специфических преобразований информации и вычислений;
удобный, интуитивно понятный для пользователя интерфейс.
Для решения таких задач уже требовались новые подходы, связанные с
управлением обработкой данных. Формируются и развиваются технологии баз данных.
История баз данных, начинается с 1955 г., когда появилось программи-
руемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. В конце
1960-х годов появилась концепция БД которая с тех пор постоянно развива-
ется. В развитии технологии обработки данных специалисты в области БД рассматривают несколько этапов [16].
На первом этапе, в начале 1960-х годов появляются технологии обра-
ботки данных, характеризующиеся следующими признаками [16]:
информация преимущественно хранится в файлах, которые последова-
тельно записываются на магнитных лентах;
132
требуется строгое соответствие физической структуры данных логиче-
ской;
архивирование осуществляется путем хранения нескольких копий фай-
лов;
каждая программа работает только со своими файлами;
логическая и физическая организация данных планируется программи-
стом;
изменения физической или логической организации данных требует пе-
реработки программы.
Основными недостатками первого этапа являются привязка файлов к
одной программе, трудоемкость разработки программ и необходимость до-
работки при изменении структуры данных.
К середине 1960 появились технологии второго этапа [16]. Для этих технологий характерны:
появление внешних устройств прямого доступа, обеспечивающих про-
извольный доступ к записям (прямой, индексно-последовательный);
появление и широкое использование процедур поиска записи по ключе-
вому полю (обычно одному);
возможность переноса файлов на другие внешние устройства без изме-
нения прикладных программ.
Но многие недостатки первого этапа остались и для второго.
В конце 1960-х годов начался третий этап развития технологии обра-
ботки данных [16]. На этом этапе произошло осознание необходимости цен-
трализации данных для доступа к ним различных приложений. Такой подход уменьшал избыточность и противоречивость информации, позволял прило-
жениям использовать стандартные средства доступа к данным. Это требова-
ло более сложной организации данных и реализации эффективного поиска записей по нескольким ключам.
Характерным для третьего этапа [16] стало появление первых систем управления базами данных (СУБД). Система управления базой данных пред-
133
ставляет собой совокупность языковых и программных средств для организа-
ции, пополнения, модификации и использования БД. В СУБД предусмотрен язык определения данных DDL, который позволяет пользователям определять структуру базы данных. Кроме того, в СУБД имеется язык управления данны-
ми DML, который позволяет пользователям вставлять, удалять и извлекать данные из базы данных. Важными функциями СУБД являются организация контроля за доступом пользователей к базе данных, поддержка безопасности и целостности данных. В классической СУБД также предусмотрен механизм со-
здания представлений, предназначенных для упрощения вида данных, с кото-
рыми имеют дело пользователи. В рамках третьего этапа развивались теория и практика построения иерархических и сетевых СУБД. В этих моделях связи данных описываются с помощью деревьев и графов общего вида.
С середины 1970-х годов начинается четвертый этап развития техноло-
гии баз данных. Он связан с появлением реляционной модели данных, благо-
даря работам Эдгара Ф. Кодда. Статья Э. Ф. Кодда, опубликованная в 1970
году [10,39], послужила основой для создания реляционной модели данных.
Замечательной особенностью этой модели хранения данных является мини-
мальное дублирование данных и исключение некоторых типов ошибок, свой-
ственных другим моделям. Для реляционной модели, данные хранятся в виде таблиц со столбцами и строками. Но не все виды таблиц могут использовать-
ся для реляционной модели. Поэтому нежелательные таблицы могут быть нормализованы для удовлетворения требованиям реляционной модели.
На четвертом этапе развития технологии баз данных были реализованы,
втой или иной степени, следующие основные характеристики СУБД:
–логическая и физическая независимость данных;
–возможность развития БД;
–обеспечение безопасности, секретности, целостности данных;
–использование различных запросов для поиска информации;
–наличие языковых средств для администратора, прикладного програм-
миста, пользователя.
134
Иерархические и сетевые системы представляют собой первое поколе-
ние СУБД. Реляционная модель, предложенная Э. Ф. Коддом, представляет собой второе поколение СУБД [10,16,39]. Третье поколение СУБД представ-
ляют объектно-реляционные СУБД и объектно-ориентированные СУБД.
С 1979 года стали широко использоваться СУБД для персональных ком-
пьютеров. Появление и развитие сетевых технологий привело к появлению клиент-серверной модели, а так же модели с совместным использованием файлов.
Дальнейший этап развития СУБД связан с возрастанием информацион-
ных потребностей и развитием сетевых технологий. Вначале возникли и ис-
пользовались сетевые СУБД файл-серверной архитектуры. База данных в локальной сети централизованно хранится на файл-сервере. На клиентских местах устанавливаются копии СУБД. Клиент-серверные СУБД могут мас-
штабироваться до сотен и тысяч рабочих мест. Всеобщее распространение,
подкрепленное стандартами, получил язык запросов SQL (Structured Query Language). Запрос к серверу формируется, как правило, на языке SQL, по-
этому клиент-серверные СУБД стали называть SQL-серверами.
Желание улучшить работу сетевых СУБД привело к появлению трех-
звенных СУБД, в которых добавлено промежуточное звено – сервер прило-
жений. Он является посредником между клиентом и сервером БД. Основная функция сервера приложений – полностью избавить клиента от забот по управлению данными.
Особенностью современных информационных технологий является распределенный характер информации. Развивающиеся распределенные СУБД могут содержать сотни серверов БД и работать в различных областях экономики. Внимание к распределенным СУБД во многом связано с успеш-
ным развитием Интернета.
К настоящему времени СУБД являются важной составной частью мно-
гих информационных систем, выполняя при этом такие основополагающие функции технологии БД, как:
135
–поиск с использованием различных запросов;
–хранение;
–целостность;
–поиск по нескольким критериям.
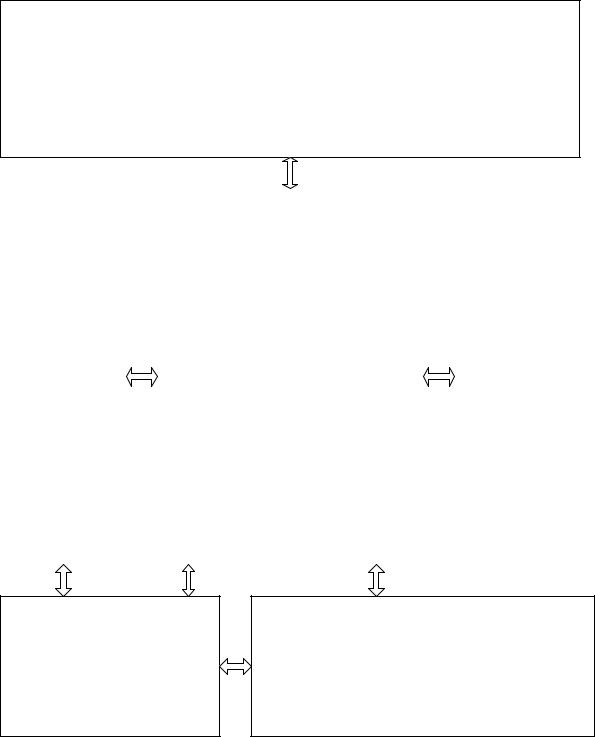
Концептуально структура современной СУБД представлена на рис. 4.1..
Здесь условно показано, что СУБД должна управлять внешней памятью, в
Интерфейсы и средства коммуникации
|
|
|
|
Разделяемая |
Средства |
|
Средства сопряжения с |
||
|
|
область |
||
коммуникации в |
|
другими компьютерными |
|
|
|
|
оперативной |
||
сети |
|
системами |
|
|
|
|
памяти |
||
|
|
|
|
|
|
|
|
|
|
|
Оперативная |
|
Ядро СУБД |
|
Физическая БД |
|||||
|
память |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Модуль управления данными во |
|
|
|
|
|
|
|
|
|
|
внешней памяти |
|
|
|
Файлы данных |
|
|
Разделяемая |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
область |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
оперативной |
|
|
|
|
|
|
|
|
|
|
|
Модуль управления буферами |
|
|
|
|
|
|||
|
памяти |
|
|
|
|
|
|
|
|
|
|
|
|
|
оперативной памяти |
|
|
|
Файлы журналов |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
Память СУБД |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
для прикладного |
|
|
|
Модуль управления транзакциями |
|
|
|
|
|
|
процесса 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Файлы |
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
системного |
|
|
. |
|
|
|
Модуль управления журналами |
|
|
|
каталога |
|
|
. |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
Память СУБД |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Вспомогательные |
|
|
|
для прикладного |
|
|
|
|
|
|
|
|
|
|
|
|
|
Транслятор SQL запросов |
|
|
||||
|
|
|
|
|
|
|
файлы |
|
||
|
процесса N |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Операционная
система
Средства прикладных процессов
Генераторы |
|
Средства |
|
|
|
формирования |
|
Прикладные |
|
форм и |
|
|
||
|
интерактивных |
|
программы |
|
отчетов |
|
|
||
|
запросов |
|
|
|
|
|
|
|
Рис. 4.1. Структура современной СУБД
136
которой расположены файлы с данными, файлы журналов и файлы систем-
ного каталога. На СУБД возлагаются также функции управления и оператив-
ной памятью, в которой располагаются буфера с данными, буфера журналов,
данные системного каталога для проверки целостности и проверки привиле-
гий пользователей. Во время работы СУБД в оперативной памяти располага-
ется информация, отражающая текущее состояние обработки запросов, в
оперативной памяти хранятся планы выполнения скомпилированных запро-
сов и др. сведения. В разделяемой области оперативной памяти содержатся фрагменты системного каталога, которые постоянно необходимы чтобы ускорить обработку запросов пользователей и операторы SQL с курсорами.
Фрагменты системного каталога в некоторых версиях СУБД называются словарем данных. Требования к системному каталогу определяются некото-
рыми стандартами SQL.
В общем виде работа СУБД может быть представлена следующим обра-
зом. Через блок интерфейсов и средств коммуникации поступает запрос на получение данных из базы данных. Проводится анализ прав источника за-
проса (пользователя) и внешней модели данных, соответствующей данному источнику запросов, подтверждается или запрещается доступ данного источ-
ника запросов к запрашиваемым данным. Если формируется запрет на доступ к данным СУБД, то об этом через блок интерфейсов и средств телекоммуни-
кации ставится в известность источник запросов и прекращается дальнейшая обработка данных. При положительном исходе анализа прав источника за-
просов, определяется часть концептуальной модели, которая соответствует запросу пользователя (источника запроса).
Ядро СУБД формирует информацию о запрошенной части концептуаль-
ной модели и с ее помощью определяются сведения о местоположении дан-
ных на физическом уровне, которые представляются в терминах операцион-
ной системы. Через операционную систему происходит перекачка информа-
137
ции из устройств хранения в системный буфер. Операционная система сооб-
щает СУБД об окончании пересылки. По результатам работы из доставлен-
ной информации, которая хранится в буфере, извлекается то, что нужно ис-
точнику запроса, и пересылаются эти данные в рабочую область источника запроса (прикладного процесса).
Развитие технологий создания вычислительных устройств, программных систем, расширение задач привело к появлению нового класса информаци-
онных систем – интеллектуальные информационные системы (ИИС). Значи-
тельную часть среди ИИС занимают системы, основанные на знаниях (СОЗ).
Эти системы использовали знания экспертов и были ориентированы на ре-
шение сложных, трудноформализуемых задач. Быстрое расширение сфер применения экспертных систем, решателей задач, обучающих систем под-
держки принятия решений и др. потребовало развития соответствующих ин-
струментальных средств, для создания прикладных СОЗ [21].
Первые системы разрабатывались на основе универсальных языков про-
граммирования высокого уровня – Паскаль, Бейсик, Си, Фортран и др. Такие языки не содержат никаких специальных функциональных средств, ориенти-
рованных на поддержку разработки СОЗ были ориентированы на использо-
вание логических, продукционных и сетевых методов представления знаний.
В работе [8] рассматривается система с продукционными правилами, состо-
ящая из группы отдельных элементов. Имеется множество продукционных правил, которые управляют фактами, хранимыми в рабочей памяти. Под-
система логического вывода используется, чтобы идентифицировать прави-
ло, которое следует использовать (на основе предусловия). После примене-
ния правила содержание рабочей памяти, на основании постусловий приме-
нения, изменяется (рис. 4.2). Продукционные правила управляют фактами,
которые хранятся в рабочей памяти. После нахождения соответствия для правила, это правило применяется. В зависимости от применения правила
138
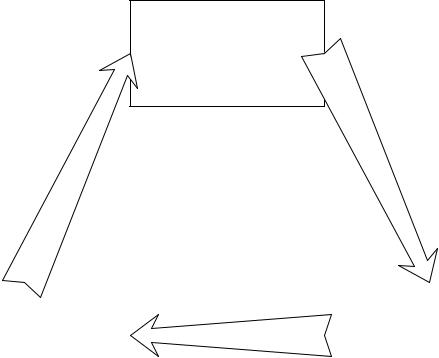
рабочая память может быть изменена, а может остаться без изменений. Вза-
имодействие подсистем продолжается до тех пор, пока не будет достигнута определенная цель.
Подсистема логического вывода
База Знаний |
|
Рабочая память |
(продукционные правила) |
|
(факты) |
|
|
|
Рис. 4.2. Система, основанная на правилах
Появившиеся языки представления знаний, были ориентированы на раз-
работку СОЗ [1]. Представителями таких языков являются Пролог, KRL, OPS5, Loglisp, LOOPS и др. Для каждого из них имеются соответствующие методы представления знаний: логические, продукционные, фреймы, про-
дукционные правила. Кроме того имеется встроенный механизм вывода. Но эти средства жестко регламентированы, и их использование при создании прикладной СОЗ предполагает привлечения не только экспертов и инжене-
ров по знаниям, но и программистов.
Следующим шагом в развитии технологий использования баз знаний явилось создание пустых оболочек систем, основанных на знаниях. Эти ин-
139
струментальные экспертные системы (оболочки ЭС) включают, как правило,
реализацию некоторого языка представления знаний и интерфейс, предна-
значенные, как для инженера по знаниям (когнитолога), например, редактор и отладчик базы знаний, так и для пользователя – наличие подсистемы объ-
яснений. В таких инструментальных системах практически полностью ис-
ключается обычное программирование при создании экспертных приложе-
ний. Но эти системы обладают малой гибкостью, ограниченностью средств представления знаний, жесткостью средств управления формированием ре-
шений, ограниченностью стратегией поиска вывода и разрешимости кон-
фликтов. Примерами таких систем являются оболочки экспертных систем:
GURU, ЭКО, ИНТЕРЭКСПЕРТ, Comp-P, ES-CORVID и др. [21].
Продвинутыми, по сравнению с пустыми оболочками ЭС, являются ин-
тегрированные гибридные инструментальные среды для разработки ЭС,
включающие несколько разнородных средств представления данных и зна-
ний и более богатый, по сравнению с оболочками ЭС, набор средств для ор-
ганизации интерфейсов. К числу таких систем относятся функционирующие на специальных Лисп-станциях системы АКТ и КЕЕ, которые, кроме доста-
точно традиционных языков представления знаний (в виде фактов и правил в системе ART, в виде фреймов и правил в системе КЕЕ), содержат средства структуризации БЗ, позволяющие задавать «миры» или «контексты», и
предоставляют инженеру по знаниям возможность управления стратегией поиска вывода и разнообразные средства конструирования интерфейса с ко-
нечным пользователем [21].
На основе имеющихся средств разработки создавались приложения, ис-
пользующие знания экспертов – системы, основанные на знаниях (СОЗ). В
ранних системах, основанных на знаниях, базы знаний использовали СУБД,
как средство для хранения элементов единиц знаний. Структура системы на основе базы знаний представлена на рис. 4.3.
140