

Digital Design VHDL Laboratory
5.Digital Design using Divide and Conquer
pepe, 4/30/96
process(Ain) begin
if Ain="0000" then flags(0) <= '1';
else
flags(0) <= '0'; end if;
end process;
process(Bin) begin
if Bin="0000" then flags(1) <= '1';
else
flags(1) <= '0'; end if;
end process;
-- To latch overflow flag
process(ctrl(5)) begin
if ctrl(5)='1' then
flags(2) <= overflow; end if;
end process;
end alu_body;
Listing 5-5. Example ALU VHDL Code Listing
5.6 Problems
1)Test component cshift by constructing a VHDL module cshtest.vhd. Test both shift directions, left and right and make sure the test covers the circular wrap effect. The test vectors should be collected in a trace file after running the cshtest.vhd simulation. In the trace file, write a comment at the side of the test vectors that corresponding to each distinct operating period.
Specifically, how long is the input to output delay. Does the delay depend on the number of shift and/or shift direction?
2)Implement a 4-bit arithmetic shift component ashift. Ashift takes a similar input to cshift except it does an arithmetic shift instead of a circular shift. This component should also be included in the package logic_parts_pkg.
3)Implement a 4-bit subtract unit that utilizes components already built, such as the adder. Notice that one can subtract two numbers by complementing the subtractant then and add the numbers. Again, this unit should be included in the package iarith_parts_pkg.
4)Implement the ALU shown in Figure 4.18 of Computer Organization and Design by Patterson and Hennessy using the control logic described in Figure 4.19.
What is the worstcase operational propagation delay in this device that you just implemented?
42 |
Copyright 1996, CERL / EE, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
6. ALU Datapth Implementation
6.1 Introduction
After learning ALU modeling in VHDL, one can carry it further by designing an ALU datapath and eventually building a complete CPU. Again, the divide and conquer approach will be used to illustrate the example. A CPU datapath consists of several major components: register file, data memory, instruction memory, and control module. To model the overall CPU datapath activity, it is necessary first to implement and model each component separately. VHDL is the nature candidate for such a task because it supports the building of small modules, for example with the. package concept.
6.2 Instruction Set Architecture (ISA)
Computer architecture design requires technology from both software and hardware areas. By conventional practice, a computer system is built in a hierarchy of hardware to software layers. The abstract layer where hardware and software interact is called the instruction set architecture (ISA). How ISA is designed and implemented is important because it affects the machine in every aspect, such as compatibility, performance, and cost. Usually, depending on the end user application, the machine architect selects the best possible trade off for its design. By utilizing the same instruction set, one can ensure compatibility problem among different machines. However, this choice might limit the machine in performance because it must follow the same architecture path as other machines using the instruction set.
To illustrate ISA directly, think as the machine’s instruction set. A machine’s instruction set plays important role in both software and hardware layers. On the hardware side, it sits on top and directly controls how the machine manipulates data. In software side, it is used by all software running on the machine because it is the lowest possible level. Thus, the ISA is obviously the software and hardware interface level. Moreover, the instruction set is abstract, and it serves as a good starting point for one to begin his/her computer architecture design.
6.3 A Computer Architecture Implementation
Perhaps MIPS is the most popular RISC machine used in academia for studying computer architecture. This laboratory will take no exception by borrowing concepts from the the MIPS architecture and implementing example datapath of a CPU in VHDL. This architecture is to be called BIA (Borrowed and Incomplete Architecture).
Similar to the MIPS instruction format, the BIA instruction format is constant but shorter in length 16 bits. To steal more MIPS ideas, BIA instructions can be separated into six fields (see Table 6-1). Notice that the field lengths sum to 16 bits.
Field |
Description |
Length |
Bit Location |
|
|
|
|
OP |
Opcode |
4 bits |
[15:12] |
rs |
Operand 1 |
2 bits |
|
[11:10] |
|||
rt |
Operand 2 |
2 bits |
|
[9:8] |
|||
rd |
Distention |
2 bits |
|
[7:6] |
|||
sh |
Shift amount |
2 bits |
|
[5:4] |
|||
|
|
|
|
43 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
funct |
Function |
4 bits |
[3:0] |
|
|
|
|
Table 6-1. BIA Instruction Field
Shamelessly, BIA also contains three types of instructions: R-type, I-type and J-type, where R instructions are for register type operations, I instructions are for data transfer operations and J instructions for unconditional instruction jumps. Since the purpose of BIA is to demonstrate the ability to model a CPU datapath in VHDL, the BIA architectural functionality need not to be complete. Only a few instructions are sufficient for modeling purposes, and they are shown in Table 6-2.
Instructions |
Description |
Format |
|
OP code |
Function |
|
|
|
|
|
|
lw |
load word |
I |
|
14 |
x |
|
|
|
|
|
|
sw |
store word |
I |
|
15 |
x |
|
|
|
|
|
|
add |
add |
R |
|
0 |
1 |
|
|
|
|
|
|
sub |
subtract |
R |
|
0 |
2 |
|
|
|
|
|
|
or |
logical or |
R |
|
0 |
3 |
|
|
|
|
|
|
sll |
logical left shift |
R |
|
0 |
5 |
|
|
|
|
|
|
srl |
logical right shift |
R |
|
0 |
6 |
|
|
|
|
|
|
andi |
and immediate |
I |
|
12 |
x |
|
|
|
|
|
|
ori |
or immediate |
I |
|
13 |
x |
|
|
|
|
|
|
|
Table 6-2. BIA Instructions |
|
|
||
6.4 Implementation Example
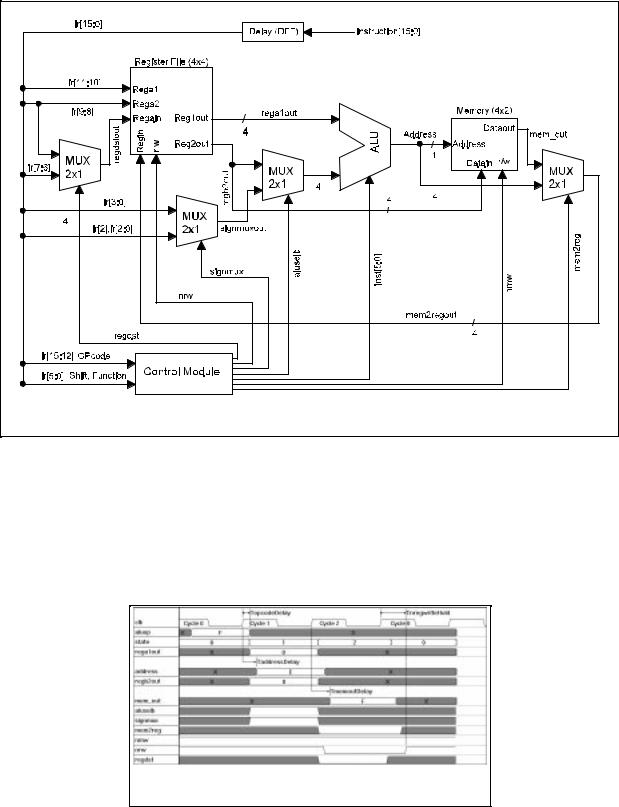
The BIA CPU block diagram shown in Figure 6-1 contains four major components: register file, ALU, memory block, and control module. The BIA ALU implementation is simple and straight forward. Most of the ALU functions, (for example, add, circular shift, logic operations, etc.), have already been presented in the previous VHDL exercise so there is no need to re-implementing them. Since the main focus of this laboratory is to learn the design of a modern microprocessor CPU, supporting logic that surrounds the ALU, (such as datapaths and memory element entities), will be the main focus of this lesson. Again, these items are shown in Figure 6-1.
44 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
Figure 6-1. BIA Block Diagram
All BIA instructions shown in Table 6-2 take one clock cycle to execute, with the exception of the lw (load word) instruction which needs two clock cycles. The clocked elements are the register file and memory in the BIA datapath. The lw operation is triggered by setting the instruction signal aluop to 14. Next, the load memory effective address is calculated. The calculation is done by adding the register content to the address offset which is stored in the immediate field of lw instruction. Next, lw reads the memory by supplying it with the effective address. Finally, the content of the memory is written back into a particular register which is specified in the instruction word. The timing diagram of the lw instruction along with other control signals is in drawn in Figure 6-2. In the figure, the BIA execution path coarsely resembles to a typical CPU instruction cycle: Decode (TopcodeDelay), Fetch (TmemoutDelay), and Execute (TnregwriteHold).
Figure 6-2. lw Instruction Timing Diagram
Due to the complexity of the Cypress VHDL tool, only a fraction of an ALU block is implemented in BIA, and it is shown in the VHDL listing. Important ALU functions such as add and circular shift are not
45 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
included because the current CPLD fitter only supports up to 128 micro-cell devices. The BIA VHDL implementation which is shown in a later section includes everything shown in Figure 6-1 with a basic ALU block that mimic ALU functions.
6.4.1 4x4 Register File and 8x4 Memory Block
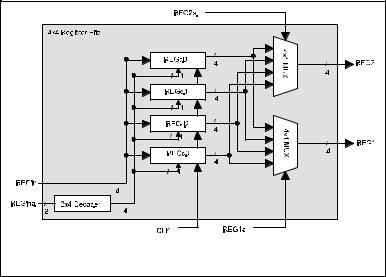
A Register file is not much different from a memory block as seen a few lessons earlier. A register file is made by an array of registers, and each register bit is built from a D flip-flop. A Register file is rather similar to a memory block in that they both are data storage devices. The difference between a register file and a memory block is that a register file contains two read ports instead of one. Moreover, a register file is a faster device because it is placed physically near the ALU. Memory, on the other hand, is located farther from the ALU or even sometimes external to the CPU chip. No less important than the ALU block, register file performance is also critical to how a carfully designed CPU performs.
The logic block diagram of the BIA register file is shown in Figure 6-3. Since BIA is a much reduced MIPS CPU, only four 4-bit wide registers are implemented. The overall BIA register file is made up of multiplexers, decoders, and D flip-flops. Two addresses, REG1a and REG2a, are used to select any two of the registers for reading. Data are output on the corresponding REG1 and REG2 ports. When writing to the register file, data to be written is input from REGin, and the writing register address from REGina is decoded to enable the corresponding register. When reading and writing from the same register, the reading port gets the value prior to the writing of the new value. In other words, the value returned to the reading port will be the value written in an earlier clock cycle. The VHDL source code can be found in a later sections.
Both the register file and memory block in BIA are clocked memory elements. To write or read from these devices, control signals such as the read/write signal, address, and write data lines need to be synchronized with a rising clock edge. This synchronization can be seen in the timing diagram Figure 6- 2.
Figure 6-3. 4x4 Register File Block Diagram
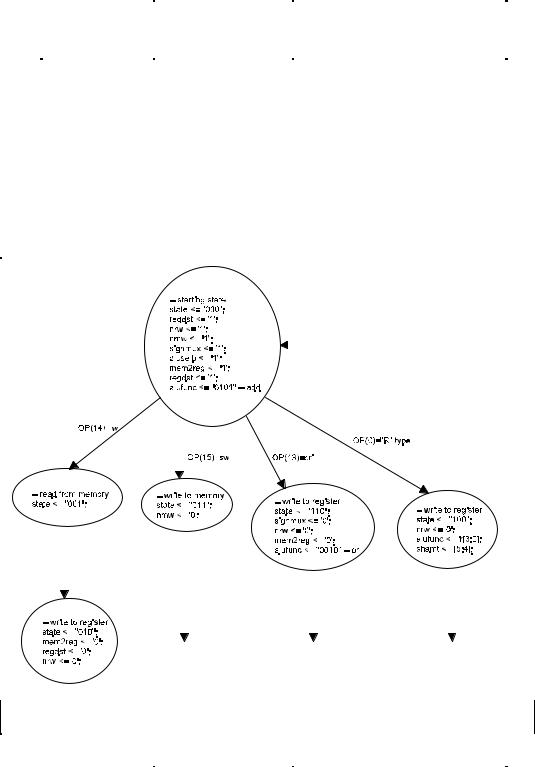
6.4.2 Control Module
When given instructions, BIA executes according to the state diagram shown in Figure 6-4 below. Notice that BIA instructions are divided into four types: lw (load word), sw (store word), ori (or immediate), and R (or register operations). Each instruction type has distinct execution flow and consequential control signal values. The VHDL file ctrlm.vhd which is shown in 6.4.4.3 contains a VHDL entity, st-mach that
46 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
implements functions dictating the BIA state flow. Entity ctrl_module uses the state value produced in st_mach to generate control signals that go to every module of the BIA CPU.
6.4.3 Execution Example
An example session of running BIA is shown in Figure 6-5. To see how the BIA datapath handles instruction and data traffic, one also needs to be familiar with the BIA block diagram of Figure 6-1. The session was captured by executing five BIA instructions. A BIA instruction is first fed into the input port inst. Next, the instructions is latched into registers ir. Notice that ir is associated with the state machine that holds instruction (opcode+operand) for some number of clock cycles. For example, the R-type, sw, and ori instructions take two cycles to complete and the lw instruction takes three. This instruction latch state machine is implemented in entity instruction_latch and it can be found in the listing for bia.vhd.
After an instruction has been latched into the instruction register ir, each instruction field, such as opcode and operands, is sent to the corresponding function block. For example, in the typical R-type instruction, after the opcode is identified to be an R-type instruction, operands are sent to the register file (fast twoport read memory) for retrieving register values and getting them to the next processing stage, namely the ALU. If the instruction in execution is simple R-type instruction, the result from the ALU stores directly back into the register file, and it takes two cycles (cycle 07 and 08 in Figure 6-5). If the instruction is a memory transfer instruction, depending on load word or store word, it can take either two or three clock cycles. Remember that both the register file and memory are clocked elements, therefore, to store a register word into memory, the first clock cycle is needed to release the data from the register and the second clock cycle to store the data into the memory. Similarly in a load word operation, the first clock cycle is to read data from the register (address), the second clock cycle to retrieve data, and the third clock cycle to store back to the register. Again, all of these processes are executed when running the BIA code in Table 6-3 below.
47 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
|
Instruction |
Comment |
Opcode |
rs |
rt |
rd |
|
sh |
|
function |
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[15:12] |
|
|
|
[11:10] [9:8] |
[7:6] |
[5:4] |
[3:0] |
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ori |
|
|
r3, r0, #06 |
; $3 <- $0 OR 6 |
1101 |
00 |
00 |
11 |
00 |
0110 |
|
|
|||||||||||||||||||||||||||||||||||||||||||||
|
ori |
|
|
r2, r0, #04 |
; $2 <- $0 OR 4 |
|
|
|
|
|
|
|
|
|
00 |
00 |
10 |
00 |
0001 |
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
1101 |
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
or |
|
|
r1, r2, r3 |
; $1 <- $2 OR $3 |
|
|
|
|
|
|
|
|
|
10 |
11 |
01 |
00 |
0010 |
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
0000 |
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
sw |
|
|
r1, #4(r0) |
; Memory[$0+4] = $1 |
|
|
|
|
|
|
|
|
|
00 |
00 |
01 |
00 |
0001 |
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
1111 |
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
lw |
|
|
r3, #4(r0) |
; $3 = Memory[$0+4] |
|
|
|
|
|
|
|
|
|
00 |
00 |
11 |
00 |
0001 |
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
1110 |
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure 6-4. BIA State Diagram
|
nop |
; no op |
0001 |
00 00 00 00 0000 |
|
|
|
|
|
|
|
Table 6-3. BIA Code
The simulation run of the operations in Figure 6-5 contains two fields, inst and ir. Inst is the input instruction corresponding to the code above. Ir is the instruction latched corresponding to the inst value. For example, at clock cycle 2, instruction 0xd0c6 is input from inst and then latched by the ir register for
48 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
two cycles. The reason that instructions are latched is because control signals at every stage or clock cycle used by various modules are generated from the instruction field. To execute each BIA instruction correctly, the instruction needs to be frozen during that instruction cycle. For example, instructions such as ori, or, and lw need to be constant for two clock cycles, and the instruction lw needs three clock cycles. Again the timing diagram in Figure 6-5 shows ir was assigned value 0xd0c6 for two cycles (cycle 3 and 4). Notice that this operation is different from the pipeline concept to be learned later.
The signals regf4x4_regd1, regf4x4_regd2, and regf4x4_regd3 are a register file that contains registers 1, 2 and 3. Notice that register 0 always contains a zero value, and therefore it was not shown in the figure. Memory contents are stored in the signals mem2x4_regd0 and mem2x4_regd1. A memory word is 4 bits wide, However, there are only two words implemented in BIA because of Cypress the VHDL compiler limitation (BIA with more memory words cannot be fitted and simulated properly).
Although a more complete ALU can be used, the ALU implemenetd here contains only a few simple operations such as the or, ori, and, and andi instructions. Due to the limited amount of logic that one can fit into a Cypress CPLD family part, only these representative operations are used and shown for purposes of this example. Similar is of the case in the memory word depth. The BIA module originally contain a 4 bit wide and 8 word deep (4x8) module. But, the fitter can’t get that BIA logic into a 37x CPLD. Therefore, the memory block size was reduced to 4x2 to make the logic fit.
Another comment about simulating these six BIA instructions in Table 6-3 is that the Cypress VHDL simulator, NOVA, takes about three minutes to do the simulation on a Petium-90 processor with 16 Megabytes of RAM in the Windows 95 platform. NOVA is not a graphically incremental simulator. The user does not see timing waveform change incrementally. The final wave shows only at the end of the simulation. In a typical simulation session, one would first start the simulation and let it run. While the machine is simulating, output timing waveforms are frozen for approximately three minutes, and then at last, the waveforms are updated all at once when the simulation completes.
49 |
Copyright 1996, EE / CERL, V1.00 |

Digital Design VHDL Laboratory 6.ALU Datapth Implementation pepe, 5/23/96
Figure 6-5. BIA Simulation Timing
6.4.4 VHDL Listing
Sections below list VHDL code for major components and modules that make BIA architecture.
6.4.4.1 regf4x4.vhd
Below is the VHDL listing for the 4x4 register file block.
package regf_type is |
|
|
constant bw: integer := 3; |
|
|
constant adw: integer := 1; |
|
|
component regf4x4 |
|
|
port( |
|
|
clk : |
in |
bit; |
nreset: in bit; |
|
|
nrw: in bit; |
|
|
50 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory 6.ALU Datapth Implementation pepe, 5/23/96
regin: |
|
in |
bit_vector(bw downto 0); |
reg1, reg2: |
out |
bit_vector(bw downto 0); |
|
reg1a, reg2a, regina: |
|
||
|
|
in |
bit_vector(adw downto 0)); |
end component; |
|
|
|
end regf_type; |
|
|
|
use work.regf_type.all; |
|
|
|
entity regf4x4 is |
|
|
|
port( |
|
|
|
clk : in |
bit; |
|
|
nreset: in bit; |
|
|
|
nrw: in bit; |
|
|
|
regin: in |
bit_vector(bw downto 0); |
||
reg1, reg2: |
out |
bit_vector(bw downto 0); |
|
reg1a, reg2a, regina: |
|
|
|
|
|
in |
bit_vector(adw downto 0)); |
end regf4x4;
architecture regf4x4_arch of regf4x4 is
signal regd0, regd1, regd2, regd3: bit_vector (bw downto 0); begin
process (clk) variable i: integer; begin
if clk'event and clk='1' then if nreset='0' then
regd0 <= "0000"; regd1 <= "0000"; regd2 <= "0000"; regd3 <= "0000";
else
-- writing to register
if nrw='0' then
if regina="00" then regd0<=regin;
elsif regina="01" then regd1<=regin;
elsif regina="10" then regd2<=regin;
else
regd3<=regin; end if;
end if;
--reading from register
--register 1 read
if reg1a="00" then -- reg1<=regd0; reg1<="0000";
elsif reg1a="01" then reg1<=regd1;
elsif reg1a="10" then reg1<=regd2;
else
reg1<=regd3; end if;
51 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
-- register 2 read
if reg2a="00" then -- reg2<=regd0; reg2<="0000";
elsif reg2a="01" then reg2<=regd1;
elsif reg2a="10" then reg2<=regd2;
else
reg2<=regd3; end if;
end if;
end if;
end process;
end;
Listing 6-1. Regf4x4.vhd VHDL Code
6.4.4.2 mem4x2.vhd
Below is the construction of both 2x4 and 8x4 memory blocks in VHDL. Although the 2x4 memory block is the one used in BIA.vhd, the 8x4 memory block illustrates a more generic method of constructing memory of any word depth.
package memory_type is
constant bw: integer := 3; constant adw: integer := 1; constant total_word: integer := 3;
type one_mem_data is array (bw downto 0)of bit;
type mem_data is array (total_word downto 0) of one_mem_data;
component mem2x4 |
|
|
port( |
clk: in bit; |
|
|
mdatain: in bit_vector(3 downto 0); |
|
|
mdataout: out bit_vector(3 downto 0); |
|
|
address: |
in bit; |
|
nw: |
in bit); |
end component; |
|
|
component mem8x4 |
|
|
port( |
clk: in bit; |
|
|
mdatain: in one_mem_data; |
|
|
mdataout: out one_mem_data; |
|
|
address: in bit_vector (adw downto 0); |
|
|
nw: |
in bit); |
end component;
end memory_type;
use work.int_math.all;
use work.memory_type.all;
52 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory 6.ALU Datapth Implementation pepe, 5/23/96
entity mem8x4 is |
|
|
port( |
clk: in bit; |
|
|
mdatain: in one_mem_data; |
|
|
mdataout: out one_mem_data; |
|
|
address: in bit_vector (adw downto 0); |
|
|
nw: |
in bit); |
end mem8x4;
architecture mem8x4_arch of mem8x4 is signal mword: mem_data;
signal madd: bit_vector (adw downto 0); begin
-- clocked memory!
process (clk) variable j: integer; begin
if clk'event and clk='1' then
-- write process
if nw='0' then
for j in 0 to total_word loop
if address=i2bv(j,2) then mword(j) <= mdatain;
end if; end loop;
else
for j in 0 to total_word loop
if address=i2bv(j,2) then mdataout <= mword(j);
end if; end loop;
end if;
end if;
end process;
end mem8x4_arch;
------------------------------------------------------------------------------
use work.memory_type.all;
entity mem2x4 is |
|
|
port( |
clk: in bit; |
|
|
mdatain: in bit_vector(3 downto 0); |
|
|
mdataout: out bit_vector(3 downto 0); |
|
|
address: |
in bit; |
|
nw: |
in bit); |
end mem2x4; |
|
|
architecture mem2x4_arch of mem2x4 is
signal word0, word1: bit_vector(3 downto 0);
begin
process (clk) begin
if clk'event and clk='1' then if address='0' then
if nw='0' then
word0 <= mdatain;
else
mdataout <= word0;
53 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
end if;
else
if nw='0' then
word1 <= mdatain;
else
mdataout <= word1; end if;
end if; end if;
end process;
end mem2x4_arch;
Listing 6-2. Mem4x2.vhd VHDL Code
6.4.4.3 ctrlm.vhd
The VHDL program ctrl_pkg below the VHDL code section main contains BIA state control logic. It dictates BIA state given independent input such as instructions. At each BIA state, ctrlm.vhd also generates control signals to control other logic blocks such as ALU, memory, and the register block. These processes comprise in the component st_mach. Notice that st_mach execute according to the flow diagram in Figure 6-4.
One more important piece of code is the alu_module block. alu_module is very similar to the one described in the previous lesson except it contains operations custom to BIA architecture. Also, operations such as addition and circular shift are not included (commented out) due the CPLD capacity.
The last remaining components are simple multiplexers of various bit widths.
package ctrl_pkg is
component alu_module port (
ain, bin: in bit_vector (3 downto 0); sel_bit: in bit_vector (3 downto 0); shamt: in bit_vector (1 downto 0); cout: out bit_vector (3 downto 0); flags: out bit_vector (2 downto 0));
end component;
component mux1_2x1 port (
ain, bin: in bit; cout: out bit; sel: in bit);
end component;
component mux4_2x1 port (
ain, bin: in bit_vector (3 downto 0); cout: out bit_vector (3 downto 0); sel: in bit);
end component;
component mux2_2x1 port (
ain, bin: in bit_vector (1 downto 0); cout: out bit_vector (1 downto 0); sel: in bit);
end component;
component st_mach
54 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory 6.ALU Datapth Implementation pepe, 5/23/96
port( state: inout bit_vector (2 downto 0); aluop: in bit_vector (3 downto 0); clk: in bit;
nreset: in bit;
ir3_0: in bit_vector (3 downto 0); aluselb: out bit;
alufunc: out bit_vector (3 downto 0); mem2reg: out bit;
regdst: out bit; nregwr: out bit; nmemwr: out bit; signmux: out bit);
end component;
end ctrl_pkg;
----------------------------------------------------------------
use work.logic_parts_pkg.all; use work.iarith_parts_pkg.all;
entity alu_module is port (
ain, bin: in bit_vector (3 downto 0); sel_bit: in bit_vector (3 downto 0); shamt: in bit_vector (1 downto 0); cout: out bit_vector (3 downto 0); flags: out bit_vector (2 downto 0));
end alu_module;
architecture alu_module_arch of alu_module is signal bAND_out, bOR_out: bit_vector (3 downto 0); signal lcshift_out, rcshift_out: bit_vector (3 downto 0); signal ripp_adder4_out: bit_vector (3 downto 0); signal apass_out, bpass_out: bit_vector (3 downto 0); signal overflow, b_zero, b_one: bit;
begin
op1: bAND port map(ain, bin, bAND_out); op2: bOR port map(ain, bin, bOR_out); b_zero <= '0';
b_one <= '1';
process (shamt) begin
if shamt="00" then lcshift_out <= "0000"; rcshift_out <= "0000";
end if; end process;
--use reg2 pass for memory transfer ripp_adder4_out <= bin;
--op3: cshift port map(ain, shamt, b_zero, lcshift_out);
--op4: cshift port map(ain, shamt, b_one, rcshift_out);
--op5: ripp_adder4 port map(ain, bin, ripp_adder4_out, overflow);
op6: apass_out <= ain; op7: bpass_out <= bin;
process(sel_bit) begin
if sel_bit="0001" then cout <= bAND_out;
elsif sel_bit="0010" then cout <= bOR_out; elsif sel_bit="0011" then
55 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory 6.ALU Datapth Implementation pepe, 5/23/96
cout <= lcshift_out; elsif sel_bit="0100" then cout <= rcshift_out; elsif sel_bit="0101" then
cout <= ripp_adder4_out; elsif sel_bit="0110" then
cout <= apass_out; elsif sel_bit="0110" then cout <= bpass_out;
else
cout <= "1111"; end if;
end process;
-- flags(0) <= overflow; flags(0) <= '0'; flags(1) <= '0'; flags(2) <= '0';
end alu_module_arch;
----------------------------------------------------------------
entity mux1_2x1 is port(
ain, bin: in bit; cout: out bit; sel: in bit);
end mux1_2x1;
architecture mux1_2x1_arch of mux1_2x1 is begin
process (sel) begin
if sel='0' then cout <= ain;
else
cout <= bin; end if;
end process;
end mux1_2x1_arch;
----------------------------------------------------------------
entity mux4_2x1 is port(
ain, bin: in bit_vector (3 downto 0); cout: out bit_vector (3 downto 0); sel: in bit);
end mux4_2x1;
architecture mux4_2x1_arch of mux4_2x1 is begin
process (sel) begin
if sel='0' then cout <= ain;
else
cout <= bin; end if;
end process;
end mux4_2x1_arch;
56 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory 6.ALU Datapth Implementation pepe, 5/23/96
entity mux2_2x1 is port(
ain, bin: in bit_vector (1 downto 0); cout: out bit_vector (1 downto 0); sel: in bit);
end mux2_2x1;
architecture mux2_2x1_arch of mux2_2x1 is begin
process (sel) begin
if sel='0' then cout <= ain;
else
cout <= bin; end if;
end process;
end mux2_2x1_arch;
----------------------------------------------------------------
-- state machine
----------------------------------------------------------------
entity st_mach is
port( state: inout bit_vector (2 downto 0); aluop: in bit_vector (3 downto 0); clk: in bit;
nreset: in bit;
ir3_0: in bit_vector (3 downto 0); aluselb: out bit;
alufunc: out bit_vector (3 downto 0); mem2reg: out bit;
regdst: out bit; nregwr: out bit; nmemwr: out bit; signmux: out bit);
end st_mach;
architecture st_mach_arch of st_mach is begin
process(clk) begin
if clk'event and clk='1' then if nreset='0' then
state <= "000"; alufunc <= "0101"; regdst <= '1'; nregwr <= '1'; nmemwr <= '1'; signmux <= '1'; aluselb <= '1'; mem2reg <= '1'; regdst <= '1';
else -- lw instruction
if state="000" and aluop="1110" then state <= "001";
elsif state="001" and aluop="1110" then state <= "010";
mem2reg <='0'; regdst <='0'; nregwr <= '0';
57 |
Copyright 1996, EE / CERL, V1.00 |
Digital Design VHDL Laboratory
6.ALU Datapth Implementation
pepe, 5/23/96
-- sw instruction
elsif state="000" and aluop="1111" then state <= "011";
nmemwr <= '0';
-- ORI instruct
elsif state="000" and aluop="1101" then state <= "110";
alufunc <= "0010"; nregwr <= '0'; signmux <= '0';
-- R-type instruction
elsif state="000" and aluop="0000" then state <= "100";
alufunc <= ir3_0 (3 downto 0); aluselb <= '0';
nregwr <= '0';
-- back to starting state else
state <= "000"; alufunc <= "0101"; regdst <= '1'; nregwr <= '1'; nmemwr <= '1'; signmux <= '1'; aluselb <= '1'; mem2reg <= '1'; regdst <= '1';
end if; end if;
end if;
end process;
end st_mach_arch;
----------------------------------------------------------------
-- test program
----------------------------------------------------------------
entity cmtest is port (
whatop: inout bit_vector (3 downto 0); state: inout bit_vector (2 downto 0); ir3_0: in bit_vector (3 downto 0); aluop: in bit_vector (3 downto 0); alufunc: inout bit_vector (3 downto 0); aluselb: out bit;
mem2reg: out bit; regdst: out bit; nregwr: out bit; signmux: out bit; nmemwr: out bit; clk: in bit; dummy: out bit; nreset: in bit );
end cmtest;
architecture cmtest_arch of cmtest is begin
state1: st_mach port map (state, aluop, clk, nreset, ir3_0, aluselb, alufunc, mem2reg, regdst,nregwr, nmemwr,
signmux);
end cmtest_arch;
58 |
Copyright 1996, EE / CERL, V1.00 |