

СПО
.pdfПродолжение табл. 17
i |
Идентификатор |
i : 1 |
:= |
Знак присвоения |
S1 |
1 |
Целочисленная константа |
1 |
to |
Ключевое слово |
X3 |
N |
Идентификатор |
N : 2 |
do |
Ключевое слово |
X4 |
fg |
Идентификатор |
fg : 3 |
:= |
Знак присвоения |
S1 |
fg |
Идентификатор |
fg : 3 |
* |
Знак арифметической операции |
A1 |
0,5 |
Вещественная константа |
0,5 |
Устанавливается связка таблицы лексем с таблицей идентификаторов (в примере это отражено некоторым индексом, следующим после идентификатора за знаком «:», а в реальном компиляторе определяется его реализацией).
8.3.2. Принципы построения лексических анализаторов
Лексический анализатор имеет дело с такими объектами, как константы и идентификаторы (к последним относятся и ключевые слова). Язык констант и идентификаторов является регулярным, т.е. может быть описан с помощью регулярных грамматик. Распознавателями для регулярных языков являются конечные автоматы. Следовательно, основой для реализации лексических анализаторов служат регулярные граммати-
ки и конечные автоматы.
Задача лексического анализатора шире, чем просто проверка цепочки символов лексемы на соответствие входному языку. Кроме этого, он должен выполнить следующие действия:
определить границы лексем, которые в тексте исходной программы явно не указаны;
выполнить действия для сохранения информации об
обнаруженной лексеме (или выдать сообщение об ошибке, если лексема неверна).
Эти действия связаны с определенными проблемами. Далее рассмотрено, как эти проблемы решаются в лексических анализаторах.
8.3.3. Определение границ лексем
Выделение границ лексем является нетривиальной задачей. Ведь в тексте исходной программы лексемы не ограничены никакими специальными символами. Если говорить в терминах лексического анализатора, то определение границ лексем - это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание.
Иллюстрацией случая, когда определение границ лексемы вызывает определенные сложности, может служить пример оператора программы на языке С, имеющий вид:
k = i+++++j;
Существует только одна единственно верная трактовка этого оператора:
k = i++ + ++j;
если явно пояснить ее с помощью скобок, то данная конструкция имеет вид:
k = (i++) + (++j);
Однако найти ее лексический анализатор может, лишь просмотрев весь оператор до конца и перебрав все варианты, причем неверные варианты могут быть обнаружены только на этапе семантического анализа (например, вариант k = (i++)++ + j; является синтаксически правильным, но семантикой языка С не допускается). Конечно, чтобы эта конструкция была в принципе допустима, входящие в нее операнды k, i и j должны быть описаны и должны допускать выполнение операций язы-
ка ++ и +.
Поэтому в большинстве компиляторов лексический и синтаксический анализаторы - это взаимосвязанные части.
Возможны два принципиально различных метода организации взаимосвязи лексического и синтаксического анализа:
последовательный;
параллельный.
При последовательном варианте лексический анализа-
тор просматривает весь текст исходной программы от начала до конца и преобразует его в таблицу лексем. Таблица лексем заполняется сразу полностью, компилятор использует ее для последующих фаз компиляции, но в дальнейшем не изменяет. Дальнейшую обработку таблицы лексем выполняют следующие фазы компиляции. Если в процессе разбора лексический анализатор не смог правильно определить тип лексемы, то считается, что исходная программа содержит ошибку.
При параллельном варианте лексический анализ текста исходной программы выполняется поэтапно, по шагам. Лексический анализатор выделяет очередную лексему в исходном коде и передает ее синтаксическому анализатору. Синтаксический анализатор, выполнив разбор очередной конструкции языка, может подтвердить правильность найденной лексемы и обратиться к лексическому анализатору за следующей лексемой либо же отвергнуть найденную лексему. Во втором случае он может проинформировать лексический анализатор о том, что надо вернуться назад к уже просмотренному ранее фрагменту исходного кода и сообщить ему дополнительную информацию о том, какого типа лексему следует ожидать. Взаимодействуя между собой таким образом, лексический и синтаксические анализаторы могут перебрать несколько возможных вариантов лексем, и если ни один из них не подойдет, будет считаться, что исходная программа содержит ошибку. Только после того, как синтаксический анализатор успешно выполнит разбор очередной конструкции исходного языка (обычно такой конструкцией является оператор исходного языка), лексический анализатор помещает найденные лексемы в таблицу лексем и в таблицу идентификаторов и продолжает разбор дальше в том же порядке.
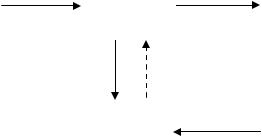
Параллельное взаимодействие лексического и синтаксического анализаторов представим в виде схемы (рис. 29).
Исходная |
|
Лексичес- |
|
Иденти- |
Таблица |
програм- |
|
кий |
|
фикаторы |
идентифика- |
ма |
|
анализ |
|
|
торов (таб- |
|
|
(сканер) |
|
|
лица имен) |
|
Очередная |
Обращение |
|
||
|
лексема |
за лексемой |
|
||
|
|
Синтакси- |
|
|
|
|
|
ческий |
|
|
|
|
|
разбор |
|
|
|
|
|
(анализ) |
|
|
|
Рис. 29. Параллельное взаимодействие лексического и синтаксического анализаторов
Последовательная работа лексического и синтаксического анализаторов представляет собой самый простой вариант их взаимодействия. Она проще в реализации и обеспечивает более высокую скорость работы компилятора, чем их параллельное взаимодействие. Поэтому разработчики компиляторов стремятся организовать взаимодействие лексического и синтаксического анализаторов именно таким образом.
Для большинства языков программирования границы лексем распознаются по заданным терминальным символам. Эти символы - пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки с запятой и т. п.). Набор таких терминальных символов зависит от синтаксиса входного языка. Важно отметить, что знаки операций сами также являются лексемами, и необходимо не пропустить их при распознавании текста.
Последовательный вариант организации взаимодействия лексического и синтаксического анализаторов является более
эффективным, так как он не требует организации сложных механизмов обмена данными и не нуждается в повторном прочтении уже разобранных лексем. Этот метод является и более простым.
Однако не для всех языков программирования возможно организовать такое взаимодействие. Это зависит в основном от синтаксиса языка, заданного его грамматикой. Большинство современных широко распространенных языков программирования, таких как С и Pascal, тем не менее, позволяют построить лексический анализ по более простому, последовательному методу.
8.3.4. Выполнение действий, связанных с лексемами
Выполнение действий в процессе распознавания лексем представляет для лексического анализатора гораздо меньшую проблему, чем определение границ лексем. Фактически конечный автомат, который лежит в основе лексического анализатора, должен иметь не только входной язык, но и выходной. Он должен не только уметь распознать правильную лексему на входе, но и породить связанную с ней последовательность символов на выходе. В такой конфигурации конечный автомат преобразуется в конечный преобразователь.
Для лексического анализатора действия по обнаружению лексемы могут трактоваться несколько шире, чем только порождение цепочки символов выходного языка. Он должен уметь выполнять такие действия, как запись найденной лексемы в таблицу лексем, поиск ее в таблице идентификаторов и запись новой лексемы в таблицу идентификаторов. Набор действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же при обнаружении конца распознаваемой лексемы.
В конечном автомате, лежащем в основе лексического анализатора, эти действия можно отобразить довольно просто - достаточно иметь возможность с каждым переходом на графе
автомата (или в функции переходов автомата) связать выполнение некоторой произвольной функции
f (q,a),
где q - текущее состояние автомата, а - текущий входной символ.
Функция f (q,a) может выполнять любые действия, доступные лексическому анализатору:
помещать новую лексему в таблицу лексем;
проверять наличие найденной лексемы в таблице идентификаторов;
добавлять новую лексему в таблицу идентификаторов;
выдавать сообщения пользователю об ошибках и предупреждения об обнаруженных неточностях в программе;
прерывать процесс компиляции.
Возможны и другие действия, предусмотренные реализацией компилятора.
8.4. Формальные языки и грамматики
8.4.1. Первичные понятия
Определение. Конечное множество символов, неделимых в данном рассмотрении, называется словарем или алфавитом, а символы, входящие в множество, - буквами алфавита.
Например, алфавит A = {a, b, c, +, !} содержит 5 букв, а алфавит B = {00, 01, 10, 11} содержит 4 буквы, каждая из которых состоит из двух символов.
Определение. Последовательность букв алфавита называется словом или цепочкой в этом алфавите. Число букв, входящих в слово, называется его длиной.
Например, слово в алфавите A a = ab++c имеет длину l(a)= 5, а слово в алфавите B b=00110010 имеет длину l (b)= 4.
Введем следующие обозначения. Если A - некоторый алфавит, то
A* обозначает множество всех предложений, которые
составлены из букв алфавита A, включая и пустое предложение.
E обозначим пустое предложение, т.е. предложение, не содержащее ни одного символа.
А+ обозначает множество всех предложений без пустого предложения.
Например, если А = {0, 1}, то
А * = {$, 0, 1, 00, 01, 10, 11, 000, ...}, А + = {0, 1, 00, 01, 10, 11, ...}.
Определение. Формальной порождающей граммати-
кой Г называется следующая совокупность четырех объектов:
Г = { Vт, VA, <I> VA, R },
где Vт - терминальный алфавит (словарь); буквы этого алфавита называются терминальными символами; из них строятся цепочки порождаемые грамматикой;
VA - нетерминальный, вспомогательный алфавит
(словарь); буквы этого алфавита используются при построении цепочек; они могут входить в промежуточные цепочки, но не должны входить в результат порождения;
<I> - начальный символ грамматики <I> VA.
R - множество правил вывода или порождающих пра-
вил вида , где и - цепочки, построенные из букв алфавита Vт VA, который называют полным алфавитом (словарем) грамматики Г.
В множество правил грамматики могут также входить правила с пустой правой частью вида <Е> . Чтобы избежать неопределенности из-за отсутствия символа в правой части правила, условимся использовать символ пустой цепочки, записывая такое правило в виде <Е> $.
Чтобы установить правила построения цепочек, порождаемых грамматикой, введем следующие понятия.
Определение. Пусть r = - правило грамматики Г и= ' " - цепочка символов, причем', " (Vт VA) *. То-
гда цепочка = ' " может быть получена из цепочки путем
применения правила r (т.е. заменой в m цепочки на ). В этом случае говорят, что цепочка непосредственно выведена из цепочки и обозначают .
Определение. Если задана совокупность цепочек = (0, 1,..., n), таких, что существует последовательность непосредственных выводов:
0 1, 1 2, ... , n-1 n,
то такую последовательность называют выводом n из 0 в грамматике Г и обозначают
0 * n.
Определение. Множество конечных цепочек терминального алфавита Vт грамматики Г, выводимых из начального символа <I>, называется языком, порождаемым граммати-
кой Г и обозначается L( Г).
L( Г ) = { Vт* | <I> * }.
Определение. Если язык, порождаемый грамматикой Г, не содержит ни одной конечной цепочки (конечного слова), то он называется пустым.
Утверждение. Для того, чтобы язык L( Г ) не был пустым, в множестве R должно быть хотя бы одно правило вида r = , где Vт* и должен существовать вывод
<I> * .
8.4.2. Примеры, иллюстрирующие первичные понятия
Рассмотрим несколько примеров, иллюстрирующих введенные понятия:
а) Задана грамматика Г1. 0 и требуется определить язык, порождаемый этой грамматикой:
Г1. 0: Vт = {a, b, c}, Va = {<I>}, R = {<I> abc}.
Схема грамматики содержит одно правило, поэтому Г1. 0 порождает язык из одного слова
L(Г1. 0) = {abc}.
б) Задана грамматика Г1. 1 и требуется определить язык, порождаемый этой грамматикой .
Г1. 1 : Vт = {a, b, c}, Va = {<I>, <B>, <C>} R = { <I> a<B>,
<B> <C>d, <B> dc, <C> $}.
Построим все выводы в этой грамматике:
<I> a<B> a<C>d ad,
<I> a<B> adc.
Следовательно язык L(Г1. 1) = {adc, ad}.
в) Задана грамматика Г1. 2 и требуется определить язык, порождаемый этой грамматикой .
Г1. 2 : Va = {<I>, <A>}, Vт = {0, 1}, R = {<I> 0<A>1,
0<A> 00<A>1, <A> $}.
Рассмотрим несколько выводов с помощью правил грамматики Г1. 2. Применяя первое и третье правила, получаем:
<I> 0<A>1 01.
Применяя два раза первое правило и третье, имеем
<I> 0<A>1 00<A>11 0011.
В общем случае, применяя K раз первое правило, получим в результате цепочку, содержащую K нулей и K единиц.
Следовательно, язык, порождаемый грамматикой Г1. 2, содержит всевозможные цепочки, в которых число нулей равно числу единиц.
г) Задана грамматика Г1. 3 и требуется построить язык, порождаемый этой грамматикой.
Г1. 3 : Vт = {a, b}, Va = {<I>, <A>}, R = { <I> a<A>,
<A> b<A>}.
Попытка построения вывода в этой грамматике приводит нас к цепочке:
<I> a<A> ab<A> abb<A> ... ,
которая оказывается бесконечной. Другими словами, Г1. 3 порождает пустой язык.
8.4.3.Типы формальных языков и грамматик
Втеории формальных языков выделяются 4 типа грамматик, которым соответствуют 4 типа языков. Эти грамматики выделяются путем наложения усиливающихся ограничений на правила грамматики.
8.4.3.1. Грамматики типа 0
Грамматики типа 0, которые называют грамматиками общего вида, не имеют никаких ограничений на правила порождения. Любое правило
r =
может быть построено с использованием произвольных цепочек (Vт Va)*. Например,
<T><W> <W><T>
или
x<A>b<C><D> x<H><D>.
8.4.3.2. Грамматики типа 1
Грамматики типа 1, которые называют также контек- стно-зависимыми грамматиками, не допускают использова-
ния любых правил.
Правила вывода в таких грамматиках должны иметь вид:
1<A>2 1 2, где
- 1,2 - цепочки, возможно пустые, из множества (Vт Va)*,