

1.1. Нечеткая и интервальная формулировка модели.
Идея преодоления проблемы операций над зависимыми нечеткими числами состоит в том, что число должно хранить не только свое текущее значение (включающее некоторым образом формализованную погрешность), но и информацию о том, из каких исходных данных и как это число было получено. Это дополнительно дает очень полезную в приложениях возможность анализа результатов численных экспериментов на предмет того, каким образом сказались на них заданные исходные данные. Однако буквальная реализация указанной идеи приводит к неадекватным затратам памяти и времени расчетов: фактически, нечеткое число превращается из значения в формулу зависимости значения от исходных данных; причем с каждым параметром этой формулы при арифметических операциях должны производиться сложные вычисления. Поэтому в целях экономии ресурсов нечеткое число предлагается представлять в виде линейной комбинации по нечетким числам — исходным данным.
Пусть R — множество всех вещественных чисел. Под
интервалом [а, b], а ≤ b, всюду ниже, если не оговорено
противное, понимается замкнутое ограниченное подмножество R вида
М![]() ножество
всех интервалов обозначим через I(R).
Элементы I(R) будем записывать прописными
буквами. Если А — элемент I(R),
ножество
всех интервалов обозначим через I(R).
Элементы I(R) будем записывать прописными
буквами. Если А — элемент I(R),![]() ,
то его левый и правый концы будем
обозначать как ,
,
то его левый и правый концы будем
обозначать как , ![]() В следующем пункте мы введем арифметические
операции над интервалами, поэтому
элементы I(R) называются также интервальными
числами. Символы
В следующем пункте мы введем арифметические
операции над интервалами, поэтому
элементы I(R) называются также интервальными
числами. Символы ![]() :
и т. п. понимаются в обычном
теоретико-множественном
смысле, причем
:
и т. п. понимаются в обычном
теоретико-множественном
смысле, причем ![]() обозначает
не обязательно строгое включение, т. е.
соотношение
обозначает
не обязательно строгое включение, т. е.
соотношение ![]() допускает
равенство интервалов. Два интервала А
и В равны тогда, когда
допускает
равенство интервалов. Два интервала А
и В равны тогда, когда ![]() и
и
![]()
Отношение
порядка на множестве I{R) определяется
следующим образом: А < В тогда и только
тогда, когда а < b.
Возможно также упорядочение по включению:
А не превосходит В, если ![]() .
Мы, в основном, используем первое
определение. Пересечение
.
Мы, в основном, используем первое
определение. Пересечение ![]() интервалов А и В пусто, если А < В или
В <А, в противном случае
интервалов А и В пусто, если А < В или
В <А, в противном случае ![]() =
= ![]() —
снова интервал. Симметричным, по
определению, является интервал
—
снова интервал. Симметричным, по
определению, является интервал![]() , у которого
, у которого ![]() .
Шириной
.
Шириной
![]() интервала А называется величина
интервала А называется величина ![]() :
:
![]() =
=![]() .
Середина
.
Середина
![]() есть полусумма концов интервала
есть полусумма концов интервала ![]()
![]() .
Абсолютная величина
.
Абсолютная величина ![]() определяется как:
определяется как:
![]() .
Наконец,
.
Наконец,
А![]() рифметические
операции над интервальными числами
определяются следующим образом. Пусть
* ^ {+, —, •. /},
рифметические
операции над интервальными числами
определяются следующим образом. Пусть
* ^ {+, —, •. /},![]() .
Тогда
.
Тогда
п![]() ричем
в случае деления
ричем
в случае деления![]() .
Легко проверить, что определение
эквивалентно соотношениям
.
Легко проверить, что определение
эквивалентно соотношениям
И з
определения видно, что интервальные
сложение и умножение ассоциативны и
коммутативны.
з
определения видно, что интервальные
сложение и умножение ассоциативны и
коммутативны.
1.2. Элементы теории нечетких множеств.
В основе нечеткой логики лежит теория нечетких множеств, изложенная в серии работ Л. Заде в 1965-1973 годах. Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов. Л. Заде, формулируя это главное свойство нечетких множеств базировался на трудах предшественников. В начале 1920-х годов польский математик Лукашевич трудился над принципами многозначной математической логики, в которой значениями предикатов могли быть не только «истина» или «ложь». В 1937 г. еще один американский ученый Макс Блэк впервые применил многозначную логику Лукашевича к спискам как множествам объектов и назвал такие множества неопределенными. Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. Нечеткая логика как научное направление развивалась сложно и непросто, не избежала она и обвинений в лженаучности. Даже в 1989 году, когда примеры успешного применения нечеткой логики в обороне, промышленности и бизнесе исчислялись десятками, Национальное научное общество США обсуждало вопрос об исключении материалов по нечетким множествам из институтских учебников. Первый период развития нечетких систем (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств. В 1970 г. Беллман совместно с Заде разработал теорию принятия решений в нечетких условиях. Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). И. Мамдани в 1975 г. спроектировал первый функционирующий на основе алгебры Заде контроллер, управляющий паровой турбиной. Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других. Кроме того, немалую роль в развитии нечеткой логики сыграло доказательство знаменитой теоремы FAT (Fuzzy Approximation Theorem) Б. Коско, в которой утверждалось, что любую математическую систему можно аппроксимировать системой на основе нечеткой логике. Одним из самых впечатляющих результатов стало создание управляющего микропроцессора на основе нечеткой логики, способного автоматически решать известную «задачу о собаке, догоняющей кота». В 1990 г. Комитет по контролю экспорта США внес нечеткую логику в список критически важных оборонных технологий, не подлежащих экспорту потенциальному противнику. В бизнесе и финансах нечеткая логика получила признание после того, как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами. В Японии это направление переживает настоящий бум. Здесь функционирует специально созданная организация – Laboratory for International Fuzzy Engineering Research. Программой этой организации является создание более близких человеку вычислительных устройств. Информационные системы, базирующиеся на нечетких множествах и нечеткой логике, называют нечеткими системами. Достоинства нечетких систем:
функционирование в условиях неопределенности;
оперирование качественными и количественными данными;
использование экспертных знаний в управлении;
построение моделей приближенных рассуждений человека;
устойчивость при действии на систему всевозможных возмущений.
Недостатками нечетких систем являются:
отсутствие стандартной методики конструирования нечетких систем;
невозможность математического анализа нечетких систем существующими методами;
применение нечеткого подхода по сравнению с вероятностным не приводит к повышению точности вычислений.
Понятие нечеткого множества - эта попытка математической формализации нечеткой информации для построения математических моделей. В основе этого понятия лежит представление о том, что составляющие данное множество элементы, обладающие общим свойством, могут обладать этим свойством в различной степени и, следовательно, принадлежать к данному множеству с различной степенью. При таком подходе высказывания типа “такой-то элемент принадлежит данному множеству” теряют смысл, поскольку необходимо указать “насколько сильно” или с какой степенью конкретный элемент удовлетворяет свойствам данного множества.
|
Нечетким
множеством (fuzzy set) на универсальном
множестве U называется совокупность
пар (), где - степень принадлежности
элемента к нечеткому множеству .
Степень принадлежности - это число
из диапазона [0, 1]. Чем выше степень
принадлежности, тем в большей мерой
элемент универсального множества
соответствует свойствам нечеткого
множества.
Функцией
принадлежности (membership function) называется
функция, которая позволяет вычислить
степень принадлежности произвольного
элемента универсального множества к
нечеткому множеству. Если универсальное
множество состоит из конечного
количества элементов , тогда нечеткое
множество записывается в виде Лингвистической переменной (linguistic variable) называется переменная, значениями которой могут быть слова или словосочетания некоторого естественного или искусственного языка. Терм–множеством (term set) называется множество всех возможных значений лингвистической переменной. Термом (term) называется любой элемент терм–множества. В теории нечетких множеств терм формализуется нечетким множеством с помощью функции принадлежности. Определения нечетких теоретико-множественных операций объединения, пересечения и дополнения могут быть обобщены из обычной теории множеств. В отличие от обычных множеств, в теории нечетких множеств степень принадлежности не ограничена лишь бинарной значениями 0 и 1 она может принимать значения из интервала [0, 1]. Поэтому, нечеткие теоретико-множественные операции могут быть определены по-разному. Ясно, что выполнение нечетких операций объединения, пересечения и дополнения над не нечеткими множествами должно дать такие же результаты, как и при использование обычных канторовских теоретико-множественных операций. Ниже приведены определения нечетких теоретико-множественных операций, предложенных Л. Заде. Функции принадлежности удобнее всего задавать в параметрической форме. В этом случае задача сводится к нахождению параметров функции. Материал основывается на понятии нечеткого числа и принципа нечеткого обобщения. Нечетким числом называется выпуклое нормальное нечеткое множество с кусочно-непрерывной функцией принадлежности, заданное на множестве действительных чисел. Например, нечеткое число «около 10» можно записать:
Принцип
нечеткого обобщения Заде. Если
П
|
 о
принципу обобщения рассчитывается
нечеткое число, соответствующее
значению четкой функции от нечетких
аргументов. Различие между функциями
от четких и нечетких аргументов (а,б):
о
принципу обобщения рассчитывается
нечеткое число, соответствующее
значению четкой функции от нечетких
аргументов. Различие между функциями
от четких и нечетких аргументов (а,б):
Компьютерно-ориентированная реализация принципа нечеткого обобщения Заде осуществляется по следующему алгоритму.
Зафиксировать значение

Найти все n-ки

Степень принадлежности элемента
 нечеткому
числу
нечеткому
числу 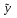 вычислить
по формуле:
вычислить
по формуле: Е
 сли
взяты все элементы то конец, если нет,
то зафиксировать новое значение и
вернуться к шагу 2.
сли
взяты все элементы то конец, если нет,
то зафиксировать новое значение и
вернуться к шагу 2.
Для
вычисления значений функции ![]() нечеткие
аргументы представляют в виде:
нечеткие
аргументы представляют в виде:
К оличествоk
выбирают
так, чтобы обеспечить требуемую точность
вычислений. На выходе алгоритма получается
нечеткое множество.
оличествоk
выбирают
так, чтобы обеспечить требуемую точность
вычислений. На выходе алгоритма получается
нечеткое множество.
Более
практичным является уровневый принцип
обобщения. В этом случае четкие числа
задают множествами ![]() :
:
г![]() де
де![]() -
минимальное
и максимальное значение.
-
минимальное
и максимальное значение.
Применение
![]() уровневого
принципа обобщения сводится к решению
для каждого
уровневого
принципа обобщения сводится к решению
для каждого ![]() уровня
следующей задачи оптимизации: найти
максимамльное и минимальное значение
функции
уровня
следующей задачи оптимизации: найти
максимамльное и минимальное значение
функции ![]() при условии, что аргументы могут принимать
значения из соответствующих
при условии, что аргументы могут принимать
значения из соответствующих ![]() сечений.
Количество уровней выбирается так,
чтобы обеспечить необходимую точность
вычислений.
сечений.
Количество уровней выбирается так,
чтобы обеспечить необходимую точность
вычислений.