

Аверянов Современная информатика 2011
.pdfсор непосредственно соединяется с каждым банком памяти. Недостаток здесь в том, что процессоры и банки памяти должны иметь очень большое количество соединительных линий. Другое решение (см. рис. 2.12, б) дает «шина» – общий канал связи, по которому каждый процессор посылает запросы к банкам памяти, а последние выдают данные. Такая «шина» может быть перегружена (и, следовательно, работать медленно), когда требуется передавать много сообщений. Еще одно решение представляет собой так называемая «сеть омега» (см. рис. 2.12, в), в ней процессоры связываются с модулями памяти коммутирующими устройствами, у каждого из которых два входных и два выходных канала. В такой сети каждый процессор может напрямую связываться с каждым модулем памяти, однако здесь нет нужды в таком большом количестве линий связи, которого требует система с прямыми связями.
Преимущества сети становятся все более очевидными по мере роста числа процессоров и модулей памяти. Недостаток ее в том, что иногда сообщения проходят через множество коммутирующих станций, прежде чем достигают абонента.
Рассматриваемая схема с общей, разделяемой ОП (которая на сегодняшний день используется в традиционных суперкомпьютерах), наряду с очевидными преимуществами простого программирования обменов данными между процессорами, по мере увеличения числа процессоров имеет серьезный недостаток – плохую масштабируемость. Система называется хорошо масштабируемой, если увеличение процессорных элементов (ПЭ) приводит к адекватному увеличению производительности). Это связано с увеличением потерь времени (при увеличении числа процессоров) на доступ к необходимым данным в любой из рассмотренных схем. Тем не менее, все эти схемы применялись и применяются на компьютерах различных типов, в современной классификации эта схема называ-
ется SMP (Symmetric Multi Processing).
Этого недостатка лишены системы с распределенной памятью. Здесь у каждого процессора, а в некоторых случаях группы, или кластера процессоров имеется своя собственная ОП, доступ к которой осуществляется без помех. Платой за это является невозможность использовать память соседнего вычислительного узла. Термин «Массивно параллельные системы» (MPS) применяется обычно для обозначения таких масштабируемых компьютеров с боль-
91

шим числом узлов (сотни, а иногда и тысячи). В соответствии с классификацией Флина такие системы идентифицируются как
MSIMD.
Рис. 2.12. Различные варианты обмена информацией для параллельных структур
В системах распределенной памяти устанавливаются соединения между процессорами, каждый из которых монопольно владеет некоторым количеством памяти. Простейшие схемы соединения процессоров – «кольцо» (рис. 2.13, а) и «решетка» (рис. 2.13, б). Более специализированная структура связей – «двоичное дерево»
92
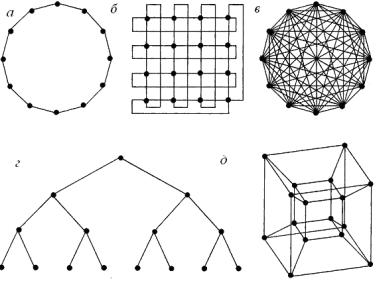
(рис. 21.13, г). Особенно эффективна она в так называемых экспертных системах, в которых последовательности принятия решений могут быть представлены в виде «дерева». Можно также соединить каждый процессор с каждым (рис. 2.13, в), но для этого потребуется нереально большое количество соединений.
Оптимальным с точки зрения связей считается гиперкуб (рис. 2.13, д), реализованный в первом проекте американского суперкомпьютера. В этой схеме процессоры играют роль вершин многомерного куба и соединены его ребрами, они находятся в вершинах четырехмерного куба.
Рис. 2.13. Способы возможного взаимодействия процессоров:
а– «кольцо»; б – «решетка»; в – каждый с каждым; г – «дерево»; д – гиперкуб
Втакой системе каждый процессор может посылать сообщения любому другому процессору по сравнительно короткому пути, при этом процессоры не перегружаются слишком большим количеством соединений.
Значительно расширились возможности суперкомпьютеров благодаря использованию векторно-конвейерной обработки, представляющей пространственно-временное распараллеливание процессов
93

обработки, внедрение которой связывают с именем Сеймура Крея, основателя фирмы Cray Research Inc., которая до 90-х годов лидировала в производстве суперкомпьютеров.
Рис. 2.14. Принцип конвейерной архитектуры
Конвейерная обработка – метод повышения быстродействия одиночного процессора – подобно линии сборки автомобиля на конвейере (рис. 2.14). Идея, впервые использованная Генри Фордом, (см. рис. 2.14, б) оказалась весьма перспективной и в области вычислительной техники.
94
Любая вычислительная операция распадается на ряд шагов, выполняемых специализированными компонентами процессора (реализующими его систему команд). В обычном процессоре (см. рис. 2.14, а) пока одна компонента работает, остальные бездействуют (простаивают). На рис. 2.14, в операция умножения распадается на следующие шаги: извлечение из памяти порядка и мантиссы обоих чисел и выделение этих частей, сложение порядков, умножение мантисс и представление результатов в требуемой форме.
Процессор с конвейерной организацией действует аналогично автомобильному конвейеру, при выполнении шага операций над одной парой чисел другая пара поступает для выполнения того же шага, не дожидаясь, пока первая пара пройдет все этапы операции. Естественно, что любая конвейерная обработка имеет смысл при массовом производстве и эффект от нее наступает после заполнения конвейера вновь поступающими данными («мертвое» время конвейера). При этом скорость конвейерной обработки зависит от длины конвейера. Так, если длина конвейера равна N компонентам, то после заполнения такой процессор будет работать в N раз быстрее обычного процессора последовательной обработки. Выбор длины конвейера – вопрос достаточно сложный, поскольку любая параллельная обработка (в том числе и векторная) предполагает соблюдение двух основных требований – независимость потока команд и независимость потока данных. Большие сложности при работе конвейеров представляют ветвящиеся алгоритмы. Хотя разработчики принимают немалые усилия для преодоления этих трудностей (сцепление конвейеров, «спекулятивное» выполнение инструкций, эвристическое предсказание переходов и т.п.). Начало конвейерной обработке положила поточная обработка в первых суперкомпьютерах с разделением процессоров на процессоры команд (осуществляющие доставку и дешифровку команд данных) и процессоры обработки данных, производящие непосредственную обработку. При этом для исключения потерь времени на доставку дешифровка следующей команды осуществляется процессором команд во время выполнения текущей команды процессорами обработки данных. Эта процедура в настоящее время реализована практически во всех современных микропроцессорах (начиная с Intel 8086).
95
Как известно, жизнь развивается по спирали. В 1972 г. после преодоления значительных проблем на аппаратном и программном уровне в исследовательском центре NASA в Эймсе был установлен первый в мире векторный суперкомпьютер с матричной структурой ILL IAC4. С ним связано введение элементов MSIMD архитектуры и начало параллельного программирования. Изначально система должна была состоять из четырех квадрантов, каждый из которых включает 64 процессорных элемента (ПЭ) и 64 модуля памяти, объединенных коммутатором на базе сети в гиперкуб. Все ПЭ квадранта обрабатывают векторную инструкцию, которую им направляет процессор команд, причем каждый выполняет одну элементарную операцию вектора, данные для которой сохраняются в связанном с этим ПЭ модулем памяти. Таким образом, квадрант ILLIAC4 способен одновременно обрабатывать 64 элемента вектора, а вся система из четырех квадрантов 256 элементов.
Результаты эксплуатации этой системы получили неоднозначную оценку. С одной стороны, использование суперкомпьютера позволило решить ряд сложнейших задач аэродинамики, с которыми не могли справиться ни одни из существующих в США машин. С другой стороны, ILLIAC4 так и не были доведены до полной конфигурации из 256 ПЭ, практически разработчики ограничились лишь одним квадрантом. Причинами явились не столько технические сложности в наращивании числа ПЭ системы, сколько проблемы, связанные с программированием обмена данными между процессорными элементами через коммутатор модулей памяти. Все попытки решить эту проблему с помощью системного программного обеспечения потерпели неудачу, в результате каждое приложение требовало ручного программирования передач коммутатора, что и породило неудовлетворительные отзывы пользователей.
Ни в 60-х годах, ни позднее удовлетворительное решение двух таких принципиальных проблем, как программирование параллельной работы нескольких сотен процессоров и при этом обеспечение минимума затрат счетного времени на обмен данными между ними, не было найдено. В связи с этим компьютеры данного типа были не в состоянии удовлетворить широкий круг пользователей и имели весьма ограниченную область применения.
96
Правда, было бы большой ошибкой считать, что развитие суперкомпьютеров матричной архитектуры не дало никаких результатов. Во-первых, ряд теоретических наработок и практическая реализация параллельных сверхскоростных вычислений были в дальнейшем использованы уже на новом витке развития этого типа компьютеров, и, во-вторых, в прикладной математике сформировалось самостоятельное направление по параллельным вычислениям, столь актуальное направление на современном этапе.
Решение большинства перечисляемых проблем было найдено в конце 60-х годов «патриархом» суперкомпьютерных технологий Сеймуром Крейем. Он представил машину, основанную на вектор- но-конвейерном принципе обработки данных.
Отличие векторно-конвейерной архитектуры от архитектуры матричных компьютеров заключается в том, что вместо множества ПЭ, использующих одну и ту же команду над разными элементами вектора, применяется единственный конвейер операций, имеющий всего один вход и один выход результата. Другими словами, в суперкомпьютерах с конвейерной обработкой данные всех параллельно исполняемых операций выбираются и записываются в единую память (не разделяемую) и отпадает необходимость в коммутаторе процессорных элементов, основной проблеме матричных суперЭВМ.
Дальнейшее развитие векторно-конвейерной обработки связано с многоконвейерной и построением многоконвейерных цепочек (или иначе векторно-командных цепочек). Суть его заключается в следующем: если в программе встречаются две связанные векторные операции (т.е. результат первой операции служит операндом второй), то в отличие от связанных скалярных операций, когда выполнение второй операции начинается только после завершения предыдущей, обе векторные команды могут обрабатываться практически параллельно, что удваивает производительность системы.
Допустим, программист задает цикл.
Do i = 1, N
C[i] = A[i] + B[i]
E[i] = C[i] * D[i]
Enddo
97

Тогда после векторизации компилятор организует две векторные команды
С = А + В Е = С * D
Формально вторая операция может стартовать только после окончательного вектора результата операции С, однако структура процессора позволяет запустить связанную операцию, как только сформируется первый элемент С.
В результате такого зацепления векторных операций суммарное время выполнения исходного цикла не на много превосходит этот показатель для одной векторной команды (рис. 2.15).
Рис. 2.15. Сцепление конвейеров
Важным достоинством векторно-конвейерной обработки является возможность использования традиционных (последовательных) языков программирования, а также разработка так называемых «интеллектуальных компиляторов», способных обнаруживать параллелизм в программах последовательного действия и преобразовывать их в векторизированный код. Следует отметить, что параллельные компиляторы хотя и называются интеллектуальными, в качестве обязательных средств содержат интерактивные оптимиза-
98
торы и анализаторы затрат, а знание особенности функционирования кэш-памяти позволяет программисту значительно увеличить производительность выполнения задач. В то же время в таких наиболее распространенных языках, как Фортран и Си, включены средства параллельного программирования.
До 90-х годов многопроцессорные, многоконвейерные суперкомпьютеры с общей для всех процессоров памятью доминировали, но затем ситуация стала возвращаться (на новом уровне) к системам с разделяемой памятью (вспомним ILLIAC4). Это объясняется тем, что примерно до середины 90-х годов XX в. основное направление развития суперкомпьютерных технологий было связано с построением специализированных многопроцессорных систем из массовых микросхем. Один из сформировавшихся подходов, упоминавшийся ранее, – SMP (Symmetric Multi Processing), подразумевал объедине-
ние многих процессоров с использованием общей памяти, что сильно облегчало программирование, но предъявляло высокие требования к самой памяти. Использовалась как поточная, так и векторная обработка. Сохранить быстродействие таких систем при увеличении количества узлов до десятков было практически невозможно. Кроме того, этот подход оказался самым дорогим в аппаратной реализации. На порядок более дешевым и практически бесконечно масштабируемым оказался упоминавшийся ранее способ MPP (Massively Parallel Processing), при котором независимые специализированные вычислительные модули объединяются специализированными каналами связи, причем те и другие создавались под конкретный компьютер и ни в каких других целях не применялись.
Идея создания кластерных рабочих станций явилась фактически развитием метода MPP, поскольку логически МРР не сильно отличается от обычной локальной сети. Локальная сеть стандартных персональных компьютеров при соответствующем программном обеспечении, использовавшаяся как многопроцессорный суперкомпьютер, и стала прародительницей современного кластера. Сейчас слова «кластер» и «суперкомпьютер» в значительной степени синонимы (хотя традиционные кластеры по-прежнему имеют широкое распространение). Эта идея получила воплощение, когда благодаря оснащению персональных компьютеров высокоскоростной шиной PCI и появлению дешевой, но быстрой сети Fast Ethernet кластеры стали
99

догонять специализированные МРР-системы по коммуникационным возможностям. Это означало, что современную МРР-систему можно создать из стандартных серийных компьютеров при помощи серийных коммуникационных технологий, причем такая система обходится дешевле, в среднем, на два порядка.
Некоторым промежуточным архитектурным решением представляется разработанный фирмой IBM суперкомпьютер SP (Scalable POWERparallel), получивший широкое распространение. Он представляет так называемую MSIMD-архитектуру, которую иногда называют массивно параллельной обработкой по схеме неразделяемых ресурсов, а иногда масс-процессорной макроконвейерной или динамической сетевой архитектурой. Компьютер построен на основе фактически автономных рабочих станций этой фирмы RS-6000, на базе 64-разрядного RISC-процессора POWER*. Модули объединяются с помощью специализированной коммуникационной матрицы. Система построена по модульному принципу, расширяется от 16 до 152 узлов, структура коммуникационной матрицы может настраиваться на конкретное приложение.
Мощный толчок развитию кластерных технологий дал быстрый рост производительности вновь выпускаемых массовых процессоров. Это сделало высокопроизводительные решения доступными даже для отечественных производителей и привело к появлению отечественных суперкомпьютеров на уровне западных и японских моделей. Самый мощный кластер в России на 2005 – 2006 гг. – МВС 15000 БН с реальной производительностью 5,3 TFlops, построен из вычислительных узлов компании IBM на базе процессоров POWER PC и системной сети Myrinet.
Доля кластеров в списке суперкомпьютеров за период с 2000 до 2004 г. увеличилась с 2,2 до 60,8 %. При этом более 71,5 % процессоров, используемых для создания суперкомпьютеров, – массово выпускаемые процессоры компаний Intel и AMD.
Кластерные технологии используются и в новейших суперкомпьютерных разработках ведущих изготовителей: например, в самом мощном суперкомпьютере IBM BlueGene/L с производитель-
* POWER – P(erformance) O(ptimization) W(ith) E(nhanced) R(ISC).
100