

I Введение
ДЕ1: Информационная система СУБД Oracle
Эффективное управление сложными организационными системами требует использования современных средств автоматизации. Успешное решение задач возможно только тогда, когда для каждого контингента пользователей автоматизированных систем обработки информации создана отвечающая их потребностям среда обработки данных. Основная цель всякой системы обработки информации — полное и своевременное удовлетворение информационных потребностей пользователей. Пользователь формулирует свои потребности на каком-либо доступном ему языке. Имеющиеся технические средства в состоянии воспринять только язык детальных инструкций, явно не приемлемый для широкого применения. Поэтому необходима некоторая компонента системы обработки информации, которая обеспечит взаимодействие с пользователем на приемлемом языковом уровне. Помимо этого необходимы средства, обеспечивающие для разработчика системы приемлемый языковый уровень описания технологических процессов обработки данных.
Для более глубокого понимания состава и функций программного обеспечения систем обработки информации целесообразно выделить несколько этапов их эволюции.
Первый этап — период становления автоматизированных систем обработки информации — характеризуется применением ЭВМ для проведения расчетов по индивидуальным программам, создаваемым, как правило, в кодах ЭВМ или на языке ассемблера. На этом этапе применение ЭВМ для автоматизации информационного обслуживания обычно не оправдывало себя: трудозатраты на подготовку программ и первичный ввод информации превышали экономию от автоматизации. Важность этого этапа состояла в том, что пришло четкое осознание того, что необходима разработка методов снижения трудозатрат на программирование процессов ввода, обработки и выдачи информации.
На втором этапе существенное снижение трудозатрат на создание программного обеспечения достигалось за счет создания операционных систем и языков программирования высокого уровня с соответствующими трансляторами. Идеей, лежащей в основе операционной системы, является выделение совокупности наиболее часто выполняемых видов работ и оправдавших себя приемов их описания в форме типовых процедур. Последующая программная реализация соответствующих процедур осуществляется коллективом высококвалифицированных специалистов.
Всякая операционная система включает компоненту, обеспечивающую ввод команд и параметров в приемлемой для человека форме, компоненту, координирующую распределение ресурсов вычислительной системы, и программы, обеспечивающие выполнение стандартных для большинства приложений функций, таких как диагностика аппаратуры, копирование данных с различных носителей, преобразование и восстановление данных и т.д. Операционная система содержит средства описания определенной последовательности действий, связанных единым замыслом. Обычно такая последовательность называется командным файлом.
В основе любого языка программирования высокого уровня лежит идея определения типовых единиц обработки, то есть операндов, и базовых конструкций обработки, то есть операторов. В роли типовых единиц обработки выступают типы данных, например, целый, вещественный, строка символов и т. п. В роли базовых конструкций обработки выступают операторы присваивания, ветвления и цикла, описания процедур или подпрограмм, присутствующие практически во всех языках высокого уровня, операторные скобки, конструкция выбора, специальные операции над строками и т.п., характерные для некоторых языков и определяемые спецификой применения.
На втором этапе развития систем обработки информации процесс изготовления систем обработки данных постепенно утрачивал элементы ремесленничества и приобретал черты промышленного производства. Начался активный поиск рутинных, четко определенных процессов обработки данных и создание языковых средств и программного обеспечения для унификации этих процессов. Удельная стоимость аппаратуры неуклонно снижалась, а относительная стоимость программного обеспечения росла.
Такая картина объясняется тем, что под каждую новую задачу создавалась новая программа. Практически не уделялось внимания вопросу совместимости программ по данным. Совершенно ясно, что ввод исходных данных в задачах обработки информации является дорогостоящим делом. Наличие собственных данных для каждой задачи приводило к дублированию хранимой информации и, как следствие, к значительным затратам, связанным с изменением данных и их синхронизацией.
Каков же должен был быть выход из сложившейся ситуации? Он следовал из логики развития программного обеспечения. По аналогии с операционными системами и языками программирования высокого уровня необходимо было создать языковые средства и соответствующее программное обеспечение для выполнения функций, характерных для систем обработки данных.
Эта задача и решалась на третьем этапе развития автоматизированных систем обработки информации. Особенность этого этапа — появление средств, обеспечивающих техническую возможность оперативного доступа большого количества пользователей к компактно хранимым данным:
запоминающих устройств прямого доступа большой емкости, дисплеев и машинно-ориентированных средств связи. Централизованное накопление, оперативный поиск и корректировка информации предвещали качественный скачок в информационном обеспечении управления. Однако прогресс сдерживался низкими темпами создания соответствующего программного обеспечения. Поэтому создаваемые программные комплексы должны были обеспечить возможность удовлетворения информационных потребностей пользователей с возможно меньшим объемом работ, выполняемых программистами-профессионалами.
Для решения этой задачи было необходимо разработать и реализовать средства общения пользователя с автоматизированной системой более высокого уровня, чем язык программирования, то есть приблизить язык системы к языку, на котором формулирует свои запросы пользователь.
Централизованное накопление и обработка информации возможны только при обеспечении согласованного представления пользователей о хранимых в системе данных. Но представление различных групп пользователей о хранимых в системе данных отражает цели этих групп, которые могут сильно отличаться друг от друга. Следовательно, согласованность представления должна обеспечиваться некоторыми специальными механизмами и соответствующими программными средствами. Причем представление данных, а значит и прикладные программы, не должны изменяться ни при изменении физической организации хранимых данных, ни при включении новых пользователей с их новыми представлениями о данных в систему.
Таким образом, в процессе эволюции программного обеспечения автоматизированных систем обработки информации, возникло четкое понимание возможности и целесообразности разработки и реализации комплексов программ, которые позволяют описывать характерные для обработки данных операции на языке более высокого уровня, чем язык программирования. Такие комплексы получили названия системы управления базами данных (СУБД).
Можно выделить две черты, характерные для современных автоматизированных систем обработки информации:
разнообразие задач, решаемых различными пользователями на общей базе данных, и постоянное улучшение аппаратных средств, предназначенных для хранения и обработки данных. Следовательно, необходимым условием существования СУБД является реализация (в большей или меньшей степени) принципа логической и физической независимости представления данных.
Логической независимостью данных называют возможность изменения логической структуры данных без изменения существующих прикладных программ и технологии обработки данных. Наиболее типичной является ситуация увеличения или уменьшения числа обрабатываемых характеристик какого-либо информационного объекта.
Физической независимостью данных называют возможность изменения физической организации данных без перестройки прикладных программ и логической структуры данных. Наиболее типичной ситуацией, когда необходимость этого требования очевидна, является переход на устройства хранения данных более высокого качества, например, на накопители на магнитных дисках большей емкости.
Стремительное совершенствование технологии производства персональных ЭВМ привело к тому, что использование для обработки данных больших ЭВМ часто становится нецелесообразным, если сравнивать их с компьютерными системами по критерию типа цена/производительность. Во многих случаях роль центральной ЭВМ может выполнять достаточно мощный сервер. Широкое распространение получили системы обработки данных на базе локальных вычислительных сетей (ЛВС), представляющих собой несколько компьютеров, соединенных высокоскоростными линиями связи. Для таких систем характерной чертой является то, что процессы обработки информации частично выполняются в месте ее получения, но наиболее ресурсоемкие процессы обработки информации происходят на сервере.
Фирма Oracle занимает 2 место после Microsoft.
Особенность: установка под очень многие версии ОС.
Oracle – максимально переносимое СУБД, доступна на всех распространяемых платформах. Физическая архитектура Oracle различна в различных ОС.
В Unix Oracle реализована виде нескольких программных процессов.
В Windows Oracle – один многопоточный поток.
Большие ЭВМ Oracle работает на OS/390 и zOS.
В Norwell Oracle использует многопоточную модель.
Преимущества архитектуры Oracle.
Переносимость.
Масштабируемость и расширяемость.
Независимость сред разработки – свой собственный язык PL/SQL.
Различные методы доступа ODO.
Широкая конфигурируемость.
Термины и понятия.
SGA – системная глобальная область – область памяти используемая процессами Oracle в том числе для процесса хэширования.
БД Oracle – набор физических файлов ОС.
Экземпляр Oracle – набор процессов Oracle и SGA.
БД может быть смонтирована и открыта в нескольких экземпляров, но каждый экземпляр может в данный момент времени смонтировать и открыть только 1 БД, но в разное время много БД. Т.о. в каждый момент времени связан 1 набор файлов.
Для одновременного монтирования 1 БД несколькими экземплярами необходимо использовать параллельный сервер Oracle OPS.
II Архитектура и принципы работы сервера Oracle.
ДЕ2: Основные схемы работы СУБД
д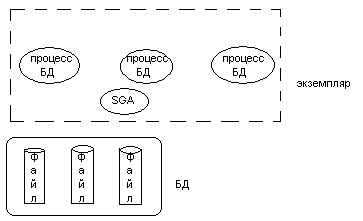 о
монтирования:
о
монтирования:
основная скорость за счет хэширования
Фоновые процессы – постоянно работающие процессы образующие экземпляр.
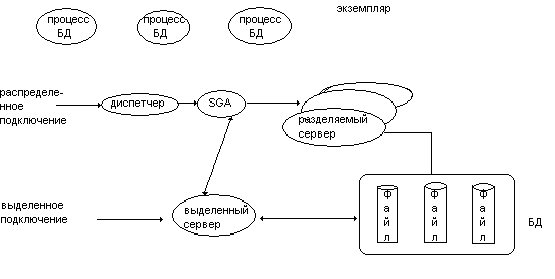
после подключения к СУБД пользователя:

О бычно
СУБДOracle
к подключению пользователя создает
новый процесс (выделенный сервер) такая
схема называется конфигурация выделенного
сервера. Сколько клиентов столько и
серверов. СУБД Oracle
может работать в режиме многопотокового
сервера (МТС). В этом режиме при подключении
пользователя не создается процесс, а
создается пул-серверов для организации
совместного использования, клиентский
процесс по сети взаимодействует со
специальным процессом диспетчера,
который помещает пользовательский
процесс в очередь запросов в SGA.
После этого 1 свободный сервер выбирает
и обрабатывает запрос, после разделяемый
сервер помещает ответ в очередь ответов
и процесс диспетчер передает ответ из
очереди ответов к клиенту.
бычно
СУБДOracle
к подключению пользователя создает
новый процесс (выделенный сервер) такая
схема называется конфигурация выделенного
сервера. Сколько клиентов столько и
серверов. СУБД Oracle
может работать в режиме многопотокового
сервера (МТС). В этом режиме при подключении
пользователя не создается процесс, а
создается пул-серверов для организации
совместного использования, клиентский
процесс по сети взаимодействует со
специальным процессом диспетчера,
который помещает пользовательский
процесс в очередь запросов в SGA.
После этого 1 свободный сервер выбирает
и обрабатывает запрос, после разделяемый
сервер помещает ответ в очередь ответов
и процесс диспетчер передает ответ из
очереди ответов к клиенту.
Подключение клиента к выделяемому серверу:

МТС – имеет несколько диспетчеров на нескольких портах
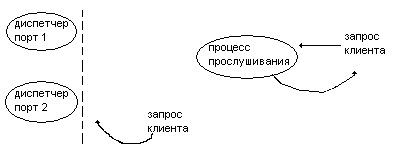
Один экземпляр может использовать оба способа подключения
ДЕ3:Файлы СУБД Oracle
В Oracle 6 типов файлов:
Файл - параметр: при запуске экземпляр Oracle по этому файлу определяет свои характеристики: размеры структур в памяти, место положение устройств файлов и т.д.
Файл - данных – это данные предназначены для хранения таблиц, индексов и др. структур.
Временные файлы – используются при сортировки больших объемов данных и для хранения временных данных.
Управляющие файлы – определяют место нахождения файлов в памяти и др. информацию о состоянии БД.
Файл - журнала повторного выполнения – журнал транзакций.
Файлы – пароли – используются для аутентификации пользователя.
Файлы 2-6 – это БД, самые важные это 2 и 3.
Рассмотрим каждый тип файлов подробнее:
Файл – параметр: самый важный из файлов параметров является файл инициализации экземпляра init – файл. Формирование имени init%ORACLE_SID%.ora. состав параметров, которые можно указать в файле меняется от версии Oracle. Структура файла: <имя_параметра>=<значение>; если значение – строка, то в «»; если список, то (), элементы списка разделяются запятой.
Пример: db_name=”abc816”
db_block_size=8192 – размер блока
_Control_files=(“C:\oradata\cont101.exe”, “C:\oradata\aaa.exe”)
_TRACE_FILES_PUBLIC=TRUE – делает доступными файлы трассировки
Имеется возможность из init файла сослаться на другой IFILE=”имя.ora”
Другие файлы-параметров: TNS NAMES.ora – на клиентской рабочей станции; LISTENER.ora – на сервере для прослушки.
Файл – данных.
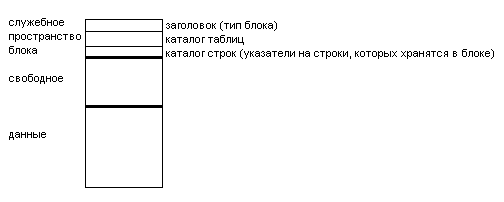
Для хранения в Oracle должен быть указан хотя бы 1 файл. Для обеспечения надежности считается, что файлов данных должно быть 2: 1 – для хранения системных данных и 2 – для пользовательских данных. Для выделения пространства используется понятие – блок – наименьшая единица выделения пространства в Oracle. Блоками выполняют чтение/запись на диск. Размер блока 2-4-8кб допускается 16 и 32кб.
Экстенд – непрерывный фрагмент пространства в файле, состоящий из блоков. Минимальный размер экстенда 1 блок, максимальный – 2Мб.
Сегмент – область на диске выделяемая под объекты, т.е. под таблицы, индексы и т.д. Сегменты состоят из экстендов и если сегмент переполняется, то ему должен быть выделен новый экстенд.
Каждый объект хранится на диске в одном сегменте.
Формат блока
Табличное пространство – контейнер с сегментами. Каждый сегмент принадлежит 1 табличному пространству. В табличном пространстве может быть много сегментов. Сегмент не выходит за границы табличного пространства. Табличное пространство связано 1 или несколькими файлами. Экстенд располагается в 1 файле. Сегмент в нескольких файлах может располагаться.
П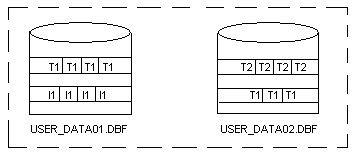 ример:
табличное пространствоUSER
DATA
состоит из 2 файлов.
ример:
табличное пространствоUSER
DATA
состоит из 2 файлов.
4 – экстенда 3 – сегмента
Сегмент Т1 состоит из 2 экстендов, которые располагаются в разных файлах.
Если для табличного пространства понадобится больше места, то нужно увеличить размер данных, либо добавить третий файл.
Табличное пространство – это логическая структура предназначена для разработчиков БД. При этим разработчики оперируют понятиями сегменты, таблицы не опускаясь до уровня файлов. Администратор БД оперирует файлами (может разделить 1 табличное пространство между 2 файлами и расположить эти файлы на различные физические диски).
Для освобождения выделения пространства на диске в ранних версиях Oracle использовалась специальная таблица – словарь БД. Особенность – доступ к любым таблицам через SQL.
Для ускорения доступа было введено понятие временное пространство, использовалось для сортировок, управлением которого осуществляется через оперативную память.
В поздних версиях появились локально-управляемое пространство. В локально-управляемом пространстве для отслеживания экстендов в каждом файле используется битовая строка (1 – экстенд занят, 0 – свободен). Недостаток – экстенды одинаковых размеров. Скорость таких операций значительно больше.
Временные файлы.
Специальный тип файлов в Oracle, при этом сервер Oracle использует временные файлы для хранения результирующих отношений, если для них не хватает места в оперативной памяти. Временные объекты создаются во временном табличном пространстве TEMP. Для его создания в файле инициализации необходимо указать оператор его создания:
creat temporary table space temp
tempfile “C:\TEMP\temp.dbf”
size 5m
extent management local включает локально-упр. табл. пр-во
uniform size 64k задает размер этого пространства.
С временными файлами связаны параметры внешней сортировки – 2 основных параметра:
SORT_AREA_RETAINED_SIZE=<значение> - макс. объем памяти, который может использоваться для внутренней сортировки.
SORT_AREA_SIZE=<значение> - макс. объем памяти для внешней сортировки.
Обычно устанавливают эти параметры одинаковыми порядка 1Мб.
Размер памяти внутренней сортировки может быть получено делением внешней сортировки на параллельное количество сортировок.
Физически временные файлы должны быть отделены от файлов данных.
Управляющие файлы.
Файлы, содержащие информацию о всех файлах необходимую серверу Oracle. Имя файла указывается в init файле. В управляющем файле содержатся сведения о: расположении файлов в БД; расположении файлов журнала повторного выполнения; времени выполнения контрольных точек.
Контрольная точка – место, где физически регистрируется транзакция.
В системе необходимо поддерживать несколько копий таких файлов на разных дисках для облегчения процесса восстановления БД.
Файл - журнала повторного выполнения.
Это журналы транзакций БД. Таких журналов несколько. Один активный журнал в двух файлах и несколько архивных. Их использование позволяет:
Восстановить систему с состояния предшествующему сбою.
Восстановить данные с резервной копии при полном разрушении диска.
Восстановление случайно удаленной таблицы или ее части.
Практически каждое действие выполнения СУБД Oracle генерирует данные повторного выполнения, которые записываются в активные файлы в журнал повторного выполнения.
Активный журнал повторного выполнения.
В каждой БД есть 2 активных файла журнала. Файлы используются поочередно, при заполнении одного файла начинает заполняться другой. Если файлов больше чем 2, то они используются по кольцу. Oracle использует активно свою собственную систему кэширования измененных блоков данных. При этом даже при операции Comet измененные блоки не переписываются на диск, по этой команде в активный файл журнала повторного выполнения записывается вся необходимая информация, которая нужна для повторного выполнения транзакций.
Управляет перезаписью грязных блоков на диск специальный механизм контрольных точек. Реализует этот механизм фоновый процесс DBW. В процессе обработки контрольной точки процесс DBW переписывает грязные блоки из SGA в файлы БД. Обработка контрольной точки может быть вызвана различными причинами, но чаще всего при смене активного файла журнала повторного выполнения. Если в начале повторного сеанса Oracle обнаружит, что последняя контрольная точка не обработана, то он повторит все операции от отработки предыдущей контрольной точки и т.о. восстановит все транзакции. При этом вся необходимая информация содержится в активном журнале повторного выполнения.
Сообщения о всех исключительных ситуациях записываются в специальном файле – журнал сообщений. В этот журнал записывается информация и о незавершенной обработке контрольной точки.
Например: попытка сервера использовать БД до завершения обработки контрольной точки процессом DBW. При правильной настройки Oracle такие сообщения не должны появляться в журнале.
Размер информации сохраняемой в активном файле журнала транзакций существенно различается. Самая большая информация соответствует манипулированию изображениями. При определении размеров активных файлов журнал транзакций нужно учитывать:
Возможность поддержки резервной копии БД в Oracle. Для повышения надежности Oracle поддерживает копию БД на другой ЭВМ. Для того чтобы разсинхронизация основной и резервной БД была бы минимальной необходимо иметь большое количество небольших файлов – журналов.
Большое количество пользователей изменяющих одни и те же блоки. В этом случае требуется больше файлы-журналов, чтобы как можно дольше отложить выгрузку измененных блоков во внешнюю память, но в этом случае самовыгрузка может потребовать значительного времени.
Величина среднего времени восстановления. При наличии большого количества сбоев необходимо сохранить величину среднего времени восстановления для этого файлы-журнала должны быль небольшие.
Архивный журнал повторного выполнения.
БД Oracle может работать в двух режимах:
ARCHIVELOG
NOARCHIVELOG
Архивация файлов журнала транзакций перед его перезаписыванием (копирование активных файлов – журнала).
Без переписывания в архив.
Обычно рекомендуется использовать при эксплуатации 1 режим, а 2 режим – при тестировании.
В режиме 1 достаточно для резервной копии применить активный журнал транзакций и информация будет восстановлена на момент последней записи в архивный журнал. Очевидно, что включение режима 1 замедляет работу системы.
ДЕ4: Структуры памяти. Расчет необходимых размеров областей и пулов.
Существует 3 основных структуры:
SGA – совместно используемый сегмент памяти к которому обращаются все процессы Oracle.
PGA – глобальная область процесса – приватная область памяти процесса или потока, недоступная другим процессам (потокам).
UGA – глобальная область пользователя – эта область памяти связанная с сеансом. Она располагается либо в SGA в режиме МТС, либо в PGA в режиме выделенного сервера.
Области PGA и UGA.
PGA - область памяти процесса, никогда не входит в SGA, всегда локально выделяется процессом, либо потоком. В режиме выделенного сервера UGA фактически синоним PGA (ее часть). Используются эти области в том числе и для внутренних сортировок.
В режиме выделенного сервера PGA должна быть достаточной для выделения в ней UGA.
PGA – куча, в которой хранят значения своих переменных процессы.
UGA – куча, в которой хранят значения своих переменных сеансы.
Область SGA.
- большая разделяемая структура к которой обращаются все процессы. Размеры от нескольких Мегабайт – для тестовых систем, сотни для средних, 1Гб – для крупных.
Область разбита на несколько пулов:
Java – пул – фиксированный пул памяти выделяемый виртуальной Java – машине, которая работает в составе сервера.
Largа – пул – используется сервером в режиме МТС для размещения памяти сеанса и при резервном копировании для буферов дискового ввода/вывода.
Shared – пул – разделяемый пул, содержит разделяемую информацию (курсоры, процедуры, объекты описывающие состояния).
Неопределенный пул – это память, выделяемая под буфера блоков (кэш блоков данных), буфер журналов повторного выполнения и фиксированная область SGA.
Управляется область SGA параметрами из файла init.ora:
JAVA_POOL_SIZE;
SHARED_POOL_SIZE;
LARGA_POOL_SIZE;
DB_BLOCK_BUFFERS;
LOG_BUFFERS – размер журнала повторного выполнения.
Фиксированная область памяти SGA – часть области SGA, размер которой зависит от платформы и версии Oracle. Можно ее рассматривать как загрузочную часть SGA используемую сервером Oracle для поиска других компонентов SGA.
Буфер журнала повторного выполнения используется для временного кэширования данных активного журнала повторного выполнения перед записью его на диск. Он сбрасывается на диск тогда когда:
- один раз через каждые 3 секунды;
- при фиксации транзакций;
- при заполнении буфера больше, чем на 1/3 или когда в нем оказывается 1Мб журнала повторного выполнения.
Устанавливать это значение больше 1Мб нет смысла. Стандартное значение либо 0.5Мб, либо 128число процессов Мб. Минимальное значение этого пространства равно максимальному размеру блока4.
Буферный кэш.
Содержит блоки БД перед их записью на диск. Важно определить максимальные размеры этой области, т.к. если она мала, то кэш часто будет разгружаться на диск и запросы выполняются долго, если пространство большое слишком, то серверу может не хватать пространства для создания глобальной области пространства. Блоки в буферном КЭШе контролируются:
список «грязных» блоков, используют процессы перезаписи этих блоков на диск;
список «чистых» блоков, организован виде очереди, в которой блоки упорядочены по времени.
Кроме этих структур в системных таблицах Oracle содержатся сведения о числе обращений к блоку, что позволяет организовывать различные алгоритмы вытеснения малоиспользуемых блоков из КЭШа в случае его заполнения.
Буферный пул в версиях ниже 8 представлял собой 1 большой кэш. Не было ни каких средств деления буферного КЭШа на части. В 8 версии была добавлена возможность создания нескольких буферных пулов.
С помощью этой возможности можно зарезервировать пространство под весь сегмент, т.е. для таблиц или индексов, следовательно, появляется возможность выделять достаточно места для расположения в ОП некоторых таблиц целиком (частое использование справочника). Такие таблицы конфликтуют за место в КЭШе только с такими же таблицами. Остальные сегменты конфликтуют за место в стандартном пуле.
Буферный пул обеспечивающий кэширование сегментам называется пулом KEEP. Блоками в пуле KEEP сервер управляет блоками как и в обычном пуле. Если блок не используется, а места в пуле нет, то он переписывается во внешнюю память, если блок часто используется, то он остается в КЭШе.
Кроме стандартного пула и пула KEEP можно выделить еще 1 буферный пул, который называется RECYCLE. Из этого пула блоки удаляются сразу после использования. Такая стратегия применяется для больших таблиц в которых вероятность повторного использования какого-либо блока мала. Таким образом буферный пул состоит из 3 пулов.
Распределенный пул.
В распределенном пуле сервер Oracle кэширует различные данные программных компонент:
Кэшируются результаты запроса, если они могут использоваться повторно.
Кэшируется выполняемый код PL/SQL (также повторные использования для разных пользователей).
Кэшируется словарь данных.
Организация распределенного пула похожа на страничную организацию, либо на буферный кэш.
Если каждый передаваемый серверу Oracle запрос специфичен с жестко с заданными константами, то такая тактика вступает в противоречие с распределенным пулом. В этом случае каждый запрос системы рассматривается как абсолютно новый, не смотря на это система все равно кэширует запросы, а результаты его не может использовать и тратит дополнительные ресурсы. Распределенный пул начинает снижать производительность. Его увеличение приводит к отрицательному результату. Выходом является использование повторно разделяемых операторов с так называемыми связанными переменными.
Большой пул.
Память в большом пуле используется по принципу кучи (по мере надобности). Используется в решении МТС для областей UGA и SGA; при распараллеливании выполнении операторов как буфер сообщения между процессами; при резервном копировании для буфера ввода/вывода.
Java-пул.
Добавлен только с версии 8.1.5. Предназначен для поддержки Java-машины в БД. Хранит процедуры на Java. В режиме разделяемого сервера Java – пул включает разделяемый Java-класс, который используется хотя бы в одном сеансе. Общий размер 8кБ*число Java классов. Обычно от 32кБ до 1Гб.
В режиме МТС кроме разделяемых частей, так же содержится информация о состоянии классов сеанса, при большом количестве пользователей, то он должен быть достаточным.
ДЕ5: Процессы. СУБД Oracle.
Процессы, т.е. поток Windows.
В экземпляре Oracle имеется 3 класса процессов:
серверные процессы, выполняющие запросы клиентов;
фоновые процессы, выполняющие запись блоков на диск и поддержку активного журнала повторного выполнения;
подчиненные процессы, основное назначение такое как у фоновых, но выполняют от имени фоновых либо серверных.
Серверные процессы.
Тратят основную часть процессорного времени. Выполняют: сортировку, суммирование и др.
Пример: выделенный и разделяемый сервер.
Фоновые процессы.
Выполняются при загрузке экземпляра и решают различные задачи поддержки БД. В основном эти процессы связаны с длительными операциями ввода/вывода.
Пример:
DBWr – отвечают за запись «грязных» блоков на диск из буферного КЭШа.
LGWR – запись журнала, отвечает за сброс на диск активного буфера повторного выполнения.
PMON – монитор процессов, отвечает за очистку после нештатного отключения подключения (если сервер отключается или падает или получив сигнал прекращает работу, этот процесс откатывает не зафиксированные изменения, снимает блокировки, освобождает ресурсы в области SGA, выделенные прекратившему работу процессу). Кроме того монитор процессов контролирует другие фоновые процессы и при необходимости их перезапускает. Монитор net8 используется для прослушки стандартного сетевого протокола.
SMON – монитор системы, играет роль сборщика мусора для БД. Выполняет освобождение экстентов для процессов закончившихся аварийно, восстановление экземпляра после запуска и т.д.
RECO – процесс восстановление распределенной БД. В Oracle имеется специальный протокол 2PC – двух этапная фиксация транзакций в распределенной БД. В случае сбоя процесс RECO пытается либо восстановить, либо откатить эту транзакцию.
CKPT – процесс обработки контрольных точек, обновляет заголовки файлов, которые переписывают «грязные» блоки.
ARCn – архивирование и кэширования в другое место активного журнала.
BSP – сервер блоков. В среде OPS несколько серверов Oracle могут иметь доступ к 1 БД. При этом буферный кэш в SGA всех машин должны быть подчиненными, синхронизацию этих кэшов осуществляет процесс BSP.
LMON – монитор контроля блокировок, это в среде OPS восстанавливает глобальные блокировки, которые удерживаются сбойным экземпляром.
LMD – демо диспетчера блокировок, в среде OPS, управляет глобальными блокировками и глобальными ресурсами.
Служебные фоновые процессы (SNPn)
- обработка снимков (очередей заданий), запускает посланные на выполнения задания, которые находятся в очереди пакетных заданий. Очередь позволяет выполнять по расписанию однократные/периодические задания. Процесс появился в версии 7.0 и первоначально предназначался для поддержания репликации – в виде снимка БД snapshort.
Этот процесс контролировал очередь задания и определял когда необходимо обновлять снимки. Позже понятие поддержка снимков заменили на очередь заданий QMNn – монитор очередей, поддерживает и обрабатывает табличные очереди, реализует средства расширенной поддержки очередей, они поддерживают возможность обмена сообщениями между сеансами БД.
Подчиненные процессы.
Выделяют 2 вида:
Подчиненный процесс ввода/вывода, для асинхронного ввода/вывода в системах или устройствах, которые его не поддерживают. Позволяет имитировать для ленточных устройств способ работы, который ОС использует для дисков. Существенно увеличивает производительность и эти процессы используют процессор записи блоков данных.
Подчиненные процессы параллельных запросов. В Oracle версии 7.1 появились средства распараллеливания запросов в БД, которые реализованы при выполнении операторов SQL типа SELECT, CreateIndex и т.д.
Так как план выполнения этих операторов состоит из нескольких планов, появилась возможность параллельного выполнения. Общее время сокращается, но эффект возможен при наличии нескольких центральных процессоров.