

Гуманитарные аспекты теории информации
.pdfпервого символа приписывают 1, а всем нижним – 0. Каждую из полученных групп, в свою очередь, разбивают на две подгруппы по тому же принципу и т.
д. Процесс повторяется до тех пор, пока в каждой подгруппе не останется по одному символу.
При кодировании по этому принципу средняя длина кодовой комбина-
ции близка к минимальной, а энтропия на выходе кодера максимальна.
Методика построения кода Хаффмена сводится к следующему. Буквы алфавита вписывают в основной столбец (табл. 1.4) в порядке убывания веро-
ятностей. Два последних символа объединяют в один вспомогательный сим-
вол, которому приписывают суммарную вероятность. Вероятности символов,
не участвовавших в объединении, и полученную суммарную вероятность сно-
ва располагают в порядке убывания вероятностей в дополнительном столбце,
а две последние объединяют. Процесс продолжается до тех пор, пока не полу-
чим единственный вспомогательный символ с вероятностью, равной единице.
Таблица 1.4
Алфавит |
Вероятности |
|
|
|
|
|
|
|
Вспомогательные столбцы |
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
a1 |
0,22 |
|
|
0,22 |
|
0,22 |
|
|
0,26 |
|
|
0,32 |
|
|
0,42 |
|
|
|
0,58 |
|
|
|
1 |
||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
a2 |
0,20 |
|
|
0,20 |
|
0,20 |
|
|
0,22 |
|
|
0,26 |
|
|
0,32 |
|
|
|
0,42 |
|
|
|
|
||
a3 |
0,16 |
|
|
0,16 |
|
0,16 |
|
|
0,20 |
|
|
0,22 |
|
|
0,26 |
|
|
|
|
|
|
|
|
||
a4 |
0,16 |
|
|
0,16 |
|
0,16 |
|
|
0,16 |
|
|
0,20 |
|
|
|
|
|
|
|
|
|
|
|
||
a5 |
0,10 |
|
|
0,10 |
|
|
|
0,16 |
|
|
0,16 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
a6 |
0,10 |
|
|
0,10 |
|
|
|
0,10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
a7 |
0,04 |
|
|
0,06 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
a8 |
0,02 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Далее строят кодовое дерево(рис. 1.1). Из точки, соответствующей ве-
роятности 1, направляют две ветви, причём ветви с большей вероятностью присваивают символ 1, а с меньшей0. Такое последовательное ветвление продолжают до тех пор, пока не дойдут до вероятности каждого символа.

|
|
|
|
0,58 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
0,32 |
|
0 |
0,26 |
|
0 |
0,42 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
0,16 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,06 |
|
0,1 |
|
|
|
|
|
|
|
|
|
|
0,1 |
1 |
0 |
|
0 |
|
|
|
|
|
|
0,16 |
|
|
|
|
|
|
0,22 |
|
|
0,2 |
||||
1 |
0 |
0,16 |
0,04 |
1 |
0 |
0,02 |
|
|
1 |
0 |
||||
а3 |
|
|
а4 а6 |
|
а7 |
|
|
а8 |
а5 |
а1 |
|
|
а2 |
|
Рис. 1.1
Двигаясь по кодовому дереву сверху вниз, записывают для каждого символа соответствующую ему кодовую комбинацию: а1 – 01; а2 – 00; а3 –
111; а4 – 110; а5 – 100; а6 – 1011; а7 – 10101; а8 – 10100.
Любой эффективный код должен обладать свойством префиксности,
т. е. никакая более короткая кодовая комбинация не должна являться началом более длинной.
Задача 2
Тема: Помехоустойчивое кодирование
Задача 2.1
Код задан производящей (генераторной) матрицей [G] (табл. 2.1).
По заданной матрице необходимо:
1.Определить параметры кода: n, k, N, M.
2.Построить проверочную матрицу.
3.Составить уравнения проверок.
4.Составить таблицу исправлений.
5.Найти кодовое расстояние и определить возможности кода по обна-
ружению и исправлению ошибок.
6.Составить схемы кодера и декодера, исправляющего одиночную ошибку.
Задача 2.2
Код задан проверочной матрицей [H] (табл. 2.2).
По заданной матрице необходимо:
1.Построить генераторную матрицу.
2.Определить параметры кода: n, k, N, M.
3.Составить уравнения проверок.
4.Составить таблицу исправлений.
5.Найти кодовое расстояние и определить возможности кода по обна-
ружению и исправлению ошибок.
6.Составить схемы кодера и декодера, исправляющего одиночную ошибку.
Задача 2.3
Код задан схемой кодирующего устройства (табл. 2.3).
По заданной схеме необходимо:
1.Составить уравнения проверок.
2.Построить генераторную и проверочную матрицы.
3.Составить таблицу исправлений.
4.Определить параметры кода: n, k, N, M.
5.Найти кодовое расстояние и определить возможности кода по обна-
ружению и исправлению ошибок.
6.Составить схему декодера, исправляющего одиночную ошибку.
Краткие сведения из теории
Кодер источника, или первичный кодер, осуществляет эффективное ко-
дирование, т. е. кодирование с целью уменьшения избыточности источника информации.
Однако двоичные слова первичного кодера не в состоянии противосто-
ять действию помех, т. к. любая ошибка переводит одну разрешенную кодо-
вую комбинацию в другую разрешенную. Для того чтобы ошибки можно бы-
ло обнаруживать и исправлять, необходимо, чтобы число возможных кодовых комбинаций было больше числа разрешенных. Эту задачу выполняет кодер канала, или вторичный кодер, который к k символам первичного кодера до-
бавляет по определенным правиламr проверочных символов. Общая длина кодового слова на выходе кодера канала становится равнойn = k + r, и общее число возможных кодовых комбинаций (N = 2n) будет намного больше числа разрешенных (M = 2k), что дает возможность обнаруживать и исправлять ошибки в тех или иных позициях кодового слова канала.

Пример. Код задан производящей (генераторной) матрицей:
æ1 |
0 |
0 |
1 |
0 |
1 |
ö |
|
ç |
|
|
|
1 |
1 |
|
÷ |
G = ç0 1 0 |
0÷. |
||||||
ç |
0 |
0 |
1 |
0 |
1 |
1 |
÷ |
è |
ø |
||||||
Параметры кода: n – длина кодовой комбинации (количество столбцов в матрице), n = 6.
Каждая строка матрицы [G] состоит из k информационных символов и r
проверочных:
V= a1 a2 Kak bk +1 bk +2 Kbn .
14243 1442443
k |
r |
Разбиваем [G] на 2 части так, чтобы слева осталась единичная матрица1; k равно количеству столбцов в этой единичной матрице (k = 3).
|
a1 |
a2 |
a3 |
b4 |
b5 |
b6 |
– разряды кодовых комбинаций: |
||
æ1 |
0 |
0 |
|
1 |
0 |
1 |
ö |
a – информационные |
|
|
b – проверочные |
||||||||
ç |
|
|
0 |
1 |
1 |
|
÷ |
||
G = ç0 1 |
0÷, |
|
|||||||
ç |
0 |
0 |
1 |
|
0 |
1 |
1 |
÷ |
|
è |
|
ø |
|
||||||
|
|
Ek |
|
R |
|
|
|
||
где Ek – единичная подматрица k-го (3-го) порядка;
R – проверочная подматрица.
Определим N – количество возможных кодовых комбинаций длиной n:
N = 2n , N = 26 = 64 кодовые комбинации.
1 Единичная матрица – это квадратная матрица, у которой по главной диагонали единицы, а все остальные символы – нули.

Определим М – количество разрешенных кодовых комбинаций:
M = 2k , M = 23 = 8 кодовых комбинаций.
Построим проверочную матрицу. Она состоит из двух подматриц:
æ1 |
1 |
0 1 |
0 |
0 |
ö |
||
ç |
|
|
1 |
0 |
1 |
|
÷ |
H = ç0 1 |
0÷, |
||||||
ç |
1 |
0 |
1 |
0 |
0 |
1 |
÷ |
è |
ø |
||||||
|
RТ |
|
Еn-k |
|
|
|
|
где RТ – транспонированная2 матрица R; |
|
||
Еn-k – единичная подматрица порядка n-k. |
|
||
Запишем уравнения проверок(по [H]). В уравнение входят только те разряды, которым соответствуют единицы в соответствующих строках матри-
цы [H]:
a1 Å a2 Å b4 = 0 a2 Å a3 Åb5 = 0 a1 Å a3 Åb6 = 0
Составим таблицу исправлений (синдромов3) для информационных раз-
рядов:
Синдром |
S1 |
S2 |
S3 |
|
|
|
|
Конфигурация синдрома |
101 |
110 |
011 |
|
|
|
|
Ошибочная позиция |
a1 |
a2 |
a3 |
|
|
|
|
2 Транспонированной называют матрицу, строками которой являются столбцы, а столбцами – строки исходной матрицы.
2 Синдромы (исправляющие векторы кодовой комбинации) – это столбцы проверочной матрицы.

Кодовое расстояние dmin равно числу единиц в строке матрицы [G] с ми-
нимальным весом4: dmin = 3.
Количество обнаруживаемых ошибок (кратность ошибки) определяется из неравенства:
dmin ³ Q +1,
где Q – кратность ошибки.
3 ³ Q +1, Q £ 2.
Таким образом, если в кодовой комбинации произошло одновременно две ошибки, то код позволит их обнаружить.
Количество исправляемых ошибок определяется из неравенства:
dmin ³ 2Q +1.
3 ³ 2Q +1, Q £ 1.
Таким образом, код может исправить только одиночную ошибку(ошиб-
ку в одном разряде).
Схемы кодера и декодера
Суммирование и вычитание по модулю два– операции эквивалентные.
Поэтому алгоритм формирования контрольных символов можно получить,
переписав уравнения проверок:
4 Вес кодовой комбинации равен количеству «1» в ней.

b4 = a1 Å a2 b5 = a2 Å a3 . b6 = a1 Å a3
Кодер состоит из n-разрядного универсального регистра сдвига и n – k = r сумматоров по модулю два (в нашем случае сумматора три). В регистр мож-
но одновременно записать k информационных символов (в нашем случае три).
После этого формируются контрольные символы, согласно уравнениям про-
верок. Схема кодера приведена на рис. 2.1.
от источника информации
b 6 |
b5 |
b 4 |
a 3 |
a 2 |
a 1 |
|
в канал |
|||
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
+
+
+
Рис. 2.1
Схема декодера, обнаруживающего ошибки, также составляется по уравнениям проверок. Регистр также n-разрядный. Сумматоров столько же,
сколько и в схеме кодера, только у каждого из них на один вход больше. Если ошибок не было, то уравнения проверок выполняются и на входах и выходе схемы «ИЛИ» – нули. Если хотя бы в одной позиции была ошибка, то хотя бы на одном из входов и выходе появится«1», что сигнализирует об ошибке.
Схема декодера, обнаруживающего ошибки, приведена на рис. 2.2.
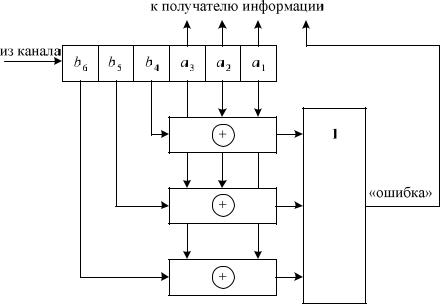
Рис. 2.2 |
Схема декодера, исправляющего одиночную ошибку, приведена на рис. 2.3. Работает декодер следующим образом. Кодовые комбинации из канала в последовательном режиме записываются в регистр Рег. 1. С помощью трех сумматоров по модулю два осуществляется проверка на наличие ошибки в информационных разрядах, согласно уравнениям проверок. В зависимости от номера разряда, в котором произошла ошибка, на выходах 1-го, 2-го и 3-го сумматоров будут различные кодовые комбинации. Если ошибка произошла в разряде a1, то на выходах трех сумматоров появится комбинация101, т.к. a1
подается на первый и третий сумматоры; если ошибка в разряде a2 – комбина-
ция 110 (a2 подается на первый и второй сумматоры); если ошибка в разряде a3 – комбинация 011 (a3 подается на второй и третий сумматоры). Если ошиб-
ки нет, то кодовая комбинация будет000. Эти кодовые комбинации называ-
ются синдромами ошибок.
Анализ синдромов осуществляет дешифратор синдромов(ДС). Он име-
ет три выхода. При наличии ошибки «1» появится на том выходе, в какой по-
зиции произошла ошибка. На остальных выходах – нули.

Ошибка исправляется следующим образом. Для исправления ошибки нужно знать номер позиции, в которой она произошла. Как следует из табли-
цы истинности для двухвходового сумматора по модулю «два», если на одном входе «0», то для второго входа сумматор работает как повторитель. Если же на одном из входов «1», то для второго входа он работает как инвертор. Оче-
видно, что для того чтобы исправить ошибку в двоичном коде, надо ошибоч-
ный разряд инвертировать. Например, произошла ошибка в разрядеa1. Син-
дром ошибки будет 101, на выходе дешифратора синдромов– 100. Поэтому второй и третий разряды инвертированы не будут, а первый разряд будет ин-
вертирован. Таким образом, в регистр Рег. 2 запишется исправленная инфор-
мационная кодовая комбинация, которую примет получатель информации.
Рег. 1 |
|
|
a1 |
|
+ |
a2 |
|
+ |
a3 |
Сум. 1 |
+ |
|
|
|
b4 |
1 1 0 |
1 0 0 |
|
+ |
|
b5 |
|
ДС |
b6 |
|
|
Сум. 2 |
|
|
|
|
|
|
0 1 1 |
0 1 0 |
из канала |
+ |
|
|
|
|
|
Сум. 3 |
|
|
1 0 1 |
0 0 1 |
|
+ |
|
|
Рис. 2.3 |
|
Рег. 2
a1
a2
a3
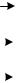 к получателю информации
к получателю информации