

ЭЛЕМЕНТЫ ТЕОРИИ АЛГОРИТМОВ_учит
.pdfследующем такте снова ищется вхождение левой части первой пары уже в измененное слово. Если нет вхождения слова P1, то первый такт продолжается аналогичным рассмотрением второй пары и т. д. Если при попытке применить формулу подстановки оказывается, что имеется несколько вхождений ее левой части, то всегда заменяется первое (самое левое) вхождение.
Если удалось применить какую-то формулу подстановки, отыскав в преобразуемом слове левую часть формулы и заменив ее на правую часть, то всегда на следующем такте возвращаются к самому началу нормального алгоритма и снова ищут вхождение левой части первой формулы в измененное слово. Если же какую-то формулу не удалось применить, то происходит попытка применить следующую за ней формулу. Процесс выполнения нормального алгоритма заканчивается в одном из двух случаев:
-либо все формулы оказались неприменимыми, т. е. в обрабатываемом слове нет вхождений ни одной левой части ка- кой-либо формулы подстановки;
-либо только что применилась завершающая формула, в
которой левую и правую части разделяет знак .
Влюбом из этих случаев считается, что нормальный алгоритм применим к данному входному слову. Если же в процессе выполнения нормального алгоритма бесконечное число раз применяются незавершающие формулы, то алгоритм неприменим к данному входному слову.
Влевых и правых частях формул подстановок могут содержаться пустые слова, не имеющие в своем составе ни одной буквы. Для записи нормальных алгоритмов не требуется специального обозначения пустого слова, так как в этой конструкции нет ячеек, не зафиксирован носитель информации, а преобразуемое слово свободно раздвигается и сужается.
Переход от иных способов описания алгоритмов к эквивалентным нормальным алгоритмам называется представлением
внормальной форме, или нормализацией.
Вкачестве примера мы опишем нормальную форму алгоритма кодировки знаками 0 и 1 слов из алфавита {а, b, с}:
109
а 101 b 1001
с 10001.
Рассмотрим применение этого алгоритма к входному слову сааb. Входное слово содержит букву а два раза. Поскольку всегда заменяется первое вхождение, то в нашем случае первая буква а заменится на 101 и мы получим измененное слово
c101аb.
На следующем такте выполнения нормального алгоритма снова ищется вхождение левой части первой формулы и, отыскав и заменив его на правую часть, получаем
c101101b.
Теперь первая формула оказывается неприменимой, применяется вторая формула и получается
c1011011001.
Опять ищется вхождение левой части первой формулы (вообще говоря, оно могло бы появиться в результате произведенного изменения, если бы буква а содержалась в правой части примененной формулы). Затем пытаемся применить вторую формулу, но в данном случае оказывается применимой только третья формула. После ее применения получается слово
100011011011001,
к которому нельзя применить ни одну формулу. Работа алгоритма завершилась, и мы получили искомую кодировку.
Рассмотрим еще несколько простых нормальных алгоритмов. Алгоритм
а b
с
стирает во входном слове буквы а, b, с.
По определению, вхождения пустого слова имеются слева и справа от каждой буквы в преобразуемом слове. Первое из них предшествует первой букве слова. Поэтому алгоритм
а,
110
который заменяет вхождение пустого слова на букву а, будет бесконечно приписывать букву а к исходному слову, а это означает, что он не применим ни к какому слову.
Алгоритм
а
применим к любому слову, так как состоящие из одной завершающей формулы алгоритмы останавливаются (т. е. заканчивают свое выполнение) либо сразу, если формула неприменима к входному слову, либо, как в нашем случае, после однократного применения формулы, хотя полученное слово и будет снова содержать вхождение левой части формулы.
Алгоритм
101 а
1001 b
10001 с
тоже применим к любому слову. Легко видеть, что он выполняет обратную задачу по сравнению с рассмотренным выше алгоритмом двоичной кодировки, так как позволяет по слову из знаков 0 и 1 получить слово из букв.
Признаки сходимости нормальных алгоритмов Маркова
Сформулируем два простых достаточных признака применимости нормального алгоритма ко всем входным словам:
1)во всех формулах подстановок левые части не пустые, а
вправых частях нет тех букв, которые входят в левые части;
2)в каждом правиле подстановки правая часть короче, чем
левая.
Первый признак гарантирует от «зацикливания», поскольку при замене вхождений левых частей на правые алгоритм с разными алфавитами левых и правых частей не может сам создавать для себя новые возможности выполнения. (Заметим, что этому признаку удовлетворяет рассмотренный нами алгоритм двоичной кодировки и алгоритм, решающий обратную задачу).
Если выполняется второй признак, то после каждого применения формулы подстановки длина слова уменьшается, поскольку большее подслово заменяется на меньшее. Поэтому
111
число замен не может превысить длину исходного слова. (Этому признаку удовлетворяет, например, алгоритм стирания букв а, b, с.) Заметим, что алгоритм, удовлетворяющий второму признаку, не может содержать формул подстановки с пустыми левыми частями, так как не бывает слов короче пустого.
Примеры
Перейдем теперь к несколько более сложным примерам. Попробуем построить нормальный алгоритм приписывания к любому слову в алфавите {а, b, с} справа буквы а. В отличие от машины Тьюринга, свободно передвигающей свой автомат вдоль ленты, нормальный алгоритм не имеет непосредственного доступа к правому концу входного слова. Однако мы будем моделировать такой доступ, введя в алфавит специальную букву * для отметки интересующего нас места в слове. Будем реализовывать искомый нормальный алгоритм по следующей схеме.
1°. Приписать букву * к входному слову слева.
2°. Если буква * не последняя в слове, то поменять ее местами со следующей буквой и снова выполнить п. 2°.
3°. Заменить букву * на букву а и остановить алгоритм. Нормальный алгоритм имеет непосредственный доступ к
левому концу слова. Для того чтобы приписать букву * к входному слову слева, достаточно применить формулу подстановки
*
Для выполнения п. 2° нужны три формулы подстановок: *а а*
*b b* *с с*
Для замены буквы * на букву а нужна еще одна формула подстановки * а.
Эта формула содержит стрелку , потому что ее применением завершается выполнение алгоритма. Теперь, чтобы получить нужный нам нормальный алгоритм, остается установить порядок этих пяти формул подстановок. Нельзя начинать запись нормального алгоритма формулой
112
*
так как эта формула оказывается применимой всегда, и поэтому она применялась бы снова и снова бесконечно долго, причем к слову приписывались бы слева все новые и новые буквы *. Чтобы избежать такого бесконечного применения, поместим эту формулу в конец нормального алгоритма после завершающей формулы * а:
*а а* |
(1) |
*b b* |
(2) |
*с с* |
(3) |
* а |
(4) |
* |
(5) |
Для удобства рассмотрения алгоритма формулы подстановки пронумерованы.
Если входное слово состоит из букв а, b, с, то к нему не применимы первые четыре формулы, левые части которых содержат знак *. Выполнение алгоритма начинается с применения формулы (5), что приводит к приписыванию знака * к слову слева. Затем, в зависимости от порядка букв во входном слове, применяются формулы (1) - (3), и каждый раз знак * сдвигается на одну позицию вправо. Так продолжается до тех пор, пока знак * не достигнет правого конца слова. Сигналом об этом будет неприменимость формул(1) - (3) из-за того, что правее знака * нет буквы. Тогда применяется завершающая формула (4), в результате чего на правом конце слова знак * заменяется на букву а и выполнение алгоритма заканчивается. Например, если входным словом было
ааbса
то алгоритм будет выполняться в такой последовательно-
сти: |
|
Преобразованное |
Примененная |
слово |
формула подстановки |
*ааbса |
(5) |
а*аbса |
(1) |
аа*bса |
(1) |
113
ааb*са |
(2) |
ааbс*а |
(3) |
ааbса* |
(1) |
ааbсаа |
(4) |
Можно доказать, что данный алгоритм применим к любому слову, хотя он и не удовлетворяет сформулированным нами достаточным признакам применимости.
Если, имея этот алгоритм, мы захотим приписывать справа не букву, а любое слово, то нам достаточно изменить только завершающую формулу (4).
Например, если заменить ее на * bас, мы будем выполнять ту же последовательность действий, но на последнем этапе перемещенный в правый конец слова знак * заменится на bас.
Теперь продемонстрируем возможность применения нормальных алгоритмов для арифметических вычислений. В принципе, нормальные алгоритмы могут работать с любой формой записи чисел, но для простоты мы будем изображать числа наборами вертикальных палочек, разделяя их знаком *. Например, число 5 изображается как |||||, а запись ||||| * ||| является изображением двух чисел 5 и 3.
Алгоритм вычисления модуля разности двух чисел а - b описывается двумя формулами подстановки:
* * *
При его выполнении последовательно применяется первая формула, и каждый раз слева и справа от знака * исчезает по одной палочке. Когда меньшее из двух чисел исчерпается, первая формула окажется неприменимой и алгоритм завершится применением второй формулы, которая сотрет знак *. Можно было бы снабдить вторую формулу признаком завершаемости, но в этом нет необходимости, так как после ее применения обе формулы оказываются неприменимыми из-за исчезновения знака *.
114
Алгоритм получения остатка от деления числа на 5 реализуется одной формулой
||||| .
При каждом применении этой формулы число уменьшается на 5, и так продолжается до получения остатка, меньшего, чем 5.
Если нужно получать не только остаток, но и частное, то можно воспользоваться таким нормальным алгоритмом:
*||||| |* * *
*
Входным словом является набор палочек без знака *. Поэтому сначала первая и вторая формулы не применимы, и мы применяем третью формулу, приписывая к числу слева знак *. Затем последовательно применяется первая формула, и каждый раз остаток уменьшается на 5, а частное увеличивается на 1. Когда первая формула оказывается неприменимой из-за того, что справа от знака * не нашлось пяти палочек, применяется вторая, завершающая формула, которая введена только для того, чтобы алгоритм прекратил выполняться, а не «проскочил» на выполнение последней формулы.
Т.о., нормальный алгоритм Маркова задается алфавитом А и нормальной схемой подстановок, где алфавит - конечное, непустое множество элементов называемых буквами. Различные сочетания букв образуют слова.
Нормальная схема подстановок - это конечный набор, состоящий из пар слов, где левое слово переходит в правое. Каждая пара представляет собой формулу подстановки для замены подслов в преобразуемом слове. В левых и правых частях формул подстановок могут содержаться пустые слова.
Сравнение алгоритмических схем Маркова и Тьюринга
Алгоритмические схемы Маркова и Тьюринга эквивалентны в том смысле, что все алгоритмы, описываемые в одной из этих схем, могут быть описаны и в другой.
115
Как и машина Тьюринга, алгоритмическая схема Маркова в общем случае не может быть физически реализована, так как она допускает неограниченно большую длину входных слов и слов, возникающих в процессе подстановок. Сравнивая алгоритмические схемы Тьюринга и Маркова, мы можем отметить, что у машины Тьюринга сравнительно лучше развито управление при слабых возможностях преобразования информации, тогда как в алгоритмической схеме Маркова богаче возможности преобразования информации при менее развитом управлении.
Вмашине Тьюринга предусматривается управление последовательностью доступа к различным элементам обрабатываемого слова (сдвиги влево и вправо). Алгоритмическая схема Маркова жестко закрепляет последовательность доступа (каждый раз ищется первое вхождение левой части очередной формулы подстановки). Аналогично и последовательность действий: в машине Тьюринга управляемая (за счет смены состояний), а в алгоритмической схеме Маркова жесткая (последовательный перебор формул подстановки, а после каждого применения не завершающей формулы возврат к самой первой формуле).
Вто же время элементарная операция по преобразованию информации в машине Тьюринга очень проста (замена буквы в ячейке ленты), а в алгоритмической схеме Маркова весьма мощная (замена любого слова на любое другое слово).
116
Общерекурсивные и рекурсивно-перечислимые множества
Для функций мы описали два фундаментальных семейства: общерекурсивных и частично-рекурсивных.
Рассмотрим множество целых неотрицательных чисел
N0 = {0, 1, 2, ….}
и его всевозможные подмножества.
Некоторым аналогом семейств функций ОР и ЧР будут семейства множеств О и Р, которые определим следующим образом:
Для множества А рассмотрим функцию
1, если x A,
A x
0,если x A.
Назовем ее характеристической функцией для множества А. Будем говорить, что множество А – общерекурсивно (А О), если А(х) - общерекурсивная функция.
Будем говорить, что множество А – рекурсивно перечислимо (А Р), если оно пусто или существует общерекурсивная функция (х) такая, что множество А есть область значений функции (х), т.е. А = { (0), (1), (2), …}.
Замечание. Определение рекурсивно перечислимого множества можно было дать аналогично определению общерекурсивных множеств, используя множество частично рекурсивных функций и так называемую частично рекурсивную характеристическую функцию для множества.
Пусть имеются два семейства множеств О и Р.
Теорема. Если А О, то А Р. (Если множество А общерекурсивно, то оно рекурсивно перечислимо).
Доказательство: Пусть А О и А(х) - общерекурсивная характеристическая функция для А.
Возможны случаи: 1) А = . Тогда А Р.
2)А – конечное множество. А = {a0, a1, …, an}.
Положим: (х) = ai, если i = rest(x, n+1).
3)А – бесконечное множество.
Положим: (0) = y[ А(х) = 1];
117
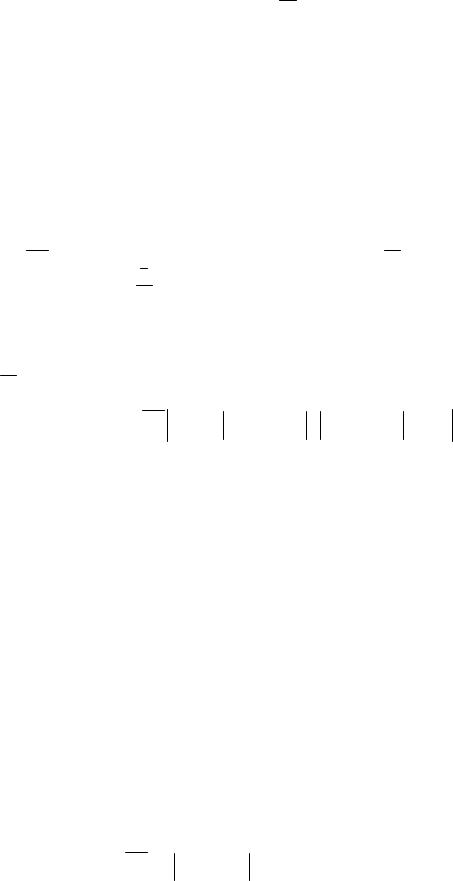
(x+1) = y[ А(х) = 1 и y > (х)]. Тогда { (0), (1),…} = A, ч. и т.д.
Докажем теорему Э. Поста.
ТПоста. А О А Р и A P .
Множество А общерекурсивно тогда и только тогда, когда
оно само и его дополнение рекурсивно перечислимо. |
|
||
|
|
При доказательстве будем использовать функции: |
|
|
|
0, если x 0, |
и |
sg x |
|||
|
|
1, в остальных случаях |
|
|
|
1, если x 0, |
|
|
|
|
|
sg x |
|
||
|
|
0, в остальных случаях. |
|
1) sg A x A x . Если А О, то А и A P . 2) Пусть А и A P .
Имеем для некоторых (x) и (x):
А = { (0), (1),…}
A 0 , 1 ,... .
Тогда A x sg y y x y x x . Что и т.д.
Зная некоторые свойства перечисляющей множество А функции (x), можно иногда узнать является ли множество А общерекурсивным.
Рассмотрим теорему:
Т. Бесконечное рекурсивно перечислимое множество А общерекурсивно тогда и только тогда, когда А можно перечислить монотонно возрастающей общерекурсивной функцией.
Доказательство. Если А – общерекурсивное множество, то функция (x):
(0) = y[ А(х) = 1];
(x+1) = y[ А(х) = 1 и y > (х)] монотонно возрастающая, перечисляющая А.
Если нам известно, что перечисляющая множество А функция (х) монотонно возрастающая, то
x
A x sg i x .
i 0
118