

новая папка / Hw_1 / MxPSER_HW1
.docМинистерство образования Российской Федерации
Государственный Университет Управления
Кафедра Экономической Кибернетики
Домашняя Работа № 1
по дисциплине: “Прогнозирование Социально Экономического Развития”
на тему: “Анализ временных рядов”
Выполнил: студент ИИСУ
ММиИОЭ IV-1
Постельник М. С.
Проверил: к.э.н., доцент
Писарева О.М.
Москва 2001
Задание.
Содержание.
Алгоритмические методы сглаживания. 4
Метод обычного среднего. 4
Метод простого скользящего среднего. 4
Метод взвешенного скользящего среднего. 6
Метод экспоненциально взвешенного скользящего среднего. 8
Аналитические методы выделения неслучайнойсоставляющей. 9
Проверка гипотезы о наличии тенденции. 9
Модель тренда. 11
Приложение 1. 14
Приложение 2.1 15
Приложение 2.2 16
Приложение 3.1.а 17
Приложение 3.1.б 19
Приложение 3.2 20
Приложение 3.3 21
Приложение 4.1 22
Приложение 4.2 23
Приложение 5.1 24
Приложение 6.1 25
Приложение 6.2 26
Алгоритмические методы сглаживания.
Метод обычного среднего.
Исходные данные приведены в Приложении 1.
Для построения краткосрочного прогноза на основе обычного среднего определяется среднее значение уровней всего ряда, затем строятся точечный и интервальный прогнозы на один период вперед.
Воспользуемся формулой простой средней величины:

Точечный прогноз на основе обычного среднего:
![]()
![]()
Интервальный прогноз на основе обычного среднего:
![]()
![]()

![]()
![]()
Метод простого скользящего среднего.
Исходные данные приведены в Приложении 1.
Перед построением прогноза с помощью простого скользящего среднего, требуется произвести подбор интервала сглаживания, дающего наибольшую точность прогноза. Для этого разобьем исходный ряд на два участка: тестовый (уровни исходного ряда с 1 по 30 период) и проверочный (с 31 по 35 период). В процессе исследования сначала производится сглаживание уровней тестового участка с помощью простого скользящего среднего, а затем, с использованием сглаженных уровней тестового участка производится построение прогнозных значений уровней проверочного участка. Данная процедура выполняется для нескольких скользящих средних, имеющих различные интервалы сглаживания. Далее, для каждого простого скользящего среднего по его тестовому участку и тестовому участку исходного ряда производится оценка точности прогнозирования. В качестве наилучшего интервала сглаживания выбирается интервал, соответствующий скользящему среднему, имеющему наибольшую точность.
Для построения простого скользящего среднего находят его значения на каждом уровне. Определение расчетных значений показателя производится с использованием следующей формулы:

С целью построения прогноза, целесообразнее воспользоваться адаптивным простым скользящим средним, значения которого относятся к концу сглаживаемого интервала:

Для построения краткосрочного прогноза с помощью простого скользящего среднего на один временной интервал вперед используют соотношение:
![]()
В данной работе проведено экспериментальное сглаживание уровней эмпирического ряда с использованием 3-х, 5-ти, и 7-уровневого простого скользящего среднего (m=3, m=5, m=7). Результаты сглаживания приведены в Приложении 2.1.
Для оценки точности прогноза используют коэффициент несоответствия Тейла:

Для наших моделей T=30, L=5. В результате расчетов были получены следующие коэффициенты несоответствия:
|
m |
KT |
|
3 |
0.1076 |
|
5 |
0.1251 |
|
7 |
0.1446 |
Наименьшее значение коэффициента несоответствия (более близкое к нулю) имеет 3-уровневый простой скользящий средний. Следовательно, наибольшая точность прогнозирования наблюдается при интервале m=3.
Для построения прогноза на основе простого скользящего среднего, выполняется сглаживание всего исходного ряда с использованием аддитивного скользящего среднего. Результаты сглаживания (m=3) приведены в Приложении 2.2.
Точечный прогноз на основе простого скользящего среднего:
![]()
Интервальный прогноз на основе простого скользящего среднего:
![]()
![]()

![]()
![]()
Метод взвешенного скользящего среднего.
Исходные данные приведены в Приложении 1.
Перед построением прогноза необходимо подобрать длину интервала сглаживания, при котором прогноз будет иметь большую точность. Для этого воспользуемся уже известным способом: разобьем исходный ряд на два участка (тестовый и проверочный). Сначала произведем сглаживание уровней тестового участка с помощью взвешенного скользящего среднего, а затем, с использованием сглаженных уровней тестового участка произведем построение прогнозных значений уровней проверочного участка. Выполним данную процедуру для нескольких взвешенных скользящих средних, имеющих различные интервалы сглаживания. Далее, произведем оценку точности прогнозирования для каждого скользящего среднего по его тестовому участку и тестовому участку исходного ряда.
Определение расчетных значений взвешенного скользящего среднего на каждом уровне производится с использованием следующей формулы:
![]()
Расчет значения весов qi для m=5, m=7, m=9, приведен в Приложении 3.1.а и Приложении 3.1.б.
Для прогнозирования с помощью взвешенного скользящего среднего на один временной интервал используем соотношение:
![]()
В данной работе проведено сглаживание с использованием 5-ти, 7-ми, и 9-уровневого взвешенного скользящего среднего (m=5, m=7, m=9). Результаты сглаживания приведены в Приложении 3.2.
Для оценки точности прогноза используют коэффициент несоответствия Тейла:

Для полученных моделей T=30, L=5. В результате расчетов были получены следующие коэффициенты несоответствия:
|
m |
KT |
|
5 |
0.0945 |
|
7 |
0.1116 |
|
9 |
0.1109 |
Наименьшее значение коэффициента несоответствия (более близкое к нулю) имеет 5-уровневый взвешенный скользящий средний. Следовательно, наибольшая точность прогнозирования наблюдается при интервале m=5.
Для построения прогноза выполняется сглаживание всего исходного ряда с использованием взвешенного скользящего среднего. Результаты сглаживания (m=5) приведены в Приложении 3.3.
Точечный прогноз на основе взвешенного скользящего среднего:
![]()
Интервальный прогноз на основе взвешенного скользящего среднего:
![]()
![]()
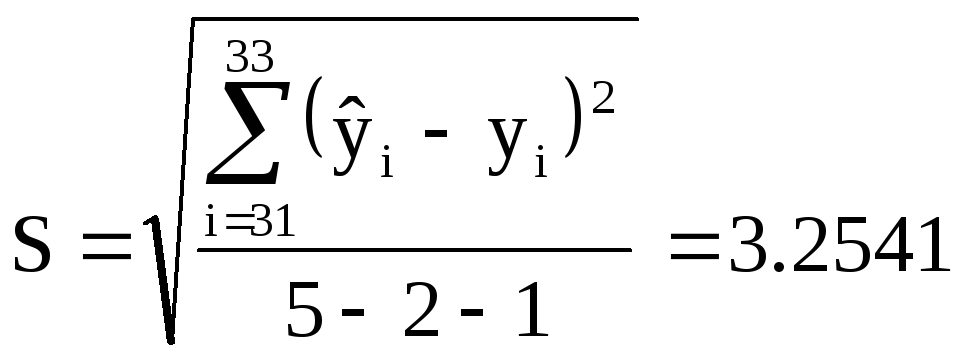
![]()
![]()
Метод экспоненциально взвешенного скользящего среднего.
Исходные данные приведены в Приложении 1.
Для построения прогноза на основе экспоненциально взвешенного скользящего среднего требуется определить значение коэффициента , при котором достигается наибольшая степень точности прогноза. Для этого сначала строим несколько моделей экспоненциально взвешенного скользящего среднего на тестовом участке (уровни исходного ряда с 1 по 32 период), строим с их помощью прогноз на проверочном участке (с 33 по 35 период), далее оцениваем степень точности между полученными значениями и исходными данными и выбираем значение коэффициента , соответствующее модели, имеющей наибольшую точность прогнозирования.
Определение расчетных значений экспоненциально взвешенного скользящего среднего на каждом уровне производится с использованием следующей формулы:
![]()
Для прогнозирования с помощью экспоненциально взвешенного скользящего среднего на один временной интервал используем соотношение:
![]()
В данной работе проведено сглаживание с использованием экспоненциально взвешенного скользящего среднего с параметрами =0.1, =0.3, =0.5, =0.7, =0.9. Результаты сглаживания приведены в Приложении 4.1.
Для оценки точности прогноза используют коэффициент несоответствия Тейла:

Для полученных моделей T=32, L=3. В результате расчетов были получены следующие коэффициенты несоответствия:
|
|
KT |
|
0.1 |
0.0510 |
|
0.3 |
0.0553 |
|
0.5 |
0.0669 |
|
0.7 |
0.1011 |
|
0.9 |
0.2604 |
Наименьшее значение коэффициента несоответствия (более близкое к нулю) имеет экспоненциально взвешенный скользящий средний с параметром =0.1.
Для построения прогноза выполняется сглаживание всего исходного ряда с использованием экспоненциально взвешенного скользящего среднего. Результаты сглаживания приведены в Приложении 4.2.
Точечный прогноз на основе экспоненциально взвешенного скользящего среднего:
![]()
Интервальный прогноз на основе экспоненциально взвешенного скользящего среднего:
![]()
![]()

![]()
![]()
Аналитические методы выделения неслучайнойсоставляющей.
Проверка гипотезы о наличии тенденции.
Исходные данные приведены в Приложении 1.
Проверим, существует ли какая-то тенденция в развитии наблюдаемого явления, или нет. Для этого разобьем исходный ряд на две совокупности и сравним их средние значения в предположении, что выборочные дисперсии различаются незначимо. Определим значимо или незначимо различие между выборочными дисперсиями с помощью критерия Фишера-Снедекора, а между средними значениями с помощью критерия Стьюдента.
F-критерий.
Наблюдаемое значение:

Значение границы правосторонней критической области:

Значение границы левосторонней критической области:

t-критерий.
Наблюдаемое значение:

Значение границ критической области:
![]()
Гипотезу о наличии тенденции в рассматриваемом ряду сформулируем следующим образом: тенденция в развитии явления наблюдается, если различие между значениями выборочных дисперсий двух совокупностей незначимо, а средние значения уровней этих совокупностей различаются значительно.
Проверка вспомогательной гипотезы - о равенстве дисперсий:
Нулевая гипотеза -
![]()
Конкурирующая гипотеза -
![]()
Проверка основной гипотезы - о равенстве средних:
Нулевая гипотеза -
![]()
Конкурирующая гипотеза -
![]()
В данной работе было проведено 32 эксперимента по разбитию исходного ряда на две совокупности (2 и 33; 3 и 32; 4 и 31;…;31 и 4; 32 и 3; 33 и 2). Наблюдаемые значения F-критерия, t-критерия, а так же значения их критических точек даны в Приложении 5.1. Как видно из таблицы Приложения 5.1, при разбиении исходного ряда на два более или менее относительно равные по размеру интервалы (13 и 22; 14 и 21;…; 20 и 15; 21 и 14), вспомогательная гипотеза о незначимом различии между дисперсиями принимается, а основная гипотеза о незначимом различии между средними при этом отвергается. Поэтому можно сделать предположение о наличии тенденции в развитии наблюдаемого явления.
Модель тренда.
Исходные данные приведены в Приложении 1.
Перед построением прогноза с помощью модели тренда, требуется произвести подбор вида модели, дающего наибольшую точность прогноза. Для этого разобьем исходный ряд на два участка: тестовый (уровни исходного ряда с 1 по 30 период) и проверочный (с 31 по 35 период). В процессе исследования сначала производится построение модели тренда для уровней тестового участка, а затем, с ее помощью производится построение прогнозных значений уровней проверочного участка. Данная процедура выполняется для нескольких моделей. Далее, для каждой модели тренда по ее тестовому участку и тестовому участку исходного ряда производится оценка точности прогнозирования.
Воспользуемся следующими видами регрессионных моделей:
1. линейная
![]() ;
;
2. логарифмическая
![]() ;
;
3. полином 2-го порядка
![]() ;
;
4. полином 3-го порядка
![]() ;
;
5. степенная
![]() ;
;
6. экспоненциальная
![]() .
.
Результаты построения вышеперечисленных моделей с помощью ППП SPSS 10.0.05 приведены в Приложении 6.1.
Для оценки точности прогноза используют коэффициент несоответствия Тейла:
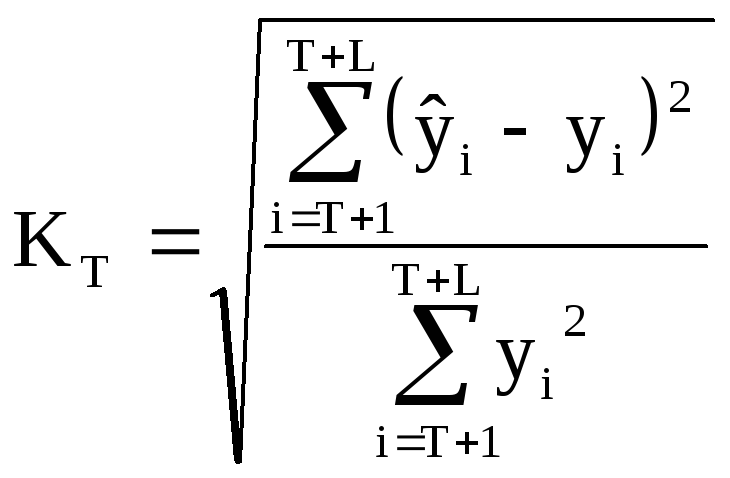
Для наших моделей T=30, L=5. В результате расчетов были получены следующие коэффициенты несоответствия:
|
Модель |
KT |
|
1 |
0.0373 |
|
2 |
0.2242 |
|
3 |
0.0398 |
|
4 |
0.0384 |
|
5 |
0.0491 |
|
6 |
0.6325 |
Наименьшее значение коэффициента несоответствия имеет линейная модель тренда.
Для построения прогноза на основе линейной модели тренда, выполняется построение модели для всего исходного ряда. Результаты моделирования приведены в Приложении 6.2.
Точечный прогноз на основе линейной модели тренда:
![]()
Интервальный прогноз на основе линейной модели тренда:

![]()


![]()
Приложение 1.
Исходные данные.
|
t |
Y |
|
1 |
13,36 |
|
2 |
27,36 |
|
3 |
33,81 |
|
4 |
47,29 |
|
5 |
45,30 |
|
6 |
57,21 |
|
7 |
73,65 |
|
8 |
72,50 |
|
9 |
82,24 |
|
10 |
97,06 |
|
11 |
103,50 |
|
12 |
104,44 |
|
13 |
114,18 |
|
14 |
126,90 |
|
15 |
143,35 |
|
16 |
141,38 |
|
17 |
153,27 |
|
18 |
166,75 |
|
19 |
173,20 |
|
20 |
186,67 |
|
21 |
193,12 |
|
22 |
196,60 |
|
23 |
199,04 |
|
24 |
216,52 |
|
25 |
222,97 |
|
26 |
226,23 |
|
27 |
239,92 |
|
28 |
256,37 |
|
29 |
253,43 |
|
30 |
263,17 |
|
31 |
279,77 |
|
32 |
286,22 |
|
33 |
285,37 |
|
34 |
276,74 |
|
35 |
309,62 |
Приложение 2.1
Сглаживание с помощью простой скользящей средней.
|
Исходный ряд |
Сглаженный ряд |
||||||
|
t |
Y |
m=3 |
m=5 |
m=7 |
|||
|
Y |
Q |
Y |
Q |
Y |
Q |
||
|
1 |
13,36 |
13,36 |
|
13,36 |
|
13,36 |
|
|
2 |
27,36 |
27,36 |
|
27,36 |
|
27,36 |
|
|
3 |
33,81 |
33,81 |
24,84 |
33,81 |
|
33,81 |
|
|
4 |
47,29 |
47,29 |
36,15 |
47,29 |
|
47,29 |
|
|
5 |
45,30 |
45,30 |
42,13 |
45,30 |
33,42 |
45,30 |
|
|
6 |
57,21 |
57,21 |
49,93 |
57,21 |
42,19 |
57,21 |
|
|
7 |
73,65 |
73,65 |
58,72 |
73,65 |
51,45 |
73,65 |
42,57 |
|
8 |
72,50 |
72,50 |
67,79 |
72,50 |
59,19 |
72,50 |
51,02 |
|
9 |
82,24 |
82,24 |
76,13 |
82,24 |
66,18 |
82,24 |
58,86 |
|
10 |
97,06 |
97,06 |
83,93 |
97,06 |
76,53 |
97,06 |
67,89 |
|
11 |
103,50 |
103,50 |
94,27 |
103,50 |
85,79 |
103,50 |
75,92 |
|
12 |
104,44 |
104,44 |
101,67 |
104,44 |
91,95 |
104,44 |
84,37 |
|
13 |
114,18 |
114,18 |
107,37 |
114,18 |
100,28 |
114,18 |
92,51 |
|
14 |
126,90 |
126,90 |
115,17 |
126,90 |
109,22 |
126,90 |
100,12 |
|
15 |
143,35 |
143,35 |
128,14 |
143,35 |
118,47 |
143,35 |
110,24 |
|
16 |
141,38 |
141,38 |
137,21 |
141,38 |
126,05 |
141,38 |
118,69 |
|
17 |
153,27 |
153,27 |
146,00 |
153,27 |
135,82 |
153,27 |
126,72 |
|
18 |
166,75 |
166,75 |
153,80 |
166,75 |
146,33 |
166,75 |
135,75 |
|
19 |
173,20 |
173,20 |
164,41 |
173,20 |
155,59 |
173,20 |
145,58 |
|
20 |
186,67 |
186,67 |
175,54 |
186,67 |
164,25 |
186,67 |
155,93 |
|
21 |
193,12 |
193,12 |
184,33 |
193,12 |
174,60 |
193,12 |
165,39 |
|
22 |
196,60 |
196,60 |
192,13 |
196,60 |
183,27 |
196,60 |
173,00 |
|
23 |
199,04 |
199,04 |
196,25 |
199,04 |
189,73 |
199,04 |
181,24 |
|
24 |
216,52 |
216,52 |
204,05 |
216,52 |
198,39 |
216,52 |
190,27 |
|
25 |
222,97 |
222,97 |
212,84 |
222,97 |
205,65 |
222,97 |
198,30 |
|
26 |
226,23 |
226,23 |
221,91 |
226,23 |
212,27 |
226,23 |
205,88 |
|
27 |
239,92 |
239,92 |
229,71 |
239,92 |
220,94 |
239,92 |
213,49 |
|
28 |
256,37 |
256,37 |
240,84 |
256,37 |
232,40 |
256,37 |
222,52 |
|
29 |
253,43 |
253,43 |
249,91 |
253,43 |
239,78 |
253,43 |
230,64 |
|
30 |
263,17 |
263,17 |
257,66 |
263,17 |
247,82 |
263,17 |
239,80 |
|
31 |
279,77 |
257,66 |
258,09 |
247,82 |
252,14 |
239,80 |
243,13 |
|
32 |
286,22 |
258,09 |
259,64 |
252,14 |
254,59 |
243,13 |
246,01 |
|
33 |
285,37 |
259,64 |
258,46 |
254,59 |
254,23 |
246,01 |
248,83 |
|
34 |
276,74 |
258,46 |
258,73 |
254,23 |
254,39 |
248,83 |
250,11 |
|
35 |
309,62 |
258,73 |
258,94 |
254,39 |
252,64 |
250,11 |
249,21 |