

Ip-адрес
IP-адрес представляет собой четырехбайтовое число, старшие (крайние левые) биты которого определяют класс IP-адреса. Для классов A, B и C четыре байта адреса делятся между идентификатором (номером) сети и идентификатором (номером) узла в сети как это показано на

Сети классов A, B и C абсолютно равноправны и отличаются лишь допустимым количеством узлов в них. Идентификаторы узлов, состоящие из одних нулевых или единичных битов имеют специальный смысл:
IP-адрес с нулевым идентификатором узла используется для обозначения сети в целом;
IP-адрес с идентификатор узла в виде единичных битов является широковещательным (broadcast) адресом.
IP-адреса принято записывать в так называемой "точечной нотации" - в виде последовательности разделенных точками четырех десятичных (или шестнадцатиричных с префиксом 0x) чисел, представляющих значения отдельных байтов.
Каждый узел в сети имеет, по крайней мере, один уникальный IP-адрес.
Кроме классов A, B и C существуют еще два класса IP-адресов - D и E

Класс D используется для организации многопунктового (multicast) режима посылки сообщений: IP-сегмент, посылаемый по по IP-адресу класса D, доставляется всем узлам сети, имеющим указанный идентификатор группы узлов. Описание данного режима дано в RFC 1112.
Примечание. Не все современные реализации протоколов TCP/IP поддерживают многопунктовое вещание.
Для обеспечения гибкости при создании и администрировании сетей различного размера в 1985 г. было введено понятие "подсеть" (RFC 950), позволяющее использовать один и тот же IP-адрес классов A,B или C для разных подсетей.
Такая возможность обеспечивается специальной битовой маской (netmask), ассоциированной с IP-адресом и определяющей распределение битов IP-адреса между идентификатором подсети и идентификатором узла.
Пусть, например, IP-адрес класса C 194.85.36.0 планируется использовать для организации четырех подсетей. Это потребует выделения двух битов из части IP-адреса, относящейся к идентификатору узла. Такое "перепланирование" структуры IP-адреса реализуется сетевой маской 255.255.255.192, где десятичное 192 - это двоичное 11000000.
Эта сетевая маска формирует IP-адрес не из двух, а из трех комронент:
идентификатор сети (24 бита);
идентификатор подсети (2 бита);
идентификатор узла (6 бит).
Примечание. Возможность разбиения сетей на подсети обусловливается, в первую очередь, средствами маршрутизации IP-сегментов, а не средствами IP-модулей, формирующих и обрабатывающих IP-сегменты.
.
Протоколы сетевого взаимодействия TCP/IP. Протокол управления передачей TCP.
Протоколы сетевого взаимодействия TCP/IP являются результатом эволюционного развития протоколов глобальной вычислительной сети ARPANET.
Работы по созданию сети ARPANET были начаты рядом университетов США и фирмой BBN в 1968 г. В 1971 г. сеть была введена в регулярную эксплуатацию и обеспечивала для всех своих узлов три основные услуги:
1.интерактивный вход пользователя на удаленный узел;
2.передача файлов между узлами сети;
3.электронная почта.
Все эти средства базировались на транспортных услугах предоставляемых программой управления сети NCP (Network Control Program), реализующей свой внутренний набор протоколов.
Накопленный к 1974 г. опыт эксплуатации сети ARPANET выявил многие недостатки протоколов NCP и позволил определить основные требования к новому набору протоколов, получившему название TCP/IP:
1. независимость от среды передачи сообщений;
2. возможность подключения к сети ЭВМ любой архитектуры;
3. единый способ организации соединения между узлами в сети;
4. стандартизация прикладных протоколов.
Широко используемая ныне версия 4 протоколов TCP/IP была стандартизирована в 1981 г. в виде документов, называемых RFC (Request For Comment). Полный переход сети ARPANET на новые протоколы был завершен в 1982 г. Эта сеть сыграла роль "зародыша" всемирной сети Internet, построенной на базе протоколов TCP/IP.
Стек протоколов TCP/IP — собирательное название для сетевых протоколов разных уровней, используемых в сетях.
В модели OSI данный стек занимает(реализует) все уровни и делится сам на 4 уровня: прикладной, транспортный, межсетевой, уровень доступа к сети. На стеке протоколов TCP/IP построено все взаимодействие пользователей в сети от программной оболочки до канального уровня модели OSI. По сути база, на которой завязано все взаимодействие. При этом стек независим от физической среды передачи данных.
Уровни стека TCP/IP
Существуют разногласия в том, как вписать модель TCP/IP в модель OSI, поскольку уровни в этих моделях не совпадают.
К тому же, модель OSI не использует дополнительный уровень — «Internetworking» — между транспортным и сетевым уровнями. Примером спорного протокола может быть ARP или STP.
Вот как традиционно протоколы TCP/IP вписываются в модель OSI:
7 Прикладной напр. HTTP, SMTP, SNMP, FTP, Telnet, scp, NFS
6 Представительный напр. XML SMB,
5 Сеансовый напр. SSH, RPC, NetBIOS
4 Транспортный напр. TCP, UDP
3 Сетевой напр. IP, ICMP, IGMP, X.25 ARP, IPX
2 Канальный напр. Ethernet, Token ring, PPP, ISDN, ATM, MPLS
1 Физический напр. электричество, радио, лазер
Физический уровень
Физический уровень описывает среду передачи данных (будь то кабель, оптоволокно или радиоканал), физические характеристики такой среды и принцип передачи данных (разделение каналов, модуляцию, амплитуду сигналов, частоту сигналов, способ синхронизации передачи, время ожидания ответа и максимальное расстояние).
Канальный уровень
Канальный уровень описывает, каким образом передаются пакеты данных через физический уровень, включая кодирование (т.е. специальные последовательности битов, определяющих начало и конец пакета данных). Ethernet, например, в полях заголовка пакета содержит указание того, какой машине или машинам в сети предназначен этот пакет.
Сетевой уровень
Изначально разработан для передачи данных из одной (под)сети в другую. Примерами такого протокола является X.25 и IPC в сети ARPANET. С развитием концепции глобальной сети в уровень были внесены дополнительные возможности по передаче из любой сети в любую сеть, независимо от протоколов нижнего уровня, а также возможность запрашивать данные от удалённой стороны, например в протоколе ICMP (используется для передачи диагностической информации IP-соединения) и IGMP (используется для управления multicast-потоками).
ICMP и IGMP расположены над IP и должны попасть на следующий — транспортный — уровень, но функционально являются протоколами сетевого уровня, а поэтому их невозможно вписать в модель OSI.
Транспортный уровень
Протоколы транспортного уровня могут решать проблему негарантированной доставки сообщений («дошло ли сообщение до адресата?»), а также гарантировать правильную последовательность прихода данных. В стеке TCP/IP транспортные протоколы определяют для какого именно приложения предназначены эти данные.
TCP (IP идентификатор 6) — «гарантированный» транспортный механизм с предварительным установлением соединения, предоставляющий приложению надёжный поток данных, дающий уверенность в безошибочности получаемых данных, перезапрашивающий данные в случае потери и устраняющий дублирование данных. TCP позволяет регулировать нагрузку на сеть, а также уменьшать время ожидания данных при передаче на большие расстояния. Более того, TCP гарантирует, что полученные данные были отправлены точно в такой же последовательности. В этом его главное отличие от UDP.
UDP (IP идентификатор 17) протокол передачи датаграмм без установления соединения. Также его называют протоколом «ненадёжной» передачи, в смысле невозможности удостовериться в доставке сообщения адресату, а также возможного перемешивания пакетов. В приложениях, требующих гарантированной передачи данных, используется протокол TCP.
UDP обычно используется в таких приложениях, как потоковое видео и компьютерные игры, где допускается потеря пакетов, а повторный запрос затруднён или не оправдан, либо в приложениях вида запрос-ответ (например, запросы к DNS), где создание соединения занимает больше ресурсов, чем повторная отправка.
И TCP, и UDP используют для определения протокола верхнего уровня число, называемое портом. Существует список стандартных портов TCP и UDP.
Прикладной уровень
На прикладном уровне работает большинство сетевых приложений.
Эти программы имеют свои собственные протоколы обмена информацией, например, HTTP для WWW, FTP (передача файлов), SMTP (электронная почта), SSH (безопасное соединение с удалённой машиной), DNS (преобразование символьных имён в IP-адреса) и многие другие.
Протокол управления передачей TCP (Transmission Control Protocol) является протоколом транспортного уровня и базируется на возможностях, предоставляемых межсетевым протоколом IP. Основная задача TCP - обеспечение надежной передачи данных в сети. Его транспортный адрес в заголовке IP-сегмента равен 6. Описание протокола TCP дано в RFC 793.
Его основные характеристики перечислены ниже:
- реализует взаимодействие в режиме с установлением логического (виртуального) соединения;
- обеспечивает двунаправленную дуплексную связь;
- организует потоковый (с точки зрения пользователя) тип передачи данных;
- дает возможность пересылки части данных, как "экстренных";
- для идентификации партнеров по взаимодействию на транспортном уровне использует 16-битовые "номера портов";
- реализует принцип "скользящего окна" (sliding window) для повышения скорости передачи;
- поддерживает ряд механизмов для обеспечения надежной передачи данных.
Несмотря на то, что для пользователя передача данных с использованием протокола TCP выглядит как потоковая, на самом же деле обмен между партнерами осуществляется посредством пакетов данных, которые мы будем называть "TCP-пакетами".
Заголовок TCP-пакета

Порт источника и порт приемника
16-битовые поля, содержащие номера портов, соответственно, источника и адресата TCP-пакета. Подробное описание понятия "номер порта" дано в "Номер порта".
Номер в последовательности (sequence number)
32-битовое поле, содержимое которого определяет (косвенно) положение данных TCP-пакета внутри исходящего потока данных, существующего в рамках текущего логического соединения.
В момент установления логического соединения каждый из двух партнеров генерирует свой начальный "номер в последовательности", основное требование к которому - не повторяться в промежутке времени, в течение которого TCP-пакет может находиться в сети (по сути, это время жизни IP-сегмента). Партнеры обмениваются этими начальными номерами и подтверждают их получение. Во время отправления TCP-пакетов с данными поле "номер в последовательности" содержит сумму начального номера и количества байт ранее переданных данных.
Номер подтверждения (acknowledgement number)
32-битовое поле, содержимое которого определяет (косвенно) количество принятых данных из входящего потока к TCP-модулю, формирующему TCP-пакет.
Смещение данных
четырехбитовое поле, содержащее длину заголовка TCP-пакета в 32-битовых словах и используемое для определения начала расположения данных в TCP-пакете.
Флаг URG
бит, установленное в 1 значение которого означает, что TCP-пакет содержит важные (urgent) данные. Подробно о данных этого типа сказано в "Важные данные".
Флаг ACK
бит, установленное в 1 значение которого означает, что TCP-пакет содержит в поле "номер подтверждения" верные данные.
Флаг PSH
бит, установленное в 1 значение которого означает, что данные содержащиеся в TCP-пакете должны быть немедленно переданы прикладной программе, для которой они адресованы. Подтверждение для TCP-пакета, содержащего единичное значение во флаге PSH, означает, что и все предыдущие TCP-пакеты достигли адресата.
Флаг RST
бит, установливаемый в 1 в TCP-пакете, отправляемом в ответ на получение неверного TCP-пакета. Также может означать запрос на переустановление логического соединения.
Флаг SYN
бит, установленное в 1 значение которого означает, что TCP-пакет представляет собой запрос на установление логического соединения. Получение пакета с установленым флагом SYN должно быть подтверждено принимающей стороной.
Флаг FIN
бит, установленное в 1 значение которого означает, что TCP-пакет представляет собой запрос на закрытие логического соединения и является признаком конца потока данных, передаваемых в этом направлении. Получение пакета с установленым флагом FIN должно быть подтверждено принимающей стороной.
Размер окна
16-битовое поле, содержащее количество байт информации, которое может принять в свои внутренние буфера TCP-модуль, отправляющий партнеру данный TCP-пакет. Данное поле используется принимающим поток данных TCP-модулем для управления интенсивностью этого потока: так, установив значение поля в 0, можно полностью остановить передачу данных, которая будет возобновлена только, когда размер окна примет достаточно большое значение. Максимальный размер окна зависит от реализации, в некоторых реализациях максимальный размер может устанавливаться системным администратором (типичное значение максимального размера окна - 4096 байт). Определение оптимального размера окна - одна из наиболее сложных задач реализации протокола TCP (см. "Исключение малых окон").
Контрольная сумма
16-битовое поле, содержащее Internet-контрольную сумму, подсчитанную для TCP-заголовка, данных пакета и псевдозаголовка. Псевдозаголовок включает в себя ряд полей IP-заголовка и имеет показанную структуру.

Указатель
16-битовое поле, содержащее указатель (в виде смещения) на первый байт в теле TCP-пакета, начинающий последовательность важных (urgent) данных. Данные этого типа и механизм их обработки описаны в "Важные данные".
Дополнительные данные заголовка
последовательность полей произвольной длины, описывающих необязательные данные заголовка. Протокол TCP определяет только три типа дополнительных данных заголовка:
конец списка полей дополнительных данных;
пусто (No Operation);
максимальный размер пакета.
Дополнительные данные последнего типа посылаются в TCP-заголовке в момент установления логического соединения для выражения готовности TCP-модулем принимать пакеты длиннее 536 байтов. В UNIX-реализациях длина пакета обычно определяется максимальной длиной IP-сегмента для сети.
Номер порта
Номера портов играют роль адресов транспортного уровня, идентифицируя на конкретных узлах сети, по сути дела, потребителей транспортных услуг, предоставляемых как протоколом TCP, так и протоколом UDP. При этом протоколы TCP и UDP имеют свои собственные адресные пространства: например, порт номер 513 для TCP не идентичен порту номер 513 для UDP.
Примечание. Своя собственная адресация на транспортном уровне стека протоколов сетевого взаимодействия необходима для обеспечения возможности функционирования на узле сети одновременно многих сетевых приложений. Наличие в TCP-заголовке номера порта позволяет TCP-модулю, получающему последовательности TCP-пакетов, формировать раздельные потоки данных к прикладным программам.
Взаимодействие прикладных программ, использующих транспортные услуги протокола TCP (или UDP), строится согласно модели "клиент-сервер", которая подразумевает, что одна программа (сервер) всегда пассивно ожидает обращения к ней другой программы (клиента). Связь программы-клиента и сервера идентифицируется пятеркой:
используемый транспортный протокол (TCP или UDP);
IP-адрес сервера;
номер порта сервера;
IP-адрес клиента;
номер порта клиента.
Для того, чтобы клиент мог обращаться к необходимому ему серверу, он должен знать номер порта, по которому сервер ожидает обращения к нему ("слушает сеть"). Для прикладных программ, получивших наибольшее распространение в сетях на основе TCP/IP, номера портов фиксированы и носят название "хорошо известных номеров портов" (well-known port numbers). В UNIX-системах такие номера портов содержатся в файле /etc/services. Ниже приводятся примеры хорошо известных номеров портов для некоторых серверов (служб).
Примечание. Обратите внимание, что некоторые серверы (такие, например, как для службы portmap с номером порта 111) могут работать как по протоколу TCP, так и по протоколу UDP.
Программы-клиенты, являющиеся активной стороной во взаимодействии "клиент-сервер", могут использовать, как правило, произвольные номера портов, назначаемые динамически непосредственно перед обращением к серверу (как любые свободные на данном узле).
Примечание. Любая прикладная программа (будь то клиент или сервер) может открывать для взаимодействия любое количество портов для использования любых транспортных протоколов.
Средства разработки сетевых приложений на базе транспортных протоколов TCP и UDP описаны в "Сетевое программирование".
Принцип "скользящего окна"
Протоколы транспортного уровня, обеспечивающие надежную передачу данных, предполагают обязательное подтверждение принимающей стороной правильности полученных данных.
В "простых" протоколах сторона, отправляющая данные, отсылает пакет с данными принимающей стороне и переходит в состояние ожидания подтверждения получения правильных данных. Только после приема подтверждения становится возможной следующая посылка. Очевидно, что такой подход использует пропускную способность сети неэффективно.
В протоколе TCP используется более совершенный принцип "скользящего окна" (sliding window), который заключается в том, что каждая сторона может отправлять партнеру максимум столько байт, сколько партнер указал в поле "размер окна" заголовка TCP-пакета, подтверждающего получение предыдущих данных.
Принцип "скользящего окна" обеспечивает "опережающую" посылку данных с "отложенным" их подтверждением. Следует отметить недостаток этого механизма: если в течение некоторого времени не будет получено "отсроченное" подтверждение ранее отправленного пакета, то отправляющий TCP-модуль будет вынужден повторить посылку всех TCP-пакетов, начиная с неподтвержденного.
Размер окна, как правило, определяется объемом свободного места в буферах принимающего TCP-модуля.
Этапы TCP-взаимодействия
Взаимодействие партнеров с использованием протокола TCP строится в три этапа:
установление логического соединения;
обмен данными;
закрытие соединения.
Ниже с помощью трех рисунков дается описание каждого из этапов. Рисунки иллюстрируют последовательность обмена TCP-пакетами двумя TCP-модулями: A и B. TCP-пакеты представлены тремя полями TCP-заголовка ("Номер в последовательности", "Номер подтверждения", "Флаги") и числом, характеризующим длину данных, составляющих тело TCP-пакета (заметим, что реально поля длины данных в TCP-заголовке нет). Стрелками показаны направления пересылки пакетов.

Рис. иллюстрирует этап установления соединения, реализуемый как "трехшаговое рукопожатие" (three-way handshake). На первом шаге TCP-модуль A, играя роль клиента, посылает TCP-модулю B пакет с установленным флагом SYN и начальным значением номера в последовательности равным 1000. TCP-модуль B, будучи готов со своей стороны установить соединение, отвечает TCP-пакетом, подтверждающим правильный прием запроса (поле "Номер подтверждения" на 1 больше начального номера в последовательности для TCP-модуля A и среди флагов есть установленный в 1 флаг ACK) и информирующим о готовности установить соединение (взведен флаг SYN и установлен в 5000 начальный номер в последовательности). На третьем шаге TCP-модуль A подтверждает правильность приема TCP-пакета от B.
Примечание. Некоторые протоколы транспортного уровня (но не TCP) допускают обмен данными уже на этапе установления логического соединения.

Рис. иллюстрирует этап двустороннего обмена данными между TCP-модулями A и B. TCP-модуль, принимающий адресованные ему данные, всегда подтверждает их прием, вычисляя значение поля "Номер подтверждения" в заголовке ответного TCP-пакета как сумму пришедшего "Номера в последовательности" и длины правильно принятых данных. Отметим, что посылка данных к партнеру и подтверждение принятых от него данных реализуются в рамках одного TCP-пакета.
Библиотека libpcap. Архитектура и основные концепции.
Архитектура BPF и UNIX
BPF, или Berkley Packet Filter (пакетный фильтр Беркли), описанный Стивеном МакКейном и Ван Якобсоном (McCane and Jacobson 1993) – это архитектура ядра для захвата пакетов, созданная для работы с ядрами ОС UNIX.
BPF представляет собой драйвер устройства, который может использоваться приложениями ОС UNIX для передачи и приема пакетов, передаваемых по сети, напрямую через сетевой интерфейс (сетевой адаптер, модем) высокоэффективным методом. С другой стороны, BPF – не совсем обычный драйвер, поскольку он не управляет сетевым адаптером, а взаимодействует с его драйвером.
BPF состоит из двух основных элементов: сетевая ловушка (network tap) и пакетный фильтр (packet filter). Сетевая ловушка – это петлевая функция, являющаяся частью кода BPF, однако не вызываемая самим BPF. Ее вызывает драйвер сетевого адаптера, когда принимает очередной входящий пакет. Драйвер адаптера должен вызывать сетевую ловушку для каждого поступившего пакета, в противном случае BPF не будет нормально работать с этим адаптером. Сетевая ловушка копирует поступившие пакеты и передает их копии приложению верхнего уровня, каковым для нее является пакетный фильтр.
Пакетный фильтр – это заданная пользователем функция с бинарным результатом, устанавливаемым относительно входящего пакета. Если значение функции TRUE, ядро передает копию входящего пакета приложению верхнего уровня , если FALSE – входящий пакет игнорируется. Практически все приложения, использующие BPF, подавляют большинство входящих пакетов, поэтому производительность фильтра определяет производительность приложения.
Пакетный фильтр BPF определяет не только необходимость приема пакета, но и количество байт входящего пакета, необходимых приложению (например, приложение может обрабатывать только заголовки пакета, если в данных нет необходимости). Это существенно ускоряет процесс фильтрации и значительно снижает потери, поскольку для сохранения меньшего объема данных меньше места задействуется в буфере драйвера.
На рис.1 показано взаимодействие BPF с операционной системой.
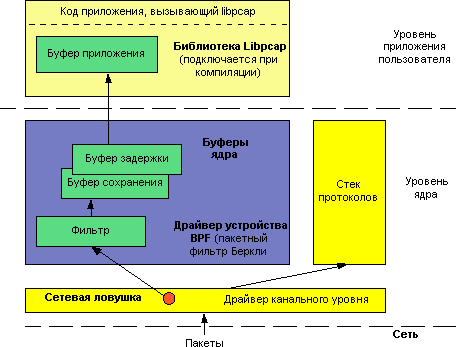
BPF назначает фильтр и два буфера на каждый процесс, запросивший его функции. Фильтр создается приложением и передается в BPF путем вызова функций IOCTL. Оба буфера постоянно размещены в BPF, и их размер составляет обычно 4 кБ. Первый буфер (store buffer – буфер сохранения) используется для приема данных от адаптера, второй (hold buffer – буфер задержки) используется для копирования пакетов для приложений. Если буфер сохранения заполнен, а буфер задержки пуст, BPF меняет их местами.
Когда очередной пакет поступает на вход сетевого интерфейса, драйвер устройства канального уровня в обычном режиме передает его системному стеку протоколов. Однако если BPF «прослушивает» сетевой интерфейс, драйвер сначала вызывает функцию сетевой ловушки.
Ловушка передает входящий пакет каждому из созданных фильтров. Заданный приложением фильтр определяет необходимость приема пакета и количество байт сохраняемого пакета. Заметим, что фильтр воздействует на пакеты, пока они находятся в памяти драйвера канального уровня до его копирования.
Если фильтр принимает пакет, ловушка копирует заданное фильтром число байт из памяти драйвера в буфер сохранения, связанный с этим фильтром. После этого драйвер сетевого интерфейса вновь получает управление и происходит нормальная обработка пакета в стеке протоколов операционной системы.
Входящий пакет игнорируется фильтром также в том случае, если буфер сохранения заполнен, а буфер задержки недоступен (т.е. приложение считывает из него данные).
Приложение взаимодействует с драйвером BPF при помощи библиотеки захвата пакетов, называемой libpcap (packet capture library). Для получения принятых пакетов из буфера задержки приложение вызывает системную функцию считывания. Если буфер задержки заполнен (или истекло время ожидания), BPF копирует содержимое буфера в память приложения и передает ему управление. Приложение способно принять более одного пакета за один раз. Для выделения границ блоков принятых данных BPF снабжает их заголовком, содержащим время приема и размер блока, а также концевиком для синхронизации блоков данных.
Архитектура PCAP
Заметим, что не все версии UNIX имеют в своем составе BPF (т.е. возможности фильтрации и буферизации в ядре операционной системы), однако архитектура PCAP (Packet Capture – захват пакетов) может компенсировать этот недостаток. Данная архитектура полностью совместима с архитектурой BPF и позволяет фильтровать пакеты аналогично BPF, но на уровне пользователя.
Программная реализация архитектуры PCAP была выполнена в виде NDIS-драйвера. NDIS (Network Driver Interface Specification – спецификация интерфейса сетевого драйвера) – это набор спецификаций, описывающих организацию обмена данными сетевым адаптером (точнее, драйвером, управляющим им) и драйверами протоколов (IP, IPX и т.д.). Основное назначение NDIS состоит в том, чтобы предоставить возможность драйверу протоколов принимать и передавать пакеты по сети (локальной или глобальной) не зависимо от того, какая версия ОС используется.
NDIS-драйвер имеeт некоторые отличия от BPF. Во-первых, процесс фильтрации проходит на уровне пользователя, поэтому каждый входящий пакет должен быть скопирован из ядра в буфер приложения до его фильтрации. При этом происходит потеря процессорного времени и оперативной памяти, поскольку в память приложения копируются все пакеты, в том числе те, которые не нужны данному приложению.
Во-вторых, в ядре ОС отсутствует буферизация пакетов. В многозадачных операционных системах приложение вынуждено делить процессорное время с другими программами. Возможна ситуация, когда приложение не будет активно в момент прихода очередного пакета. Кроме того, приложение может быть занято выполнением других задач и не ждать входящий пакет. При отсутствии буфера в ядре ОС возникновение этих ситуаций приведет к потере пакета.
Существование этих недостатков привело к тому, что фильтрацию и буферизацию задает и выполняет драйвер захвата пакетов (packet capture driver), а не приложение. Заметим, что управление драйвером осуществляется при помощи все той же библиотеки libpcap, а это обеспечивает программную совместимость двух архитектур.
Основная концепция архитектуры WinPCAP
Архитектура WinPCAP дополняет стандартные функции операционных систем семейства Win32 возможностью принимать и передавать данные по сети, минуя стек протоколов операционной системы и взаимодействуя непосредственно с сетевым адаптером компьютера. Более того, она предоставляет приложениям API высокого уровня для управления низкоуровневыми процессами. WinPCAP состоит из трех компонентов: драйвер устройства захвата пакетов (paсket.vxd), низкоуровневая динамическая библиотека (packet.dll) и статическая библиотека высокого уровня (libpcap).
Данная архитектура может быть использована как для создания программ обработки пакетов для ОС Windows, так и для переноса аналогичных программ, написанных для ОС UNIX, и полностью совместима с архитектурой BPF – libpcap.
Структура стека захвата пакетов
Для перехвата пакетов, передаваемых по сети, приложению необходимо взаимодействовать непосредственно с сетевым оборудованием. По этой причине операционная система должна предоставлять несколько примитивных функций для приема и передачи данных непосредственно через сетевой адаптер. Назначение этих функций состоит в том, чтобы принять входящий пакет и передать его в стек протоколов операционной системы для дальнейшей обработки. Приложение получает пакет без заголовков канального, сетевого и транспортного уровней, интерпретирует и обрабатывает его и предоставляет в удобном для пользователя виде.
На рис. 2 приведена структура стека захвата пакетов от сетевого адаптера до приложения верхнего уровня.
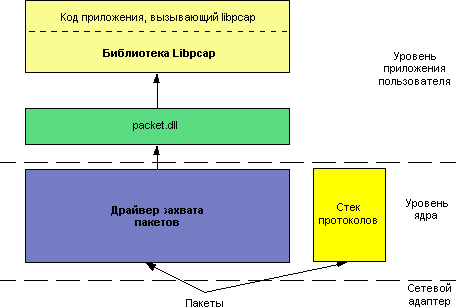
На нижнем уровне находится сетевой адаптер, принимающий все пакеты, передаваемые по сети. Драйвер захвата пакетов (pcap-драйвер) packet.vxd является программным модулем низкого уровня. Он работает на уровне ядра ОС и взаимодействует непосредственно с драйвером сетевого адаптера. Pcap-драйвер предоставляет набор функций низкого уровня, обеспечивающих прием и передачу данных на канальном уровне через NDIS, который является частью сетевой подсистемы Win32. NDIS отвечает за управление различными типами адаптеров и обеспечивает связь адаптера с программным обеспечением, отвечающим за формирование пакетов различной структуры.
Динамическая библиотека packet.dll «изолирует» программу пользователя от драйвера и предоставляет приложению независимый от вида ОС (семейства Win32) интерфейс. Это позволяет приложению работать на различных Windows-платформах без перекомпиляции. Библиотека packet.dll работает на уровне пользователя, но отдельно от приложения.
Статическая библиотека libpcap используется частью программы пользователя, обеспечивающей перехват и фильтрацию пакетов. Она задействует функции, предоставляемые библиотекой packet.dll, и обеспечивает программе пользователя управление процессами приема и фильтрации данных на высоком уровне. Библиотека libpcap статически связана с программой пользователя и является ее частью.
Программа пользователя – высший уровень структуры стека захвата пакетов. Она обеспечивает обработку принятых пакетов и отображение результатов в удобном для пользователя виде.
Взаимодействие с NDIS
NDIS поддерживает три типа сетевых драйверов:
1. Драйверы сетевых карт (NIC – Network Interface Card) – низший уровень сетевой подсистемы.
2. Промежуточные драйверы – обеспечивают взаимодействие драйверов верхнего уровня (например, драйверов протоколов) с драйверами NIC.
3. Драйверы транспортного уровня (драйверы протоколов) – обеспечивают прием и передачу данных приложения верхнего уровня, используя стек стандартных сетевых протоколов (например, TCP/IP).
Общий вид структуры NDIS с двумя стеками захвата пакетов, привязанных к одному сетевому адаптеру, представлен на рис. 3. Один из них состоит из драйвера NIC и драйвера протокола, другой – из драйвера NIC, промежуточного драйвера и драйвера протокола.

Рисунок 3: структура NDIS
Для нормальной работы драйверу захвата пакетов необходимо взаимодействовать как с драйвером сетевого устройства (для передачи и приема данных), так и с приложением пользователя (для получения от него данных или передачи ему принятых от сетевого устройства пакетов). Поэтому драйвер захвата пакетов разработан как драйвер протокола в структуре NDIS
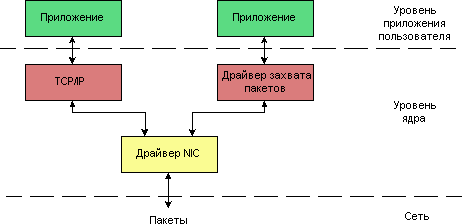
Рисунок 4: положение драйвера захвата пакетов в структуре NDIS
Это позволяет ему работать со всеми сетевыми устройствами, поддерживаемыми ОС Windows (адаптерами Ethernet и т. д.). Тем не менее, на данный момент драйвер работает только с адаптерами Ethernet, loopback-адаптерами и поддерживает подключение к глобальной сети через Ethernet-адаптер. Пакет протоколов PPP NCP-LCP «прозрачен» для драйверов протоколов, поскольку PPP-соединения устанавливаются виртуально. Поэтому драйвер захвата пакетов не может работать с такого рода соединениями.
Основные функции библиотеки libpcap.
· PCAP_T pcap_open_live (char *device, int snaplen, boolean promisc, int to_ms, char *ebuf)
Функция предназначена для получения дескриптора структуры захвата пакетов, используемой для записи и просмотра пакетов, передаваемых по сети (режим он-лайн). Device – это строка, задающая открываемый сетевой адаптер. Переменная Snaplen задает максимальное число захватываемых байт. Флаг Promisc переводит адаптер в режим работы “прием всех входящих пакетов”. Переменная to_ms содержит время ожидания пакета в миллисекундах. При возникновении ошибки функция возвращает значение NULL и записывает строку, характеризующую ошибку, в буфер ebuf.
· PCAP_T pcap_open_offline (char *fname, char *ebuf)
Функция предназначена для получения дескриптора структуры захвата пакетов, используемой для записи и просмотра пакетов, сохраненных в файле (режим офф-лайн). Имя файла указывается в переменной fname. Если в качестве имени файла указан символ ‘-‘, информация будет считываться из устройства, определяемого системной переменной stdin.
· PCAP_DUMPER_T pcap_dump_open (pcap_t *p, char *fname)
Функция открывает файл, имя которого указано в переменной fname, для записи всех принятых пакетов (дампа). Имя файла ‘-‘ означает запись в stdout. Переменная p – это указатель на дескриптор структуры pcap, полученный при помощи функции pcap_open_live(). Функция возвращает дескриптор открытого для записи файла. При возникновении ошибки функция возвращает значение NULL, при этом описание ошибки может быть получено при помощи pcap_geterr().
· CHAR pcap_lookupdev (char *errbuf)
Функция возвращает указатель на сетевое устройство, которое возможно использовать совместно с pcap_open_live() и pcap_lookupnet().
· INT pcap_lookupnet (char *device, bpf_u_int32 *netp, bpf_u_int32 *maskp, char *ebuff)
Функция используется для определения сетевого адреса и сетевой маски устройства, заданного в переменной device. Эти данные записываются соответственно в переменные netp и maskp. При возникновении ошибки функция возвращает значение “–1”.
· INT pcap_dispatch (pcap_t *p, int cnt, pcap_handler callback, u_char *user)
Функция используется для сбора и обработки принятых пакетов. Аргумент cnt задает максимальное число принимаемых и обрабатываемых пакетов за один сеанс работы подпрограммы. Значение cnt = -1 означает, обрабатываются все пакеты, принятые одним буфером. Значение cnt = 0 означает обработку всех пакетов до возникновения ошибки, достижения конца файла (при работе в режиме офф-лайн) или до окончания времени ожидания пакета (при приеме пакетов из сети и ненулевом значении to_ms). Переменная callback задает подпрограмму, вызываемую с тремя аргументами: указатель u_char user, передаваемый функцией pcap_dispatch(), указатель на структуру pcap_pkthdr, содержащую сетевые заголовки и данные принятых пакетов, и указатель u_char на данные этих пакетов. Функция возвращает число считанных пакетов. При достижении конца файла функция возвращает нулевое значение, значение функции “–1” означает возникновение ошибки. В последнем случае описание ошибки может быть получено при помощи функций pcap_geterr() или pcap_perr().
· VOID pcap_dump (u_char *user, struct pcap_pkthdr *h, u_char *sp)
Функция записывает принятые пакеты в файл, открытый функцией pcap_dump_open(). Аргументы функции позволяют использовать ее совместно с pcap_dispatch(). Формат записываемых в файл данных аналогичен формату программы TCPDUMP и ее аналога WinDump, включенной в состав дистрибутива WinPCap (см. руководство пользователя по данной программе).
· INT pcap_compile (pcap_t *p, struct bpf_program *fp, char *str, int optimize, bpf_u_int32 *netmask)
Функция компилирует текстовое описание фильтра str в псевдокод (см. далее). Переменная fp содержит указатель на структуру bpf_program и заполняется функцией pcap_compile(). Переменная optimize определяет наличие оптимизации псевдокода компилируемой программы. Переменная netmask задает сетевую маску локальной сети.
· INT pcap_setfilter (pcap_t *p, struct bpf_program *fp)
Функция устанавливает программу фильтра для вызвавшего ее приложения. Переменная fp содержит указатель на программу фильтра, полученный при вызове функции pcap_compile().
· INT pcap_loop (pcap_t *p, int cnt, pcap_handler callback, u_char *user)
Действия данной функции аналогичны pcap_dispatch(), за тем исключением, что она считывает пакеты до тех пор, пока не обнулится счетчик cnt или не возникнет ошибка, и не прекращает работы при окончании времени ожидания. Отрицательное значение cnt заставит функцию работать бесконечно, до возникновения первой ошибки.
· U_CHAR pcap_next (pcap_t *p, struct bpf_program *fp)
Функция возвращает указатель на следующий принятый пакет.
· INT pcap_datalink (pcap_t *p)
Функция возвращает имя устройства сетевого уровня, например DLT_EN10MB.
· INT pcap_snapshot (pcap_t *p)
Функция используется для получения «снимка», т.е. для захвата определенного количества пакетов. Длина «снимка» указывается при вызове функции pcap_open_live.
· INT pcap_is_swapped (pcap_t *p)
Функция возвращает значение TRUE, если открытый для записи файл имеет порядок байт, не совпадающий с используемым в операционной системе.
· INT pcap_major_version (pcap_t *p)
Функция возвращает старшее число номера версии PCAP, записываемого в файл.
· INT pcap_minor_version (pcap_t *p)
Функция возвращает младшее число номера версии PCAP, записываемого в файл.
· FILE *pcap_file (pcap_t *p)
Функция возвращает имя открытого для записи файла.
· INT pcap_stats (pcap_t *p, struct pcap_stat *ps)
Функция возвращает 0 и заполняет структуру pcap_stat значениями, которые несут различную статистическую информацию о входящих пакетах с момента запуска процесса до момента вызова этой функции. При возникновении какой-либо ошибки, а также в случае, когда используемый драйвер не поддерживает статистический режим, функция возвращает значение “–1”. При этом код описание ошибки можно получить с помощью функций pcap_perror() или pcap_geterr().
· INT pcap_fileno (pcap_t *p)
Функция возвращает дескриптор открытого для записи файла.
· VOID pcap_perror (pcap_t *p, char *prefix)
Функция выводит текст последней возникшей ошибки библиотеки PCAP на устройстве stderr с префиксом, определяемым переменной prefix.
· CHAR *pcap_geterr (pcap_t *p)
Функция возвращает строку с описанием последней ошибки библиотеки PCAP.
· CHAR *pcap_strerror (int error)
Функция используется в том случае, когда strerror по каким-либо причинам недоступно.
· VOID pcap_close (pcap_t *p)
Функция закрывает файл, связанный с адаптером p, и высвобождает занимаемые библиотекой ресурсы.
· VOID pcap_dump_close (pcap_dumper_t *p)
Функция закрывает открытый для записи файл.
Функции, присутствующие только в версии для WIN32
· INT pcap_setbuff (pcap_t *p, int dim)
Функция устанавливает размер буфера задержки и буфера сохранения, связанных с адаптером p, равным значению, указанному в переменной dim. При этом оба старых буфера уничтожаются, и информация в них теряется. В случае успешного выполнения операции функция возвращает значение “0”, иначе “–1”. Первоначально оба буфера создаются при вызове функции pcap_open_live(), по умолчанию размер буфера задержки и буфера сохранения равен 1 Мб.
· INT pcap_setmode (pcap_t *p, int mode)
Функция устанавливает режим работы адаптера p в соответствии с заданным в переменной mode. Допустимые значения переменной mode – это “0” (режим захвата пакетов) и “1” (статистический режим). Если адаптер находится в статистическом режиме, сетевая ловушка, заданная при помощи функций pcap_dispatch() или pcap_loop(), вызывается драйвером каждые to_ms миллисекунд (параметр задается при вызове функции pcap_open_live()) и передает библиотеке два 64-битных числа, содержащих число пакетов и полное количество байт, удовлетворяющих условиям фильтра.
Способы задания параметров фильтра
Для создания фильтра, необходимо составить его текстовое описание и затем использовать текстовую строку с параметрами фильтра в качестве одного из аргументов функции pcap_compile(). Текстовое описание фильтра обусловливается правилами, принятыми для описания фильтра в программе TCPDUMP и ее Win32-версии WinDUMP, включенную в состав дистрибутива WinPCap. Рассмотрим способы задания программы-фильтра.
В текстовом виде фильтр выглядит как выражение, состоящее из одного или нескольких примитивов. Примитивы в выражении определяют возможность приема фильтром входящего пакета. Каждый примитив определяет конкретный элемент пакета протокола стандартной структуры и его значение, сравниваемое фильтром со значением соответствующего элемента входящего пакета. Если значение примитива совпадает со значением элемента пакета, фильтр отмечает его как «логическую истину» (True) и переходит к сравнению следующего примитива. При совпадении всех значений выражения со значениями проверенных элементов пакета фильтр принимает решение о приеме данного пакета, в противном случае входящий пакет игнорируется.
Каждый примитив обычно состоит из одного или нескольких квалификаторов и следующего за ними идентификатора (имя или число). Всего имеется три типа квалификаторов:
type определяет тип имени или номера идентификатора. Возможные значения: host (хост), net (сеть), port (порт) или proto (протокол). Например: ‘host foo’, ‘net 128.3’, ‘port 20’. Если квалификатор отсутствует, по умолчанию принимается host.
dir определяет возможное направление приема и передачи данных объектом, указанным в качестве идентификатора: к нему и/или от него. Допускается указание следующих значений: src (источник), dst (приемник), src and dst (источник и приемник), src or dst (источник или приемник). Например: ‘src host foo’, ‘dst net 128.3’, ‘src or dst port ftp-data’. Если квалификатор не указан, по умолчанию принимается src or dst.
proto определяет тип протокола, используемого объектом, указанным в качестве идентификатора. Возможные значения: ether, fddi, ip, arp, rarp, decnet, lat, sca, moprc, mopdl, tcp и udp. Например: ‘ether src foo’, ‘arp net 128.3’, ‘tcp port 21’. При отсутствии квалификатора значение по умолчанию выбирается по максимальному соответствию указанному идентификатору. Например, ‘src foo’ означает ‘(ip, arp или rarp) src foo’, ‘net bar’ означает ‘(ip, arp или rarp) net bar’, ‘port 53’ означает ‘(tcp или udp) port 53’.
Общие выражения строятся путем объединения примитивов при помощи логических операторов and (&&), or (||) и not (!). Например: ‘host foo and not port ftp and not port ftp-data’. В целях экономии занимаемого строкой объема памяти одинаковые квалификаторы могут не указываться. Например, ‘tcp dst port ftp or ftp-data or domain’ означает то же самое, что и ‘tcp dst port ftp or tcp dst port ftp-data or tcp dst port domain’.
Родственные группы примитивов могут объединяться с помощью тех же логических операторов. Например, tcp and (port ftp or ftp-data). Однако при объединении следует учесть, что операция отрицания имеет высший приоритет, а операции «И» и «ИЛИ» имеют одинаковый приоритет.
Ниже перечислены примеры примитивов, которые можно использовать при построении выражений фильтра:
dst host хост True, если поле IP-пакета «адрес приемника» совпадает со значением идентификатора host (может указываться имя или адрес хоста).
ether host хост True, если поле «источник» или «приемник» ethernet-кадра совпадает со значением идентификатора host (при этом имя или адрес хоста указывается в формате, определяемом квалификатором, в данном случае – ethernet).
ip proto протокол True, если IP-пакет соответствует указанному типу протокола (может указываться номер или имя соответствующего протокола: icmp, igrp, udp, nd или tcp).
При отборе пакетов определенного протокола имя протокола можно указывать без соответствующих квалификаторов ether или ip. Например, вместо ether proto arp можно указать arp, или вместо ip proto tcp можно указать tcp.
В дополнение к перечисленному выше, имеется еще несколько специальных примитивов, состоящих из одного ключевого слова:
gateway (шлюз) Используется следующим образом: gateway хост. Эквивалентное выражение для данного примитива выглядит так: ether host хост and not host хост. Фактически это означает, что хост является шлюзом, поскольку ethernet-адрес в пакете совпадает с адресом хост, однако в IP-заголовке адрес хост отсутствует.
mask (маска) Используется совместно с квалификатором net для задания сетевой маски. Например, net сеть mask маска означает отбор пакетов, IP-адрес которых удовлетворяет заданной маске.
broadcast (широковещательный адрес), multicast (групповой адрес) Используется совместно с квалификаторами ip и ehter для определения широковещательных и групповых пакетов. Например: ether broadcast, ip multicast.
less (меньше), greater (больше) Используется для отбора пакетов определенной длины. В качестве идентификатора указывается длина пакета. Например, выражение less 520 означает, что будут приняты все пакеты, длина которых не превышает 520 байт.
Кроме этого, имеется возможность отбора пакетов путем проверки отдельных байт и даже бит независимо от того, где они находятся – в заголовке, данных или концевике пакета. Для этого предусмотрен специальный математический примитив:
expr relop expr True, если математическое выражение истинно. relop это один из символов >, <, >=, =<, =, !=, а expr – выражение, составленное из целочисленных констант по правилам синтаксиса языка С, нормальных двоичных операторов [+, -, *, /, &, | ], оператора длины len и специальных выражений для доступа к данным пакета.
Для доступа к данным пакета используется следующее выражение:
proto [expr:size] Proto - это один из следующих протоколов: ip, ether, fddi, arp, rarp, tcp, udp, icmp. Эта переменная определяет уровень протокола для операции индексации. Переменная expr определяет смещение в байтах применительно к указанному протоколу. Переменная size определяет размер поля, применительно к которому будет выполнена дальнейшая операция сравнения. Эта переменная может принимать значения 1, 2 или 4. Если она не указана, по умолчанию выбирается значение 1. Оператор len дает длину всего пакета.
Например, выражение ether[0]&1 != 0 позволяет перехватывать весь групповой трафик. Выражение ip[0]&0xf != 5 означает отбор IP-пакетов с наличием опций, а выражение ip[6:2]&0x1fff = 0 отбирает только не фрагментированные дейтаграммы.
Приведем несколько примеров выражений для описания фильтра:
host sundown – принимать все пакеты от хоста с именем sundown
host helios and (hot or ace) – перехватывать трафик между хостами helios и hot и helios и ace
ip host helios and not ace – перехватывать трафик между хостом helios и всеми хостами, исключая ace
gateway snup and (port ftp or ftp-data) – перехватывать весь ftp-трафик, проходящий через шлюз snup
tcp[13]&3 != 0 and not src and dst net localnet – принимать только TCP SYN и FIN пакеты, не предназначенные локальному хосту localnet и не отправленные им.
Отличия библиотеки Winpcap от библиотеки libpcap.
Архитектура PCAP изначально разрабатывалась для операционных систем с открытым исходным кодом. Закрытые коммерческие операционные системы остались без внимания разработчиков. Этот факт явился одной из причин, из-за которых практически все более-менее серьезные сетевые приложения написаны для UNIX, Linux, BSD и т.д. Windows в этом плане заметно отставала.
Однако программирование приложений на языках высокого уровня под Windows – процесс куда более приятный, чем под той же Linux. Удобство отладки, наличие удобной системы помощи, быстрая разработка приложений и визуальных интерфейсов и масса других положительных качеств средств разработки приложений (Delphi, C++ Builder, Visual Studio) и отсутствие возможности низкоуровневого управления сетевым интерфейсом привели к возникновению необходимости создания архитектуры, аналогичной PCAP, для семейства ОС Windows. Естественно, разработчики архитектуры WinPCAP не стали изобретать велосипед, а адаптировали существующую архитектуру PCAP для ОС Windows.
Процесс переноса PCAP на Windows заключался в адаптации pcap-драйвера и библиотеки libpcap для работы под Win32. Оригинальная версия libpcap написана на языке C с учетом возможности переноса библиотеки на различные версии UNIX. ОС Windows не поддерживает всех вызовов POSIX-систем, однако предоставляет некоторые аналогичные им функции через API. Модели памяти UNIX и Windows одинаковы (Windows и большинство UNIX являются 32-х битными ОС) и имеют аналогичный размер целых чисел.
Версия PCAP для Win32 основана на драйвере захвата пакетов, структура и принцип действия которого аналогичен его предшественнику для UNIX. Это значительно облегчает процесс переноса приложений с одной ОС на другую. Библиотеки и функции ОС UNIX, отсутствующие в Windows (например, getnetbyname) и необходимые для компиляции libpcap на Windows-машине, разработчикам пришлось включить в исходный код драйвера (директория Win32-Include дистрибутива).
Часть исходного кода, отвечающая за взаимодействие с сетевым адаптером, была изменена для поддержки его NDIS-драйвера. В соответствии с обозначениями, принятыми в оригинальной версии libpcap, исходный код для взаимодействия с драйвером находится в наборе файлов pcap-XXX.c (и соответствующий ему pcap-XXX.h), где XXX – указывает на операционную систему (например, pcap-linux.c). К уже существующим файлам были добавлены pcap-win32.c и pcap-win32.h.
Основному изменению подвергся принцип взаимодействия приложения пользователя с драйвером захвата пакетов. Libpcap для Win32 взаимодействует с аппаратным обеспечением через интерфейс, предоставляемый динамической библиотекой packet.dll (в отличие от Windows, в ОС UNIX сетевой адаптер или модем «виден» как стандартный файл, поэтому нет необходимости в использовании промежуточных библиотек – достаточно просто создать пакет необходимой структуры и записать его в этот файл). Это не влияет на нормальную работу libpcap, однако может создать определенные проблемы программисту, желающему получить доступ непосредственно к драйверу захвата пакетов. Например, в ОС UNIX возможно использовать системный вызов SELECT для того, чтобы узнать, поступил ли пакет на вход адаптера. В ОС Windows такая возможность отсутствует.
Программист может использовать функции libpcap для обеспечения работоспособности исходного кода приложения на различных операционных системах, но при этом возможности приложения будут ограничены (например, libpcap не позволяет отправлять пакеты через сетевой интерфейс). Если программист решит воспользоваться функциями packet.dll, то его приложение будет работать только под управлением ОС семейства Win32, однако при этом возможности приложения будут практически неограниченными.
Для обеспечения максимальной совместимости исходного кода libpcap различных ОС часть кода, предназначенная для ОС Windows, отделена от остального кода директивами #ifdef и #ifndef. Например:
#ifdef WIN32
/* исходный код для Windows */
#endif
Это позволяет компилировать исходный код libpcap как на ОС Windows, так и на UNIX.
Каркас приложения для прослушивания сети на основе библиотеки libpcap.
#include <pcap.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
pcap_t *handle;/* Session handle */
char *dev;/* The device to sniff on */
char errbuf[PCAP_ERRBUF_SIZE];/* Error string */
struct bpf_program fp;/* The compiled filter */
char filter_exp[] = "port 23";/* The filter expression */
bpf_u_int32 mask;/* Our netmask */
bpf_u_int32 net;/* Our IP */
struct pcap_pkthdr header;/* The header that pcap gives us */
const u_char *packet;/* The actual packet */
/* Define the device */
dev = pcap_lookupdev(errbuf);
if (dev == NULL) {
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
/* Find the properties for the device */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1) {
fprintf(stderr, "Couldn't get netmask for device %s: %s\n", dev, errbuf);
net = 0;
mask = 0;
}
/* Open the session in promiscuous mode */
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
/* Compile and apply the filter */
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) {
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1) {
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
/* Grab a packet */
packet = pcap_next(handle, &header);
/* Print its length */
printf("Jacked a packet with length of [%d]\n", header.len);
/* And close the session */
pcap_close(handle);
return(0);
}
Программирование сокетов. Функции локального управления.
Socket-интерфейс
Данное средство было первоначально разработано для обеспечения прикладным программистам в среде ОС UNIX доступа к транспортному уровню стека протоколов TCP/IP. Позже оно было адаптировано для использования и иных протоколов (например, DECnet), а также реализовано в других операционных системах.
Socket (гнездо, разъем) - абстрактное программное понятие, используемое для обозначения в прикладной программе конечной точки канала связи с коммуникационной средой, образованной вычислительной сетью. При использовании протоколов TCP/IP можно говорить, что socket является средством подключения прикладной программы к порту (см. выше) локального узла сети.
Socket-интерфейс представляет собой просто набор системных вызовов и/или библиотечных функций языка программирования СИ, разделенных на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Функции локального управления
Функции локального управления используются, главным образом, для выполнения подготовительных действий, необходимых для организации взаимодействия двух программ-партнеров. Функции носят такое название, поскольку их выполнение носит локальный для программы характер.
Создание socket'а
Создание socket'а осуществляется следующим системным вызовом
#include <sys/socket.h>
int socket (domain, type, protocol)
int domain;
int type;
int protocol;
Аргумент domain задает используемый для взаимодействия набор протоколов (вид коммуникационной области), для стека протоколов TCP/IP он должен иметь символьное значение AF_INET (определено в sys/socket.h).
Аргумент type задает режим взаимодействия:
SOCK_STREAM - с установлением соединения;
SOCK_DGRAM - без установления соединения.
Аргумент protocolзадает конкретный протокол транспортного уровня (из нескольких возможных в стеке протоколов). Если этот аргумент задан равным 0, то будет использован протокол "по умолчанию" (TCP для SOCK_STREAM и UDP для SOCK_DGRAM при использовании комплекта протоколов TCP/IP).
При удачном завершении своей работы данная функция возвращает дескриптор socket'а - целое неотрицательное число, однозначно его идентифицирующее. Дескриптор socket'а аналогичен дескриптору файла ОС UNIX.
При обнаружении ошибки в ходе своей работы функция возвращает число "-1".
Связывание socket'а
Для подключения socket'а к коммуникационной среде, образованной вычислительной сетью, необходимо выполнить системный вызов bind, определяющий в принятом для сети формате локальный адрес канала связи со средой. В сетях TCP/IP socket связывается с локальным портом. Системный вызов bind имеет следующий синтаксис:
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int bind (s, addr, addrlen)
int s;
struct sockaddr *addr;
int addrlen;
Аргумент s задает дескриптор связываемого socket'а.
Аргумент addr в общем случае должен указывать на структуру данных, содержащую локальный адрес, приписываемый socket'у. Для сетей TCP/IP такой структурой является sockaddr_in.
Аргумент addrlen задает размер (в байтах) структуры данных, указываемой аргументом addr.
Структура sockaddr_in используется несколькими системными вызовами и функциями socket-интерфейса и определена в include-файле in.h следующим образом:
struct sockaddr_in {
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
Поле sin_family определяет используемый формат адреса (набор протоколов), в нашем случае (для TCP/IP) оно должно иметь значение AF_INET.
Поле sin_addr содержит адрес (номер) узла сети.
Поле sin_port содержит номер порта на узле сети.
Поле sin_zero не используется.
Определение структуры in_addr (из того же include-файла) таково:
struct in_addr {
union {
u_long S_addr;
/*
другие (не интересующие нас)
члены объединения
*/
} S_un;
#define s_addr S_un.S_addr
};
Структура sockaddr_in должна быть полностью заполнена перед выдачей системного вызова bind. При этом, если поле sin_addr.s_addr имеет значение INADDR_ANY, то системный вызов будет привязывать к socket'у номер (адрес) локального узла сети.
В случае успеха bind возвращает 0, в противном случае - "-1".
Программирование сокетов. Функции установления связи.
Socket-интерфейс
Данное средство было первоначально разработано для обеспечения прикладным программистам в среде ОС UNIX доступа к транспортному уровню стека протоколов TCP/IP. Позже оно было адаптировано для использования и иных протоколов (например, DECnet), а также реализовано в других операционных системах.
Socket (гнездо, разъем) - абстрактное программное понятие, используемое для обозначения в прикладной программе конечной точки канала связи с коммуникационной средой, образованной вычислительной сетью. При использовании протоколов TCP/IP можно говорить, что socket является средством подключения прикладной программы к порту (см. выше) локального узла сети.
Socket-интерфейс представляет собой просто набор системных вызовов и/или библиотечных функций языка программирования СИ, разделенных на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Функции установления связи
Для установления связи "клиент-сервер" используются системные вызовы listen и accept (на стороне сервера), а также connect (на стороне клиента). Для заполнения полей структуры socaddr_in, используемой в вызове connect, обычно используется библиотечная функция gethostbyname, транслирующая символическое имя узла сети в его номер (адрес).
Ожидание установления связи
Системный вызов listen выражает желание выдавшей его программы-сервера ожидать запросы к ней от программ-клиентов и имеет следующий вид:
#include <sys/socket.h>
int listen (s, n)
int s;
int n;
Аргумент s задает дескриптор socket'а, через который программа будет ожидать запросы к ней от клиентов. Socket должен быть предварительно создан системным вызовом socket и обеспечен адресом с помощью системного вызова bind.
Аргумент n определяет максимальную длину очереди входящих запросов на установление связи. Если какой-либо клиент выдаст запрос на установление связи при полной очереди, то этот запрос будет отвергнут.
Признаком удачного завершения системного вызова listen служит нулевой код возврата.
Запрос на установление соединения
Для обращения программы-клиента к серверу с запросом на установление логической соединения используется системный вызов connect, имеющий следующий вид
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int connect (s, addr, addrlen)
int s;
struct sockaddr_in *addr;
int addrlen;
Аргумент s задает дескриптор socket'а, через который программа обращается к серверу с запросом на соединение. Socket должен быть предварительно создан системным вызовом socket и обеспечен адресом с помощью системного вызова bind.
Аргумент addr должен указывать на структуру данных, содержащую адрес, приписанный socket'у программы-сервера, к которой делается запрос на соединение. Для сетей TCP/IP такой структурой является sockaddr_in. Для формирования значений полей структуры sockaddr_in удобно использовать функцию gethostbyname.
Аргумент addrlen задает размер (в байтах) структуры данных, указываемой аргументом addr.
Для того, чтобы запрос на соединение был успешным, необходимо, по крайней мере, чтобы программа-сервер выполнила к этому моменту системный вызов listen для socket'а с указанным адресом.
При успешном выполнении запроса системный вызов connect возвращает 0, в противном случае - "-1" (устанавливая код причины неуспеха в глобальной переменной errno).
Примечание. Если к моменту выполнения connect используемый им socket не был привязан к адресу посредством bind ,то такая привязка будет выполнена автоматически.
Примечание. В режиме взаимодействия без установления соединения необходимости в выполнении системного вызова connect нет. Однако, его выполнение в таком режиме не является ошибкой - просто меняется смысл выполняемых при этом действий: устанавливается адрес "по умолчанию" для всех последующих посылок дейтаграмм.
Прием запроса на установление связи
Для приема запросов от программ-клиентов на установление связи в программах-серверах используется системный вызов accept, имеющий следующий вид:
#include <sys/socket.h>
#include <netinet/in.h>
int accept (s, addr, p_addrlen)
int s;
struct sockaddr_in *addr;
int *p_addrlen;
Аргумент s задает дескриптор socket'а, через который программа-сервер получила запрос на соединение (посредством системного запроса listen ).
Аргумент addr должен указывать на область памяти, размер которой позволял бы разместить в ней структуру данных, содержащую адрес socket'а программы-клиента, сделавшей запрос на соединение. Никакой инициализации этой области не требуется.
Аргумент p_addrlen должен указывать на область памяти в виде целого числа, задающего размер (в байтах) области памяти, указываемой аргументом addr.
Системный вызов accept извлекает из очереди, организованной системным вызовом listen, первый запрос на соединение и возвращает дескриптор нового (автоматически созданного) socket'а с теми же свойствами, что и socket, задаваемый аргументом s. Этот новый дескриптор необходимо использовать во всех последующих операциях обмена данными.
Кроме того после удачного завершения accept:
область памяти, указываемая аргументом addr, будет содержать структуру данных (для сетей TCP/IP это sockaddr_in), описывающую адрес socket'а программы-клиента, через который она сделала свой запрос на соединение;
целое число, на которое указывает аргумент p_addrlen, будет равно размеру этой структуры данных.
Если очередь запросов на момент выполнения accept пуста, то программа переходит в состояние ожидания поступления запросов от клиентов на неопределенное время (хотя такое поведение accept можно и изменить).
Признаком неудачного завершения accept служит отрицательное возвращенное значение (дескриптор socket'а отрицательным быть не может).
Примечание. Системный вызов accept используется в программах-серверах, функционирующих только в режиме с установлением соединения.
Формирование адреса узла сети
Для получения адреса узла сети TCP/IP по его символическому имени используется библиотечная функция
#include <netinet/in.h>
#include <netdb.h>
struct hostent *gethostbyname (name)
char *name;
Аргумент name задает адрес последовательности литер, образующих символическое имя узла сети.
При успешном завершении функция возвращает указатель на структуру hostent, определенную в include-файле netdb.h и имеющую следующий вид
struct hostent {
char *h_name;
char **h_aliases;
int h_addrtype;
int h_lenght;
char *h_addr;
};
Поле h_name указывает на официальное (основное) имя узла.
Поле h_aliases указывает на список дополнительных имен узла (синонимов), если они есть.
Поле h_addrtype содержит идентификатор используемого набора протоколов, для сетей TCP/IP это поле будет иметь значение AF_INET.
Поле h_lenght содержит длину адреса узла.
Поле h_addr указывает на область памяти, содержащую адрес узла в том виде, в котором его используют системные вызовы и функции socket-интерфейса.
Программирование сокетов. Функции обмена данными (ввода/вывода).
Socket-интерфейс
Данное средство было первоначально разработано для обеспечения прикладным программистам в среде ОС UNIX доступа к транспортному уровню стека протоколов TCP/IP. Позже оно было адаптировано для использования и иных протоколов (например, DECnet), а также реализовано в других операционных системах.
Socket (гнездо, разъем) - абстрактное программное понятие, используемое для обозначения в прикладной программе конечной точки канала связи с коммуникационной средой, образованной вычислительной сетью. При использовании протоколов TCP/IP можно говорить, что socket является средством подключения прикладной программы к порту (см. выше) локального узла сети.
Socket-интерфейс представляет собой просто набор системных вызовов и/или библиотечных функций языка программирования СИ, разделенных на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Функции обмена данными
В режиме с установлением логического соединения после удачного выполнения пары взаимосвязанных системных вызовов connect (в клиенте) и accept (в сервере) становится возможным обмен данными.
Этот обмен может быть реализован обычными системными вызовами read и write, используемыми для работы с файлами (при этом вместо дескрипторов файлов в них задаются дескрипторы socket'ов).
Кроме того могут быть дополнительно использованы системные вызовы send и recv, ориентированные специально на работу с socket'ами.
Примечание. Для обмена данными в режиме без установления логического соединения используются, как правило, системные вызовы sendtoи recvfrom. Sendto позволяет специфицировать вместе с передаваемыми данными (составляющими дейтаграмму) адрес их получателя. Recvfrom одновременно с доставкой данных получателю информирует его и об адресе отправителя.
Посылка данных
Для посылки данных партнеру по сетевому взаимодействию используется системный вызов send, имеющий следующий вид
#include <sys/types.h>
#include <sys/socket.h>
int send (s, buf, len, flags)
int s;
char *buf;
int len;
int flags;
Аргумент s задает дескриптор socket'а, через который посылаются данные.
Аргумент buf указывает на область памяти, содержащую передаваемые данные.
Аргумент len задает длину (в байтах) передаваемых данных.
Аргумент flags модифицирует исполнение системного вызова send. При нулевом значении этого аргумента вызов send полностью аналогичен системному вызову write.
При успешном завершении send возвращает количество переданных из области, указанной аргументом buf, байт данных. Если канал данных, определяемый дескриптором s, оказывается "переполненным", то send переводит программу в состояние ожидания до момента его освобождения.
Получение данных
Для получения данных от партнера по сетевому взаимодействию используется системный вызов recv, имеющий следующий вид
#include <sys/types.h>
#include <sys/socket.h>
int recv (s, buf, len, flags)
int s;
char *buf;
int len;
int flags;
Аргумент s задает дескриптор socket'а, через который принимаются данные.
Аргумент buf указывает на область памяти, предназначенную для размещения принимаемых данных.
Аргумент len задает длину (в байтах) этой области.
Аргумент flags модифицирует исполнение системного вызова recv. При нулевом значении этого аргумента вызов recv полностью аналогичен системному вызову read.
При успешном завершении recv возвращает количество принятых в область, указанную аргументом buf, байт данных. Если канал данных, определяемый дескриптором s, оказывается "пустым", то recv переводит программу в состояние ожидания до момента появления в нем данных.
Программирование сокетов. Функции закрытия связи
Socket-интерфейс
Данное средство было первоначально разработано для обеспечения прикладным программистам в среде ОС UNIX доступа к транспортному уровню стека протоколов TCP/IP. Позже оно было адаптировано для использования и иных протоколов (например, DECnet), а также реализовано в других операционных системах.
Socket (гнездо, разъем) - абстрактное программное понятие, используемое для обозначения в прикладной программе конечной точки канала связи с коммуникационной средой, образованной вычислительной сетью. При использовании протоколов TCP/IP можно говорить, что socket является средством подключения прикладной программы к порту (см. выше) локального узла сети.
Socket-интерфейс представляет собой просто набор системных вызовов и/или библиотечных функций языка программирования СИ, разделенных на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Функции закрытия связи
Для закрытия связи с партнером по сетевому взаимодействию используются системные вызовы close и shutdown.
Системный вызов close
Для закрытия ранее созданного socket'а используется обычный системный вызов close, применяемый в ОС UNIX для закрытия ранее открытых файлов и имеющий следующий вид
int close (s)
int s;
Аргумент s задает дескриптор ранее созданного socket'а.
Однако в режиме с установлением логического соединения (обеспечивающем, как правило, надежную доставку данных) внутрисистемные механизмы обмена будут пытаться передать/принять данные, оставшиеся в канале передачи на момент закрытия socket'а. На это может потребоваться значительный интервал времени, неприемлемый для некоторых приложений. В такой ситуации необходимо использовать описываемый далее системный вызов shutdown.
Сброс буферизованных данных
Для "экстренного" закрытия связи с партнером (путем "сброса" еще не переданных данных) используется системный вызов shutdown, выполняемый перед close и имеющий следующий вид
int shutdown (s, how)
int s;
int how;
Аргумент s задает дескриптор ранее созданного socket'а.
Аргумент how задает действия, выполняемые при очистке системных буферов socket'а:
0 - сбросить и далее не принимать данные для чтения из socket'а;
1 - сбросить и далее не отправлять данные для посылки через socket;
2 - сбросить все данные, передаваемые через socket в любом направлении.
Программирование сокетов. Способы параллельного обслуживания клиентов.
Socket-интерфейс
Данное средство было первоначально разработано для обеспечения прикладным программистам в среде ОС UNIX доступа к транспортному уровню стека протоколов TCP/IP. Позже оно было адаптировано для использования и иных протоколов (например, DECnet), а также реализовано в других операционных системах.
Socket (гнездо, разъем) - абстрактное программное понятие, используемое для обозначения в прикладной программе конечной точки канала связи с коммуникационной средой, образованной вычислительной сетью. При использовании протоколов TCP/IP можно говорить, что socket является средством подключения прикладной программы к порту (см. выше) локального узла сети.
Socket-интерфейс представляет собой просто набор системных вызовов и/или библиотечных функций языка программирования СИ, разделенных на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Способ 0 - Запуск серверного приложения через inetd
В операционной системе UNIX и некоторых других имеется сетевой суперсервер inetd(xinetd), который позволяет почти без усилий сделать приложение сетевым. Кроме того, если есть всего один процесс, который прослушивает входящие соединения и входящие UDP-датаграммы, то можно сэкономить системные ресурсы. Обычно inetd поддерживает, по меньшей мере, протоколы TCP и UDP, а возможно, и некоторые другие. Здесь будут рассмотрены только первый. Поведение inetd(xinetd) существенно зависит от того, с каким протоколом - TCP или UDP - он работает.
TCP-серверы
Для TCP-серверов inetd(xinetd) прослушивает хорошо известные порты, ожидая запроса на соединение, затем принимает соединение, ассоциирует с ним файловые Дескрипторы stdin, stdout и stderr, после чего запускает приложение. Таким образом, сервер может работать с соединением через дескрипторы 0, 1 и 2. Если это допускается конфигурационным файлом inetd(xinetd) (/etc/ inetd.conf /etc/xinetd.conf) , то inetd(xinetd) продолжает прослушивать тот же порт. Когда в этот порт поступает запрос на новое соединение, запускается новый экземпляр сервера, даже если первый еще не завершил сеанс. Это показано на рис. 1. Обратите внимание, что серверу не нужно обслуживать нескольких клиентов. Он просто выполняет запросы одного клиента, а потом завершается. Остальные клиенты обслуживаются дополнительными экземплярами сервера.

Рис. 1. Действия inetd при запуске TCP-сервера
Применение inetd(xinetd) освобождает от необходимости самостоятельно устанавливать TCP или UDP-соединение и позволяет писать сетевое приложение почти так же, как обычный фильтр.
Способ 1 - Параллельный сервер с созданием копий.
Этот способ подразумевает создание дочернего процесса для обслуживания каждого нового клиента. При этом родительский процесс занимается только прослушиванием порта и приёмом соединений. Чтобы добиться такого поведения, сразу после accept сервер вызывает функцию fork(Windows-программисты в этом случае пишут сервер на основе thread)для создания дочернего процесса (вам знакома функция fork по практическим работам по предмету "ОС UNIX". Далее анализируется значение, которая вернула эта функция. В родительском процессе оно содержит идентификатор дочернего, а в дочернем процессе равно нулю. Используя этот признак, мы переходим к очередному вызову accept в родительском процессе, а дочерний процесс обслуживает клиента и завершается (exit).
Листинг 1. Код сервер (версия fork)
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main()
{
int sock, listener;
struct sockaddr_in addr;
char buf[1024];
int bytes_read;
listener = socket(AF_INET, SOCK_STREAM, 0);
if(listener < 0)
{
perror("socket");
exit(1);
}
addr.sin_family = AF_INET;
addr.sin_port = htons(3425);
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(listener, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
perror("bind");
exit(2);
}
listen(listener, 1);
while(1)
{
sock = accept(listener, NULL, NULL);
if(sock < 0)
{
perror("accept");
exit(3);
}
switch(fork())
{
case -1:
perror("fork");
break;
case 0:
close(listener);
while(1)
{
bytes_read = recv(sock, buf, 1024, 0);
if(bytes_read <= 0) break;
send(sock, buf, bytes_read, 0);
....
}
close(sock);
exit(0);
default:
close(sock);
}
}
close(listener);
return 0;
}
Очевидное преимущество такого подхода состоит в том, что он позволяет писать весьма компактные, понятные программы, в которых код установки соединения отделён от кода обслуживания клиента. К сожалению, у него есть и недостатки. Во-первых, если клиентов очень много, создание нового процесса для обслуживания каждого из них может оказаться слишком дорогостоящей операцией. Во-вторых, такой способ неявно подразумевает, что все клиенты обслуживаются независимо друг от друга. Однако это может быть не так. Если, к примеру, вы пишете чат-сервер, то ваша основная задача - поддерживать взаимодействие всех клиентов, присоединившихся к нему. В этих условиях границы между процессами станут для вас серьёзной помехой. В подобном случае вам следует серьёзно рассмотреть другой способ обслуживания клиентов.
Способ 2 - Параллельный сервер с предварительным созданием копий.
Второй способ является модификацией первого и применяется в приложениях, требующих мапой задержки(латентности) между моментом первого запроса и ответа сервера. Нужно только поменять fork & accept местами - создать заранее некоторый пул обслуживающих процессов, каждый из которых до прихода клиентского запроса будет заблокирован на accept (accept на одном и том же прослушиваемом сокете). А после отработки клиентского запроса заблаговременно создать новый обслуживающий процесс. Эта техника известна как «предварительный fork» или pre-fork.
Фрагмент кода программы сервера с использованием этой методики показан в листинге 2. Для более четкого показа приводится код программы на C++.
Листинг 2. Код сервер (версия pre- fork)
#include <common.h>
Const int NUMPROC = 3;
int main(int argc, char *argv[])
{
int ls = getsocket( PREFORK_PORT ), rs;
for( int i = 0; i < NUMPROC; i++ ) {
if( fork() == 0 ) {
int rs;
while( true ) {
if( ( rs = accept( ls, NULL, NULL ) ) < 0 ) errx( "accept error" );
server( rs ); /* В подпрограмме server реализуется логика работы сервера */
close( rs );
cout << i << flush;
delay( 250 );
};
};
};
for( int i = 0; i < NUMPROC; i++ ) waitpid( 0, NULL, 0 );
exit( EXIT_SUCCESS );
}
При написании этого текста я несколько «схитрил» и упростил в сравнении с предложенной абзацем выше моделью. Здесь 3 обслуживающих процесса сделаны циклическими и не завершаются по окончанию обслуживания, а снова блокируются на accept, но для наблюдения эффектов этого вполне достаточно (последняя строка нужна вообще только для блокировки родительского процесса, и «сохранения» управляющего терминала - для возможности прекращения всей группы процессов по ^C или по kill -TERM ... в случае, когда сервер запущен в фоновом режиме).
Способ 3 - Использование неблокирующих сокетов
Третий способ основан на использовании неблокирующих сокетов (nonblocking sockets) и функции select. Сначала разберёмся, что такое неблокирующие сокеты. Сокеты, которые мы до сих пор использовали, являлись блокирующими (blocking). Это название означает, что на время выполнения операции с таким сокетом ваша программа блокируется. Например, если вы вызвали recv, а данных на вашем конце соединения нет, то в ожидании их прихода ваша программа "засыпает". Аналогичная ситуация наблюдается, когда вы вызываете accept, а очередь запросов на соединение пуста. Это поведение можно изменить, используя функцию fcntl.
#include <unistd.h>
#include <fcntl.h>
sockfd = socket(AF_INET, SOCK_STREAM, 0);
fcntl(sockfd, F_SETFL, O_NONBLOCK);
Эта несложная операция превращает сокет в неблокирующий. Вызов любой функции с таким сокетом будет возвращать управление немедленно. Причём если затребованная операция не была выполнена до конца, функция вернёт -1 и запишет в errno значение EWOULDBLOCK. Чтобы дождаться завершения операции, мы можем опрашивать все наши сокеты в цикле, пока какая-то функция не вернёт значение, отличное от EWOULDBLOCK. Как только это произойдёт, мы можем запустить на выполнение следующую операцию с этим сокетом и вернуться к нашему опрашивающему циклу. Такая тактика (называемая в англоязычной литературе polling) работоспособна, но очень неэффективна, поскольку процессорное время тратится впустую на многократные (и безрезультатные) опросы.
Чтобы исправить ситуацию, используют функцию select. Эта функция позволяет отслеживать состояние нескольких файловых дескрипторов (а в Unix к ним относятся и сокеты) одновременно.
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int n, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
FD_CLR(int fd, fd_set *set);
FD_ISSET(int fd, fd_set *set);
FD_SET(int fd, fd_set *set);
FD_ZERO(int fd);
Функция select работает с тремя множествами дескрипторов, каждое из которых имеет тип fd_set. В множество readfds записываются дескрипторы сокетов, из которых нам требуется читать данные (слушающие сокеты добавляются в это же множество). Множество writefds должно содержать дескрипторы сокетов, в которые мы собираемся писать, а exceptfds - дескрипторы сокетов, которые нужно контролировать на возникновение ошибки. Если какое-то множество вас не интересуют, вы можете передать вместо указателя на него NULL. Что касается других параметров, в n нужно записать максимальное значение дескриптора по всем множествам плюс единица, а в timeout - величину таймаута. Структура timeval имеет следующий формат.
struct timeval {
int tv_sec; // секунды
int tv_usec; // микросекунды
};
Поле "микросекунды" смотрится впечатляюще. Но на практике вам не добиться такой точности измерения времени при использовании select. Реальная точность окажется в районе 100 миллисекунд.
Теперь займёмся множествами дескрипторов. Для работы с ними предусмотрены функции FD_XXX, показанные выше; их использование полностью скрывает от нас детали внутреннего устройства fd_set. Рассмотрим их назначение.
FD_ZERO(fd_set *set) - очищает множество set
FD_SET(int fd, fd_set *set) - добавляет дескриптор fd в множество set
FD_CLR(int fd, fd_set *set) - удаляет дескриптор fd из множества set
FD_ISSET(int fd, fd_set *set) - проверяет, содержится ли дескриптор fd в множестве set
Если хотя бы один сокет готов к выполнению заданной операции, select возвращает ненулевое значение, а все дескрипторы, которые привели к "срабатыванию" функции, записываются в соответствующие множества. Это позволяет нам проанализировать содержащиеся в множествах дескрипторы и выполнить над ними необходимые действия. Если сработал таймаут, select возвращает ноль, а в случае ошибки -1. Расширенный код записывается в errno.
Программы, использующие неблокирующие сокеты вместе с select, получаются весьма запутанными. Если в случае с fork мы строим логику программы, как будто клиент всего один, здесь программа вынуждена отслеживать дескрипторы всех клиентов и работать с ними параллельно. Чтобы проиллюстрировать эту методику, я в очередной раз переписал код сервера с использованием select. Новая версия приведена в листинге 3. Эта программа, также написана на C++ (а не на C). В программе использовался класс set из библиотеки STL языка C++, чтобы облегчить работу с набором дескрипторов и сделать её более понятной.
Листинг 3. Код сервера (неблокирующие сокеты и select).
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/time.h>
#include <netinet/in.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <algorithm>
#include <set>
using namespace std;
int main()
{
int listener;
struct sockaddr_in addr;
char buf[1024];
int bytes_read;
listener = socket(AF_INET, SOCK_STREAM, 0);
if(listener < 0)
{
perror("socket");
exit(1);
}
fcntl(listener, F_SETFL, O_NONBLOCK);
addr.sin_family = AF_INET;
addr.sin_port = htons(3425);
addr.sin_addr.s_addr = INADDR_ANY;
if(bind(listener, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
perror("bind");
exit(2);
}
listen(listener, 2);
set<int> clients;
clients.clear();
while(1)
{
// Заполняем множество сокетов
fd_set readset;
FD_ZERO(&readset);
FD_SET(listener, &readset);
for(set<int>::iterator it = clients.begin(); it != clients.end(); it++)
FD_SET(*it, &readset);
// Задаём таймаут
timeval timeout;
timeout.tv_sec = 15;
timeout.tv_usec = 0;
// Ждём события в одном из сокетов
int mx = max(listener, *max_element(clients.begin(), clients.end()));
if(select(mx+1, &readset, NULL, NULL, &timeout) <= 0)
{
perror("select");
exit(3);
}
// Определяем тип события и выполняем соответствующие действия
if(FD_ISSET(listener, &readset))
{
// Поступил новый запрос на соединение, используем accept
int sock = accept(listener, NULL, NULL);
if(sock < 0)
{
perror("accept");
exit(3);
}
fcntl(sock, F_SETFL, O_NONBLOCK);
clients.insert(sock);
}
for(set<int>::iterator it = clients.begin(); it != clients.end(); it++)
{
if(FD_ISSET(*it, &readset))
{
// Поступили данные от клиента, читаем их
bytes_read = recv(*it, buf, 1024, 0);
if(bytes_read <= 0)
{
// Соединение разорвано, удаляем сокет из множества
close(*it);
clients.erase(*it);
continue;
}
// Другие лействия сервера
} }
} return 0;
}
Программирование сокетов. Способы повышения эффективности обмена данными.
Socket-интерфейс
Данное средство было первоначально разработано для обеспечения прикладным программистам в среде ОС UNIX доступа к транспортному уровню стека протоколов TCP/IP. Позже оно было адаптировано для использования и иных протоколов (например, DECnet), а также реализовано в других операционных системах.
Socket (гнездо, разъем) - абстрактное программное понятие, используемое для обозначения в прикладной программе конечной точки канала связи с коммуникационной средой, образованной вычислительной сетью. При использовании протоколов TCP/IP можно говорить, что socket является средством подключения прикладной программы к порту (см. выше) локального узла сети.
Socket-интерфейс представляет собой просто набор системных вызовов и/или библиотечных функций языка программирования СИ, разделенных на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Системный вызов sendfile
Системный вызов sendfile был добавлен в ядро Linux относительно недавно и стал важным приобретением для приложений, таких как ftp или web серверы, которым просто необходим эффективный механизм передачи файлов. В данной работе вы ознакомитесь с sendfile -- что он делает и как с ним работать. Рассмотрение сопровождается небольшими примерами и комментариями.
История вопроса
Приложения-серверы, такие как web-серверы, тратят огромное количество времени на передачу файлов, хранящихся на жестком диске, клиентам, работающим с сервером через web-браузер. Простой алгоритм передачи данных может выглядеть примерно так:
открыть исходный файл (на диске)
открыть файл назначения (сетевое соединение)
пока файл не передан:
прочитать блок данных из исходного файла в буфер
записать данные из буфера в файл назначения
закрыть оба файла
Процедуры чтения и записи данных обычно используют системные вызовы read и write, соответственно, либо библиотечные функции, которые являются своего рода "обертками" для этих системных вызовов.
Если следовать вышеприведенному алгоритму, то получается так, что данные копируются несколько раз, прежде чем они "уйдут" в сеть. Каждый раз, когда вызывается read, данные копируются с жесткого диска в буфер ядра (обычно посредством DMA). Затем буфер копируется в буфер приложения. Затем вызывается write и данные из буфера приложения опять копируются в буфер ядра и лишь потом этот буфер отправляется в сеть. Каждый раз, когда приложение обращается к системному вызову, происходит переключение контекста между пользовательским режимом и режимом ядра, а это весьма "дорогостоящая" операция. И чем больше в программе будет обращений к системным вызовам read и write, тем больше времени будет потрачено на выполнение переключений контекста исполнения.
Операции копирования данных из области ядра в область приложения и обратно, в данном случае, излишни, поскольку сами данные в приложении не изменяются и не анализируются. Многие операционные системы, такие как Windows NT, FreeBSD и Solaris предоставляют в распоряжение программиста системный вызов, который выполняет передачу файла за одно обращение. Ранние версии Linux часто критиковали за отсутствие подобной возможности, в результате, начиная с версии 2.2.x, такой вызов появился. Теперь он широко используется такими серверными приложениями, как Apache и Samba для ускорения обслуживания большого количества клиентов.
Реализация sendfile различна для разных операционных систем. Поэтому, в данной статье мы будем говорить о версии sendfile в Linux. Обратите внимание: утилита sendfile не то же самое, что системный вызов sendfile.
Подробное описание
Чтобы использовать sendfile в своих программах, вы должны подключить заголовочный файл <sys/sendfile.h>, в котором находится описание прототипа функции-вызова:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
Функция принимает следующие входные параметры:
out_fd
файловый дескриптор файла назначения, открытого на запись. В этот файл производится запись данных
in_fd
файловый дескриптор исходного файла, открытого на чтение. Из этого файла читаются данные
offset
смещение от начала исходного файла, с этой точки будет начата передача данных (т.е. значение 0 соответствует началу файла). Это значение изменяется в процессе работы функции и ваше приложение получит его в измененном виде после того, как функция вернет управление.
count
количество байт, которое необходимо передать
В случае успеха функция возвращает количество переданных байт, и -1 -- в случае ошибки.
В Linux файловый дескриптор может соответствовать как обычному файлу так и устройству, например -- сокету. На сегодняшний день, реализация sendfile требует, чтобы исходный файловый дескриптор соответствовал обычному файлу или устройству, поддерживаемому mmap. Это означает, например, что исходный файл не может быть сокетом. Файл назначения может быть и сокетом, и это обстоятельство широко используется приложениями.
Пример
Рассмотрим простой пример работы с системным вызовом sendfile. В листинге ниже приведен текст программы fastcp.c, которая выполняет простое копирование файла.
1 int main(int argc, char **argv) {
2 int src; /* дескриптор исходного файла */
3 int dest; /* дескриптор файла назначения */
4 struct stat stat_buf; /* сведения об исходном файле */
5 off_t offset = 0; /* смещение от начала исходного файла */
7 /* проверить -- существует ли исходный файл и открыть его */
8 src = open(argv[1], O_RDONLY);
9 /* запросить размер исходного файла и права доступа к нему */
10 fstat(src, &stat_buf);
11 /* открыть файл назначения */
12 dest = open(argv[2], O_WRONLY|O_CREAT, stat_buf.st_mode);
13 /* скопировать файл */
14 sendfile (dest, src, &offset, stat_buf.st_size);
15 /* закрыть файлы и выйти */
16 close(dest);
17 close(src);
18 }
В строке 8 открывается исходный файл, имя которого передается программе, как первый аргумент командной строки. В строке 10 программа получает дополнительные сведения о файле, с помощью fstat, таким образом мы получаем длину файла и права доступа к нему, которые понадобятся нам позднее. В строке 12 открывается на запись файл назначения. В строке 14 производится вызов sendfile, которому передаются файловые дескрипторы, смещение от начала исходного файла (в данном случае -- 0) и количество байт для копирования, которое соответствует размеру исходного файла. И в строках 16 и 17, после выполнения копирования, файлы закрываются.
Функции для преобразования из хостового порядка байт в сетевой и наоборот в стандарте POSIX.
Выше было отмечено, что преобразование значений типов uint16_t и uint32_t из хостового порядка байт в сетевой выполняется посредством функций htons() и htonl(); функции ntohs() и ntohl() осуществляют обратную операцию (см. листинг 11.6).
#include <arpa/inet.h>
uint32_t htonl (uint32_t hostlong);
uint16_t htons (uint16_t hostshort);
uint32_t ntohl (uint32_t netlong);
uint16_t ntohs (uint16_t netshort);
Функции для работы с базой данных узлов сети в стандарте POSIX.
Данные о хостах как узлах сети хранятся в сетевой базе, последовательный доступ к которой обслуживается функциями sethostent(), gethostent() и endhostent()
#include <netdb.h>
void sethostent (int stayopen);
struct hostent *gethostent (void);
void endhostent (void);
Описание функций последовательного доступа к сетевой базе данных о хостах - узлах сети.
Функция sethostent() устанавливает соединение с базой, остающееся открытым после вызова gethostent(), если значение аргумента stayopen отлично от нуля. Функция gethostent() последовательно читает элементы базы, возвращая результат в структуре типа hostent, содержащей по крайней мере следующие поля.
char *h_name;
/* Официальное имя хоста */
char **h_aliases;
/* Массив указателей на альтернативные */
/* имена хоста, завершаемый пустым */
/* указателем */
int h_addrtype;
/* Тип адреса хоста */
int h_length;
/* Длина в байтах адреса данного типа */
char **h_addr_list;
/* Массив указателей на сетевые адреса */
/* хоста, завершаемый пустым указателем */
Функция endhostent() закрывает соединение с базой.
В пример показана программа, осуществляющая последовательный просмотр сетевой базы данных о хостах - узлах сети,
#include <stdio.h>
#include <netdb.h>
int main (void) {
struct hostent *pht;
char *pct;
int i, j;
sethostent (1);
while ((pht = gethostent ()) != NULL) {
printf ("Официальное имя хоста: %s\n", pht->h_name);
printf ("Альтернативные имена:\n");
for (i = 0; (pct = pht->h_aliases [i]) != NULL; i++) {
printf (" %s\n", pct);
}
printf ("Тип адреса хоста: %d\n", pht->h_addrtype);
printf ("Длина адреса хоста: %d\n", pht->h_length);
printf ("Сетевые адреса хоста:\n");
for (i = 0; (pct = pht->h_addr_list [i]) != NULL; i++) {
for (j = 0; j < pht->h_length; j++) {
printf (" %d", (unsigned char) pct [j]);
}
printf ("\n");
}
}
endhostent ();
return 0;
}
Функции для работы с базой данных сетевых сервисов в стандарте POSIX.
Еще одно проявление той же логики работы - база данных сетевых сервисов
#include <netdb.h>
void setservent (int stayopen);
struct servent *getservent (void);
struct servent *getservbyname
(const char *name, const char *proto);
struct servent *getservbyport
(int port, const char *proto);
void endservent (void);
Листинг 11.16. Описание функций доступа к базе данных сетевых сервисов.
Обратим внимание на то, что в данном случае можно указывать второй аргумент поиска - имя протокола. Впрочем, значение аргумента proto может быть пустым указателем, и тогда поиск производится только по имени сервиса (функция getservbyname()) или номеру порта ( getservbyport()), который должен быть задан с сетевым порядком байт.
Структура типа servent содержит по крайней мере следующие поля.
char *s_name;
/* Официальное имя сервиса */
char **s_aliases;
/* Массив указателей на альтернативные */
/* имена сервиса, завершаемый пустым */
/* указателем */
int s_port;
/* Номер порта, соответствующий сервису */
/* (в сетевом порядке байт) */
char *s_proto;
/* Имя протокола для взаимодействия с */
/* сервисом */
В пример 11.17 приведен пример программы, использующей функции доступа к базе данных сервисов, а также функции преобразования между хостовым и сетевым порядками байт
#include <stdio.h>
#include <netdb.h>
int main (void) {
struct servent *pht;
char *pct;
int i;
setservent (1);
while ((pht = getservent ()) != NULL) {
printf ("Официальное имя сервиса: %s\n", pht->s_name);
printf ("Альтернативные имена:\n");
for (i = 0; (pct = pht->s_aliases [i]) != NULL; i++) {
printf (" %s\n", pct);
}
printf ("Номер порта: %d\n", ntohs ((in_port_t) pht->s_port));
printf ("Имя протокола: %s\n\n", pht->s_proto);
}
if ((pht = getservbyport (htons ((in_port_t) 21), "udp")) != NULL) {
printf ("Официальное имя сервиса: %s\n", pht->s_name);
printf ("Альтернативные имена:\n");
for (i = 0; (pct = pht->s_aliases [i]) != NULL; i++) {
printf (" %s\n", pct);
}
printf ("Номер порта: %d\n", ntohs ((in_port_t) pht->s_port));
printf ("Имя протокола: %s\n\n", pht->s_proto);
} else {
perror ("GETSERVBYPORT");
}
if ((pht = getservbyport (htons ((in_port_t) 21), (char *) NULL)) != NULL) {
printf ("Официальное имя сервиса: %s\n", pht->s_name);
printf ("Альтернативные имена:\n");
for (i = 0; (pct = pht->s_aliases [i]) != NULL; i++) {
printf (" %s\n", pct);
}
printf ("Номер порта: %d\n", ntohs ((in_port_t) pht->s_port));
printf ("Имя протокола: %s\n\n", pht->s_proto);
} else {
perror ("GETSERVBYPORT");
}
endservent ();
return 0;
}
Функции для работы с базой данных сетевых протоколов в стандарте POSIX.
Точно такой же программный интерфейс предоставляет база данных сетевых протоколов
#include <netdb.h>
void setprotoent (int stayopen);
struct protoent *getprotoent (void);
struct protoent *getprotobyname
(const char *name);
struct protoent *getprotobynumber (int proto);
void endprotoent (void);
Описание функций доступа к базе данных сетевых протоколов.
Структура типа protoent содержит по крайней мере следующие поля.
char *p_name;
/* Официальное имя протокола */
char **p_aliases;
/* Массив указателей на альтернативные */
/* имена протокола, завершаемый пустым */
/* указателем */
int p_proto;
/* Номер протокола */
В пример 11.14 показан пример программы, осуществляющей последовательный и случайный доступ к базе данных сетевых протоколов
#include <stdio.h>
#include <netdb.h>
int main (void) {
struct protoent *pht;
char *pct;
int i;
setprotoent (1);
while ((pht = getprotoent ()) != NULL) {
printf ("Официальное имя протокола: %s\n", pht->p_name);
printf ("Альтернативные имена:\n");
for (i = 0; (pct = pht->p_aliases [i]) != NULL; i++) {
printf (" %s\n", pct);
}
printf ("Номер протокола: %d\n\n", pht->p_proto);
}
if ((pht = getprotobyname ("ipv6")) != NULL) {
printf ("Номер протокола ipv6: %d\n\n", pht->p_proto);
} else {
fprintf (stderr, "Протокол ip в базе не найден\n");
}
if ((pht = getprotobyname ("IPV6")) != NULL) {
printf ("Номер протокола IPV6: %d\n\n", pht->p_proto);
} else {
fprintf (stderr, "Протокол IPV6 в базе не найден\n");
}
endprotoent ();
return 0;
}
Листинг 11.14. Пример программы, осуществляющей последовательный и случайный доступ к базе данных сетевых протоколов.
Функции для работы с базой данных сетей в стандарте POSIX.
Наряду с базой данных хостов (узлов сети) поддерживается база данных сетей с аналогичной логикой работы и набором функций (см. пример 11.12).
#include <netdb.h>
void setnetent (int stayopen);
struct netent *getnetent (void);
struct netent *getnetbyaddr (uint32_t net,
int type);
struct netent *getnetbyname (const char *name);
void endnetent (void);
Листинг 11.12. Описание функций доступа к базе данных сетей.
Функция getnetent() обслуживает последовательный доступ к базе, getnetbyaddr() осуществляет поиск по адресному семейству (аргумент type) и номеру net сети, а getnetbyname() выбирает сеть с заданным (официальным) именем. Структура типа netent, указатель на которую возвращается в качестве результата этих функций, согласно стандарту POSIX-2001, должна содержать по крайней мере следующие поля.
char *n_name;
/* Официальное имя сети *
char **n_aliases;
/* Массив указателей на альтернативные */
/* имена сети, завершаемый пустым указателем */
int n_addrtype;
/* Адресное семейство (тип адресов) сети */
uint32_t n_net;
/* Номер сети (в хостовом порядке байт) */
Программирование на уровне TLI. Функции установления связи.
Интерфейс транспортного уровня (TLI) был разработан как альтернатива более раннему socket-интерфейсу. Он базируется на средстве ввода-вывода STREAMS, первоначально реализованном в версиях System V операционной системы UNIX. Основное достоинство STREAMS заключается в гибкой, управляемой пользователем многослойности модулей, по конвейерному принципу обрабатывающих информацию, передаваемую от прикладной программы к физической среде хранения/пересылки и обратно. Это делает STREAMS удобным инструментом для реализации стеков протоколов сетевого взаимодействия различной архитектуры (OSI, TCP/IP, DECnet, SNA, XNS и т.п.).
Хотя все современные реализации и версии ОС UNIX поддерживают socket-интерфейс по крайней мере для TCP/IP, для вновь разрабатываемых сетевых приложений настоятельно рекомендуется использовать TLI, что обеспечит их независимость от используемых сетевых протоколов.
С точки зрения прикладного программиста логика TLI очень похожа на логику socket-интерфейса (даже имена функций первого образованы от имен системных вызовов второго добавлением префикса "t_"). TLI реализован в виде библиотеки функций языка программирования СИ, разделенных (как и в случае с socket-интерфейсом) на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Основу концепции TLI составляют три базовых понятия:
поставщик транспортных услуг
пользователь транспорта
транспортная точка.
Поставщиком транспортных услуг (transport provider) называется набор модулей, реализующих какой-либо конкретный стек протоколов сетевого взаимодействия (в данном учебном пособии - TCP/IP) и обеспечивающий сервис транспортного уровня модели OSI [REF].
Пользователем транспорта (transport user) является любая прикладная программа, использующая сервис, предоставляемый ПТС на локальном узле сети.
Транспортная точка (transport endpoint) - абстрактное понятие (аналогичное socket'у), используемое для обозначения канала связи между пользователем транспорта и поставщиком транспортных услуг на локальном узле сети. Транспортная точка имеем уникальный для всей сети транспортный адрес (для сетей TCP/IP этот адрес образуется триадой: адрес узла сети, номер порта, используемый протокол транспортного уровня). Для ссылки на транспортные точки в функциях TLI используются их дескрипторы, подобные дескрипторам обычных файлов и socket'ов ОС UNIX.
Функции установления связи
Для установления логического соединения "клиент-сервер" в TLI используются функции t_listen, t_accept (на стороне сервера), t_connect (на стороне клиента), а также ряд других.
Ожидание запроса на соединение
Ожидание в программе-сервере запроса от клиента на соединение реализуется функцией t_listen, имеющей следующий вид
#include <tiuser.h>
int t_listen (fd, call)
int fd;
struct t_call *call;
Аргумент call должен указывать на область памяти под структуру t_call, в которой после успешного выполнения функции будет размещена следующая информация: транспортный адрес (call->addr) транспортной точки програм- мы-клиента, через которую она делает запрос на установление соединения; необязательные характеристики соединения (call->opt); необязательные данные (call->udata), передаваемые клиентом серверу вместе с запросом на соединение (однако, не любой поставщик транспортных услуг обеспечивает возможность передачи данных вместе с запросом на соединение); уникальный идентификатор соединения (call->sequence), имеющий смысл для программы-сервера только, если она допускает обслуживание одновременно нескольких соединений с нею.
Функция t_listen извлекает из очереди запросов на установление соединения первый запрос и возвращает в области памяти, указываемой аргументом call, описанную выше информацию клиента. Если очередь запросов на момент выполнения t_listen пуста, то программа переходит в состояние ожидания поступления запросов от клиентов на неопределенное время (хотя такое поведение t_listen можно и изменить).
При успешном завершении функция t_listen возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Примечание. Обратите внимание: схожие по названию функция t_listen и системный вызов listen из socket-интерфейса имеют различный смысл.
Прием запроса на соединение
Прием в программе-сервере запроса от клиента на соединение, "услышанного" функцией t_listen, реализуется функцией t_accept, имеющей следующий вид
#include <tiuser.h>
int t_accept (fd, resfd, call)
int fd;
int resfd;
struct t_call *call;
Аргумент fd задает дескриптор транспортной точки, через которую ранее выполненная функция t_listen получила запрос на соединение.
Аргумент resfd задает дескриптор еще одной транспортной точки, созданной с теми же свойствами, что и точка, задаваемая аргументом fd, но имеющей другой транспортный адрес.
Аргумент call указывает на структуру данных типа t_call, поля которой должны содержать следующую информацию: транспортный адрес (call->addr) транспортной точки программы-клиента, через которую она сделала запрос на установление соединения; необязательные характеристики соединения (call->opt); необязательные данные (call->udata), возвращаемые сервером клиенту вместе с подтверждением установления соединения (однако, не любой поставщик транспортных услуг обеспечивает возможность такой передачи данных); уникальный идентификатор (call->sequence), присвоенный соединению функцией t_listen.
После успешного выполнения в программе-сервере функции t_accept устанавливается логическое соединение с клиентом и становится возможным обмен данными с ним через дескриптор resfd.
В типичной программе сервере транспортная точка с дескриптором resfd создается и активизируется после успешного завершения функции t_listen с помощью функций t_open и t_bind. Допустимой является ситуация, когда resfd = fd, но тогда программа-сервер до момента закрытия соединения с клиентом теряет возможность получать и ставить в очередь запросы на соединение от других клиентов.
При успешном завершении функция t_accept возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Программа-сервер может отказаться от установления соединения с клиентом, используя функцию t_snddis.
Примечание. Обратите внимание: схожие по названию функция t_accept и системный вызов accept из socket-интерфейса имеют различный смысл.
Отвергнуть запрос на соединение
Программа-сервер может отвергнуть запрос клиента на соединение, "услышанный" функцией t_listen, используя функцию t_snddis, имеющую следующий вид
#include <tiuser.h>
int t_snddis (fd, call)
int fd;
struct t_call *call;
Аргумент fd задает дескриптор транспортной точки, через которую ранее выполненная функция t_listen получила запрос на соединение.
Аргумент call указывает на структуру данных типа t_call, поля которой должны содержать следующую информацию: уникальный идентификатор (call->sequence), присвоенный соединению функцией t_listen; необязательные данные (call->udata), возвращаемые сервером клиенту вместе с информацией об отклонении запроса на соединения (однако, не любой поставщик транспортных услуг обеспечивает возможность такой передачи данных); поля call->addr и call->opt не используются.
При успешном завершении функция t_snddis возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Примечание. Функция t_snddis используется также для "экстренного" закрытия ранее установленного соединения, при этом аргумент call формируется несколько иначе.
Запрос на установление соединения
Для обращения программы-клиента к серверу с запросом на установление логической соединения используется функция t_connect, имеющая следующий вид
#include <tiuser.h>
int t_connect (fd, sndcall, rcvcall)
int fd;
struct t_call *sndcall;
struct t_call *rcvcall;
Аргумент fd задает дескриптор транспортной точки, созданной ранее с помощью функции t_open и активизированной функцией t_bind.
Аргумент sndcall указывает на структуру данных типа t_call, в которой функции передается следующая информация: транспортный адрес (sndcall->addr) транспортной точки программы-сервера, к которой клиент делает запрос на установление соединения; необязательные характеристики соединения (sndcall->opt); необязательные данные (sndcall->udata), передаваемые клиентом серверу вместе с запросом на соединение (однако, не любой постав- щик транспортных услуг обеспечивает возможность передачи данных вместе с запросом на соединение).
Поле sndcall->sequence не используется и может принимать произвольное значение.
Аргумент rcvcall должен указывать на область памяти под структуру t_call, в которой после успешного выполнения функции будет размещена следующая информация: транспортный адрес (rcvcall->addr) транспортной точки в программе-сервере, с которой установлено соединение; необязательные характеристики соединения (rcvcall->opt); необязательные данные (rcvcall->udata), передаваемые клиенту сервером (посредством функции t_accept) вместе с подтверждением соединения (однако, не любой поставщик транспортных услуг обеспечивает возможность такой передачи данных); поле rcvcall->sequence не используется.
При успешном установлении соединения функция t_connect возвращает ноль. Если же сервер отверг запрос на соединение, то t_connect возвращает "-1" и устанавливает код ошибки TLOOK в глобальной переменной t_errno.
Программирование на уровне TLI. Функции локального управления.
Интерфейс транспортного уровня (TLI) был разработан как альтернатива более раннему socket-интерфейсу. Он базируется на средстве ввода-вывода STREAMS, первоначально реализованном в версиях System V операционной системы UNIX. Основное достоинство STREAMS заключается в гибкой, управляемой пользователем многослойности модулей, по конвейерному принципу обрабатывающих информацию, передаваемую от прикладной программы к физической среде хранения/пересылки и обратно. Это делает STREAMS удобным инструментом для реализации стеков протоколов сетевого взаимодействия различной архитектуры (OSI, TCP/IP, DECnet, SNA, XNS и т.п.).
Хотя все современные реализации и версии ОС UNIX поддерживают socket-интерфейс по крайней мере для TCP/IP, для вновь разрабатываемых сетевых приложений настоятельно рекомендуется использовать TLI, что обеспечит их независимость от используемых сетевых протоколов.
С точки зрения прикладного программиста логика TLI очень похожа на логику socket-интерфейса (даже имена функций первого образованы от имен системных вызовов второго добавлением префикса "t_"). TLI реализован в виде библиотеки функций языка программирования СИ, разделенных (как и в случае с socket-интерфейсом) на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Основу концепции TLI составляют три базовых понятия:
поставщик транспортных услуг
пользователь транспорта
транспортная точка.
Поставщиком транспортных услуг (transport provider) называется набор модулей, реализующих какой-либо конкретный стек протоколов сетевого взаимодействия (в данном учебном пособии - TCP/IP) и обеспечивающий сервис транспортного уровня модели OSI [REF].
Пользователем транспорта (transport user) является любая прикладная программа, использующая сервис, предоставляемый ПТС на локальном узле сети.
Транспортная точка (transport endpoint) - абстрактное понятие (аналогичное socket'у), используемое для обозначения канала связи между пользователем транспорта и поставщиком транспортных услуг на локальном узле сети. Транспортная точка имеем уникальный для всей сети транспортный адрес (для сетей TCP/IP этот адрес образуется триадой: адрес узла сети, номер порта, используемый протокол транспортного уровня). Для ссылки на транспортные точки в функциях TLI используются их дескрипторы, подобные дескрипторам обычных файлов и socket'ов ОС UNIX.
К функциям локального управления относятся функции создания/удаления транспортной точки (t_open/t_close), назначения/снятия транспортного адреса для транспортной точки (t_bind/t_unbind), выделения/освобождения оперативной памяти под структуры данных, используемые TLI (t_alloc/t_free) и другие.
Выделение памяти под TLI-структуры
Динамическое выделение оперативной памяти под различные структуры данных, используемые TLI, удобно осуществлять функцией t_alloc, имеющей следующий вид
#include <tiuser.h>
char *t_alloc (fd, structType, fields)
int fd;
int structType;
int fields;
Аргумент fd задает дескриптор ранее созданной функцией t_open транспортной точки.
Аргумент structType задает тип структуры данных, под которую необходимо выделить память, и может принимать следующие значения:
T_INFO для struct t_info;
T_BIND для struct t_bind;
T_CALL для struct t_call;
T_UNITDATA для struct t_unitdata;
T_DIS для struct t_discon и др.
Каждая из указанных структур (исключая struct t_info) содержит одно или несколько полей типа struct netbuf. Для каждого из таких полей можно также потребовать динамического выделения памяти. Аргумент fields конкретизирует это требование, допуская задание fields в виде побитового ИЛИ из следующих значений:
T_ALL для выделения памяти для всех полей типа struct netbuf, имеющихся в структуре;
T_ADDR для поля addr;
T_UDATA для поля udata;
T_OPT для поля opt.
При успешном завершении функция возвращает указатель на размещенную структуру данных, в противном случае - NULL.
Освобождение памяти
Для освобождения оперативной памяти, динамически выделенной под различные структуры данных, используемые TLI, удобно использовать функцию t_free, имеющую следующий вид
#include<tiuser.h>
int t_free (ptr, structType)
char *ptr;
int structType;
Аргумент ptr указывает освобождаемую область памяти.
Аргумент structType задает тип структуры данных, занимающей память. Этот аргумент может принимать те же значения, что и аналогичный аргумент функции t_alloc.
Функция t_free освобождает оперативную память, занятую собственно структурой и всеми ее буферами типа struct netbuf.
При успешном завершении функция t_free возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Создание транспортной точки
Создание транспортной точки осуществляется функцией t_open, имеющей следующий вид
#include <tiuser.h>
#include <fcntl.h>
int t_open (path, oflags, info)
char *path;
int oflags;
struct t_info *info;
Аргумент path задает имя файла (располагающегося, как правило, в каталоге /dev), определяющего используемого поставщика транспортных услуг. Для стека протоколов TCP/IP такими файлами могут быть /dev/tcp (режим с установлением логического соединения) и /dev/udp (режим без установления логического соединения).
Аргумент oflags задает флаги открытия транспортной точки. Допустимые значения флагов - те же, что и для обычного системного вызова open. Если транспортная точка создается для двустороннего обмена информацией через нее, то значением oflags должно быть O_RDWR.
Аргумент info должен указывать на структуру данных типа struct t_info, поля которой заполняются функцией t_open при ее удачном завершении информацией о характеристиках используемого поставщика транспортных услуг. Если info задан как NULL, то информация о протоколе не возвращается. Для выделения памяти под структуру удобно использовать функцию t_alloc [REF].
При успешном завершении функция t_open возвращает дескриптор транспортной точки, используемый для ссылки на нее в большинстве функций TLI. Дескриптор транспортной точки аналогичен дескриптору socket'а. При обнаружении ошибки в ходе своей работы функция возвращает число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Назначение транспортного адреса
Для назначения транспортного адреса транспортной точке и ее активизации используется функция t_bind, имеющая следующий вид
#include <tiuser.h>
int t_bind (fd, req, ret)
int fd;
struct t_bind *req;
struct t_bind *ret;
Аргумент fd задает дескриптор транспортной точки, созданной ранее с помощью функции t_open.
Аргумент req указывает на структуру t_bind, которая должна определять требуемый транспортный адрес для точки (поле req->addr) и максимальное количество запросов на соединение (поле req->qlen), одновременно обрабатываемых программой. Для программы-клиента поле req->qlen должно быть нулевым, а для программ-серверов, работающих в режиме с установлением логического соединения, оно, как правило, содержит 1 (необходимо учитывать, что не все поставщики транспортных услуг могут обеспечивать одновременную обработку сразу нескольких соединений к одной транспортной точке). Для программ-серверов, функционирующих в режиме без установления логического соединения, поле req->qlen смысла не имеет.
Если аргумент req имеет значение NULL, то функция t_bind сама назначит произвольный транспортный адрес для точки.
Аргумент ret должен указывать на область памяти под структуру t_bind, в которой после успешного выполнения функции будет размещена информация о транспортном адресе, назначенном транспортной точке. Если этот аргумент равен NULL, то информация о назначенном транспортном адресе возвращена не будет.
При успешном завершении функция t_bind возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Снятие транспортного адреса
Для снятия транспортного адреса у транспортной точки используется функция t_unbind, имеющая следующий вид
#include <tiuser.h>
int t_unbind (fd)
int fd;
Аргумент fd задает дескриптор транспортной точки, которой ранее с помощью функции t_bind был назначен транспортный адрес.
После выполнения функции t_unbind для транспортной точки обмен данными через нее становится невозможным.
При успешном завершении функция t_unbind возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Удаление транспортной точки
Удаление транспортной точки осуществляется функцией t_close, имеющей следующий вид
#include <tiuser.h>
int t_close (fd)
int fd;
Аргумент fd задает дескриптор транспортной точки, созданной ранее с помощью функции t_open.
При успешном завершении функция t_close возвращает ноль, иначе - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Программирование на уровне TLI. Функции обмена данными (ввода/вывода).
Интерфейс транспортного уровня (TLI) был разработан как альтернатива более раннему socket-интерфейсу. Он базируется на средстве ввода-вывода STREAMS, первоначально реализованном в версиях System V операционной системы UNIX. Основное достоинство STREAMS заключается в гибкой, управляемой пользователем многослойности модулей, по конвейерному принципу обрабатывающих информацию, передаваемую от прикладной программы к физической среде хранения/пересылки и обратно. Это делает STREAMS удобным инструментом для реализации стеков протоколов сетевого взаимодействия различной архитектуры (OSI, TCP/IP, DECnet, SNA, XNS и т.п.).
Хотя все современные реализации и версии ОС UNIX поддерживают socket-интерфейс по крайней мере для TCP/IP, для вновь разрабатываемых сетевых приложений настоятельно рекомендуется использовать TLI, что обеспечит их независимость от используемых сетевых протоколов.
С точки зрения прикладного программиста логика TLI очень похожа на логику socket-интерфейса (даже имена функций первого образованы от имен системных вызовов второго добавлением префикса "t_"). TLI реализован в виде библиотеки функций языка программирования СИ, разделенных (как и в случае с socket-интерфейсом) на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Основу концепции TLI составляют три базовых понятия:
поставщик транспортных услуг
пользователь транспорта
транспортная точка.
Поставщиком транспортных услуг (transport provider) называется набор модулей, реализующих какой-либо конкретный стек протоколов сетевого взаимодействия (в данном учебном пособии - TCP/IP) и обеспечивающий сервис транспортного уровня модели OSI [REF].
Пользователем транспорта (transport user) является любая прикладная программа, использующая сервис, предоставляемый ПТС на локальном узле сети.
Транспортная точка (transport endpoint) - абстрактное понятие (аналогичное socket'у), используемое для обозначения канала связи между пользователем транспорта и поставщиком транспортных услуг на локальном узле сети. Транспортная точка имеем уникальный для всей сети транспортный адрес (для сетей TCP/IP этот адрес образуется триадой: адрес узла сети, номер порта, используемый протокол транспортного уровня). Для ссылки на транспортные точки в функциях TLI используются их дескрипторы, подобные дескрипторам обычных файлов и socket'ов ОС UNIX.
Функции обмена данными
В режиме с установлением логического соединения для обмена данными используются функции t_snd и t_rcv.
В режиме без установления логического соединения для обмена данными используются функции t_sndudata и t_rcvudata.
Посылка данных в режиме с установлением соединения
Для посылки данных партнеру по сетевому взаимодействию в режиме с установлением логического соединения используется функция t_snd, имеющая следующий вид
#include <tiuser.h>
int t_snd (fd, buf, len, flags)
int fd;
char *buf;
unsigned int len;
int flags;
Аргумент fd задает дескриптор транспортной точки, через которую посылаются данные.
Аргумент buf указывает на область памяти, содержащую передаваемые данные.
Аргумент len задает длину (в байтах) передаваемых данных.
Аргумент flags модифицирует исполнение функции t_snd. При нулевом значении этого аргумента функция t_snd полностью аналогична системному вызову write.
При успешном завершении t_snd возвращает количество переданных из области, указанной аргументом buf, байт данных. Если канал данных, определяемый дескриптором fd, оказывается "переполненным", то t_snd переводит программу в состояние ожидания до момента его освобождения.
Прием данных в режиме с установлением соединения
Для получения данных от партнера по сетевому взаимодействию в режиме с установлением логического соединения используется функция t_rcv, имеющая следующий вид
#include <tiuser.h>
int t_rcv (fd, buf, len, flags)
int fd;
char *buf;
unsigned int len;
int flags;
Аргумент fd задает дескриптор транспортной точки, через которую принимаются данные.
Аргумент buf указывает на область памяти, предназначенную для размещения принимаемых данных.
Аргумент len задает длину (в байтах) этой области.
Аргумент flags модифицирует исполнение системного вызова recv. При нулевом значении этого аргумента вызов t_rcv полностью аналогичен системному вызову read.
При успешном завершении t_rcv возвращает количество принятых в область, указанную аргументом buf, байт данных. Если канал данных, определяемый дескриптором fd, оказывается "пустым", то t_rcv переводит программу в состояние ожидания до момента появления в нем данных.
Посылка данных в режиме без установления соединения
Для посылки данных, составляющих дейтаграмму, партнеру по сетевому взаимодействию в режиме без установления логического соединения используется функция t_sndudata, имеющая следующий вид
#include <tiuser.h>
int t_sndudata (fd, unitdata)
int fd;
struct t_unitdata *unitdata;
Аргумент fd задает дескриптор транспортной точки, через которую посылаются данные.
Аргумент unitdata указывает на структуру данных типа t_unitdata, в которой функции передается следующая информация: транспортный адрес (unitdata->addr) транспортной точки программы-партнера по взаимодействию, которой посылается дейтаграмма; необязательные характеристики соединения (unitdata->opt); собственно данные (unitdata->udata), составляющие дейтаграмму, передаваемую партнеру по взаимодействию.
Если канал данных, определяемый дескриптором fd, оказывается "переполненным", то t_sndudata переводит программу в состояние ожидания до момента его освобождения.
При успешном выполнении функция t_sndudata возвращает ноль, в противном случае - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Прием данных в режиме без установления соединения
Для получения данных, составляющих дейтаграмму, от партнера по сетевому взаимодействию в режиме без установления логического соединения используется функция t_rcvudata, имеющая следующий вид
#include <tiuser.h>
int t_rcvudata (fd, unitdata, flags)
int fd;
struct t_unitdata *unitdata;
int *flags;
Аргумент fd задает дескриптор транспортной точки, через которую посылаются данные.
Аргумент unitdata указывает на структуру данных типа t_unitdata, в которой функции передается следующая информация: транспортный адрес (unitdata->addr) транспортной точки программы-партнера по взаимодействию, которой посылается дейтаграмма; необязательные характеристики соединения (unitdata->opt); собственно данные (unitdata->udata), составляющие дейтаграмму, передаваемую партнеру по взаимодействию.
Аргумент unitdata должен указывать на область памяти под структуру t_unitdata, в которой после успешного выполнения функции будет размещена следующая информация: транспортный адрес (unitdata->addr) транспортной точки в программе-партнере по взыимодействию, отправившей дейтаграмму; необязательные характеристики соединения (unitdata->opt); собственно данные (unitdata->udata), составляющие дейтаграмму, принимаемую от партнера по взаимодействию.
Аргумент flags должен указывать область памяти (типа int), в которой функция t_rcvudata может установить флаг T_MORE, сигнализирующий о том, что в канале передачи остались еще данные, составляющие дейтаграмму. Такая ситуация может возникнуть в случае, если размер буфера в unitdata->udata недостаточен для размещения в нем сразу всей дейтаграммы.
Если канал данных, определяемый дескриптором fd, оказывается "пустым", то t_rcvudata переводит программу в состояние ожидания до момента появления в нем данных.
При успешном выполнении функция t_rcvudata возвращает ноль, в противном случае - число "-1" и устанавливает код ошибки в глобальной переменной t_errno.
Программирование на уровне TLI. Функции закрытия связи.
Интерфейс транспортного уровня (TLI) был разработан как альтернатива более раннему socket-интерфейсу. Он базируется на средстве ввода-вывода STREAMS, первоначально реализованном в версиях System V операционной системы UNIX. Основное достоинство STREAMS заключается в гибкой, управляемой пользователем многослойности модулей, по конвейерному принципу обрабатывающих информацию, передаваемую от прикладной программы к физической среде хранения/пересылки и обратно. Это делает STREAMS удобным инструментом для реализации стеков протоколов сетевого взаимодействия различной архитектуры (OSI, TCP/IP, DECnet, SNA, XNS и т.п.).
Хотя все современные реализации и версии ОС UNIX поддерживают socket-интерфейс по крайней мере для TCP/IP, для вновь разрабатываемых сетевых приложений настоятельно рекомендуется использовать TLI, что обеспечит их независимость от используемых сетевых протоколов.
С точки зрения прикладного программиста логика TLI очень похожа на логику socket-интерфейса (даже имена функций первого образованы от имен системных вызовов второго добавлением префикса "t_"). TLI реализован в виде библиотеки функций языка программирования СИ, разделенных (как и в случае с socket-интерфейсом) на четыре группы:
локального управления;
установления связи;
обмена данными (ввода/вывода);
закрытия связи.
Основу концепции TLI составляют три базовых понятия:
поставщик транспортных услуг
пользователь транспорта
транспортная точка.
Поставщиком транспортных услуг (transport provider) называется набор модулей, реализующих какой-либо конкретный стек протоколов сетевого взаимодействия (в данном учебном пособии - TCP/IP) и обеспечивающий сервис транспортного уровня модели OSI [REF].
Пользователем транспорта (transport user) является любая прикладная программа, использующая сервис, предоставляемый ПТС на локальном узле сети.
Транспортная точка (transport endpoint) - абстрактное понятие (аналогичное socket'у), используемое для обозначения канала связи между пользователем транспорта и поставщиком транспортных услуг на локальном узле сети. Транспортная точка имеем уникальный для всей сети транспортный адрес (для сетей TCP/IP этот адрес образуется триадой: адрес узла сети, номер порта, используемый протокол транспортного уровня). Для ссылки на транспортные точки в функциях TLI используются их дескрипторы, подобные дескрипторам обычных файлов и socket'ов ОС UNIX.
TLI поддерживает две процедуры закрытия связи в режиме с установлением логического соединения: упорядоченную и экстренную.
Упорядоченная процедура реализуется парой функций t_sndrel и t_rcvrel и обеспечивает надежную доставку к партнеру по взаимодействию всех данных, планируемых для передачи. Однако не все поставщики транспортных услуг поддерживают эту процедура закрытия связи.
Экстренная процедура закрытия логического соединения реализуется функциями t_snddis и t_rcvdis.
Средства вызова удаленных процедур (RPC). Функции клиента.
Средства вызова удаленных процедур (RPC) является составной частью более общего средства, называемого Open Network Computing (ONC), разработанного фирмой Sun Microsystems и получившего всеобщее признание в качестве промышленного стандарта.
ONC помимо RPC включает в себя средства внешнего представления данных (XDR), необходимые для организации обмена информацией в гетерогенных сетях, включающих в себя ЭВМ различной архитектуры, и средства монтирования удаленных файловых систем (NFS), обеспечивающее доступ пользователям локального узла сети к файлам, физически расположенным на удаленных узлах, как к файлам локальным.
Средство RPC реализует модель "клиент-сервер", где роль клиента играет прикладная программа, обращающаяся к набору процедур (функций), исполняемых на удаленном узле в качестве сервера. RPC предоставляет прикладным программистам сервис более высокого уровня, чем ранее рассмотренных два, т.к. обращение за услугой к удаленным процедурам выполняется в привычной для программиста манере вызова "локальной" функции языка программирования СИ. RPC реализовано, как правило, на базе socket-интерфейса и/или TLI. При пересылке данных между узлами сети в RPC для их внешнего представления используется стандарт XDR.
Средство RPC предоставляет программистам сервис трех уровней:
препроцессор rpcgen, преобразующий исходные тексты "монолитных" программ на языке программирования СИ в исходные тексты программы-клиента и программы-сервера по спецификации программиста;
библиотека функций вызова удаленных процедур по их идентификаторам;
библиотека низкоуровневых функций доступа к внутренним механизмам RPC и ниже лежащим протоколам транспортного уровня.
В данном учебном учебном пособии рассматриваются только средства RPC среднего уровня.
Согласно идеологии RPC все процедуры (функции) некоторого распределенного приложения, планируемые к исполнению на одном и том же удаленном узле вычислительной сети, объединяются в единый модуль, оформляемый в виде исполняемого файла и характеризующегося уникальным "номером программы". Допустимо иметь несколько вариантов такого модуля, идентифицируемых уникальным "номером версии". Каждая процедура в составе модуля имеет уникальный "номер процедуры". Таким образом, для однозначной идентификации конкретной процедуры-сервера используется четверка:
имя узла сети;
номер программы на этом узле;
номер версии программы;
номер процедуры в программе.
Каждая процедура-сервер прежде, чем она станет доступной для обращения к ней, должна быть зарегистрирована на соответствующем узле сети. Регистрация процедуры делает ее известной под соответствующими номерами (программы, версии и, собственно, процедуры) сетевому демону portmapper на локальном узле сети. Удаленный RPC-клиент, обращаясь скрытно от пользователя к этому демону, может получить точный сетевой адрес процедуры, который и будет использовать в дальнейшем для прямых обращений к процедуре-серверу.
Процедура-сервер, создаваемая средствами RPC любого уровня, должна иметь единственный аргумент и единственный результат. Это ограничение заставляет прикладного программиста в случае необходимости передачи в процедуру (или возврата из нее) нескольких аргументов (результатов) компоновать их в сложные агрегаты данных (структуры, массивы, списки и т.п.).
Для создания распределенных приложений средствами RPC среднего уровня достаточно использовать три функции: registerrpc, svc_run (на стороне сервера) и callrpc (на стороне клиента).
Примечание. Столь малое количество функций объясняется тем, что средний уровень средств RPC беден с точки зрения возможностей выбора используемого транспорта данных, управления количеством ретрансляций данных, назначения тайм-аутов, организации асинхронной обработки и т.п.
Программисты распределенных приложений кроме собственно функций RPC обязаны также использовать функции преобразования данных во внешнее представление согласно стандарту XDR (так называемые XDR-функции).
Регистрации процедуры-сервера
Регистрация процедуры в качестве сервера на узле сети выполняется функцией registerrpc, имеющей следующий вид
#include <sys/types.h>
#include <rpc/rpc.h>
int registerrpc (prognum, vernum, procnum, procname,
inproc, outproc)
u_long prognum;
u_long vernum;
u_long procnum;
char *(*procname) ();
xdrproc_t inproc;
xdrproc_t outproc;
Аргументы prognum, vernum и procnum задают номера программы, версии и процедуры соответственно. Номера версии и процедуры назначаются программистом произвольно. Номер же программы, находящейся в стадии разработки, должен назначаться из диапазона 0x20000000...0x3fffffff.
Аргумент procname задает функцию языка программирования СИ, регистрируемую в качестве сервера. Эта функция (процедура) вызывается с указателем на ее аргумент и должна возвращать указатель на свой результат, располагаемый в статической или динамически выделенной (функциями malloc или calloc) памяти. Для хранения результата нельзя использовать автоматически выделяемую память (напоминаем, что локальные переменные функций располагаются именно в такой памяти).
Аргументы inproc и outproc задают XDR-функции преобразования, соответственно, аргумента и ее результата.
При успешном выполнении функция registerrpc возвращает 0, иначе - число "-1".
Диспетчеризация запросов к процедурам-серверам
Для приема запросов к процедурам-серверам от клиентов и диспетчеризации их используется функция svc_run, имеющая следующий вид
#include <rpc/rpc.h>
void svc_run ();
Не имеющая аргументов функция svc_run должна вызываться после регистрации всех диспетчируемых ею процедур-серверов. При успешном выполнении svc_run никогда не возвращает управление в вызвавшую ее программу.
Запрос к процедуре-серверу
Для запроса к удаленной процедуре-серверу из программы-клиента используется функция callrpc, имеющая следующий вид
#include <sys/types.h>
#include <rpc/rpc.h>
int callrpc (host, prognum, vernum, procnum,
inproc, in, outproc, out)
char *host;
u_long prognum;
u_long vernum;
u_long procnum;
xdrproc_t inproc;
char *in;
xdrproc_t outproc;
char *out;
Аргумент host задает имя узла, на котором функционирует вызы- ваемая процедура-сервер.
Аргументы prognum, vernum и procnum задают номера программы, версии и, собственно, вызываемой процедуры-сервера. К моменту вызова процедуры она должна быть зарегистрирована на узле сети, определяемом аргументом host.
Аргумент in должен указывать на данные, передаваемые процеду- ре-серверу в качестве аргумента.
Аргумент out должен указывать на область памяти, предназначенную для размещения в ней результата работы процедуры-сервера.
Аргументы inproc и outproc задают XDR-функции преобразования, соответственно, аргумента процедуры-сервера и ее результата.
На время обработки процедурой-сервером запроса к ней программа-клиент переходит в состояние ожидания результата.
При успешном выполнении вызова удаленной процедуры-сервера функция registerrpc возвращает 0, иначе - число "-1".
Средства вызова удаленных процедур (RPC). Функции сервера.
Средства вызова удаленных процедур (RPC) является составной частью более общего средства, называемого Open Network Computing (ONC), разработанного фирмой Sun Microsystems и получившего всеобщее признание в качестве промышленного стандарта.
ONC помимо RPC включает в себя средства внешнего представления данных (XDR), необходимые для организации обмена информацией в гетерогенных сетях, включающих в себя ЭВМ различной архитектуры, и средства монтирования удаленных файловых систем (NFS), обеспечивающее доступ пользователям локального узла сети к файлам, физически расположенным на удаленных узлах, как к файлам локальным.
Средство RPC реализует модель "клиент-сервер", где роль клиента играет прикладная программа, обращающаяся к набору процедур (функций), исполняемых на удаленном узле в качестве сервера. RPC предоставляет прикладным программистам сервис более высокого уровня, чем ранее рассмотренных два, т.к. обращение за услугой к удаленным процедурам выполняется в привычной для программиста манере вызова "локальной" функции языка программирования СИ. RPC реализовано, как правило, на базе socket-интерфейса и/или TLI. При пересылке данных между узлами сети в RPC для их внешнего представления используется стандарт XDR.
Средство RPC предоставляет программистам сервис трех уровней:
препроцессор rpcgen, преобразующий исходные тексты "монолитных" программ на языке программирования СИ в исходные тексты программы-клиента и программы-сервера по спецификации программиста;
библиотека функций вызова удаленных процедур по их идентификаторам;
библиотека низкоуровневых функций доступа к внутренним механизмам RPC и ниже лежащим протоколам транспортного уровня.
В данном учебном учебном пособии рассматриваются только средства RPC среднего уровня.
Согласно идеологии RPC все процедуры (функции) некоторого распределенного приложения, планируемые к исполнению на одном и том же удаленном узле вычислительной сети, объединяются в единый модуль, оформляемый в виде исполняемого файла и характеризующегося уникальным "номером программы". Допустимо иметь несколько вариантов такого модуля, идентифицируемых уникальным "номером версии". Каждая процедура в составе модуля имеет уникальный "номер процедуры". Таким образом, для однозначной идентификации конкретной процедуры-сервера используется четверка:
имя узла сети;
номер программы на этом узле;
номер версии программы;
номер процедуры в программе.
Каждая процедура-сервер прежде, чем она станет доступной для обращения к ней, должна быть зарегистрирована на соответствующем узле сети. Регистрация процедуры делает ее известной под соответствующими номерами (программы, версии и, собственно, процедуры) сетевому демону portmapper на локальном узле сети. Удаленный RPC-клиент, обращаясь скрытно от пользователя к этому демону, может получить точный сетевой адрес процедуры, который и будет использовать в дальнейшем для прямых обращений к процедуре-серверу.
Процедура-сервер, создаваемая средствами RPC любого уровня, должна иметь единственный аргумент и единственный результат. Это ограничение заставляет прикладного программиста в случае необходимости передачи в процедуру (или возврата из нее) нескольких аргументов (результатов) компоновать их в сложные агрегаты данных (структуры, массивы, списки и т.п.).
Для создания распределенных приложений средствами RPC среднего уровня достаточно использовать три функции: registerrpc, svc_run (на стороне сервера) и callrpc (на стороне клиента).
Примечание. Столь малое количество функций объясняется тем, что средний уровень средств RPC беден с точки зрения возможностей выбора используемого транспорта данных, управления количеством ретрансляций данных, назначения тайм-аутов, организации асинхронной обработки и т.п.
Программисты распределенных приложений кроме собственно функций RPC обязаны также использовать функции преобразования данных во внешнее представление согласно стандарту XDR (так называемые XDR-функции).
Регистрации процедуры-сервера
Регистрация процедуры в качестве сервера на узле сети выполняется функцией registerrpc, имеющей следующий вид
#include <sys/types.h>
#include <rpc/rpc.h>
int registerrpc (prognum, vernum, procnum, procname,
inproc, outproc)
u_long prognum;
u_long vernum;
u_long procnum;
char *(*procname) ();
xdrproc_t inproc;
xdrproc_t outproc;
Аргументы prognum, vernum и procnum задают номера программы, версии и процедуры соответственно. Номера версии и процедуры назначаются программистом произвольно. Номер же программы, находящейся в стадии разработки, должен назначаться из диапазона 0x20000000...0x3fffffff.
Аргумент procname задает функцию языка программирования СИ, регистрируемую в качестве сервера. Эта функция (процедура) вызывается с указателем на ее аргумент и должна возвращать указатель на свой результат, располагаемый в статической или динамически выделенной (функциями malloc или calloc) памяти. Для хранения результата нельзя использовать автоматически выделяемую память (напоминаем, что локальные переменные функций располагаются именно в такой памяти).
Аргументы inproc и outproc задают XDR-функции преобразования, соответственно, аргумента и ее результата.
При успешном выполнении функция registerrpc возвращает 0, иначе - число "-1".
Диспетчеризация запросов к процедурам-серверам
Для приема запросов к процедурам-серверам от клиентов и диспетчеризации их используется функция svc_run, имеющая следующий вид
#include <rpc/rpc.h>
void svc_run ();
Не имеющая аргументов функция svc_run должна вызываться после регистрации всех диспетчируемых ею процедур-серверов. При успешном выполнении svc_run никогда не возвращает управление в вызвавшую ее программу.
Запрос к процедуре-серверу
Для запроса к удаленной процедуре-серверу из программы-клиента используется функция callrpc, имеющая следующий вид
#include <sys/types.h>
#include <rpc/rpc.h>
int callrpc (host, prognum, vernum, procnum,
inproc, in, outproc, out)
char *host;
u_long prognum;
u_long vernum;
u_long procnum;
xdrproc_t inproc;
char *in;
xdrproc_t outproc;
char *out;
Аргумент host задает имя узла, на котором функционирует вызы- ваемая процедура-сервер.
Аргументы prognum, vernum и procnum задают номера программы, версии и, собственно, вызываемой процедуры-сервера. К моменту вызова процедуры она должна быть зарегистрирована на узле сети, определяемом аргументом host.
Аргумент in должен указывать на данные, передаваемые процеду- ре-серверу в качестве аргумента.
Аргумент out должен указывать на область памяти, предназначенную для размещения в ней результата работы процедуры-сервера.
Аргументы inproc и outproc задают XDR-функции преобразования, соответственно, аргумента процедуры-сервера и ее результата.
На время обработки процедурой-сервером запроса к ней программа-клиент переходит в состояние ожидания результата.
При успешном выполнении вызова удаленной процедуры-сервера функция registerrpc возвращает 0, иначе - число "-1".
Средства вызова удаленных процедур (RPC). XDR функции.
Для преобразования данных в/из XDR-формат библиотека функций RPC содержит ряд функций, некоторые из них перечислены ниже:
xdr_int - для преобразования целых;
xdr_u_int - для преобразования беззнаковых целых;
xdr_short - для преобразования коротких целых;
xdr_u_short - для преобразования беззнаковых коротких целых;
xdr_long - для преобразования длинных целых;
xdr_u_long - для преобразования беззнаковых длинных целых;
xdr_char - для преобразования символов;
xdr_u_char - для преобразования беззнаковых символов;
xdr_wrapstring - для преобразования строк символов (заканчивающихся символом '\0').
В ситуациях, когда в процедуру-сервер аргумент не передается (или от нее не возвращается результат), используется функция-"заглушка" xdr_void.
XDR-функции универсальны: в зависимости от контекста их использования они могут преобразовывать данные из внутреннего представления, специфичного для ЭВМ данной архитектуры, во внешнее согласно стандарту XDR и наоборот, а также динамически выделять/освобождать память под сложные агрегаты данных.
При необходимости прикладной программист может легко расширить имеющийся набор XDR-функций, создав свои собственные на базе уже имеющихся.
Технология CGI. Спецификация CGI. Общие принципы работы.
Форматирование страниц в Web-технологии достигается за счет HTML-разметки. Остается только создать инструмент ввода данных через рабочее окно браузера или через HTML-документ. В 1991 году эта проблема была решена специалистами NCSA. Они разработали и реализовали две взаимосвязанные спецификации: HTML-формы и Common Gateway Interface.
Формы произвели настоящую революцию в HTML-разметке: авторы документов получили возможность создавать сложные шаблоны ввода информации в рамках HTML-страницы, пользователи — эти шаблоны заполнять. При этом авторы форм опирались на свойства HTTP-протокола и универсальный локатор ресурсов URL с учетом того, что при HTTP-обмене можно использовать различные методы доступа к ресурсам. Это позволило сделать механизм интерпретации форм расширяемым и легко приспосабливаемым к дальнейшему развитию Web-технологии. Таким образом кроме HTTP можно было использовать и другие протоколы, которые поддерживал универсальный браузер, например mailto.
Common Gateway Interface — это спецификация обмена данными между прикладной программой, выполняемой по запросу пользователя, и HTTP-сервером, который данную программу запускает. До появления CGI новые функции нужно было внедрять непосредственно в сервер. CGI позволила разрабатывать программы независимо от сервера, а механизм передачи им управления и данных был унаследован от программирования в среде командной строки. Последнее резко сократило трудозатраты на разработку приложений, так как не надо было программировать интерфейс пользователя: его функции выполняли формы.
Введение
Обмен данными в Web-технологии подразделяется в соответствии с типами методов доступа протокола HTTP и видами запросов в спецификации CGI.
Основных методов доступа два: GET и POST. Помимо них часто используются HEAD и PUT.
Виды запросов CGI разделяют на два основных MIME-типа: application/x-www-form-urlencoded и multipart/form-data. Второй тип запроса специально создан для передачи больших внешних файлов.
Эту классификацию можно представить в виде таблицы:
При реализации нестандартных методов доступа, например, DELETE, могут быть несколько иные комбинации содержания откликов и ответов.
Мы рассмотрим все эти типы обменов.
Спецификация Common Gateway Interface
Данная спецификация определяет стандартный способ обмена данными между прикладной программой и HTTP-сервером. Спецификация была предложена для сервера NCSA и является основным средством расширения возможностей обработки запросов клиентов HTTP-сервером.
В CGI имеет смысл выделить следующие основные моменты:
понятие CGI-скрипта;
типы запросов;
механизмы приема данных скриптом;
механизм генерации отклика скриптом.
Основное назначение CGI — обработка данных из HTML-форм. В настоящее время область применения CGI гораздо шире.
Понятие CGI-скрипта
CGI-скриптом называют программу, написанную на любом языке программирования или командном языке, которая осуществляет обмен данными с HTTP-сервером в соответствии со спецификацией Common Gateway Interface.
Наиболее популярными языками для разработки скриптов являются Perl и С.
Типы запросов
Различают два типа запросов к CGI-скриптам: по методу GET и по методу POST. В свою очередь, запросы по методу GET подразделяются на запросы по типам кодирования: isindex и form-urlencoded, а запросы по методу POST — multipart/form-data и form-urlencoded.
В запросах по методу GET данные от клиента передаются скрипту в переменной окружения QUERY_STRING. В запросах по методу POST данные от скрипта передаются в потоке стандартного ввода скрипта. При передаче через поток стандартного ввода в переменной окружения CONTENT_LENGHT указывается число передаваемых символов.
Запрос типа ISINDEX — это запрос вида:
http://pub.niiar.ru/somthig-cgi/
cgi-script?слово1+слово2+слово3
Главным здесь является список слов после символа "?". Слова перечисляются через символ "+" и для кириллицы в шестнадцатеричные последовательности не кодируются. Последовательность слов после символа "?" будет размещена в переменной окружения QUERY_STRING.
Запрос типа form-urlencoded — это запрос вида:
http://pub.niiar.ru/somthig-cgi/
cgi-script?field=word1&field2=word2
Данные формы записываются в виде пар "имя_поля-значение", которые разделены символом "&".
Приведенный пример — это обращение к скрипту по методу GET. Все символы после "?" попадут в переменную окружения QUERY_STRING. При этом если в значениях полей появляется кириллица или специальные символы, то они заменяются шестнадцатеричным кодом символа, который следует за символом "%".
При обращении к скрипту по методу POST данные после символа "?" не будут размещаться в QUERY_STRING, а будут направлены в поток стандартного ввода скрипта. В этом случае количество символов в потоке стандартного ввода скрипта будет указано в переменной окружения CONTENT_LENGTH.
При запросе типа multipart/form-data применяется составное тело HTTP-сообщения, которое представляет собой данные, введенные в форме, и данные присоединенного внешнего файла. Это тело помещается в поток стандартного ввода скрипта. При этом к данным формы применяется кодирование как в form-urlencoded, а данные внешнего файла передаются как есть.
Механизмы приема данных скриптом
Скрипт может принять данные от сервера тремя способами:
через переменные окружения;
через аргументы командной строки;
через поток стандартного ввода.
При описании этих механизмов будем считать, что речь идет об обмене данными с сервером Apache для платформы Unix.
Переменные окружения
При вызове скрипта сервер выполняет системные вызовы fork и exec. При этом он создает среду выполнения скрипта, определяя ее переменные. В спецификации CGI определены 22 переменные окружения. При обращении к скрипту разными методами и из различных контекстов реальные значения принимают разные совокупности этих переменных. Например, при обращении по методу POST переменная QUERY_STRING не имеет значения, а по методу GET — имеет. Другой пример — переменная окружения HTTP_REFERER. При переходе по гипертекстовой ссылке она определена, а если перейти по значению поля location или через JavaScript-программу, то HTTP_REFERER определена не будет.
Получить доступ к переменным окружения можно в зависимости от языка программирования следующим образом:
#Perl
$a = $ENV{CONTENT_LENGTH};
...
// C
a = getenv("CONTENT_LENGTH");
В случае доступа к скрипту по методу GET данные, которые передаются скрипту, размещаются в переменной окружения QUERY_STRING.
Аргументы командной строки
Как ни странно звучит, но у CGI-скрипта может быть такой элемент операционного окружения как командная строка. Это не означает, что скрипт реально можно вызвать из командной строки через сервер. Тем не менее получить доступ к содержанию командной строки скрипта можно с помощью тех же функций, что и при вызове его из-под интерактивной оболочки:
#Perl
foreach $a (@ARGV)
{
print $a,"\n";
}
// C
void main(argc,argv)
int argc;
char *argv[];
{
int i;
for(i=0;i<argc;i++)
{
printf("%s\n",argv[i]);
}
}
В обоих примерах показана распечатка аргументов командной строки для программ на Perl и C соответственно.
Аргументы командной строки появляются только в запросах типа ISINDEX.
Поток стандартного ввода
Ввод данных в скрипт через поток стандартного ввода осуществляется только при использовании метода доступа к ресурсу (скрипту) POST. При этом в переменную окружения CONTENT_LENGTH помещается число символов, которое необходимо считать из потока стандартного ввода скрипта, а в переменную окружения CONTENT_TYPE помещается тип кодирования данных, которые считываются из потока стандартного ввода.
При посимвольном считывании в C можно применить, например, такой фрагмент кода:
int n;
char *buf;
n= atoi(getenv("CONTENT_LENGTH"));
buf = (char *) malloc(n+1);
memset(buf,'\000',n+1);
for(i=0;i<n;i++)
{
buf[i]=getchar()
}
free(buf);
В данном фрагменте применено динамическое размещение памяти в скрипте, поэтому при выходе из него память следует освободить. Вообще говоря, память будет автоматически освобождена операционной системой после завершения скрипта. Однако, если переносить скрипт на спецификацию FCGI (Fast CGI), что требует минимума переделок, из-за неаккуратной работы с памятью могут возникнуть проблемы.
Технология CGI. Протокол HTTP (общая структура сообщений, методы доступа и оптимизация обменов).
Все данные в рамках Web-технологии передаются по протоколу HTTР. Исключение составляет обмен с использованием программирования на Java или обмен из Plugin-приложений. Учитывая реальный объем трафика, который передается в рамках Web-обмена по HTTP, мы будем рассматривать только этот протокол. При этом мы остановимся на таких вопросах, как:
общая структура сообщений;
методы доступа;
оптимизация обменов.
Общая структура сообщений
HTTP — это протокол прикладного уровня. Он ориентирован на модель обмена "клиент-сервер". Клиент и сервер обмениваются фрагментами данных, которые называются HTTP-сообщениями. Сообщения, отправляемые клиентом серверу, называют запросами, а сообщения, отправляемые сервером клиенту — откликами. Сообщение может состоять из двух частей: заголовка и тела. Тело от заголовка отделяется пустой строкой.
Заголовок содержит служебную информацию, необходимую для обработки тела сообщения или управления обменом. Заголовок состоит из директив заголовка, которые обычно записываются каждая на новой строке.
Тело сообщения не является обязательным, в отличие от заголовка сообщения. Оно может содержать текст, графику, аудио- или видеоинформацию.
Ниже приведен HTTP-запрос:
GET / HTTP/1.0
Accept: image/jpeg
пустая строка
И отклик:
HTTP/1.0 200 OK
Date: Fri, 24 Jul 1998 21:30:51 GMT
Server: Apache/1.2.5
Content-type: text/html
Content-length: 21345
пустая строка
<HTML>
...
</HTML>
Текст "пустая строка" — это просто обозначение наличия пустой строки, которая отделяет заголовок HTTP-сообщения от его тела.
Сервер, принимая запрос от клиента, часть информации заголовка HTTP-запроса преобразует в переменные окружения, которые доступны для анализа CGI-скриптом. Если запрос имеет тело, то оно становится доступным скрипту через поток стандартного ввода.
Методы доступа
Самой главной директивой HTTP-запроса является метод доступа. Он указывается первым словом в первой строке запроса. В нашем примере это GET. Различают четыре основных метода доступа:
GET;
HEAD;
POST;
PUT.
Кроме этих четырех методов существует еще около пяти дополнительных методов доступа, но они используются редко.
Метод GET
Метод GET применяется клиентом при запросе к серверу по умолчанию. В этом случае клиент сообщает адрес ресурса (URL), который он хочет получить, версию протокола HTTP, поддерживаемые им MIME-типы документов, версию и название клиентского программного обеспечения. Все эти параметры указываются в заголовке HTTP-запроса. Тело в запросе не передается.
В ответ сервер сообщает версию HTTP-протокола, код возврата, тип содержания тела сообщения, размер тела сообщения и ряд других необязательных директив HTTP-заголовка. Сам ресурс, обычно HTML-страница, передается в теле отклика.
Метод HEAD
Метод HEAD используется для уменьшения обменов при работе по протоколу HTTP. Он аналогичен методу GET за исключением того, что в отклике тело сообщения не передается. Данный метод используется для проверки времени последней модификации ресурса и срока годности кэшированных ресурсов, а также при использовании программ сканирования ресурсов World Wide Web. Одним словом, метод HEAD предназначен для уменьшения объема передаваемой по сети информации в рамках HTTP-обмена.
Метод POST
Метод POST — это альтернатива методу GET. При обмене данными по методу POST в запросе клиента присутствует тело HTTP-сообщения. Это тело может формироваться из данных, которые вводятся в HTML-форме, или из присоединенного внешнего файла. В отклике, как правило, присутствует и заголовок, и тело HTTP-сообщения. Чтобы инициировать обмен по методу POST, в атрибуте METHOD контейнера FORM следует указать значение "post".
Метод PUT
Метод PUT используется для публикации HTML-страниц в каталоге HTTP-сервера. При передаче данных от клиента к серверу в сообщении присутствует и заголовок сообщения, в котором указан URL данного ресурса, и тело — содержание размещаемого ресурса.
В отклике тело ресурса обычно не передается, а в заголовке сообщения указывается код возврата, который определяет успешное или неуспешное размещение ресурса.
Оптимизация обменов
Протокол HTTP изначально не был ориентирован на постоянное соединение. Это означает, что как только сервер принял запрос от клиента и ответил на него, соединение между клиентом и сервером разрывается. Для нового обмена данными нужно устанавливать новое соединение. Такой подход имеет как достоинства, так и недостатки.
К достоинствам относится возможность одновременного обслуживания большого количества коротких запросов. Даже на популярных серверах число открытых соединений может не превышать сотни при обслуживании порядка миллиона запросов в сутки. При этом один клиент может открыть до 40 соединений одновременно, и с точки зрения сервера все они равноправны. При высокоскоростных линиях связи это позволяет добиться малого времени отклика на запрос клиента для всей страницы (текст, графика и т.п.).
К недостаткам такой схемы обмена относятся: необходимость каждый раз устанавливать соединение и невозможность поддерживать сессию работы с информационным ресурсом. При инициализации соединения по транспортному протоколу TCP и разрыве этого соединения требуется передать довольно большой объем служебной информации. Отсутствие поддержки сессий в HTTP затрудняет работу с такими ресурсами как базы данных или ресурсы, требующие аутентификации.
Для оптимизации числа открытых TCP-соединений в HTTP-протоколе версий 1.0 и 1.1 предусмотрен режим keep-alive. В этом режиме соединение инициализируется только один раз, и по нему последовательно можно реализовать несколько HTTP-обменов.
Для обеспечения поддержки сессий к директивам HTTP-заголовка были добавлены "ключики" (cookies). Они позволяют сымитировать поддержку соединения при работе по протоколу HTTP.
Программирование CGI на языке С.
Директивы препроцессора позволяют собрать программу на языке С из готовых блоков кода. Кроме того, можно реализовать управление процессом компиляции, например, разработать процедуру условной компиляции для разных операционных систем.
В рамках разработки простых CGI-скриптов нам нужна будет только инструкция включения "include". Во всех примерах данного раздела она используется для включения в код программы описаний функций из набора стандартных библиотек.
Если необходимо задействовать функции форматного ввода/вывода, а их мы применяем для печати в стандартный вывод, то следует использовать инструкцию #include <stdio.h>:
#include <stdio.h>
void main()
{
printf("Content-type: text/html\n\n");
printf("<HTML>");
printf("<HEAD>");
printf("</HEAD>");
printf("<BODY>");
printf("<H1>Привет от-CGI</H1>");
printf("</BODY>");
printf("</HTML>");
}
Инструкция препроцессора начинается с символа "#". При использовании инструкций включения различают локальные файлы и стандартные файлы включения. Когда применяются стандартные файлы включения, имя файла заключают в "<имя_файла>". При использовании локального файла имя файла заключают в обычные двойные кавычки — "имя_файла". В наших примерах применяются только стандартные файлы включений.
Мы используем файлы включения только для ввода в код программы описаний стандартных функций и констант, с этими функциями связанных. Для наиболее распространенных функций существует файл /usr/include/stdlib.h. Его включения в программу достаточно для того, например, чтобы использовать функции ввода/вывода и сравнения строк:
#include <stdlib.h>
void main()
{
printf("Content-type: text/plain\n\n");
if(strcmp("GET",getenv("REQUEST_METHOD"))
{
printf("Нет даты в потоке STDIN");
}
}
В данном случае в stdlib.h определены шаблоны для функций strcmp() и getenv().
При программировании в среде Unix программист всегда может применить команду man, которая позволяет получить подсказку по использованию той или иной функции C.
Компиляция
Программа на С — это текстовый файл, из которого программа-компилятор создает исполняемый файл. CGI-скрипт — это исполняемый файл. Для компиляции используется компилятор с языка С. В большинстве Unix-платформ этот компилятор носит название cc.
Предположим, что нужно создать программу с именем hello.cgi. Код на С расположен в файле hello.c. В этом случае достаточно выполнить:
bash%cc -o hello.cgi hello.c
Опция "-о" в этой записи определяет имя исполняемого файла. Он задается сразу вслед за ней. Имя файла исходного текста С указывается просто в качестве параметра.
Если в скрипте использовать функции из внешней библиотеки, то компилятору необходимо указать ее адрес:
bash%cc -o test.cgi test.c -lpq
В данном случае мы используем внешнюю библиотеку pq. Опция -l определяет имя библиотеки. Сама процедура сборки программы называется linking (связывание). Отсюда и буква "l" перед именем библиотеки.
Технология CGI. Метод доступа GET.
Метод доступа GET долгое время был основным методом доступа из форм к CGI-скриптам. Это происходило по причине отсутствия при вводе большого количества данных и из-за прямого обращения к скриптам по их URL. В настоящее время ситуация меняется, но тем не менее данный метод занимает едва ли не главное место в программировании обработки данных из HTML-форм.
Условно использование GET можно разбить на два способа:
запросы типа isindex;
запросы типа from-urlencoded.
В первом случае имитируется или реально происходит передача запроса, который появляется при вводе данных в строке приглашения контейнера ISINDEX. Во втором случае происходит передача пар "имя_поля=значение". И в том, и в другом случае данные, не входящие в кодировку Latin1, преобразуются в пары шестнадцатеричных символов, предваряемых символом "%" (%20 — пробел).
Кроме вызова скрипта непосредственно из гипертекстовой ссылки, скрипт можно запустить и через Server Site Include. В этом случае данные из формы будут приписываться к URL документа, а не скрипта. Скрипт при этом будет вызываться сервером при разборе текста HTML-страницы перед отправкой ее клиенту.
Кроме собственно запроса, который в методе GET появляется в URL после символа "?", скрипту еще можно передать информацию в HTTP-пути. Это переменная окружения PATH_INFO. Обработка данных из этой переменной требует особого подхода к их получению и использованию в скрипте и гипертекстовых ссылках.
Запрос isindex
Запрос типа isindex является исторически первым способом передачи данных от браузера серверу. Он был разработан для передачи списка ключевых слов для поисковой машины. Запрос данного типа появляется либо в случае использования контейнера ISINDEX, либо при прямом обращении к скрипту через гипертекстовую ссылку. Данный тип запроса имеет ряд особенностей, которые отличают его от запроса типа form-urlencoded.
При использовании контейнера ISINDEX в начале документа появляется шаблон ввода ключевых слов. После ввода списка слов, разделенных пробелом, вызывается скрипт, который принимает список, разбирает его на отдельные слова и выполняет необходимую обработку. Первоначально isindex был ориентирован на модуль, подключавший поисковую систему WAIS к серверу CERN. После появления спецификации CGI стало возможным передавать списки слов любому CGI-скрипту. Запрос типа isindex определен только для метода доступа GET.
Согласно спецификации CGI для метода GET запрос присоединяется к URL документа или скрипта (указан атрибут ACTION в контейнере ISINDEX) после символа "?"(getis2.htm):
http://localhost/htdocs/isindex.htm?search+
engine+world+wide+web
или
http://localhost/htdocs/isindex.cgi?search+
engine+world+wide+web
Как видно из этого примера, в запросе пробел заменяется на символ "+". Причем буквы русского алфавита в таком запросе перекодировать не надо, они передаются как есть. Если пользователь работает с локализованной версией операционной среды, то все будет отображаться так, как положено. В случае нелокализованной версии операционной среды, например, Windows NT, буквы будут отображаться абракадаброй, но в скрипт будут передаваться правильные коды.
Традиционно в GET данные запроса выбираются из переменной окружения QUERY_STRING. Например, это можно сделать на Perl следующим образом:
#!/usr/local/bin/perl
print "Content-type: text/playn\n\n";
print "Запрос: $ENV{QUERY_STRING}.\n";
В данном примере первый оператор печати формирует заголовок HTTP-сообщения в соответствии со спецификацией CGI. Второй оператор печати распечатывает содержание переменной окружения QUERY_STRING. Главное при этом — разделить запрос на отдельные слова, чтобы можно было использовать их в качестве ключей поиска. В Perl для этого существует функция split:
#!/usr/local/bin/perl
print "Content-type: text/playn\n\n";
print "Запрос: $ENV{QUERY_STRING}.\n";
@words = split('+',$ENV{QUERY_STRING});
foreach $word (@words)
{
print $word,"\n";
}
В данном случае следует обратить внимание на то, что в запросе нет никаких имен полей — только введенные слова и их разделители. Естественно, если среди введенных символов встретится разделитель, он будет заменен шестнадцатеричным.
У запроса isindex есть еще одно замечательное свойство — это передача данных в командной строке CGI-скрипта. Очевидно, что ввести аргументы пользователь не в состоянии (у него нет удаленного терминала), но вот принять данные из командной строки скрипт может:
#!/usr/local/bin/perl
print "Content-type: text/playn\n\n";
print "Запрос: $ENV{QUERY_STRING}.\n";
$n = @ARGV;
for ($i=0;$i
{
print $ARGV[$i],"\n";
}
Внешне результаты работы данного скрипта и скрипта разбора QUERY_STRING ничем не отличаются. Но данные они получают из разных источников (getis6.htm).
Запрос типа isindex не порождается событием onSubmit, как это происходит в запросах form-urlencoded. Он является одной из разновидностей схемы http универсального локатора ресурсов (URL). При использовании обычной контекстной гипертекстовой ссылки (контейнер A (anchor)) запрос просто дописывается вслед за символом "?".
При программировании на JavaScript обратиться к скрипту через запрос isindex можно либо путем изменения значения атрибута HREF в одном из элементов массива гипертекстовых ссылок документа, либо путем вызова метода replace() объекта Location.
Запрос from-urlencoded
В методе GET запрос типа form-urlencoded является основной формой запроса. От запроса типа isindex он отличается форматом и способом передачи, точнее, кодировкой данных в теле HTTP-сообщения. Данные формы попадают в запрос, который расширяет URL скрипта в виде пар "имя_поля=значение&имя_поля=значение&...". Например, для формы вида:
<FORM ACTION=test.cgi METHOD=get>
Поле1:<INPUT NAME=f1 VALUE=value1>
Поле2:<INPUT NAME=f1 VALUE=value1>
<INPUT TYPE=submit VALUE="Послать">
</FORM>
запрос в сообщении HTTP-протокола будет выглядеть следующим образом:
GET /test.cgi?f1=value1&f2=value2 HTTP/1.0
Несмотря на то, что в форме имеется три поля, переданы будут значения только двух полей. Это связано с тем, что у третьего поля в форме нет имени. Если у поля нет имени, то его значение не передается серверу. Это правило общее для всех полей. Чаще всего оно применяется для полей подтипов submit и reset типа text.
Применение неименованных полей позволяет передавать в скрипт только ту информацию, которая реально требуется для выполнения обработки данных. Иногда неименованные поля применяют и при программировании на JavaScript.
Кроме формата в запросе типа form-urlencoded, данные, введенные в форму, подвергаются дополнительной обработке — кодированию.
Кодирование, собственно, и дало название методу (urlencoded). Согласно спецификации, текстовое сообщение не может содержать символы, не входящие в набор Latin1. Это означает, что вторая половина таблицы ASCII и первые 20 символов должны быть закодированы. В CGI символ кодируется как две шестнадцатеричные цифры, следующие за знаком "%". Для российских Web-узлов это означает, что скрипт, который принимает запрос, должен предварительно перекодировать все шестнадцатеричные эквиваленты в символы (getform2.htm). На Perl это можно реализовать в одну строку:
query =~ s/%(.{2})/pack('c',hex($1))/ge;
В данном случае мы осуществляем глобальную подстановку (оператор "=~ s///"), который употреблен с модификаторами "ge". Первый модификатор обозначает глобальную замену по всей строке query, а второй требует выполнения перед заменой выражения "pack('c',hex($1))". Более подробно о программировании на Perl см. раздел "Введение в программирование на Perl".
Передача параметров через PATH_INFO
Передача данных в скрипты возможна не только при помощи переменной окружения QUERY_STRING или аргументов командной строки скрипта. Передать параметры в скрипт можно через переменную окружения PATH_INFO. Данная переменная принимает свое значение после преобразования URL скрипта. Рассмотрим следующий URL:
http://localhost/cgi-bin/test/arg1/arg2/
arg3?param1+param2
Согласно спецификации URI адрес ресурса делится на две части: название схемы адресации и путь к ресурсу:
схема разделитель путь к ресурсу
http : //localhost/cgi-bin/test/arg1/arg2/arg3?param1+param2
схема адресации задается протоколом обмена данными. Обращение к скрипту осуществляется по схеме http. В свою очередь, в схеме http путь снова делится на две части: адрес ресурса и параметры. Эти части разделены символом "?". Параметры могут быть записаны либо в форме isindex, либо в формате form-urlencoded:
адрес ресурса разделитель параметры
//localhost/cgi-bin/test/arg1/arg2/arg3 ? param1+param2
Адрес ресурса в случае обращения к скрипту снова можно разделить на две части — адрес скрипта и путевой параметр PATH_INFO:
адрес скрипта PATH_INFO
//localhost/cgi-bin/test /arg1/arg2/arg3
В данном случае явного разделителя между адресом скрипта и PATH_INFO нет. Деление определяется настройками сервера. У большинства серверов стандартным каталогом CGI-скриптов является каталог cgi-bin. При этом подразумевается, что все файлы этого каталога — скрипты. Можно даже указать файл с расширением html, который в данном случае будет интерпретироваться как скрипт (getpath1.htm). Значение путевого параметра сервер помещает в переменную окружения PATH_INFO. При этом в нее попадает и лидирующий символ "/".
Управление работой скрипта через путевой параметр довольно популярно. Например, при выполнении перенаправления, когда нужно собирать статистику обращений к ресурсам, расположенным вне Web-узла:
http://localhost/cgi-bin/banner/
http://otherhost/page.html
Вообще говоря, при таких перенаправлениях возникает опасность Web-спуффинга. Существует очень большая вероятность, что администратор не заметит подмены одной из частей такого URL.
PATH_INFO применяется не только в совокупности с каталогами скриптов, но и с любым скриптом, определенным пользователем. Часто в качестве такого скрипта определяются файлы с расширением *.cgi:
http://www.pub.niiar.ru/~user/script.cgi/
path_param/test?arg1+arg2
В этом примере в переменную PATH_INFO попадет /path+param/test.
Технология CGI. Метод доступа PUT и другие методы.
Метод POST — это второй основной метод доступа к информационным ресурсам Web-узла. Он является альтернативой методу GET. Вообще, при HTTP-обмене используются три основных метода: GET, POST и HEAD. Первые два предназначены для получения страниц. Страницы при этом передаются в виде тела HTTP-отклика. При методе GET от клиента к серверу отправляется запрос, состоящий только из заголовка HTTP-сообщения. Все введенные пользователем данные размещаются в URL документа. При методе POST от клиента к серверу уходит запрос, который состоит из заголовка и тела HTTP-сообщения. При этом данные, введенные пользователем, размещаются в теле запроса. Метод HEAD применяется только для управления обменом и отображением. В рамках данного метода тело HTTP-сообщения не пер едается как клиентом в запросе, так и сервером в отклике.
Основное назначение метода POST — передача сравнительно больших объемов данных от клиента к серверу. Применение этого метода оправдано при передаче сложных состоящих из множества полей форм. В спецификации CGI от NCSA рекомендуется использовать метод POST при передаче данных из форм, содержащих поля textarea.
Современное использование Web в качестве альтернативы FTP-архивам расширило свойства метода POST. Так, большинство архивов научной периодики построено по принципу их обновления авторами статей. Для этой цели используются страницы с формами, содержащими поля типа File-upload. Этот механизм позволяет передать на сервер файл любого размера и любого типа. При этом сами пользователи не получают Web-account на сервере архива, они пользуются стандартным скриптом публикации.
Из перечисленных выше методов только POST формирует тело сообщения. В спецификации CGI речь при этом идет только об HTTP-сообщениях. Но современные браузеры — это мультипротокольные программы. При этом в качестве гипертекстовых ссылок можно использовать различные схемы. Во многих протоколах, на которые эти схемы указывают, нет понятия метода доступа. Тем не менее в контейнере FORM такой метод можно использовать, например, со схемой mailto. В данном случае ни по какому методу POST, который не определен в протоколе SMTP, ничего не передается. POST просто заставляет браузер создать тело, в данном случае, почтового сообщения.
Чтение данных из стандартного потока ввода
При передаче запроса по методу POST от клиента к серверу передается HTTP-сообщение, которое состоит из заголовка и тела. Данные, введенные в HTML-форму, как раз и составляют тело сообщения. При обработке такого запроса CGI-скриптом данные следует выбирать из стандартного потока ввода скрипта, а не из переменной окружения QUERY_STRING. Эта переменная будет иметь пустое значение.
Для того, чтобы принять данные, нужно прочитать стандартный поток ввода. При этом из стандартного потока ввода нужно считать строго определенное количество байтов. Число байтов определяется переменной окружения CONTENT_LENGTH. В Perl прием данных в скрипт можно организовать следующим образом:
#!/usr/local/bin/perl
read STDIN,$query,$ENV(CONTENT_LENGTH);
Здесь из стандартного потока ввода STDIN считывается $ENV(CONTENT_LENGTH) данных и помещается в переменную $query. После этого можно уже что-то делать с запросом, например, распечатать его в виде HTML-таблицы.
Аналогично можно принять запрос из стандартного ввода и в С. Для этого следует воспользоваться в простейшем случае функцией getchar():
#include <stdlib.h>
#include <malloc.h>
void main()
{
int n,i;
char *buff;
n = atoi(getenv("CONTENT_LENGTH");
buff = (char *) malloc(n+1);
memset(buff,'\000',n+1);
for(i=0;i<n;i++)
{
buff[i] = getchar();
}
printf("Content-type: text/plain\n\n");
printf("Length of data into STDIN:%d\n",n);
printf("STDIN data: %s\n",buff);
free(buff);
}
Посимвольное чтение в этом примере можно заменить чтением по функции fread(). При этом не следует ожидать существенного уменьшения времени чтения данных. Во-первых, данные при вводе буферизуются. Во-вторых, в С применяется потоковая модель работы с внешними наборами данных.
Передача присоединенных файлов
Метод POST позволяет реализовать передачу файлов с компьютера пользователя в архив на HTTP-сервере. Для этой цели разработана специальная форма кодирования тела документа: multipart/form-data. Она указывается в контейнере FORM в атрибуте ENCTYPE совместно с методом POST:
<FORM ENCTYPE=multipart/form-data
METHOD=post>
Скрипт, который принимает такие данные, должен определить метод доступа, затем определить тип тела документа и только после этого начать разбирать тело. В теле может быть как минимум две части: значения различных полей, которые доставляются скрипту в первой части сообщения, и тело передаваемого файла, которое передается как вторая часть сообщения.
Поля разбираются по традиционной схеме. Это обычные ASCII-символы. С ними никаких проблем не возникает. Тело документа передается как есть, т.е. без преобразований. Это значит, что применять для его выделения текстовые функции С нельзя, т.к. внутри документа могут попадаться любые символы, в том числе и символы конца символьного массива (строки).
Чтобы убедиться в этом, достаточно просто распечатать данные, посланные браузером. Для приема данных и их разбора нужно либо написать собственную программу, либо воспользоваться готовыми программами и библиотеками языка Perl, например.
Очевидно, что метод POST с полями file-upload используется для опубликования данных на стороне сервера. При этом файл, который передается по сети, должен быть размещен в файловой системе либо сервера, либо другого удаленного компьютера. Для этого пользователь, от имени которого запускается скрипт, должен иметь соответствующие права на доступ к каталогу файловой системы компьютера, в который записывается файл. Довольно часто модули стандартных библиотек, например, CGI_Lite или CGI.pm, используют для временного хранения каталог /tmp. Иногда данный каталог закрывают на запись, из-за чего могут возникнуть проблемы с приемом данных скриптом, составленным из модулей стандартной библиотеки.
Стандартные библиотеки разбора данных
Разбор запроса по методу POST CGI-скриптом — это рутинная процедура. При запросе типа url-encoded нужно просто выделить имена полей и их значения, а при запросе типа multipart/form-data — выделить части составного тела запроса и преобразовать их в имена полей, их значения и файлы.
С 1995 года было написано достаточно много заготовок для такого разбора, которые оформлены в виде свободно распространяемых библиотек. Наиболее популярными являются библиотеки модулей Perl — CGI.pm и CGI_Lite.
CGI.pm — полный набор функций для генерации HTML-файлов с формами и разбора запросов CGI-скриптами.
CGI_Lite — это средство работы с составными (multipart/form-data) запросами. При работе с функциями данного модуля следует иметь в виду, что временные файлы эти функции размещают в каталоге /tmp.
Метод доступа PUT и другие способы использования CGI-скриптов
Кроме стандартных способов использования CGI-скриптов, т.е. приема запросов от браузеров по методам GET и POST, скрипты применяются и для решения ряда других задач. К таким задачам можно отнести обслуживание расширенного набора методов доступа, например, PUT и DELETE.
Кроме того, для исполнения скриптов сам HTTP-сервер должен быть настроен соответствующим образом. В конфигурации по умолчанию сервера Apache предполагается, что все стандартные скрипты будут размещаться в каталоге ~server_root/cgi-bin, а скрипты пользователя будут иметь расширение *.cgi.
Если эксплуатируется только один Web-узел, этих настроек вполне достаточно. Если же на одной вычислительной установке эксплуатируется несколько виртуальных Web-узлов, то для каждого из них следует дополнительно определять и каталоги стандартного размещения, и расширения по умолчанию, и методы обработки нестандартных методов доступа.
Нередко CGI-скрипты применяются в качестве подстановок SSI на стороне сервера. Схема проста: HTML-документ используется как шаблон, в котором HTML-комментарии задают команды подстановок. В зависимости от различных условий сервер, который обрабатывает эти документы перед отправкой клиенту (браузеру), вставляет в шаблон результаты выполнения команд подстановок, в частности CGI-скриптов.
Преимущество CGI-скриптов в данном случае заключается в том, что они работают с переменными окружения, порожденными сервером для скрипта, а не с системными переменными окружения. Это позволяет включить механизмы анализа IP-адреса клиента, его доменного имени или cookie, чего нельзя сделать при работе с обычным набором переменных окружения, который порождается операционной системой.
Технология CGI. Контейнер INPUT и его компоненты.
Контейнер INPUT является самым распространенным контейнером HTML-формы. Существует целых 10 типов этого контейнера (text, image, submit, reset, hidden, password, file, checkbox, radio, button), причем каждый из них отображается по-разному.
В общем виде контейнер имеет вид:
<INPUT
NAME="Имя"
TYPE="Тип"
[вариации параметров, зависящие от типа]
>
Чаще всего контейнер INPUT применяется для организации текстового поля ввода: например, для ввода списка ключевых слов или для заполнения регистрационных форм.