

11 Лекция - Поддержка целостности
.pdfCONSTRAINT CK_PAGES CHECK (PAGES > = 5 AND PAGES <= 1000),
CONSTRAINT CK_BOOKS CHECK (NOT (AUTOR IS NULL AND COAUTOR IS NOT NULL))
);
CREATE TABLE READERS
(
READER_ID Smallint PRIMARY KEY, FIRST_NAME char(30) NOT NULL, LAST_NAME char(30) NOT NULL, ADRES char(50),
HOME_PHON char(12), WORK_PHON char(12),
BIRTH_DAY date CHECK( DateDiff(year, GetDate(),BIRTH_DAY) >=17 ),
CONSTRAINT CK_READERS CHECK (HOME_PHON IS NOT NULL OR WORK_PHON IS NOT NULL)
);
CREATE TABLE CATALOG
(
ID_CATALOG Smallint PRIMARY KEY, KNOWELEDGE_AREA varchar(150)
);
CREATE TABLE EXEMPLAR
(
ID_EXEMPLAR int NOT NULL,
ISBN varchar(14) NOT NULL FOREIGN KEY references BOOKS(ISBN), READER_ID Smallint(4) NULL FOREIGN KEY references READERS (READER_ID), DATA_IN date,
DATA_OUT date, EXIST Logical,
PRIMARY KEY (ID_EXEMPLAR, ISBN) );
CREATE TABLE RELATION_1
(
ISBN varchar(14) NOT NULL FOREIGN KEY references BOOKS(ISBN),
ID_CATALOG smallint NOT NULL FOREIGN KEY references CATALOG(ID_CATA-
LOG),
CONSTRAINT PK_RELATION_1 PRIMARY KEY (ISBN,ID_CATALOG) ).
Операторы языка SQL, как указывалось ранее, транслируются в режиме интерпретации, в отличие от большинства алгоритмических языков, трансляторы для которых выполнены по принципу компиляции. В режиме интерпретации каждый оператор отдельно транслируется, то есть переводится в машинные коды, и тут же выполняется. В режиме компиляции вся программа, то есть совокупность операторов, сначала переводится в машинные коды, а затем может быть выполнена как единое целое. Такая осо-
бенность SQL накладывает ограничение на порядок описания создаваемых таблиц. Действительно, если при трансляции оператора описания подчиненной таблицы с указанным внешним ключом и соответствующей ссылкой на родительскую таблицу эта родительская таблица не будет обнаружена, то мы получим сообщение об ошибке с указанием ссылки на несуществующий объект. Сначала должны быть описаны все основные таблицы, а потом подчиненные таблицы.
В нашем примере с библиотекой порядок описания таблиц следующий:
1.Таблица BOOKS
2.Таблица READERS
3.Таблица CATALOG (системный каталог)
4.Таблица EXEMPLAR
5.Таблица RELATION_1 (дополнительная связующая таблица между книгами и системным каталогом).
Набор операторов языка SQL принято называть не программой, а скриптом. Тогда скрипт, который добавит набор из 5 взаимосвязанных таблиц базы данных "Библиотека" в существующую базу данных, будет выглядеть следующим образом:
CREATE TABLE BOOKS
(
ISBN varchar(14) NOT NULL , TITLE varchar(120) NOT NULL, AUTOR varchar (30) NULL, COAUTOR varchar(30) NULL, YEAR_PUBL smallint NOT NULL, PUBLICH varchar(20) NULL, PAGES smallint NOT NULL,
CONSTRAINT PK_BOOKS PRIMARY KEY (ISBN), CONSTRAINT DF_ YEAR_PUBL DEFAULT (Year(GetDate()),
CONSTRAINT CK_ YEAR_PUBL CHECK (YEAR_PUBL >= 1960 AND YEAR_PUBL <= YEAR(GetDate())),
CONSTRANT CK_PAGES CHECK (PAGES > = 5 AND PAGES <= 1000),
CONSTRAINT CK_BOOKS CHECK (NOT (AUTOR IS NULL AND COAUTOR IS NOT NULL))
CREATE TABLE READERS
(
READER_ID Smallint PRIMARY KEY, FIRST_NAME char(30) NOT NULL, LAST_NAME char(30) NOT NULL, ADRES char(50),
HOME_PHON char(12), WORK_PHON char(12),
BIRTH_DAY date CHECK( DateDiff(year, GetDate(),BIRTH_DAY) >=17 ),
CONSTRAINT CK_READERS CHECK (HOME_PHON IS NOT NULL OR WORK_PHON IS NOT NULL)
);
CREATE TABLE CATALOG
(
ID_CATALOG Smallint PRIMARY KEY, KNOWELEDGE_AREA varchar(150)
);
CREATE TABLE EXEMPLAR
(
ID_EXEMPLAR int NOT NULL,
ISBN varchar(14) NOT NULL FOREIGN KEY references BOOKS(ISBN), READER_ID Smallint(4) NULL FOREIGN KEY references READERS (READER_ID), DATA_IN date,
DATA_OUT date, EXIST Logical,
PRIMARY KEY (ID_EXEMPLAR, ISBN) );
CREATE TABLE RELATION_1
(
ISBN varchar(14) NOT NULL FOREIGN KEY references BOOKS(ISBN),
ID_CATALOG smallint NOT NULL FOREIGN KEY references CATALOG(ID_CATA-
LOG),
CONSTRAINT PK_RELATION_1 PRIMARY KEY (ISBN, ID_CATALOG) ).
При написании скрипта мы добавили в оператор создания таблицы "Читатели" ограничение на уровне таблицы, которое связано с обязательным наличием хотя бы одного из двух телефонов.
11.3.Средства определения схемы базы данных
В стандарте SQL1 задается спецификация оператора описания схемы базы данных, но не указывается способ создания собственно базы данных, поэтому в различных СУБД используются неодинаковые подходы к этому вопросу.
Например, в СУБД ORACLE база данных создается в ходе установки программного обеспечения собственно СУБД. Все таблицы пользователей помещаются в единую базу данных. Однако они могут быть разделены на группы, объединенные в подсхемы. Понятие подсхемы не стандартизировано в SQL и не используется в других СУБД.
Всостав СУБД INGRES входит специальная системная утилита, имеющая имя CREATEDB, которая позволяет создавать новые базы данных. Права на использование этой утилиты имеет администратор сервера. Для удаления базы данных существует соответствующая утилита DESTROYDB.
ВСУБД MS SQL Server существует специальный оператор CREATE DATABASE, который является частью языка определения данных, для удаления базы данных в языке определен оператор DROP DATABASE. Правами на создание баз данных наделяются администраторы баз данных, которых в общем случае может быть несколько. Правами более высокого уровня обладает администратор сервера баз данных (SQL Server), который и может предоставить права администратора базы данных другим пользователям сервера. Администраторы баз данных могут удалить только свою базу данных. Приведем пример оператора создания схемы базы данных в MS SQL Server:
CREATE DATABASE database_name
[ON [PRIMARY][<спецификация файла>[,...n]][,<группа файлов> [,...n]]] [ LOG ON { спецификация файла> [,...n]} ][ FOR LOAD | FOR ATTACH ]
<спецификация файла> ::=
( [ NAME = логическое имя файла,]FILENAME = 'физическое имя файла'
[, SIZE = размер][, MAXSIZE = { максимальный размер | UNLIMITED } ] [, FILEGROWTH = инкремент увеличения файла] ) [,...n]
<группа файлов>::= FILEGROUP имя группы файлов спецификация файла>
[,...n]
Здесь
database_name — имя базы данных, идентификатор в системе;
ON — ключевое слово, которое означает, что далее будут заданы спецификации файлов, которые будут использованы для размещения базы данных;
PRIMARY — ключевое слово, которое определяет первичное файловое пространство, в котором будет размещена собственно база данных;
LOG ON — ключевое слово, которое задает спецификацию файлов, которые будут использованы для хранения журналов транзакций;
FOR LOAD — ключевое слово, которое определяет, что после создания базы данных будет произведена загрузка базы данных данными;
FOR ATTACH — предложение, которое определяет, что база данных для управления будет подсоединена к другому серверу.
Почти все параметры, кроме имени базы данных, являются необязательными, поэтому оператор создания простой базы данных "Библиотека" может выглядеть следующим образом:
CREATE DATABASE Library
Для изменения схемы базы данных в MS SQL Server может быть использована
команда:
ALTER DATABASE database
{ ADD FILE спецификация файлов> [,...n] [TO FILEGROUP filegroup_name] | ADD LOG FILE спецификация файлов> [,...n]
| REMOVE FILE имя_файла
| ADD FILEGROUP имя группы файлов REMOVE FILEGROUP имя группы_фай-
лов
| MODIFY FILE спецификация файлов>
| MODIFY FILEGROUP имя_группы_файлов имя_свойства_группы файлов} Здесь свойства группы файлов определяет одно из допустимых ключевых слов:
READONLY — только для чтения;
READWRITE — для чтения и записи;
DEFAULT — назначает данную группу файлов в качестве группы по умолчанию, в которой размещаются данные, если не задано дополнительных условий размещения информации.
Как видно, при изменении схемы базы данных в нее могут быть добавлены ( ADD ) дополнительные файлы и файловые группы или удалены ( REMOVE ) ранее определенные файлы или файловые группы. Назначение этих файлов нам будет более понятно после того, как мы познакомимся с физическими моделями и файловыми структурами, используемыми для хранения данных в базах данных.
Сейчас мы познакомимся с последней командой, которая предназначена для уда-
ления базы данных. В MS SQL Server это команда имеет следующий синтаксис: DROP DATABASE database_name
После выполнения этой команды уничтожается вся база данных вместе с содержащимися в ней данными.
11.4. Средства изменения описания таблиц и средства удаления таблиц
В язык SQL добавлены средства изменения схемы таблиц. Что можно и что нельзя изменять в описании таблицы? В стандарте SQL2 добавлены достаточно широкие возможности по модификации уже существующих схем таблиц. Для модификации таблиц используется оператор ALTER TABLE, который позволяет выполнить следующие операции изменения для схемы таблицы:
добавить новый столбец в уже существующую и заполненную таблицу;
изменить значение по умолчанию для какого-либо столбца;
удалить столбец из существующей таблицы;
добавить или удалить первичный ключ таблицы;
добавить или удалить новый внешний ключ таблицы;
добавить или удалить условие уникальности;
добавить или удалить условие проверки для любого столбца или для таблицы в целом.
Синтаксис оператора ALTER TABLE:
<Изменить описание таблицы>::= ALTER TABLE <имя таблицы> { ADD определение столбца>
ALTER <имя столбца> {SET DEFAULT <значение>
DROP DEFAULT } |
DROP <имя столбца> {CASCADE | RESTRICT} | ADD { <определение первичного ключа>| <определение внешнего ключа> | <условие уникальности данных> | <условие проверки> } |
DROP CONSTRAINT имя условия { CASCADE | RESTRICT} }
Одним оператором ALTER TABLE можно провести только одно из перечисленных изменений, например, за один раз можно добавить один столбец. Если вам требуется добавить два столбца, то необходимо применить два оператора.
Давайте рассмотрим несколько примеров. Чаще всего применяется операция добавления столбца. Предложение определения нового столбца в операторе ALTER
TABLE имеет точно такой же синтаксис, как и в операторе создания таблицы. Добавим столбец EDUCATION (образование), содержащий символьный тип данных, с заданным перечнем значений ("начальное", "среднее", "неоконченное высшее", "высшее").
ALTER TABLE READERS
ADD EDUCATION varchar (30) DEFAULT NULL CHECK (EDUCATION IS NULL OR EDUCATION= "начальное" OR
EDUCATION= "среднее " OR EDUCATION= "неоконченное высшее" OR EDUCATION= "высшее" )
В таблицу READERS будет добавлен столбец EDUCATION, в который по умолчанию будут добавлены все кортежи неопределенного значения. В дальнейшем эти значения могут быть заменены на одно из допустимых символьных значений.
Добавим ограничение на соответствие между датами взятия и возврата книги в таблице EXEMPLAR. Действительно, если даты введены, то требуется, чтобы дата возврата книги была бы больше на срок выдачи книги. Считаем, что стандартным сроком являются 2 недели. Теперь сформулируем оператор изменения таблицы EXEMPLARE:
ALTER TABLE EXEMPLARE
ADD CONSTRAINT CK_ EXEMPLARE CHECK ((DATA_IN IS NULL AND DATA_OUT IS NULL) OR
(DATA_OUT >= DATA_IN +14) )
Здесь мы применили операцию сложения к календарной дате, которая предполагает, что добавляют заданное число дней.
Операция удаления столбца связана с проверкой ссылочной целостности, и поэтому не разрешается удалять столбцы, связанные с поддержкой ссылочной целостности таблицы, то есть нельзя удалить столбцы родительской таблицы, входящие в первичный ключ таблицы, если на них есть ссылки в подчиненных таблицах.
При изменении первичного ключа таблицы следует быть внимательными. Во-пер- вых, у исходной таблицы могут быть подчиненные, при этом первичный ключ исходной таблицы является внешним ключом для подчиненных таблиц, и просто его удалить невозможно, СУБД контролирует ссылочную целостность и не позволит выполнить операцию удаления первичного ключа таблицы, если на него имеются ссылки. Следовательно, в этом случае порядок изменения первичного ключа должен быть таким, как на рис. 11.1:
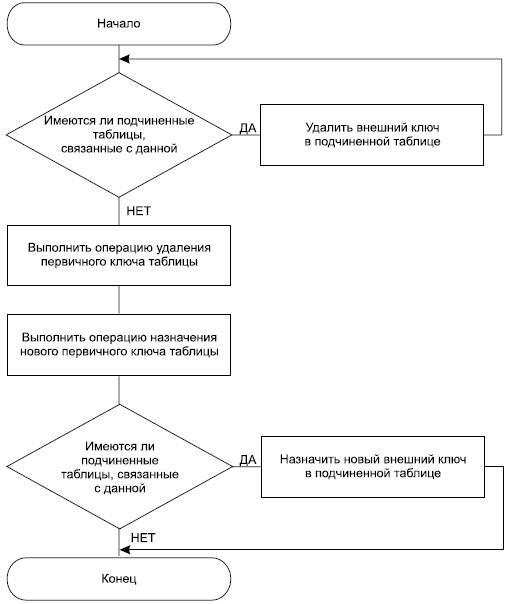
Рис. 11.1. Алгоритм изменения первичного ключа таблицы
Чаще всего операция ALTER TABLE применяется в CASE-системах при автоматической генерации скриптов создания таблиц в базе данных. В этих системах универсальный алгоритм предполагает сначала создание всех таблиц, которые заданы в даталогической модели, и только после этого добавляются соответствующие связи. И это понятно — в отличие от человеческого разума искусственный интеллект CASE-си- стемы будет испытывать затруднения в определении иерархических взаимосвязей таблиц базы данных, поэтому он предпочитает использовать универсальный алгоритм, в котором сначала все объекты определяются, а затем добавляются соответствующие свойства для атрибутов, которые являются внешними ключами с указанием требуемых ссылок. В этом случае все операции назначения внешних ключей будут считаться корректными, потому что все объекты были описаны заранее, и для такого алгоритма порядок создания таблиц безразличен.
В языке SQL присутствует и операция удаления таблиц. Синтаксис этой операции предельно прост:
<Удалить таблицу>::= DROP TABLE <имя таблицы> [CASCADE | RESTRICT]
Параметр CASCADE означает, что при удалении таблицы одновременно удаляются и все объекты, связанные с ней. С таблицей, кроме рассмотренных ранее ограничений, могут быть связаны также объекты типа триггеров и представления. Однако операция удаления объектов определяется еще правами пользователей, что связано с концепцией безопасности в базах данных. Это значит, что если вы не являетесь владельцем объекта, то вы можете не иметь прав на его удаление. И в этом случае синтаксически правильный оператор DROP TABLE не может быть выполнен системой в силу отсутствия прав на удаление связанных с удаляемой таблицей объектов. Кроме того, операция удаления таблицы не должна нарушать целостность базы данных, поэтому удалять таблицу, на которую имеются ссылки других таблиц, невозможно.
Например, в нашей схеме, связанной с библиотекой, мы не можем удалить ни таблицу BOOKS, ни таблицу READERS, ни таблицу CATALOG. У этих таблиц есть связь с подчиненными таблицами EXEMPLAR и RELATION_67. Поэтому если вы хотите удалить некоторый набор таблиц, то сначала необходимо грамотно построить последовательность их удаления, которая не нарушит базовых принципов поддержки целостности вашей схемы БД. В нашем примере последовательность операторов удаления таблиц
может быть следующей:
DROP TABLE EXEMPLAR DROP TABLE RELATION_67 DROP TABLE CATALOG DROP TABLE READERS DROP TABLE BOOKS
11.5.Понятие представления. Операции создания представлений
Для описания внешних моделей в реляционной модели могут использоваться представления. Представление (View) — это SQL-запрос на выборку, который пользователь воспринимает как некоторое виртуальное отношение. Задание представлений входит в описание схемы БД в реляционных СУБД. Представления позволяют скрыть ненужные несущественные детали для разных пользователей, модифицировать реальные структуры данных в удобном для приложений виде и, наконец, разграничить права доступа к данным и тем самым повысить защиту данных от несанкционированного доступа.
В отличие от реальной таблицы представление в том виде, как оно сконструировано, не существует в базе данных, это действительно только виртуальное отношение, хотя все данные, которые представлены в нем, действительно существуют в базе данных, но в разных отношениях. Они скомпонованы для пользователя в удобном виде из реальных таблиц с помощью некоторого запроса. Однако пользователь может этого не знать, он может обращаться с этим представлением как со стандартной таблицей. Представление при создании получает некоторое уникальное имя, его описание хранится в описании схемы базы данных, и СУБД в любой момент времени при обращении к этому представлению выполняет запрос, соответствующий его описанию, поэтому пользователь, работая с представлением, в каждый момент времени видит действительно реальные, актуальные на настоящий момент данные. Оно формируется как бы на лету, в момент обращения.
Оператор определения представления имеет следующий вид: <создание представления>::= CREATE VIEW <имя представления>
[ (<список столбцов>)] AS <SQL-запрос>
При необходимости в представлении можно задать новое имя для каждого столбца виртуальной таблицы. При этом надо помнить, что если указывается список столбцов, то он должен содержать ровно столько столбцов, сколько содержит их SQL-
запрос.
Если список имен столбцов в представлении не задан, то каждый столбец представления получает имя соответствующего столбца запроса.
Рассмотрим типичные виды представлений и их назначение.
Горизонтальное представление
Этот вид представления широко применяется для уменьшения объема реальных таблиц в обработке и ограничения доступа пользователей к закрытой для них информации. Так, например, правилом хорошего тона считается, что руководитель подразделения в некоторой фирме может видеть оклады и результаты работы только своих сотрудников, в этом случае для него создается горизонтальное представление, в которое загружены строки общей таблицы сотрудников, работающих в его подразделении.
Например, у нас есть таблица "Сотрудник" ( EMPLOYEE ) с полями "Табельный номер" ( T_NUM ), "ФИО" ( NAME ), "должность"( POSITION ), "оклад"( SALARY ), "надбав-ка"( PREMIUM ), "отдел" ( DEPARTMENT ).
Для приложения, с которым работает начальник отдела продаж, будет создано представление
CREATE VIEW SAL_DEPT AS
SELECT *
FROM EMPLOYEE
WHERE DEPARTMENT= "Отдел продаж"
Вертикальное представление
Этот вид представления практически соответствует выполнению операции проектирования некоторого отношения на ряд столбцов. Он используется в основном для скрытия информации, которая не должна быть доступна в конкретной внешней модели.
Например, для работника табельной службы, который учитывает присутствие сотрудников на работе, информация об окладе и надбавке должна быть закрыта. Для него можно создать следующее вертикальное представление:
CREATE VIEW TABEL AS
SELECT T_NUM, NAME, POSITION, DEPARTMENT FROM EMPLOYEE
Сгруппированные представления
Эти представления содержат запросы, которые имеют группировку. Сгруппированные представления всегда должны содержать список столбцов. Они могут использовать агрегированные функции в качестве результирующих столбцов, а в дальнейшем это представление может использоваться как виртуальная таблица, например, в других запросах.
Создадим представление, которое определяет суммарный фонд заработной платы и надбавок по каждому подразделению с указанием количества сотрудников, мини-
мальной, максимальной и средней зарплаты и надбавки по подразделению. Такой запрос позволяет сравнить заработную плату и надбавки прямо по всем подразделениям, и он может быть очень эффективно использован администрацией при проведении сравнительного анализа подразделений фирмы.
CREATE VIEW RATE
DEPARTMENT, COUNT(*), SUM(SALARY), SUM(PREMIUM), MAX(SALARY), MIN(SALARY),
AVERAGE (SALARY), MAX(PREMIUM), MIN(PREMIUM), AVERAGE (PREMIUM) AS
SELECT DEPARTMENT, COUNT(*), SUM(SALARY), SUM(PREMIUM), MAX(SALARY), MIN(SALARY), AVERAGE (SALARY), MAX(PREMIUM), MIN(PREMIUM),
AVERAGE (PREMIUM) FROM EMPLOYEE GROUP BY DEPARTMENT
Объединенные представления
Часто представления базируются на многотабличных запросах. Такое использование позволяет упростить разработку пользовательского интерфейса, сохранив при этом корректность схемы базы данных. Для примера снова обратимся к базе данных "Библиотека" и создадим представление, которое содержит список читателей-должни- ков с указанием книг, которые у них на руках, и указанных в базе сроков сдачи этих книг. Такое представление может понадобиться для административного приложения, которое разрабатывается для директора библиотеки или его заместителя, они должны принимать административные меры для наказания нарушителей и возврата книг в библиотеку.
CREATE VIEW DEBTORS
ISBN, TITLE, NUM_READER,NAME,ADRES,HOME_PHON, WORK_PHON,DATA_OUT AS
SELECT ISBN, TITLE, NUM_READER, NAME, ADRES, HOME_PHON, WORK_PHON, DATA_OUT
FROM BOOKS, EXEMPLAR, READERS WHERE BOOKS.ISBN = EXEMPLAR.ISBN AND
EXEMPLAR.NUM_READER = READERS.NUM_READER AND EXEMPLAR.PRESENT = FALSE AND EXEMPLAR.DATA_OUT < GetDate()