

Idf (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт idf уменьшает вес широкоупотребительных слов.
![]() ,
,
где
|D| — количество документов в корпусе;
![]() —
количество
документов, в которых встречается ti (когда
—
количество
документов, в которых встречается ti (когда ![]() ).
).
Таким образом, мера TF-IDF является произведением двух сомножителей: TF и IDF.
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
Достоинством данного метода является то, что он учитывает не конкретный документ, а все документы коллекции. Недостатком — существенное занижение веса документов включающих схожие определения и синонимы, документов большой длины, которые по определению будет проигрывать по TF коэффициенту, и завышение веса «коротких» документов, по этой же причине. Также многократное повторение в бесполезном тексте ключевого слова приводит к неверной высокой оценке.
PageRank
PageRank (пэйдж-ранк) — один из алгоритмов ссылочного ранжирования.
Алгоритм применяется к коллекции документов, связанных гиперссылками (таких, как веб-страницы из всемирной паутины), и назначает каждому из них некоторое численное значение, измеряющее его «важность» или «авторитетность» среди остальных документов.
PageRank — это числовая величина, характеризующая «важность» веб-страницы. Чем больше ссылок на страницу, тем она становится «важнее». Кроме того, «вес» страницы А определяется весом ссылки, передаваемой страницей B. Таким образом, PageRank — это метод вычисления веса страницы путём подсчёта важности ссылок на неё.
Надстройка для браузера Google Toolbar показывает для каждой веб-страницы целое число от 0 до 10, которое она называет PageRank, или важностью этой страницы с точки зрения Google. Однако механизм его расчета и что в точности обозначает это значение не раскрывается. По некоторым данным, эти значения обновляются лишь несколько раз в год (в то время, как внутренние значения PageRank пересчитываются непрерывно) и показывают значения PageRank страниц на логарифмической шкале.
Достоинство состоит в том, что учитывается не только содержание конкретной страницы, но и «мнение» и «популярность» среди других страниц. Недостатком является возможность искусственного увеличения PageRank путем создания пустых сайтов с множеством ссылок.
LexRank
Исследуя документ, LexRank работает не с отдельными словами, а с целыми предложениями. Из предложений составляется граф, а затем оценивается вес каждого предложения.
Тематический индекс цитирования
Тематический индекс цитирования (тИЦ) — технология поисковой машины «Яндекс», заключающаяся в определении авторитетности интернет-ресурсов с учётом качественной характеристики — ссылок на них с других сайтов. тИЦ рассчитывается по специально разработанному алгоритму, в котором особое значение придаётся тематической близости ресурса и ссылающихся на него сайтов. Данный показатель в первую очередь используется для определения порядка расположения ресурсов в рубриках каталога «Яндекса». Все ссылающиеся сайты обязательно должны быть проиндексированы Яндексом. При этом на соответствующих страницах каталога указываются лишь округлённые значения, которые помогают приблизительно ориентироваться в авторитетности ресурсов раздела.
ТИЦ определяется суммарным весом ссылающихся сайтов. Не могут влиять на тИЦ сайты, где любой человек может поставить свою ссылку без ведома администратора ресурса. (тИЦ) имеет систему апдейтов (пересчетов показателей) и обычно его обновление происходит 2 раза в месяц.
Гугл большое значение придает тому, как долго сайт находится в сети.
Помимо примитивного "исторического" подсчета существования сайта, Гугл немалое значение придает и таким данным (а их можно то же отнести к хронологической составляющей алгоритма), как:
- продолжительность нахождения контента на сайте (дата появления контента);
- сколько времени прошло с того момента, как часть контента (например, статья) была процитирована другим ресурсом. Иными словами, учитывается не только появление статьи на другом сайте, но и момент ее появления;
- количество сайтов, которые процитировали статью - причем, это делается не только по объему цитирований, но и по промежутку времени между ними.
Алгоритм Гугла очень четко отслеживает объемы обновлений, которые происходят на сайте.
В заключении этого пункта отметим следующее. Гугл анализирует и запоминает:
- как часто менялись страницы;
- существенность этих изменений;
- как меняется плотность ключевых слов на странице;
- изменялись ли якорные тексты ссылок.
Как известно, Гугл оперирует значениями Page Rank для того, что бы определить насколько весома страница. Домен, на котором находится сайт, очень о многом говорит Гуглу. Репутация хостинг-компании - еще один аспект, который учитывается Гуглом.
Технологии ранжирования Гугл основаны на понимании страниц, запросов и пользователей. Понимание страниц обеспечивается технологиями краулинга и индексирования. Одна из ключевых технологий, которая была разработана для понимания страниц, привязывает логически-важные понятия к странице, даже если она их не содержит.
Понимание запросов включает в себя систему распознавания текстового содержимого, развитую систему синонимов и очень мощную систему анализирования.
Другая технология, которая используется в системе ранжирования — это поиск идеи. Обнаружение главной идеи запроса позволяет возвратить намного более релевантные результаты. Работа по пониманию намерений пользователя нацелена на возврат результатов, которые действительно хотят пользователи получить, а не просто тех, которые они написали в своем запросе. Эта работа начинается с системы локализации мирового уровня. И добавляет улучшенную технологию индивидуализации и несколько других больших шагов, таких как Универсальный Поиск. Упор на принцип «наиболее релевантные запросу результаты» отражается в нашей работе по локализации. Один и тот же запрос, написанный в различных странах, даст абсолютно разные результаты.
Персонализация — это еще одна сильная особенность нашей поисковой системы, которая подгоняет результаты поиска для каждого пользователя. Пользователи, которые "залогинились" во время поиска и имеют включенный журнал посещений, получают результаты, которые более релевантны для них, чем общие результаты Google.
Работа над Универсальным Поиском — это ещё один пример нашего толкования намерений пользователя для предоставления им того, что они (иногда) на самом деле хотят. Т.е., кто ищет [bangalore], получают не только нужные веб-страницы, также ему становится доступна карта, видео, жизнь на улицах Бангалоре и т.д., и плюч ко всему еще и новости/блоги о Бангалоре.
Последнее улучшение, сделанное в механизме поиска: Cross Language Information Retrieval (CLIR). Это позволяет пользователям сначала получить информацию не на их родном языке, а затем, используя технологию перевода Google, информация становится доступной. Воплощается принцип «дайте мне то, что мне нужно, на любом языке».
Yandex
Для оценки релевантности сайта Яндекс использует технологию Матрикснет. Важная особенность этого метода — в том, что он устойчив к переобучению. Это позволяет учитывать очень много факторов ранжирования — и при этом не увеличивать количество оценок асессоров и не опасаться, что машина найдет несуществующие закономерности.
С помощью Матрикснета можно построить очень длинную и сложную формулу ранжирования, которая учитывает множество различных факторов и их комбинаций. Другие методы машинного обучения позволяют либо строить более простые формулы с меньшим количеством факторов, либо нуждаются в большей обучающей выборке. Матрикснет строит формулу с десятками тысяч коэффициентов. Это позволяет сделать существенно более точный поиск. Ещё одна важная особенность Матрикснета — в том, что формулу ранжирования можно настраивать отдельно для достаточно узких классов запросов. При этом ранжирование по остальным классам запросов не ухудшится. Кроме того, Матрикснет автоматически выбирает разную чувствительность для разных диапазонов значений факторов ранжирования. Поиск ведётся одновременно на тысячах серверов. Каждый сервер ищет по своей части индекса и формирует список самых лучших результатов. В него гарантированно попадают все самые релевантные запросу страницы.
Дальше из этих списков составляется один общий, и страницы, попавшие туда, упорядочиваются по формуле ранжирования — той самой длинной и сложной формуле, построенной с помощью Матрикснета, с учётом всех факторов и их комбинаций.
Расширенный поиск
Рассмотрим на примере Яндекса.
Яндекс позволяет решать сложные поисковые задачи, не пользуясь языком запросов. Для этого воспользуйтесь формой расширенного поиска, где сложные поисковые условия задаются в простой и наглядной форме.
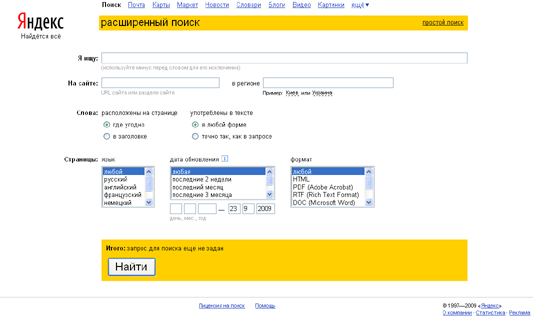
Обратите внимание, что при заполнении нескольких полей Яндекс учтет все заданные вами условия одновременно.
Поиск на сайте
Яндекс позволяет искать страницы не только по всей базе, но и по группе страниц, расположенных на одном или нескольких сайтах. Для этого достаточно указать через запятую адреса сайтов в поле находятся на сайте.
Если вы нашли качественный сайт, на котором много информации на интересующую вас тему, эффективней поискать ответ именно на нем, чем по всей базе сайтов. Поиск по сайту также выручает, когда на каком-либо сайте нет функции поиска (правда, следует помнить, что Яндекс мог проиндексировать не все страницы сайта).
Блок «Cлова»
Вы можете указать, в каких частях страницы нужно вести поиск слов запроса.
Есть два варианта:
-где угодно - поиск слов идет везде на странице;
-в заголовке - поиск ведется в заголовке страницы (title);
Яндекс понимает морфологию слов и ищет по запросу все их формы.
Если вы хотите найти слова в определенной форме, выберите один из вариантов:
-в любой форме - аналогично действиям Яндекса по умолчанию.
-точно так, как в запросе - слово будет искаться только в той форме, которую вы указали. Блок «Страницы»
Язык
Яндекс может отбирать для вас страницы только на определенном языке. Если вам интересны несколько языков, удерживая клавишу Shift, выберите нужные.
Дата обновления
Если вы хотите составить ретроспективу определенных событий, вы можете делать это, как добавляя к тексту запроса даты, так и сделав по запросу выборку документов, созданных в определенный период. Вы можете либо выбрать из списка срок давности документа, либо указать точный диапазон дат.
Формат страницы
Яндекс понимает документы, созданные в нескольких форматах: HTML, PDF (Adobe Acrobat Reader), RTF, DOC (Microsoft Word), XLS (Microsoft Excel), PPT (PowerPoint), SWF (Macromedia Flash). Если вам интересны определенные форматы, удерживая клавишу Shift, выберите нужные.
Ограничение по формату полезно, когда вы ищете научные статьи или инструкции — подобные документы редко выкладываются в HTML из-за большого количества формул и графики.
Итого
После слова «Итого» вы можете прочитать описание заданного запроса на естественном языке. Выглядеть это может, например, так:

Все параметры поиска, у которых вы не меняли значение по умолчанию, не упоминаются.
Так же возможен поиск с использованием языка запросов. Приведем основные примеры.
Поисковый контекст
Вы можете указать требования к совместной встречаемости слов запроса.
Точное совпадение
Слова идут подряд в точной форме
Такой порядок слов можно указать с помощью запроса в кавычках.
Джокер
При поиске точного выражения в кавычках вы можете разрешить одно или несколько пропущенных слов. Для этого используйте одну или несколько звездочек через пробел.
"ползет змея, как * дьявола"
Совместная встречаемость
В одном предложении
Ограничить поиск страницами, где слова запроса находятся в пределах предложения, вы можете, соединив слова оператором & через пробел.
В одном документе
Если вам нужны документы, где присутствуют заданные слова — неважно, на каком расстоянии друг от друга и в каком порядке — соедините их оператором && через пробел.
Исключить слова
В одном документе
Яндекс позволяет исключать из поисковой выдачи страницы, где есть определенные слова. Для этого используется оператор ~~, слева от которого вы пишете через пробел «что искать», а справа — какие страницы исключать из поиска.
В одном предложении
Иногда требуется, чтобы слово встречалось на странице, но не в одном предложении с другим словом запроса. С этой целью используйте оператор ~.
Расстояние между словами
Вы можете регулировать расстояние между словами с точностью до слова.
Расстояние между словами a и b — это разница между номерами слов b и a. Таким образом, расстояние между соседними словами равно 1 (а не 0), а расстояние между соседними словами, стоящими "не в том порядке", равно -1.
Слова на расстоянии в несколько слов
Вы можете указать максимально допустимое расстояние между двумя любыми словами запроса, поставив после первого слова символ /, сразу за которым идет число, означающее расстояние.
Слова на расстоянии в несколько предложений
Аналогично записи, указывающей расстояния между словами, вы можете задавать расстояние в предложениях. Для этого перед оператором расстояния / нужно указать оператор &&.