

llama / llama_bachelor_MPiTK_2004_VM-1
.pdf- 31-
Шаг 3. Построить разбиение Ωi = {ωk }kL=−10 множества обучающих векторов {am}, где ячейки разбиения определяются по текущей кодовой книге Ci = {cik }kL=−10 , следующим образом:
ω |
k |
= |
|
a |
A |
J |
( |
a |
m |
,ci |
= |
min |
( |
J |
( |
a |
m |
,ci |
= D |
( |
a |
m |
,ci |
+ λR |
( |
a |
m |
,ci |
. |
|
||||||
|
|
|
{ m |
|
|
|
k ) |
|
j=0,...,L−1 |
|
|
j ) |
|
|
|
j ) |
|
|
|
j ))} |
|
|
||||||||||||||
Шаг 4. |
Вычислить |
среднее |
|
|
значение |
функционала |
J |
|
|
для последовательности |
||||||||||||||||||||||||||
a0 ,...,aM −1 : |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
L−1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ei+1 = |
|
|
|
å å J (am ,cik ). |
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
M k =0 amωk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Шаг 5. Если |
|
Ei |
− Ei+1 |
< ε , то положить J probe |
= Ei+1 |
и перейти на шаг 6, |
иначе |
|||||||||||||||||||||||||||||
|
|
|
Ei+1 |
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
перейти на шаг 5. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Шаг 6. Найти новые кодовые векторы усреднением по ячейкам: |
|
|
||||||||||||||||||||||||||||||||||
cik |
= |
|
|
1 |
|
|
å am , |
k = 0,..., L −1, |
где |
|
|
|
{am ωk } |
|
|
|
– |
количество векторов |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
{am |
ωk } |
|
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
amωk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
обучающей последовательности, попавших в ячейку ωk . |
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
Положить i = i +1 и перейти на шаг 3. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
Шаг |
7. |
Если |
|
J probe < JL−1 , |
|
|
то |
|
положить |
|
|
|
JL |
= J probe , |
|
|
j = j +1, C = Ci , |
иначе |
||||||||||||||||||
положить L = L −1 и q = q +1. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
Шаг 8. |
Проверка возможности останова. Если |
L = Lmax |
|
или |
q = qmax , то положить |
|||||||||||||||||||||||||||||||
C* = C и завершить работу алгоритма, иначе перейти на шаг 1. |
|
|
|
|
||||||||||||||||||||||||||||||||
Конец. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
2.4. Общая схема алгоритма сжатия изображений
Разработанный алгоритм, как следует из сказанного выше, должен состоять из двух частей. В первой части строится кодовая книга, которая потом используется как начальная кодовая книга для алгоритма адаптивного векторного квантования. Для всех изображений, подлежащих сжатию, можно использовать одну и ту же кодовую книгу, а значит, первую часть алгоритма нужно запустить всего один раз и полученную на ее выходе кодовую книгу сохранить, например, в виде файла, который затем используется второй частью – как кодером, так и декодером. Таким образом, для сжатия изображения

- 32-
не требуется каждый раз запускать алгоритм, описанный в п.0, который обладает невысокой скоростью работы, а также хранить кодовую книгу вместе со сжатым файлом, что приводит к повышению битовых затрат.
Вторая часть алгоритма представляет собой обычную реализацию алгоритма GTR (п.1.2.6). Кодирование выходных потоков индексов и скалярно проквантованных
компонент векторов производится адаптивным многомодельным арифметическим кодером [1].
Баланс между качеством и сжатием при кодировании изображения определяется параметром λ , т.е. для каждого значения λ требуется построить свой набор кодовых книг.
2.4.1. Построение кодовых книг по обучающей последовательности векторов
Шаг 1. С помощью алгоритма, описанного в п.1.2.8, найти разбиение матрицы ДКП (8×8 ) на слабо коррелированные друг с другом подмножества (кластеры). Оптимальное число – 14 кластеров.
Шаг 2. Найти поблочное (8×8 ) ДКП обучающего изображения.
Шаг 3. В каждом из получившихся блоков преобразовать набор элементов, входящих в один и тот же кластер, в вектор. Векторы из всех блоков группируются в наборы по кластерам, которым они принадлежат*.
Шаг 4. Построить кодовые книги по каждому набору векторов, полученному на предыдущем шаге (всего 14 книг) с помощью алгоритма, описанного в п.0. Вместе с n -й
кодовой книгой вычисляется и массив вероятностей кодовых векторов { pk0}Lkn=−01 , который далее используется при кодировании.
* Приведем пример. Пусть изображение состоит из |
N блоков 2× 2 : {B0 |
æ i |
i |
ö |
а |
,..., BN −1} , где Bi = ç b11i |
b12i |
÷ |
|||
|
|
èb21 |
b22 |
ø |
|
матрица разбиения на кластеры выглядит следующим образом: |
æ 1 |
2 |
ö |
. Тогда |
i |
-й блок будет разделен на два |
||||
ç |
1 |
÷ |
||||||||
|
è 2 |
ø |
|
|
|
|
|
|
|
|
вектора: a1i = {b11i ,b22i } и ai2 = {b12i ,b21i } , а группировка векторов будет проведена так: |
A1 |
= {a1i }N −1 , |
A2 |
= {ai2 |
}N −1 . |
|||||
|
|
|
|
|
|
|
i=0 |
|
|
i=0 |
- 33-
Шаг 5. Строится массив вероятностей {πk0}kK=0 скалярно проквантованных компонент
векторов, полученных на шаге 3 (здесь K – максимальная амплитуда проквантованного сигнала).
Шаг 6. Разбиение матрицы ДКП на кластеры, кодовые книги, массивы вероятностей и параметр λ сохраняются в постоянную память и далее не изменяются.
Конец.
В экспериментах использовались обучающие изображения, «склеенные» из нескольких стандартных тестовых изображений (см. приложение 1):
Лена+Барбара+Goldhill (1536×512 );
Лена+Собор+Лодка (1792×512 ).
2.4.2. Сжатие изображения
Шаг 1. Вычисляется поблочное ДКП изображения (всего M блоков).
Шаг 2. Каждый блок разбивается на кластеры. ДКП-спектр изображения разбивается на подмножества аналогично шагу 3 алгоритма, описанного в п.2.4.1.
Шаг 3. Каждое подмножество кодируется отдельно с помощью алгоритма GTR (используется то же значение параметра λ , с которым были построены кодовые книги),
на выходе которого получается массив индексов векторов кодовой книги {I (c*k )}Mk=0 и
массив {aˆupdatek }kN=0 скалярно проквантованных векторов, дополнительно занесенных в
кодовую книгу. Для скалярного квантования компонент каждого вектора используется один из четырех квантователей, оптимальный выбирается из них по критерию
минимума функции JSQ = DSQ + λRSQ , |
где битовые затраты на |
кодирование |
проквантованных компонент вектора оцениваются по вероятностям {πki }K |
: |
|
|
k=0 |
|
RSQ = − å log2 πki . |
|
|
ˆ |
ˆ |
|
k:ak a |
|
|
Шаг 4. Постоянная составляющая квантуется отдельно скалярным квантователем и кодируется с помощью дифференциальной импульсно-кодовой модуляции (ДИКМ).
Шаг 5. Проводится статистическое кодирование массивов {I (c*k )}Mk=0 и {aˆupdatek }kN=0 с
помощью многомодельного арифметического кодера. Для массива индексов каждого кластера используется отдельная модель, а компоненты всех векторов массива

- 34-
{aˆupdatek }kN=0 кодируются в одной модели. Отдельные модели используются также для
кодирования постоянной составляющей и номеров скалярных квантователей, с помощью которых проводилось квантование.
Шаг 6. Выходной поток данных выводится в файл побайтно в двоичном виде.
Конец.
Декодирование изображения производится в обратном порядке.
2.5. Реализация алгоритма сжатия изображений
Описанный в предыдущем параграфе алгоритм был реализован на языке пакета MATLAB 6.5 с использованием дополнительных наборов функций Image Processing Toolbox и External Interfaces API. Наиболее критичные для производительности алгоритма функции – поблочное ДКП, поиск в кодовой книге вектора с минимальным значением J методом полного перебора и алгоритм GTR – были реализованы на языке C и скомпилированы компилятором CL производства Microsoft в MEX-библиотеки, используемые средой MATLAB. Для реализации арифметического кодера были использованы оригинальные исходные тексты программы на языке C++, описанной в
[1].Они также были скомпилированы в виде MEX-библиотеки.
2.6.Сравнение алгоритма с существующими методами сжатия изображений
2.6.1. Условия тестирования
Реализованный алгоритм сравнивался со стандартным методом JPEG и его модификацией, использующей вместо кодирования Хаффмана арифметическое кодирование. Работа алгоритма тестировалась при различных параметрах: изменялось число кластеров, размеры кодовых книг, параметр λ , величины скалярных квантователей.
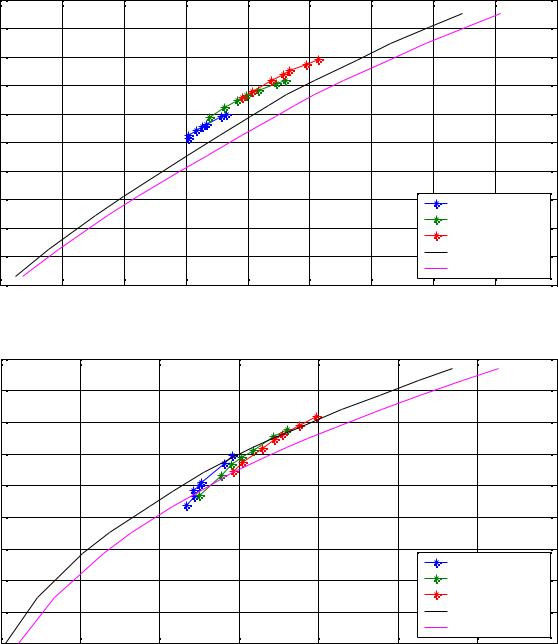
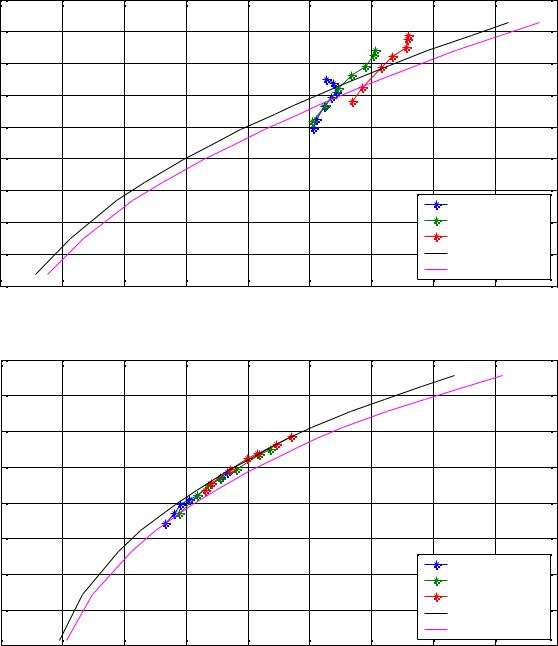
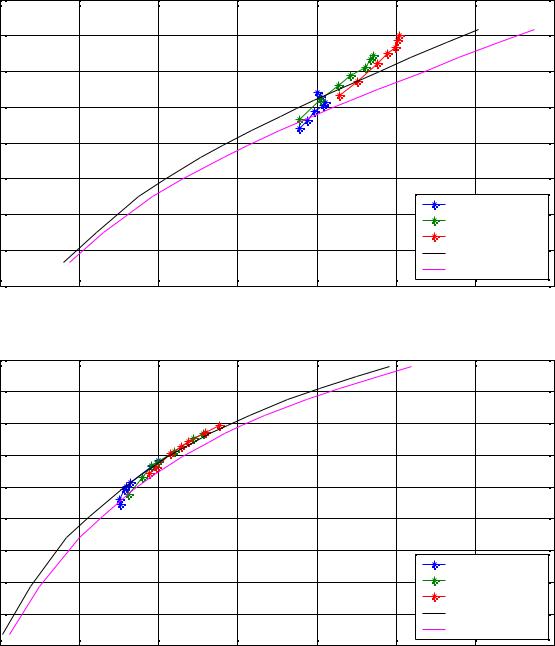
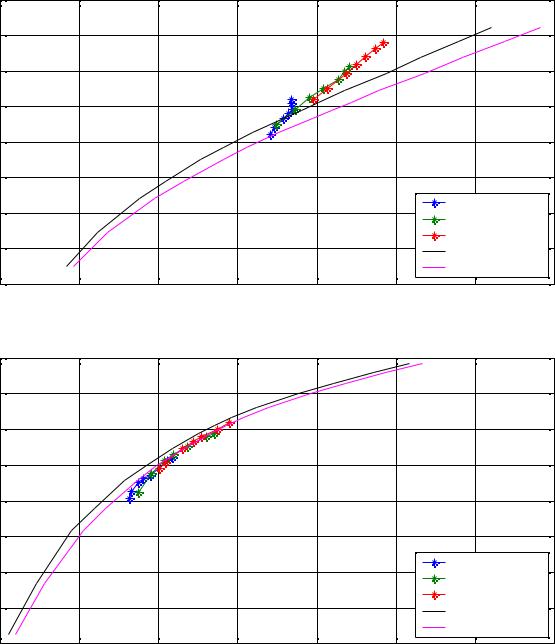
Эксперименты проводились на девяти тестовых изображениях: Barbara, Boat, Cathedral, Goldhill, House, Lena, Mandrill, Peppers и Zelda. Для оценки качества сжатия изображения использовалась оценка PSNR (см. п.1.2.2). Мерой битовых затрат являлось число бит, затраченное на кодирование изображения, приходящихся на 1 пиксель (bits
per pixel): BPP = MN8S , где S – размер файла в байтах, а M,N – размеры изображения в пикселях. На всех графиках буквой L обозначены длины кодовых книг. Приведены
|
|
|
|
|
- 35- |
|
|
|
|
|
только графики для значения |
λ = 2 ; алгоритм тестировался и на других значениях |
λ |
||||||||
(0…3), но выигрыш по битовым затратам был для каждого изображения примерно |
||||||||||
одинаковым в процентном соотношении. |
|
|
|
|
|
|||||
2.6.2. Сравнение с алгоритмом JPEG (сжатие по Хаффману и |
|
|||||||||
арифметическое) |
|
|
|
|
|
|
|
|
||
|
33 |
Compression of barbara.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
32 |
|
|
|
|
|
|
|
|
|
|
31 |
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
dB |
29 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PSNR, |
28 |
|
|
|
|
|
|
|
|
|
27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
26 |
|
|
|
|
|
|
|
Clusters=10 |
|
|
25 |
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
Clusters=14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
24 |
|
|
|
|
|
|
|
JPEG Arithm. |
|
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
23 |
0.2 |
0.3 |
0.4 |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
1 |
|
0.1 |
|||||||||
|
|
|
|
|
BPP |
|
|
|
|
|
|
|
|
Compression of boat.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
|
|||||
|
35 |
|
|
|
|
|
|
|
|
34 |
|
|
|
|
|
|
|
|
33 |
|
|
|
|
|
|
|
|
32 |
|
|
|
|
|
|
|
dB |
31 |
|
|
|
|
|
|
|
PSNR, |
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
29 |
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
|
|
|
|
28 |
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
Clusters=14 |
|
|
27 |
|
|
|
|
|
JPEG Arith |
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
26 |
0.2 |
0.3 |
0.4 |
0.5 |
0.6 |
0.7 |
0.8 |
|
0.1 |
|||||||
|
|
|
|
|
BPP |
|
|
|
|
|
|
|
|
- 36- |
|
|
|
|
|
|
32 |
|
Compression of cathedral.TIF, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
31 |
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
29 |
|
|
|
|
|
|
|
|
|
dB |
28 |
|
|
|
|
|
|
|
|
|
PSNR, |
|
|
|
|
|
|
|
|
|
|
27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
26 |
|
|
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
25 |
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
|
Clusters=14 |
|
|
24 |
|
|
|
|
|
|
|
JPEG Arith |
|
|
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
23 |
0.2 |
0.3 |
0.4 |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
1 |
|
0.1 |
|||||||||
|
|
|
|
|
|
BPP |
|
|
|
|
|
|
Compression of goldhill.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
|
||||||
|
34 |
|
|
|
|
|
|
|
|
|
|
33 |
|
|
|
|
|
|
|
|
|
|
32 |
|
|
|
|
|
|
|
|
|
dB |
31 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PSNR, |
30 |
|
|
|
|
|
|
|
|
|
29 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
28 |
|
|
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
27 |
|
|
|
|
|
|
|
Clusters=14 |
|
|
|
|
|
|
|
|
|
JPEG Arith |
|
|
|
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
260 |
0.1 |
0.2 |
0.3 |
0.4 |
0.5 |
0.6 |
0.7 |
0.8 |
0.9 |
|
|
|
|
|
BPP |
|
|
|
|
|
|
|
|
|
- 37- |
|
|
|
|
|
29 |
|
Compression of house.TIF, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
||||
|
|
|
|
|
|
|
|
|
|
28 |
|
|
|
|
|
|
|
|
27 |
|
|
|
|
|
|
|
dB |
26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PSNR, |
25 |
|
|
|
|
|
|
|
24 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
23 |
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
|
|
|
22 |
|
|
|
|
|
Clusters=14 |
|
|
|
|
|
|
|
JPEG Arith |
|
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
210 |
0.2 |
0.4 |
0.6 |
0.8 |
1 |
1.2 |
1.4 |
|
|
|
|
|
BPP |
|
|
|
|
|
Compression of lena.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
|
|
|||
|
36 |
|
|
|
|
|
|
|
|
35 |
|
|
|
|
|
|
|
|
34 |
|
|
|
|
|
|
|
|
33 |
|
|
|
|
|
|
|
dB |
32 |
|
|
|
|
|
|
|
PSNR, |
|
|
|
|
|
|
|
|
31 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
|
|
|
|
29 |
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
Clusters=14 |
|
|
28 |
|
|
|
|
|
JPEG Arith |
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
27 |
0.2 |
0.3 |
0.4 |
0.5 |
0.6 |
0.7 |
0.8 |
|
0.1 |
|||||||
|
|
|
|
BPP |
|
|
|
|
|
|
|
|
- 38- |
|
|
|
|
|
29 |
|
Compression of mandrill.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
||||
|
|
|
|
|
|
|
|
|
|
28 |
|
|
|
|
|
|
|
|
27 |
|
|
|
|
|
|
|
dB |
26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PSNR, |
25 |
|
|
|
|
|
|
|
24 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
23 |
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
|
|
|
22 |
|
|
|
|
|
Clusters=14 |
|
|
|
|
|
|
|
JPEG Arith |
|
|
|
210 |
|
|
|
|
|
JPEG Huffman |
|
|
0.2 |
0.4 |
0.6 |
0.8 |
1 |
1.2 |
1.4 |
|
|
|
|
|
|
BPP |
|
|
|
|
|
|
Compression of peppers.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
||||
|
35 |
|
|
|
|
|
|
|
|
34 |
|
|
|
|
|
|
|
|
33 |
|
|
|
|
|
|
|
dB |
32 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PSNR, |
31 |
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
29 |
|
|
|
|
|
Clusters=10 |
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
|
|
|
28 |
|
|
|
|
|
Clusters=14 |
|
|
|
|
|
|
|
JPEG Arith |
|
|
|
|
|
|
|
|
|
JPEG Huffman |
|
|
27 |
0.2 |
0.3 |
0.4 |
0.5 |
0.6 |
0.7 |
0.8 |
|
0.1 |
|||||||
|
|
|
|
|
BPP |
|
|
|

|
|
|
|
|
- 39- |
|
|
|
|
|
|
|
38 |
|
Compression of zelda.tif, λ=2.0 L=[16 32 64 96 128 192 256 ] |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
36 |
|
|
|
|
|
|
|
|
|
|
PSNR, dB |
34 |
|
|
|
|
|
|
|
|
|
|
32 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Clusters=10 |
|
|
|
30 |
|
|
|
|
|
|
|
Clusters=12 |
|
|
|
|
|
|
|
|
|
|
Clusters=14 |
|
||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
JPEG Arith |
|
|
|
28 |
|
|
|
|
|
|
|
JPEG Huffman |
|
|
|
0.1 |
0.15 |
0.2 |
0.25 |
0.3 |
0.35 |
0.4 |
0.45 |
0.5 |
0.55 |
|
|
0.05 |
||||||||||
|
|
|
|
|
BPP |
|
|
|
|
|
|
Как видно из графиков, оптимальным является разбиение на 14 кластеров с |
|||||||||||
большими размерами кодовых книг. Выигрыш по сравнению JPEG составил от 5 до |
|||||||||||
28%. |
|
|
|
|
|
|
|
|
|
|
|
В случае использования арифметического кодирования в алгоритме JPEG общая |
|||||||||||
картина сохраняется с той лишь разницей, что графики JPEG «сдвинулись» влево на 7- |
|||||||||||
10%. В результате на одном из изображений результаты были немного ниже JPEG. В |
|||||||||||
остальных случаях выигрыш составил 3-19%. |
|
|
|
|
|
|
|||||
Заключение
В настоящей работе были достигнуты следующие результаты:
1.Апробирован алгоритм кластеризации коррелированных данных [4] в применении
кДКП-блокам изображения.
2.Предложен новый метод «условного разделения» для построения начальной кодовой книги алгоритма LBG. В применении к сжатию изображений этот метод оказался эффективнее, чем стандартные способы задания начальной книги.
3.На основе рассмотренных методов создан новый алгоритм сжатия изображений на основе ДКП и векторного квантования кластеров. В сравнении со стандартным алгоритмом JPEG, использующим ДКП и скалярное квантование, данный алгоритм оказывается эффективнее на 5-28% в мере качества PSNR при кодировании тестовых
фотографических изображений.
- 40-
Также проведен обзор теоретических основ сжатия изображений с потерями, в частности, основ векторного квантования.
Существует несколько направлений дальнейшей работы по улучшению созданного алгоритма. Во-первых, возможно использование контекстного кодирования для постоянной составляющей ДКП. Во-вторых можно применять вместо ДКП другие ортогональные преобразования, например, ДВП, так как предлагаемый алгоритм векторного квантования является универсальным и при кодовой книге, построенной по соответствующим обучающим векторам, может использоваться для сжатия любых данных. В-третьих, для более эффективного кодирования индексов векторов можно воспользоваться алгоритмом группировки индексов [10]. В-четвертых, можно использовать контекстное кодирование как индексов векторов, так и скалярно проквантованных их компонент.