

llama / llama_bachelor_MPiTK_2004_VM-1
.pdf- 11-
Шаг 4. Если JVQ (ciI* ) < JSQ , то закодировать индекс I* , увеличить счетчик i = i +1,
обновить вероятности Pi , перейти на шаг 2.
Иначе закодировать компоненты вектора aˆi , увеличить счетчик i = i +1, обновить вероятности Πi , занести вектор QS−1 (aˆi ) в кодовую книгу, увеличить L = L +1, обновить вероятности Pi . Если остались еще не закодированные векторы ai , то перейти на шаг 2,
иначе завершить работу.
Конец.
Здесь в массиве Pi хранятся вероятности, с которыми в выходном потоке индексов встречаются индексы векторов кодовой книги. При добавлении нового вектора в кодовую книгу на шаге 4 новому вектору присваивается вероятность, равная 1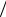 L . В
L . В
массиве Πi хранятся вероятности, с которыми в выходном потоке скалярно проквантованных векторов встречается каждое число (алфавит состоит из N таких чисел).
Данная схема может предусматривать также ограничение максимального размера кодовой книги; в этом случае при достижении ей максимального размера новые векторы не добавляются, а заменяют самые «старые» и редко используемые векторы кодовой книги.
1.2.7. Проблемы практической реализации векторных квантователей
Основной проблемой, связанной с использованием векторных квантователей является невысокая скорость их работы: самым медленным участком алгоритма квантования является поиск минимального значения функционала D или J по всем векторам кодовой книги. Этот процесс включает в себя многократное вычисление метрики, которое в случае евклидовой метрики в n -мерном пространстве и кодовой книги размером M векторов требует M (2n −1) сложений и Mn умножений на каждый квантуемый вектор; в случае учета битовых затрат помимо этого необходимо вычислить еще и M логарифмов.
Эта проблема частично решается с помощью различных методов поиска «ближайшего» вектора кодовой книги, позволяющих не проводить полный перебор всей кодовой книги ([7], раздел 12.16). Однако эти методы, разумеется, не могут
- 12-
гарантировать того, что найденный вектор действительно минимизирует целевой функционал; кроме того, в процессе работы они используют довольно большое количество оперативной памяти. В последние годы были предложены алгоритмы (например, [11]), дающие тот же результат, что и метод полного перебора, но работающие значительно быстрее (в 5-30 раз), чем он.
Другой проблемой является то, что затруднительно использовать векторный квантователь для векторов большой размерности, так как при увеличении размерности векторов резко увеличивается размер кодовой книги, необходимый для адекватного представления сигнала при квантовании.
1.2.8. Алгоритм кластеризации коррелированных данных
Проблему, связанную с увеличением размера кодовой книги при увеличении размерности кодируемых векторов, для алгоритмов кодирования изображений на основе
декоррелирующего ортогонального преобразования можно разрешить с помощью алгоритма [4]. Он основан на предположении, что для каждого элемента обобщенного дискретного спектра, представляемого в виде случайного вектора, его связи с другими элементами, определяемые соответствующими коэффициентами корреляции, существенно отличаются по величине, причем число сильных связей у каждого элемента мало (именно такой характер связей наблюдается в спектрах ортогональных преобразований, получаемых при цифровой обработке изображений).
Предположим, что кодированию будет подвергаться некоторый случайный вектор
Y = (Y0 ,Y1,...,YN −1 )T , представляющий собой коррелированный набор данных и известна ковариационная матрица K = (cov(Yk ,Yj ))kN,−j1=0 . Требуется провести разбиение вектора Y
на кластеры так, чтобы априорная неопределенность межкластерных связей была минимальна, при этом максимальная неопределенность ограничена сверху значением
Hmax .
Ниже приведена краткая схема алгоритма кластеризации.
Шаг 0. Сформировать множество невыбранных индексов A0 = {0,1,..., N −1} .
Шаг 1. Полагаем возможные границы коэффициентов корреляции: нижняя a = 0 , верхняя b = 1.
- 13-
Шаг 2.Полагаем активное множество индексов A = A0 , число сформированных кластеров J = 0 , ограничение на модуль коэффициента корреляции R = (a + b) 2 .
2 .
Шаг 3. Если активное множество пусто ( A = ), то переход на шаг 7, иначе переход на шаг 4.
Шаг 4. Начало формирования нового кластера из множества активных индексов.
Номер текущего кластера полагаем J = J +1. Далее, множество индексов нового |
|||||
кластера полагаем состоящим из одного |
индекса, |
который |
соответствует элементу |
||
вектора Y с максимальной дисперсией: M |
(J ) |
|
2 |
2 |
|
|
|
= {kJ }, где σkJ = maxσk . |
|||
|
|
|
|
|
k A |
Шаг 5. Удалить из множества активных индексов все индексы, содержащиеся в
текущем множестве индексов |
кластера: A := A \ M (J ) . Затем, просматривая все пары |
|||||||||
элементов |
из множеств A и |
M (J ) , анализируем соответствующие коэффициенты |
||||||||
корреляции: если $l Î A,m Î M (J ) : |
|
r |
|
> R , то перейти к шагу 6, иначе – к шагу 3. |
|
|||||
|
|
|
||||||||
|
|
|
|
|
l,m |
|
|
|
|
|
Шаг 6. Добавить к множеству M (J ) индекс l : M (J ) := M (J ) È{l} . Перейти на шаг 5. |
||||||||||
Шаг |
7. |
Проверить значение энтропии для всех сформированных кластеров |
||||||||
Y (1),...,Y (J ) , |
определяемых |
множествами |
индексов |
M (1),..., M (J ) . |
Если |
|||||
$k Î{1,..., J}: H (Y (k ) )> Hmax , то перейти на шаг 8, иначе – на шаг 9. |
|
|||||||||
Шаг 8. |
Проверка существования решения. Если текущая верхняя граница |
b для |
||||||||
модуля коэффициента корреляции |
слишком приблизилась |
к нулю ( b < εer ), считать |
||||||||
решение не найденным и завершить работу. В противном случае положить a := R (уменьшить нижнюю границу) и перейти на шаг 2.
Шаг 9. Если верхняя и нижняя границы для коэффициента корреляции достаточно близки друг к другу ( b − a < ε ), то перейти на шаг 10, иначе положить b := R (увеличить нижнюю границу) и перейти на шаг 2.
Шаг 10. Считать очередной кластер окончательно сформированным. Выбрать его из
Y |
(1) |
,...,Y |
(J ) |
} |
по |
максимуму |
значения |
энтропии: |
æ |
( j* ) ö |
= max |
|
H |
( |
Y |
( j) |
) |
. |
|
|
|
H çY |
÷ |
|
|
||||||||||||||
{ |
|
|
|
|
|
|
|
|
è |
ø |
j 1,...,J |
} |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
{ |
|
|
|
|
|
|
|||
Соответствующее |
множество |
индексов |
M * = M ( j* ) |
исключить |
из множества |
||||||||||||||
невыбранных индексов: A := A \ M * . Затем, если множество невыбранных индексов не |
|||||||||||||||||||
|
|
|
|
|
|
0 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
пусто ( A0 ¹ Æ ), то перейти на шаг 1, иначе завершить работу алгоритма.
Конец.
-14-
Вп.2.2 настоящей работы приведены результаты применения данного алгоритма для разбиения блоков ДКП 8×8 на различное число кластеров.
1.3.Эффективное кодирование сообщений дискретного источника без памяти
1.3.1.Понятие энтропии
Рассмотрим модель дискретного источника сообщений, который изменяет свое состояние в некоторые моменты времени, причём число возможных состояний конечно и равно N . Переходы источника X из одного состояния в другое случайны, не зависят от текущего и предыдущих состояний (говорят, что у источника сообщений «нет
памяти»), а вероятности перехода в состояние |
xj ( j =1,K, N ) |
pj = P{X = xj} заданы, |
||
N |
|
|
|
|
å pj = 1. |
|
|
|
|
j=1 |
|
|
|
|
Состояние xj |
можно понимать как реализацию случайной величины дискретного |
|||
типа, или |
как |
случайный выбор символа |
из некоторого |
символьного алфавита |
{x1,K, xN } . |
Последовательность символов на |
выходе источника представляет собой |
||
некоторое сообщение.
В качестве меры количества информации (априорной неопределённости) для
дискретного источника сообщений без памяти Шенноном была предложена следующая величина [3]:
N |
|
H ( X ) = −å pk log pk . |
(4) |
j=1
Величина (4) носит название энтропии. Основание логарифма здесь не имеет принципиального значения и определяет количество информации, приходящейся на одну единицу измерения. В цифровой обработке сигналов традиционно выбирается двоичное основание, т.е. количество информации измеряется в битах.
Величину (4) можно трактовать как среднее количество информации, приходящейся на один символ, создаваемый источником сообщения
Двоичная энтропия источника (4) является точной оценкой снизу для минимально возможных битовых затрат, приходящихся в среднем на кодирование одного символа. Об этом говорит теорема Шеннона: сообщение источника с двоичной энтропией H можно кодировать так, что ε > 0 битовые затраты R , приходящиеся на один символ

|
|
|
- 15- |
|
|
сообщения: R < H + ε , |
где |
R = lim |
RM |
( R – битовые затраты на кодирование |
|
|
|||||
|
|
M →∞ M |
M |
||
|
|
|
|||
последовательности из |
M |
символов). Невозможно построить такой декодируемый |
|||
двоичный код, для которого R < H . |
|
|
|
||
Коды, обеспечивающие минимально возможные битовые затраты, называются эффективными. Теорема Шеннона не дает правил построения эффективных кодов, а лишь определяет теоретически возможный предел для эффективности кодирования.
1.3.2. Арифметическое кодирование
Сжатие по Хаффману [12] постепенно вытесняется арифметическим кодированием [19]. При арифметическом кодировании сообщение представляется вещественным числом в интервале [0,1). По мере кодирования сообщения, отображающий его интервал уменьшается, а количество бит для его представления возрастает. Очередные
символы сообщения сокращают величину интервала исходя из значений их вероятностей, определяемых моделью. Более вероятные символы делают это в меньшей степени, чем менее вероятные, и, следовательно, добавляют меньше битов к результату.
До начала кодирования соответствующий сообщению интервал представляет собой
[0,1). При обработке очередного символа его ширина сужается за счет выделения этому символу части интервала. Рассмотрим работу арифметического кодера на примере сообщения {eaii!} алфавита {a, e, i, o, u,!}. Для этого воспользуемся статистической
моделью с постоянными вероятностями, представленной в табл. 1.
Таблица 1.1. Постоянная модель для алфавита {a, e, i, o, u,!}
Символ |
Вероятность |
Интервал |
a |
0.2 |
[0.0; 0.2) |
e |
0.3 |
[0.2; 0.5) |
i |
0.1 |
[0.5; 0.6) |
o |
0.2 |
[0.6; 0.8) |
u |
0.1 |
[0.8; 0.9) |
! |
0.1 |
[0.9;1.0) |
И кодеру и декодеру известно, что в самом начале интервал равен [0,1). После просмотра первого символа "e", кодер сужает интервал до [0.2; 0.5) , который модель выделяет этому символу. Второй символ "a" сузит новый интервал до первой его пятой
- 16-
части, поскольку для "a" выделен фиксированный интервал [0.0; 0.2) . В результате,
рабочий интервал примет вид [0.2; 0.26), т.к. предыдущий интервал имел ширину в 0.3
единицы и одна пятая от него есть 0.06. Следующему символу "i" соответствует фиксированный интервал [0.5; 0.6) , что применительно к рабочему интервалу
[0.2; 0.26) сужает его до интервала [0.23; 0.236) , продолжая аналогично для остальных символов, получим следующие интервалы (см. табл. 2).
Таблица 1.2. Кодирование сообщения {eaii!}
|
В начале |
|
|
|
[0.0,1.0) |
|
|
После просмотра |
|
e |
|
[0.2; 0.5) |
|
|
− −""− − |
|
a |
|
[0.2; 0.26) |
|
|
− −""− − |
|
i |
|
[0.23; 0.236) |
|
|
− −""− − |
|
i |
|
[0.233; 0.2336) |
|
|
− −""− − |
|
! |
|
[0.23354; 0.2336) |
|
Декодер знает, что конечный |
интервал |
[ |
0.23354; 0.2336), |
следовательно, первый |
||
закодированный символ есть "e", т.к. итоговый интервал целиком лежит в интервале, выделенном моделью для этого символа согласно табл. 1. Аналогично восстанавливаются остальные символы сообщения.
Декодеру не обязательно знать обе границы итогового интервала, полученного от кодера, достаточно знать какое-либо значение, лежащее внутри этого интервала.
Чтобы завершить процесс, декодеру нужно вовремя распознать конец сообщения. Кроме того, одно и тоже число 0.0 может представить и как "a", и как "aa" , "aaa" и т.д.
Для устранения неясности необходимо обозначить завершение каждого сообщения специальным символом EOF , известным и кодеру, и декодеру.
При фиксированной модели, заданной табл.1, энтропия (4) равна
H = -0.1×log2 0.1- 0.1×log2 0.1- 0.1×log2 0.1- -0.2×log2 0.2 - 0.3×log2 0.3 » 1.98 (бит)
Очевидно, что разные модели дают разную энтропию. Лучшая модель в этом смысле есть модель, построенная на анализе отдельных символов текста {eaii!} , т.е. следующее множество частот:
{"e"(0.2), "a"(0.2), "i"(0.4), "!"(0.2)} ,
при этом энтропия будет равна:
- 17-
H = -0.2 ×log2 0.2 - 0.2×log2 0.2 - 0.4×log2 0.4 - 0.2×log2 0.2 » 1.92 (бит) .
Приведенный выше алгоритм может сжимать только достаточно короткие сообщения из-за ограниченности разрядности всех переменных. Чтобы избежать этих ограничений, реальный алгоритм работает с целыми числами и оперирует дробями, числитель и знаменатель которых являются целыми числами. При этом с потерей точности можно бороться, отслеживая сближение нижней li и верхней hi границ
рабочего интервала и умножая числитель и знаменатель представляющей их дроби на какое-то число (удобно на 2). С переполнением сверху можно бороться, записывая старшие биты в li и hi в файл тогда, когда они перестают меняться (т.е. реально уже не участвуют в дальнейшем уточнении интервала). Подробное описание и реализация алгоритма арифметического кодирования приведены в [15].
Минимизация потерь по точности достигается благодаря тому, что длина целочисленного интервала всегда не менее половины всего интервала. Когда li и hi
одновременно находятся в верхней или нижней половине интервала, их одинаковые старшие биты записываются в выходной поток, а интервал увеличивается вдвое. Если li
и hi приближаются к середине интервала, оставаясь по разные стороны от его середины,
то интервал также удваивается, при этом биты записываются «условно», т.е. реально эти биты выводятся в выходной файл позднее, когда становятся известны их значения. Процедура изменения значений li и hi называется нормализацией, а вывод соответствующих битов – переносом.
Часто в качестве статистических моделей используются адаптивные модели, изменяющие частоты символов в процессе обработки сообщения. В начале все символы считаются равновероятными, что отражается отсутствие начальных данных. Далее, по мере просмотра каждого входного символа, частоты изменяются, приближаясь к наблюдаемым вероятностям. И кодер, и декодер используют одинаковые начальные значения (например, одинаковые частоты появления символов) и один и тот же алгоритм обновления, что позволяет их моделям синхронизироваться. Кодер получает очередной символ, кодирует его и изменяет модель. Декодер определяет очередной символ на основании своей текущей модели, а затем обновляет её. На практике адаптивные модели превосходят фиксированные по эффективности сжатия.

-18-
1.4.Ортогональные преобразования
1.4.1.Корреляция как мера статистической зависимости данных
Пусть X = ( X0 ,K, X – случайный вектор, состоящий из отсчётов дискретного сигнала во временной области. Для реальных физических процессов соседние отсчёты вектора обычно имеют близкие значения, т.е. между компонентами вектора имеется статистическая зависимость.
Зависимость между случайными величинами X и Y можно характеризовать
ковариацией: cov |
( |
X ,Y |
) |
= M |
ë( |
X - m |
X )( |
Y )û |
m |
X |
Y |
– математические |
||
|
|
é |
|
|
Y - m |
ù , где |
|
,m |
||||||
ожидания случайных величин |
|
X и Y |
соответственно. Если cov( X ,Y ) ¹ 0 , то говорят, |
|||||||||||
что случайные величины коррелированны. Из коррелированности случайных величин следует их зависимость. Обратное, в общем случае, не верно. В качестве меры
зависимости случайных величин |
удобно |
использовать |
коэффициент |
корреляции |
|||||||
ρ ( X ,Y ) = cov( X ,Y ) |
|
, где |
DX , DY |
– дисперсии |
случайных |
величин X ,Y . |
|||||
DX DY |
|||||||||||
Коэффициент корреляции может принимать значения из диапазона |
ρ Î[-1,1], чем |
||||||||||
ближе к единице абсолютная величина коэффициента корреляции |
|
|
ρ |
|
, |
тем сильнее |
|||||
|
|
||||||||||
зависимость между случайными величинами, а при ρ = 1 реализация одной случайной величины позволяет указать точное значение другой.
В рамках корреляционной теории для описания математической модели вектора данных X = ( X0 ,K, X необходимо задать вектор из математических ожиданий компонент mX = (mX0 ,K,mX N −1 )T и ковариационную матрицу KX = (cov(Xk , X j ))kN,−j1=0 .
Считая X и mX векторами-столбцами, ковариационную матрицу можно записать как
KX = M éë(X - mX )(X - mX )T ùû .
Для реальных дискретных сигналов в большинстве случаев соседние отсчёты имеют близкие значения, т.е. корреляция между близко расположенными на временной оси
отсчетами положительна, ρ (Xk , Xk + j ) > 0 , причем коэффициент корреляции |
тем |
больше, чем меньше j . Вследствие наличия межкомпонентных связей в векторе |
X |
независимое покомпонентное статистическое кодирование компонент (отсчётов дискретного сигнала), следующее за их квантованием, порождает избыточные,
- 19-
неэффективные коды. Учёт статистических зависимостей при построении эффективных кодов технически сложен из-за больших размерностей моделей, описывающих совместные распределения вероятностей компонент вектора X.
Общий подход, который используется для повышения эффективности кодирования дискретных сигналов, состоит в предварительной обработке исходных данных при помощи обратимого преобразования F , переводящего вектор X в некоторый вектор
Y = F {X} , компоненты которого менее зависимы (в рамках корреляционной теории – менее коррелированны), – декоррелирующего преобразования. Тогда независимое покомпонентное кодирование вектора Y, а не вектора X, становится более обоснованным.
Оптимальным по декоррелированию исходных данных является преобразование Карунена-Лоэва Y = WX, матрица которого составлена из собственных векторов-строк ковариационной матрицы KX вектора X. В результате применения этого ортогонального ( WT = W−1 ) преобразования матрица KY принимает диагональный вид.
Однако возможности практического использования преобразования Карунена-Лоэва существенно ограничиваются следующими факторами. Прежде всего, преобразование Карунена-Лоэва является неуниверсальным: матрица преобразования W жестко определяется конкретной ковариационной матрицей KX . Применяя для обрабатываемого сигнала модель случайного процесса, обычно нельзя говорить о его стационарности, т.е. корреляционные зависимости между отсчётами дискретного сигнала меняются, и различные выборки из дискретного сигнала (векторы данных X) могут иметь существенно различающиеся ковариационные матрицы, для которых
априори |
неизвестны |
точные |
значения |
элементов |
{kk ,m |
= cov( Xk |
, Xm )}N −1 . |
|
|
|
|
|
|
|
k ,m=0 |
Использование же некоторой «средней» ковариационной матрицы KX для построения преобразования Карунена-Лоэва не позволяет говорить об оптимальности последнего для каждого отдельного вектора X – очередной выборки из дискретного сигнала. Другая проблема, связанная с использованием преобразования Карунена-Лоэва, заключается в отсутствии быстрых алгоритмов его вычисления. Поэтому на практике используются другие ортогональные преобразования.

-20-
1.4.2.Применение ортогональных преобразований
На Рис. 1 представлена общая схема кодирования и декодирования дискретного сигнала X.
а) |
|
|
|
|
|
|
б) |
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дискретный сигнал- |
|
|
|
|
Входные сжатые |
|
|
|
|
|
|||||||
|
|
|
|
вектор X |
|
|
|
|
|
|
|
|
|
|
данные |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Статистическое декодирование |
|
|
|
|
|
|||
|
|
Декоррелирующее ортогональное |
|
|
|
|
|
||||||||||||||
|
|
|
|
преобразование: Y = WX |
|
|
|
|
|
|
|
|
компонент проквантованного |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
% |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
вектора Y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Квантование компонент |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
(Y) |
|
|
|
|
|
«Деквантование» компонент |
|
|
|
|
|
||||||
% |
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
преобразованного вектора: Y = Q |
|
|
% |
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
вектора Y: Y → Y ≈ Y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Статистическое кодирование |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
Обратное ортогональное |
|
|
|
|
|
||||
|
|
|
компонент проквантованного |
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
преобразование: X = W−1Y |
|
|
|
|
|
||||||||
|
% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
вектора Y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Выходные сжатые |
|
|
|
|
|
|
|
|
|
Восстановленный сигнал- |
|
|
|
|
|
||
|
|
|
|
данные (код) |
|
|
|
|
|
|
|
|
|
вектор X ≈ X |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 1 Схема сжатия (а) и восстановления (б) коррелированных данных с использованием ортогонального преобразования
Наличие этапа квантования компонент вектора Y (обобщенного спектра) |
вносит |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
определенную ошибку в восстановленные данные (вектор X): |
|
|||||||||||||
|
ˆ |
|
|
|
= |
|
|
|
ˆ |
|
|
|
, |
(5) |
|
|
|
|
|
|
|
|
|||||||
|
X − X |
|
|
|
|
|
|
Y − Y |
|
|
|
|||
|
|
|
|
|
E |
|
|
|
|
|
|
|
E |
|
|
|
|
|
|
|
|
|
|
|
|||||
которая может быть снижена до пренебрежимо малого уровня за счет квантования спектральных компонент с большим количеством уровней квантования. Важно, что соотношение (5) выполняется всегда только для ортогональных преобразований.
Кодирование спектра Y = {Y0 ,K,YN −1}, а не исходного вектора X = {X0 ,K, X N −1} ,
позволяет во многих случаях получить существенно меньшие битовые затраты
1.4.3. Дискретный марковский процесс первого порядка
Одной из важнейших корреляционных моделей для дискретных сигналов является
модель дискретного марковского процесса первого порядка. Данный процесс является стационарным, т.е. его параметры не зависят от момента наблюдения. Стационарность