


2. Алгоритм видеокомпрессии
Рис. 12. Успешная компенсация быстрого движения
В случае, если один из векторов-соседей не существует или не удовлетворяет критерию участия в построении прогноза, базовый вектор строится по оставшемуся вектору-соседу. Если же такое случается с обоими векторами-соседями, базовый вектор считается нулевым.
2.3. Кодирование векторов движения
Полученные на этапе компенсации движения векторы перемещения блоков необходимо каким-то образом передавать декодеру. Очевидно, записывать вектор в выходной поток в виде набора из двух компонент неэффективно, так как векторы движения принадлежат конечному множеству, а значит, каждому их них можно поставить в соответствие индекс и уже его записывать в выходной поток. Так как распределение частот векторов движения неравномерно (небольших перемещений больше всего), то имеет смысл сжимать поток индексов с помощью статистического кодера [10]. Этот кодер должен быть также адаптивным, то есть изменять в процессе работы свою статистику так, чтобы она была как можно ближе к статистике реального входного сигнала. Адаптивность позволяет кодеру автоматически настраиваться на статистику каждого конкретного кадра.
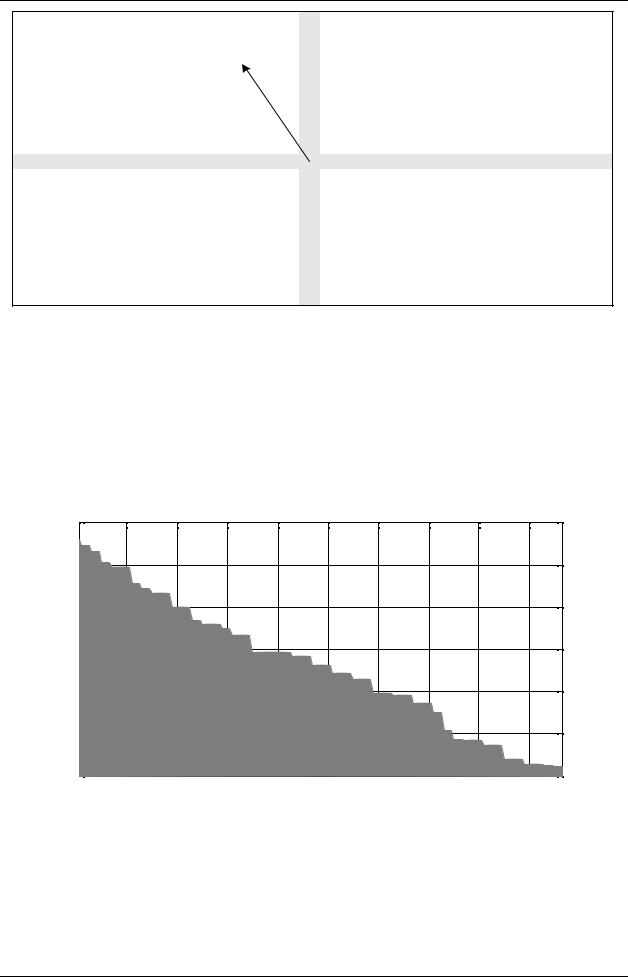
Для двухэтапного алгоритма направленного поиска была разработана таблица перекодировки размером 23×23, по которой вектор можно преобразовать в индекс. В таблице числами отмечены индексы возможных векторов, которые отсчитываются от нулевого индекса, который соответствует вектору перемещения (0; 0). Стрелкой для примера показан вектор (−3; −8), имеющий индекс 153.
Звездочками помечены векторы, которые не могут встречаться в выходном потоке для данного алгоритма компенсации движения.
29
2. Алгоритм видеокомпрессии
Рис. 13. Карта индексов возможных векторов перемещения. Стрелкой показан вектор (−3; −8)
По этой таблице можно выполнять и обратные преобразования из индекса в вектор, но это требует дополнительных вычислений, поэтому для обратного преобразования используется массив всех возможных векторов движения, упорядоченный по возрастанию индекса; таким образом процедура преобразования индекса i в вектор заключается во взятии элемента ri ' из массива.
Вероятность
0.012 
0.01
0.008
0.006
0.004
0.002
0 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
20 |
№ индекса
Рис. 14. Начальная статистика для интервального кодера
Для кодирования индексов векторов перемещения в разработанном видеокодеке был применен адаптивный алгоритм интервального кодирования (range coder) [19], который по принципу работы практически не отличается от арифметического кодера [20], но работает быстрее за счет
30
2. Алгоритм видеокомпрессии
небольшой потери в эффективности сжатия. Перед началом работы кодер инициализируется статистикой, показанной на рис. 14. Это распределение было получено искусственным путем из двумерного нормального распределения с нулевым математическим ожиданием, а стандартное отклонение подбиралось эмпирически. В другой модели этого же кодера, обладающей алфавитом всего из двух символов, сжимаются флаги fi пригодности векторов к построению по ним контекстного прогноза.
2.4. Уточняющее изображение
Очевидно, никакие методы блочной компенсации движения в общем случае не позволяют полностью восстановить следующий кадр по предыдущему. Поэтому кодеки, использующие блочную компенсацию, обычно имеют в своем составе модуль для независимого кодирования блоков, перемещение которых не удалось компенсировать. Кроме собственно метода кодирования, которые в современных кодеках бывают весьма сложными, требуется также правило, по которому определяется, каким образом кодировать блок – независимо или считать его перемещенным, кодируя только вектор движения. Эти правила обычно основываются на RD-критерии [21], учитывающем как вносимое при кодировании каждым методом искажение, так и битовые затраты на блок.
В предложенном видеокодеке всего этого нет, несмотря на то, что используется блочная компенсация движения. В этом заключается его основное отличие от аналогов.
Очередной найденный вектор движения применяется для построения разностного изображения между старым кадром с перемещенными блоками и новым кадром.
Рис. 15. Уточняющее изображение перед сжатием
31

2. Алгоритм видеокомпрессии
Рис. 16. Уточняющее изображение, восстановленное после сжатия с bpp=0,1
Полученное изображение, значения пикселов в котором находятся в диапазоне [−255; 255], приводится к нормальному диапазону [0; 255] путем прибавления числа 255 к каждому пикселу и деления получившегося значения пополам. После этого все изображение, содержащее, как правило, мало информации, сжимается алгоритмом SPIHT c фиксированными битовыми затратами на каждый кадр (битовые затраты задаются в bpp – среднем количестве битов на один пиксел изображения) и полученный битовый код выводится в выходной поток после заголовков и векторов движения.
Для обеспечения корректности дальнейшей работы кодера только что закодированное изображение восстанавливается SPIHT-декодером, затем к нему применяются вектора движения, и декодированный кадр сохраняется в кодере в буфере предыдущего кадра. Этот кадр будет использован на следующей итерации кодера в качестве опорного при компенсации движения. Оригинальный кадр сохранять в буфер предыдущего кадра нельзя, так как он неизвестен декодеру видеопотока, который должен работать синхронно с кодером, иначе будут быстро накапливаться ошибки при декодировании потока, хорошо заметные визуально.
Метод SPIHT (set partitioning in hierarchical trees, разложение множества по иерархическим деревьям) [17] был разработан для оптимальной прогрессирующей передачи изображений, а также для их сжатия. Самая важная особенность этого алгоритма заключается в том, что на любом этапе декодирования качество отображаемой в этот момент картинки является наилучшим для введенного объема информации о данном образе.
Другая отличительная черта алгоритма SPIHT состоит в использовании им вложенного кодирования. Это свойство можно определить следующим образом:
32

2. Алгоритм видеокомпрессии
если кодер производит два файла, большой объема M бит и маленький объема m бит, то меньший файл совпадает с первыми m битами большего файла.
Начнем с общего описания метода SPIHT. Обозначим пикселы исходного изображения p через pi, j , а коэффициенты его двумерного вейвлет-разложения
c – через ci, j .
Основная цель прогрессирующего метода состоит в скорейшей передаче самой важной части информации об изображении. Эта информация дает самое большое сокращение расхождения исходного и реконструированного образов. Для количественного измерения этого расхождения метод SPIHT использует среднеквадратическую ошибку MSE (mean squared error):
MSE |
= |
1 |
∑(ci, j |
− ˆ |
2 |
|
|
||||
|
MN |
ci, j ) , |
|||
|
|
i, j |
|
|
|
|
|
|
|
|
|
где M и N – размеры изображения. В силу ортогональности ДВП выполняется неравенство Парсеваля, позволяющее утверждать, что убывание значения MSE в области преобразования соответствует убыванию его значения в пространственной области. Таким образом, имеется возможность точно контролировать качество сжатия, не выполняя обратное ДВП, что существенно экономит вычислительные ресурсы. Из этого следует, что алгоритм SPIHT может иметь любой из двух критериев остановки работы: либо по достижении заданного качества сжатия, либо по достижении заданного размера сжатого файла.
Очевидно, самыми значимыми для восстановления изображения являются наибольшие по модулю коэффициенты, поэтому алгоритм должен передавать их в первую очередь. Процесс кодирования набора коэффициентов, предварительно отсортированных по невозрастанию их модуля (информация о порядке перестановки коэффициентов из их исходного расположения передается декодеру независимо), показан в таблице 1. В столбцах таблицы содержатся коэффициенты, каждый из которых содержит знаковый бит и биты модуля, расположенные в порядке убывания значимости сверху вниз (MSB – старший бит, LSB – младший бит). Соответственно, в строках таблицы содержатся битовые слои коэффициентов.
Таблица 1. Послойное кодирование упорядоченных коэффициентов ДВП
№ коэфф-та |
1 |
2 |
3 |
4 |
5 |
6 |
|
N |
|
|
|
|
|
|
|
|
|
33

|
|
|
|
|
|
2. Алгоритм видеокомпрессии |
|||
знак |
|
s |
s |
s |
s |
s |
s |
… |
s |
MSB |
14 |
1 |
1 |
0 |
0 |
0 |
0 |
… |
0 |
|
13 |
a |
b |
1 |
1 |
1 |
0 |
… |
0 |
|
12 |
c |
d |
e |
f |
g |
1 |
… |
0 |
|
11 |
h |
i |
j |
k |
l |
m |
… |
… |
|
… |
… |
… |
… |
… |
… |
… |
… |
… |
LSB |
0 |
t |
u |
v |
w |
z |
y |
… |
z |
Так как известно, что коэффициенты отсортированы, то можно легко описать |
|||||||||
структуру каждого битового слоя: сначала идут несколько бит данных (в таблице |
|||||||||
показаны буквами латинского алфавита), затем серия единиц (показаны в серых |
|||||||||
ячейках), а все остальные биты до конца строки нулевые. |
|
|
|
||||||
Такая структура позволяет организовать эффективное кодирование |
|||||||||
коэффициентов по битовым слоям, перемещаясь от старшего значащего бита к |
|||||||||
младшему. При этом в каждом слое необходимо закодировать только те биты, |
|||||||||
которые обозначены в таблице латинскими буквами (например, для 12-го слоя это |
|||||||||
биты cdefg), а следующую за ними серию единиц и серию нулей можно |
|||||||||
проигнорировать. Выводимые по слоям биты практически не коррелированы и |
|||||||||
распределены равномерно, что позволяет записывать их в файл напрямую, не |
|||||||||
используя дополнительное сжатие статистическим кодером. |
|
|
|
||||||
Слой со знаками коэффициентов кодируется отдельно. |
|
|
|
||||||
Декодер, зная количество закодированных бит на каждом слое, и тот факт, что |
|||||||||
коэффициенты отсортированы, может легко восстановить всю таблицу. Для этого |
|||||||||
при рассмотрении очередного слоя нужно сначала записать в соответствующую |
|||||||||
ему строку таблицы все закодированные биты данных с этого слоя, а затем вписать |
|||||||||
единицы в предыдущую строку для тех коэффициентов, биты которых ранее не |
|||||||||
кодировались (например, при декодировании 12-го слоя единицы будут вписаны на |
|||||||||
13-й слой над битами efg). При этом декодер может в любой момент остановить |
|||||||||
работу, получив на выходе некоторое приближение к исходному набору |
|||||||||
коэффициентов, над которым после перестановки коэффициентов в исходный |
|||||||||
порядок можно провести обратное ДВП и получить декодированное изображение с |
|||||||||
той или иной степенью детализации. |
|
|
|
|
|
|
|||
34

2. Алгоритм видеокомпрессии
Однако в этом случае есть тонкость, которую обязательно следует учитывать при практической реализации алгоритма. Предположим, что декодер был остановлен после записи в таблицу бита d на 12-м слое. В этот момент ему известна следующая информация:
№ коэффициента |
Значение коэффициента |
|
|
1 |
1ac************ |
2 |
1bd************ |
3 |
01************* |
все остальные |
0************** |
Звездочками обозначены неизвестные декодеру значения битов. Чем их заполнить? Как было отмечено ранее, выводимые в файл биты практически не коррелированы, поэтому для коэффициентов №№ 1-3 можно считать неизвестные биты независимыми равномерно распределенными случайными величинами дискретного типа. Нетрудно показать, что случайная величина – число, составленное из таких битов, имеет равномерное распределение, а значит и математическое ожидание, равное половине максимального значения этого числа, то есть старший бит математического ожидания равен 1, а остальные биты – нулю. Таким образом, после остановки декодера следует для каждого коэффициента из тех, в которые уже были записаны биты (в нашем примере это №№ 1-3), вписать единицу в следующий слой, а остальные биты этого коэффициента заполнить нулями. Все коэффициенты, еще не участвовавшие в декодировании, приравниваются к нулю.
Окончательно, декодированные коэффициенты будут иметь следующий вид:
№ коэффициента |
Значение коэффициента |
|
|
1 |
1ac100000000000 |
2 |
1bd100000000000 |
3 |
011000000000000 |
все остальные |
000000000000000 |
Описанный выше алгоритм очень прост, так как в нем предполагалось, что коэффициенты были отсортированы (упорядочены) перед началом работы. В принципе, изображение может состоять из нескольких миллионов пикселов и сортировка может оказаться весьма медленной процедурой. Вместо сортировки
35

2. Алгоритм видеокомпрессии
коэффициентов алгоритм SPIHT использует тот факт, что сортировка делается с помощью сравнения в каждый момент времени двух элементов, а каждый результат сравнения – это просто ответ: «да» или «нет». Поэтому, если кодер и декодер используют один и тот же алгоритм сортировки, то кодер может просто послать декодеру последовательность результатов сравнения, по которым декодер сможет восстановить работу кодера и выполнить все обратные преобразования.
Алгоритм SPIHT основан на том, что нет необходимости сортировать все коэффициенты. Главной задачей этапа сортировки на каждой итерации является
выявление коэффициентов, удовлетворяющих неравенству |
2n ≤ |
|
c |
|
< 2n+1 , где n – |
|
|
||||
|
|
|
i, j |
|
|
номер текущего битового слоя. Эта задача делится на две части. Для заданного n ,
если коэффициент c |
удовлетворяет неравенству |
|
c |
|
≥ 2n , то он называется |
|
|
||||
i, j |
|
|
i, j |
|
|
значимым (significant), в противном случае он называется незначимым (insignificant). На первом шаге (битовый слой соответствует MSB) относительно немного коэффициентов будут значимыми, но их число будет возрастать от
итерации к итерации, так как число |
n убывает. Сортировка должна определить, |
|||||||||
какие значимые коэффициенты удовлетворяют второму неравенству |
|
c |
|
< 2n+1 |
, и |
|||||
|
|
|||||||||
|
|
|
|
|
|
|
i, j |
|
|
|
передать их координаты декодеру. |
|
|
|
|
|
|
|
|
|
|
Кодер разделяет все коэффициенты на некоторое количество множеств Tk |
и |
|||||||||
выполняет проверку на значимость |
|
|
|
|
|
|
|
|
|
|
max |
|
c |
|
≥ 2n ? |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
(i, j) T |
|
|
i, j |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
|
|
|
для каждого множества Tk . Результатом может быть «нет» (все коэффициенты из
Tk являются значимыми) или «да» (некоторые коэффициенты из Tk являются значимыми, то есть, само Tk значимо). Этот результат передается декодеру. Если результат проверки положителен, то Tk делится и кодером, и декодером с помощью общего правила на подмножества, к которым применяется та же проверка на значимость. Это деление продолжается до тех пор, пока все значимые множества не будут иметь размер 1 (то есть, каждое будет содержать ровно один коэффициент, который является значимым). С помощью этого метода производится выделение значимых коэффициентов на этапе сортировки при каждой итерации.
36
2. Алгоритм видеокомпрессии
Проверку на значимость множества T можно переписать в следующем виде:
1, max |
|
c |
|
≥ 2n |
|
|
|
||||
Sn (T )= (i, j ) Tk |
|
|
i, j |
|
|
|
|
|
|
||
|
|
|
|
||
0, иначе |
|
|
|
||
Результатом этого теста служит бит Sn (T ), который следует передать декодеру.
Поскольку результат каждого теста записывается в сжатый файл, то хорошо бы минимизировать число необходимых тестов. Для достижения этой цели множества должны создаваться и разделяться так, чтобы ожидаемые значимые множества были большими, а незначимые множества содержали бы всего один элемент.
Множества Tk создаются и разделяются с помощью специальной структуры данных, которая называется пространственно ориентированным деревом. Эта структура определяется с использованием пространственных соотношений между вейвлет-коэффициентами и различными уровнями пирамиды саббэндов. Коэффициенты саббэндов каждого уровня ДВП, соответствующие одной пространственной области исходного изображения, коррелированы друг с другом.
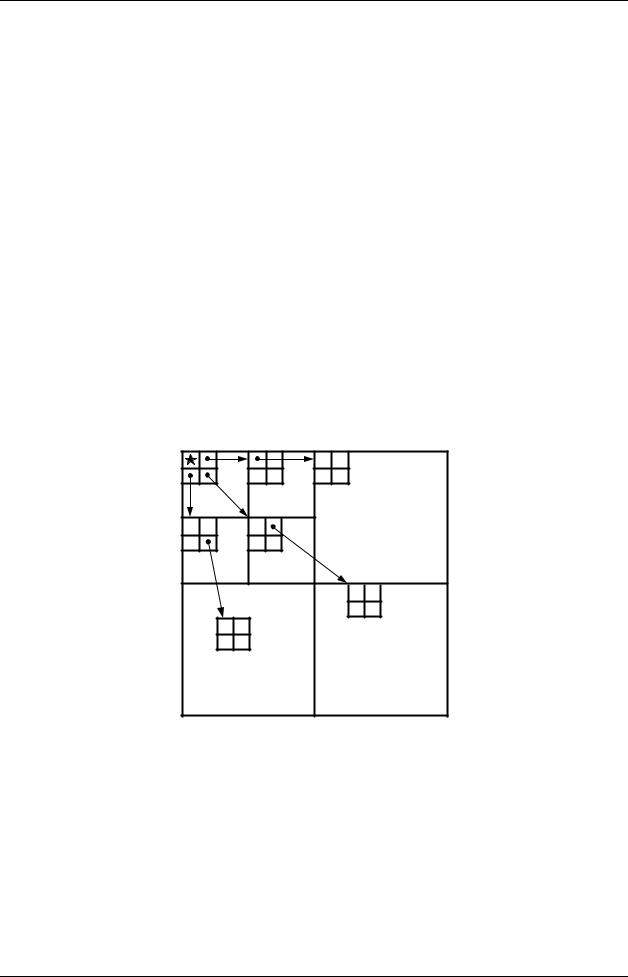
Рис. 17. Связи между «родителями» и «потомками» в области ДВП
Пример построения пространственно ориентированных деревьев для случая алгоритма SPIHT показан на рис. 17. На этом рисунке показаны два уровня: уровень 1 (низкочастотный) и уровень 2 (высокочастотный). Каждый уровень разделен на 4 саббэнда.
Корнями дерева считаются коэффициенты LL-саббэнда, который обрабатывается следующим образом. LL-саббэнд разбит на блоки из 2×2 коэффициентов. В каждом блоке 3 из 4 его коэффициентов за исключением
37

2. Алгоритм видеокомпрессии
верхнего левого становятся корнями трех деревьев, причем в этом случае первые потомки корней находятся на том же уровне, что и они сами.
В прочих саббэндах коэффициент с координатами (i, j) является родителем четырех коэффициентов с координатами (2i, 2 j), (2i +1, 2 j), (2i, 2 j +1) и (2i +1, 2 j +1), принадлежащих соответствующему саббэнду со следующего уровня.
Так строится пространственно ориентированное дерево. Стрелками показан пример связи между различными уровнями деревьев.
Таким образом, корни деревьев расположены в LL-саббэнде, их непосредственные потомки – в оставшихся саббэндах первого уровня, а потомки этих потомков находятся уже на втором уровне.
Алгоритм сортировки разделением множеств использует следующие четыре множества координат:
– O(i, j) – множество непосредственных (прямых) потомков коэффициента,
может состоять из 0, 3 или 4 коэффициентов;
– D(i, j) – множество всех потомков коэффициента, составляющих дерево или поддерево;
–H (i, j) – множество коэффициентов LL-саббэнда;
–L(i, j)= D(i, j)\ O(i, j).
Правила разделения множеств просты и формулируются следующим образом:
– начальными множествами являются множества {(i, j)} и D(i, j) |
для всех |
||
|
(i, j) H ; |
|
|
– |
если множество |
D(i, j) является значимым, то оно разбивается на |
L(i, j) и |
|
четыре одноэлементных множества с четырьмя прямыми потомками |
||
|
(k,l) O(i, j); |
|
|
– |
если множество |
D(i, j) является значимым, то оно разбивается на четыре |
|
множества D(k,l), где (k,l) O(i, j)
Теперь можно полностью описать алгоритм кодирования. SPIHT использует три списка, которые называются: список значимых пикселов (LSP, list of significant pixels), список незначимых пикселов (LIP, list of insignificant pixels) и список незначимых множеств (LIS, list of insignificant sets). В эти списки заносятся координаты (i, j) так, что в списках LIP и LSP они представляют индивидуальные
38

2. Алгоритм видеокомпрессии
коэффициенты, а в списке LIS они представляют или множество D(i, j) (запись типа А), или множество L(i, j) (запись типа В).
Список LIP содержит координаты коэффициентов, которые были незначимыми на предыдущем этапе сортировки. Они проверяются на текущем этапе, и пикселы, ставшие на этом этапе значимыми, перемещаются в список LSP. Аналогично, множества из LIS проверяются в последовательном порядке, и если обнаруживается, что множество стало значимым, то оно удаляется из LIS и разделяется. Новые подмножества, состоящие более чем из одного элемента, помещаются обратно в список LIS, где они позже будут подвергнуты проверке, а одноэлементные подмножества проверяются и добавляются в список LSP или LIP в зависимости от результатов проверки. На этапе уточнения передается очередной битовый слой коэффициентов из списка LSP.
Рис. 18. Участок исходного (а) и восстановленного после кодирования алгоритмом SPIHT (б) стандартного изображения Lena, bpp=0,3
1. Инициализация: Присвоить переменной n значение n = log2 (max{ci, j }) и
передать n . Сделать список LSP пустым. Поместить в список LIP координаты всех коэффициентов (i, j) H . Поместить в список LIS координаты тех корней
(i, j) H , у которых имеются прямые потомки. 2. Сортировка:
2.1. Для каждой записи (i, j) из списка LIP выполнить: передать Sn (i, j);
если Sn (i, j)=1, то переместить (i, j) в список LSP и передать знак ci, j . 2.2. Для каждой записи (i, j) из списка LIS выполнить:
39

2. Алгоритм видеокомпрессии
2.2.1. Если запись типа А, то передать Sn (D(i, j));
если Sn (D(i, j))=1, то для каждого (k,l) O(i, j) выполнить: выдать на выход Sn (k,l);
если Sn (k,l)=1, то добавить (k,l) в список LSP, передать знак ck,l ;
если Sn (k,l)= 0 , то добавить (k,l) в список LIP;
если L(i, j)≠ , то переместить (i, j) в конец LIS в виде записи типа В и
перейти к шагу 2.2.2; иначе удалить (i, j) из списка LIS. 2.2.2. Если запись типа В, то
передать Sn (L(i, j)); если Sn (L(i, j))=1, то
добавить каждую координату (k,l) O(i, j) в LIS в виде записи типа A;
удалить (i, j) из списка LIS.
3. Уточнение: для каждой записи (i, j) из LSP, за исключением добавленных в список при последней сортировке (с тем же самым n ), выдать в выходной поток n –й старший бит числа ci, j .
4. Уменьшить n на единицу и перейти к шагу 2, если это необходимо.
Для алгоритма видеокомпрессии, предложенного в настоящей работе, была реализована версия SPIHT с возможностью контроля как качества сжатия (по MSE), так и битовых затрат (с точностью до байта). Однако при кодировании разностного изображения используется только контроль над битовыми затратами, который задается пользователем в параметрах кодека перед началом работы, то есть фактически при кодировании всей видеопоследовательности используется жестко заданное ограничение битовых затрат. Это во многих случаях полезно, чтобы не допускать «скачков» сетевого трафика при работе на низкоскоростных каналах связи. Но очевидно, что во многих случаях, когда необходимость такого ограничения отсутствует, кодек работает неэффективно.
Более предпочтительной выглядит схема с одновременным контролем и качества, и битовых затрат, в которой битовые затраты задавались бы не на каждый
40