

Эволюция многоядерной процессорной архитектуры Intel Core: Conroe, Kentsfield, далее по расписанию
|
|
Начало формы Конец формы |
 Автор:Владимир
Романченко
Дата:
27.06.2006
Автор:Владимир
Романченко
Дата:
27.06.2006
Одна из самых интересных IT-интриг нынешнего сезона – несомненно, в близящемся анонсе нового поколения многоядерной процессорной архитектуры Intel Core. Благодаря благожелательной PR-политике Intel в целом и открытому общению с прессой в частности, уже сейчас, до официального анонса моделей розничных процессоров, мы знаем об этих чипах очень и очень много. По крайней мере, более чем достаточно, чтобы сегодня представить вниманию наших читателей обзорный рассказ об архитектурных изменениях и усовершенствованиях, реализованных в новом поколении процессоров с архитектурой Intel Core.
Уже давно ни для кого не секрет, что новые двухъядерные процессоры с рабочими названиями Merom, Conroe и Woodcrest, для рынков мобильных, настольных и серверных компьютеров соответственно, будут иметь в своей основе единые архитектурные построения под сводным названием Intel Core(ранее -Architecture 101), разве что, с дополнениями в соответствии со специфическими требованиями каждого рыночного сегмента. Тем не менее, представляя сегодня новое поколение архитектуры Intel Core, основной упор будет делаться на чипы для настольных ПК – Conroe.
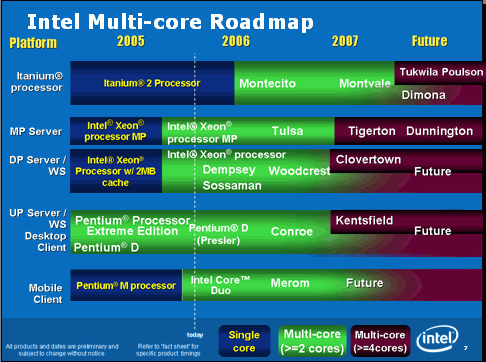
Сразу же уточню, что этот рассказ посвящён исключительно архитектурным особенностям новых процессоров Intel. Поэтому не стоит ожидать в материале каких-либо слухов, утечек или намёков на маркировку чипов Conroe, сроки их анонса и появления в рознице, ожидаемые цены и тому подобное. Максимум, что автор позволил себе в рамках этого рассказа – это предположения о возможном приросте производительности в тех или иных приложениях.
Всю остальную информацию, сопровождаемую сравнительным тестированием новых чипов, наши читатели получат в соответствующее время. Вот сейчас фактически тот самый момент, когда лучше семь раз отмерить и подать только проверенную информацию, чем до поры до времени пускать "жёлтые" слухи. Надеюсь, что наши читатели, заранее "переварив" архитектурные особенности нового поколения процессоров Intel, смогут в последствии не отрешённо разглядывать количество "попугаев", полученных при тестировании, но лучше понимать причины и следствия, закономерно ведущие к тому или иному результату. Приступим.
Основополагающие формулы, определяющие эффективность современной процессорной архитектуры
Как известно, несколько лет назад компания Intel отказалась от "гонки мегагерцев" и взяла курс на разработку эффективных процессорных микроархитектур с экономным энергопотреблением. А этом свете максимальная эффективность работы процессора напрямую зависит не столько от тактовой частоты, сколько от количества инструкций, выполняемых за один такт. Иными словами, тактовая частота процессора – лишь один из множителей в простой формуле:
[Производительность] = [Тактовая частота] x [Количество инструкций, выполняемых за один такт]
Таким образом, на практике совсем не обязательно "гнать частоту", есть множество других эффективных способов значительно поднять производительность. Одно из подмножеств таких способов в частности - столь популярное нынче использование многоядерности, хотя, как показывает практика, просто так взять и распараллелить вычисления на множество ядер - тоже задачка не из простых, так просто "в лоб" не решается.

Другим весьма эффективным способом повышения одного из множителей выше приведённой формулы расчёта производительности можно назвать метод снижения количества инструкций, необходимых для исполнения той или иной задачи, иными словами, оптимизация потока команд. Нагляднейший пример тому – SIMD-команды (single instruction multiple data) MMX, используемые Intel в виде целочисленных 64-битных SIMD инструкций с 1996 года, начиная чипами Pentium с поддержкой MMX, а также представленные чуть позже 128-битные SIMD инструкции с плавающей запятой и одинарной точностью, впервые представленные пакетом SIMD-расширений SSE в чипе Pentium III и дополненные впоследствии наборами SSE2 и SSE3.
Ещё один яркий пример технологии оптимизации потока команд – так называемая технология микрослияния команд (microfusion), в результате чего несколько внутренних микроопераций (micro-ops) процессора могут быть скомбинированы в одну микрооперацию, чем также значительно сокращается общее количество микроопераций для выполнения конкретной задачи.
В то же время нынешняя индустриальная установка на выпуск экономичных процессоров требует других расчётов. Таким образом, появляется понятие оптимальной производительности, отражающее количество энергии, затрачиваемое процессором на выполнение той или иной задачи. Получается, что энергопотребление можно оценить как произведение динамической ёмкости (соотношение электростатического заряда проводника к разнице потенциалов между проводниками, обеспечивающими этот заряд) на эффективность исполнения инструкций за такт, квадрат напряжения питания и тактовую частоту:
[Энергопотребление] = [Динамическая ёмкость] x [Напряжение] x [Напряжение] x [Тактовая частота]
Соотнося это уравнение расчёта энергопотребления с предыдущей формулой, разработчики процессоров могут взвешенно подойти к оценке оптимального баланса между эффективностью количества выполняемых за такт инструкций, динамической ёмкости с одной стороны, подходящего напряжения питания ядра и буферных цепей в связке с тактовой частотой чипа с другой стороны, таким образом можно достичь оптимальной производительности и эффективного энергопотребления.
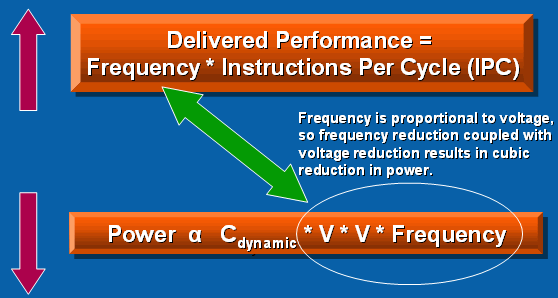

Прошу прощения за затянувшееся вступление и растолковывание прописных истин, но благодаря этому введению будет проще понять цели и методы, применённые при разработке нового поколения микроархитектуры Intel Core с улучшенной производительностью и, что, возможно, ещё более важно, с улучшенной производительностью на ватт.