

Работа с разделяемой памятью
Общая память для всех потоков одного блока.
Содержит переменные, объявленные в ядре с квалификатором __shared__ (для каждого блока будет создан один экземпляр таких переменных), и аргументы ядер.
Обычно используется для взаимодействия потоков одного блока, в этом случае нужна синхронизация __syncthreads().
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
41 |

Работа с разделяемой памятью
Латентность 4 такта.
Малый размер (от 16 или 48kB).
Типичная схема использования разделяемой памяти для уменьшения времени доступа к глобальной памяти:
–загрузка интенсивно используемых данных из глобальной памяти;
–синхронизация (при необходимости);
–вычисления с использованием загруженных данных;
–синхронизация (при необходимости);
–запись результатов в глобальную память.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
42 |

Пример
Всем потокам блока необходимо работать с определенным участком массива в глобальной памяти. Каждый поток загружает один элемент в соответствующий элемент массива в разделяемой памяти. Считается, что число потоков равно (или меньше чем) NUM_THREADS.
__global__ void kernel(int * a)
{
int globalIdx = blockIdx.x * blockDim.x + threadIdx.x; __shared__ int shared_a[NUM_THREADS]; shared_a[threadIdx.x] = a[globalIdx]; __syncthreads();
// все потоки блока могут использовать shared_a
}
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
43 |

Динамически выделяемая разделяемая память
Данные в разделяемой памяти, размер которых определяется при запуске ядра (аналог динамических массивов).
Может использоваться внутри ядер и __device__-функций.
Синтаксис (только для динамически выделяемой разделяемой памяти):
–Объявление переменной с квалификаторами extern __shared__ перед телом функции.
–Получение адресов начал массивов при помощи сдвигов. Начало каждого массива должно быть выровнено по размеру типа.
–Указание общего размера используемой таким образом разделяемой памяти в качестве третьего аргумента при
запуске ядра (по умолчанию 0).
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
44 |

Пример
Пусть мы хотим выделить массив array0 типа short длины 2n, массив array1 типа float длины n и массив array2 типа int длины 3n.
extern __shared__ float array[]; __global__ void kernel(int n) { short* array0 = (short*)array;
float* array1 = (float*)&array0[2 * n]; int* array2 = (int*)&array1[n];
}
…
int shared_mem_size = sizeof(short) * 2 * n + sizeof(float) * n + sizeof(int) * 3 * n;
kernel<<<num_blocks, num_threads, shared_mem_size>>>(n);
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
45 |

Эффективная работа с разделяемой памятью
Разделяемая память разбита на банки (страницы) таким образом, что последовательные 32-битные слова попадают в последовательные банки.
Каждый банк работает независимо от других, возможен параллельный доступ к различным банкам.
Доступ нескольких потоков к одному банку происходит конфликт банков и доступ сериализуется (выполняется отчасти последовательно для исключения конфликтов), исключение – чтение всеми потоками данных из одного и того же банка.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
46 |

Эффективная работа с разделяемой памятью
Пример:
__shared__ float x[32];
float data = x[BaseIndex + s * tid];
Пусть tid – thread ID, s – шаг доступа к элементам массива.
Потоки с ID tid и tid+n вызовут конфликт банков, если s*n кратно числу банков m.
Для того, чтобы избежать конфликтов банков, необходимо НОД(m, s) = 1.
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
47 |
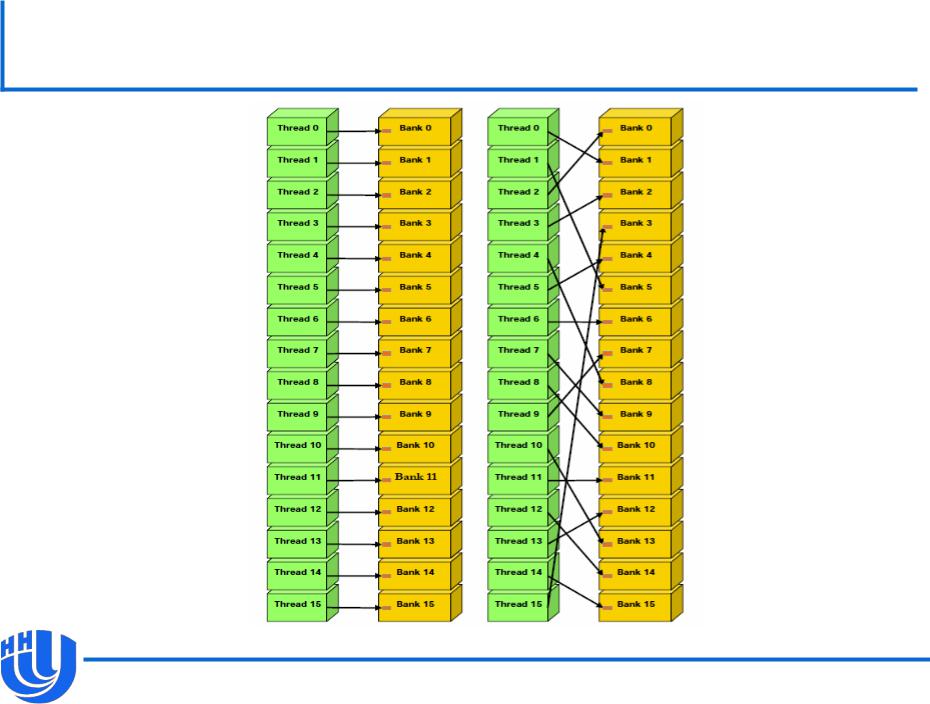
Доступ к разделяемой памяти без конфликтов банков
[NVIDIA CUDA C Programming Guide v. 4.0]
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
48 |

Доступ к разделяемой памяти с конфликтами банков
[NVIDIA CUDA C Programming Guide v. 4.0]
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
49 |

Пример: параллельная редукция
Н. Новгород, 2012 г. |
Исполнение потоков. Иерархия памяти |
50 |