

лекция 3 Документ Microsoft Word
.docЛекция 3
Методология исследований (продолжение лекции 2)
-
Особенности объектов агрономии как предмета математического описания
-
Основные задачи в агрономии
-
Планирование экспериментов на основе статистических моделей
Ключевые слова. Модель дисперсионного анализа, модель регрессионного анализа.
1) Особенности объектов агрономии как предмета математического описания
Уважаемые студенты. Сегодня мы продолжаем знакомиться с основными трудностями при самостоятельном формировании исследовательской программы. Важно знать, что как почва (почвенный покров), так и растение (фитоценоз) имеют стохастическую природу и не могут описываться детерминированными функциями. Следовательно, любые задачи могут корректно решаться методами математической статистики. При это исследование можно проводить на нескольких уровнях : нуль-мерном, одномерном, уровне распределения частот, двумерном и.т.п.
2. Основные задачи в агрономии. Не смотря на то, что большинство агрономических проблем решается на сравнительно-сопоставительном уровне, первым шагом является описание. Нельзя сравнить контроль (стандарт) с изучаемым вариантом без данных, описывающих отдельно варианты сравнения. На этом этапе исследований агроном выступает как естествоиспытатель. Он проясняет количественным языком изучаемые варианты. Здесь допустимо только самосравнение или сравнение с идеальным вариантом. Чаще всего этим идеальным вариантом выступает теоретические распределения. Как уже было сказано, что, чтобы получить кривую распределения, необходим предварительный этап с отбором не менее 25 точек опробования. Затем информация набивается в электронные таблицы и с помощью пакта анализа (гистограмма) получают числовые данные, а затем и через мастера диаграмм график распределения. Следует помнить, что использование пакета анализа обязательно, поскольку в противном случае получают графическое выражение данных. Это типичная ошибка студентов, которую легко заметить по числу столбиков.
Наиболее желательным вариантом для агрономии выступает выявление нормально распределенной изучаемой величины (признака). Это автоматически допускает свертывание информации в арифметические средние с последующим сопровождением предельными ошибками. То есть представление доверительных интервалов арифметической средней.
Для расчета ошибок используют распределение Стьюдента (критерий т) табличные значения которого общедоступны и зависят от объема выборки. При другом типе распределения ошибки считают иначе. Но эти задачи относятся к специальным задачам и их осваивают на специализированных курсах. К примеру, численность вредных насекомых не редко имеет гамма-распределение.
Наиболее часто число изучаемых вариантов в опыте более двух. Для таких случаев при планировании используют модель дисперсионного анализа. Позвольте напомнить, что ее автором является сотрудник Ротамстедсткой полевой станции Фишер. И в настоящее время эта модель является основной не только для агрономии, но и биологии. Вы уже знакомы по курсу бакалавриата с дисперсионным анализом. Но только в одностороннем аспекте. То есть при обработке результатов. Наша задача другая (обратная). Но чтобы использовать модель для планирования, необходимо ее знать для прямых задач. Поэтому я сейчас очень быстро продемонстрирую вам самый простой алгоритм для однофакторного опыта с рандомизированными повторениями. (смотри слайды)
|
|
|
|
|
|
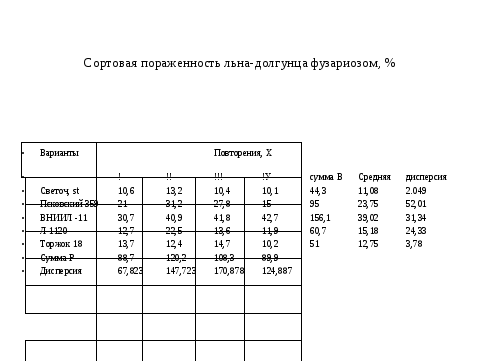
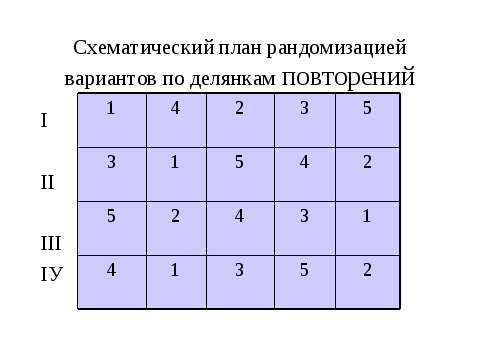

И так видим, что ДА заканчивается проверкой нулевой гипотезы о существовании различий между средними по вариантам по критерию Фишера и если гипотеза отвергается, то имеет смысл поиска конкретных частных
различий по критерию НСР. Для нас очень важно понимать следующее. Первое, для каких случаев дисперсионная модель пригодна (условия применимости). Второе, когда следует считать, что опыт не состоялся. От чего зависит повторность и какую повторность следует иметь, чтобы доказательно найти различия. Все это легко понять из прямой задачи.
|
|
|
|
|
|
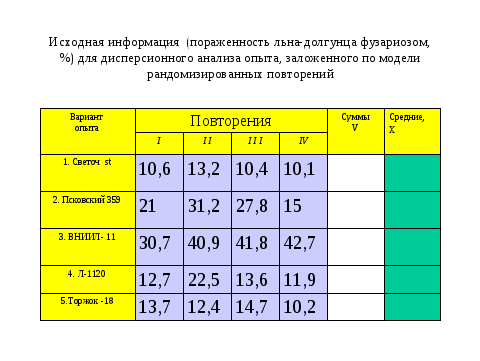
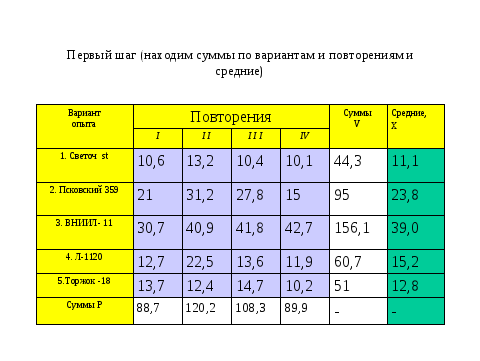
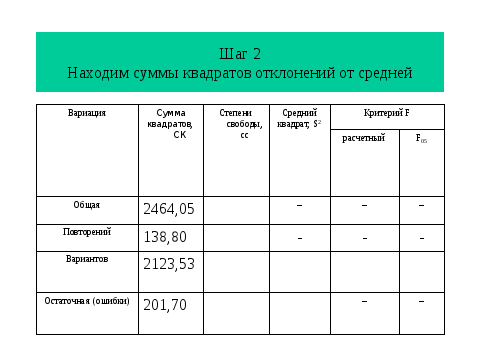
Все данные расчеты легко выполнить в мастере функций на ехеl и тем более через имеющийся в нем пакет программ, но сейчас важно почувствовать алгоритм. И, прежде всего, связь среднего квадрата остаточной вариации с числом повторений.
|
|
|
|
|
|
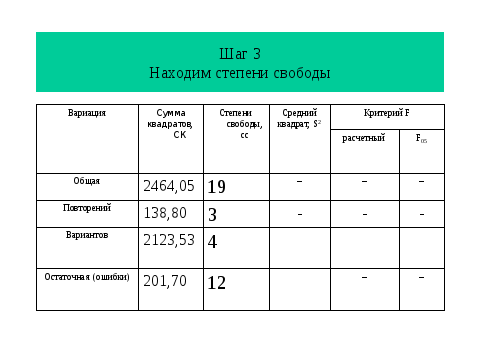
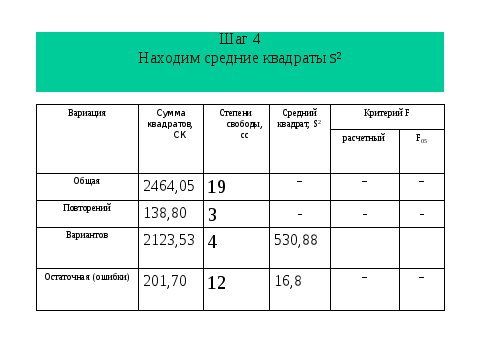
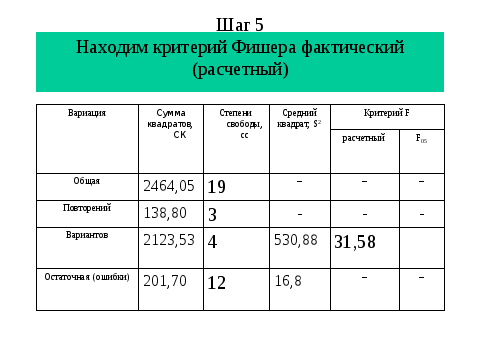
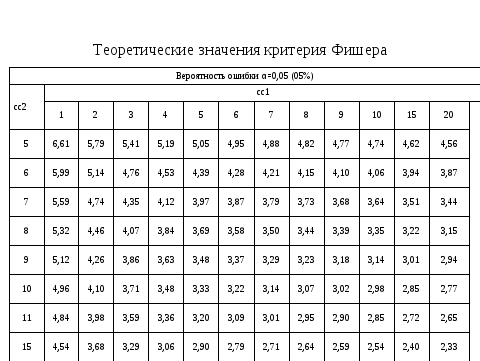
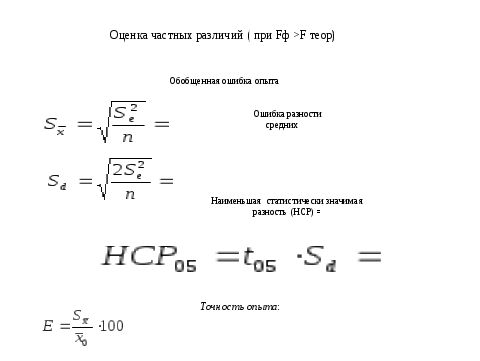
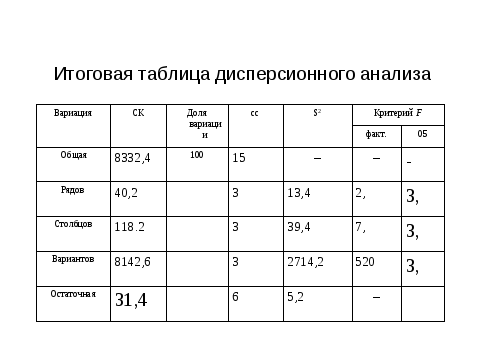
И так, воспользуясь таблицей находим теоретическое значение критерия Фишера, которое оказалось меньше фактического, что отвергает нулевую гипотезу и дает основание рассчитать НСР. К сожалению, в пакете программ ехеl окончание (расчет НСР) отсутствует. Но зная алгоритм НСР легко рассчитать. Из слайда мы видим, что кроме ошибки разности необходимо найти табличное значение критерия Т, но эта информация доступна в Интернет.
|
|
|
|
|
|
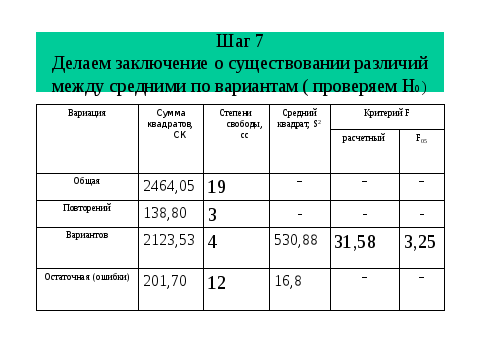



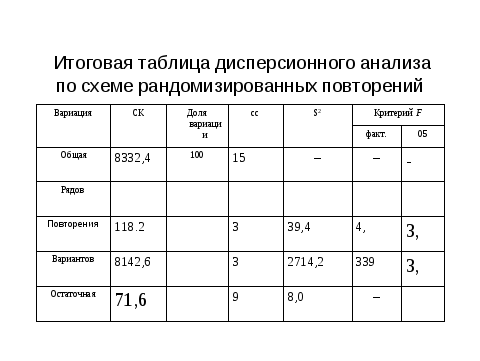
Для нас важно заметить также зависимость НСР от степеней свободы остатка и конечно величины риска, с которым мы будем оценивать результаты и планировать исследование. Современный ехеl нам очень удобен, поскольку дает реальную величину ошибки и риска. То есть мы не только можем отвергнуть или принять гипотезу, ни и видеть с какой степенью надежности. Чтобы понять принцип обратной задачи вновь обратимся к слайду по результатам дисперсионного анализа и зададимся вопросом моги ли мы сократить объемы работ и соответственно материальных затрат без снижения точности (увеличения ошибки)?. Как видно снижение повторности привело бы к снижению степени свободы остатка. Если повторность 4-хкратная , остаток равен 12 , а если 3х кратная, то соответственно 8. Это приведет к увеличении. Среднего квадрата , и следовательно обобщенной ошибки, и через критерий Т- НСР. Заметим, что при значения точности опыта более 10% интерпретировать результаты сложно.

Успешное планирование должно максимально согласовать физическую реальность и математические алгоритмы. Так при постановке экспериментов в условиях, изменяющихся в двух противоположных направлениях более правильно использовать схематический план латинского квадрата или при значительном числе вариантов (более 6-7) латинского прямоугольника. В этом случае можно получить практически аналогичную или меньше величину ошибки, что и при рандомизированных повторениях.
|
|
|
|
|
|
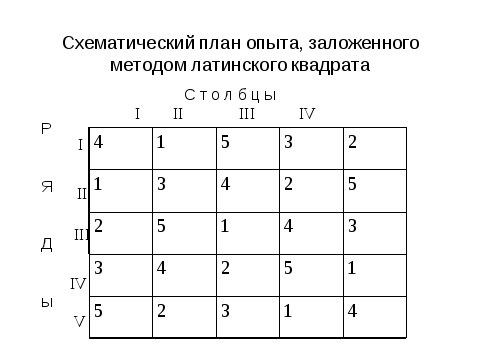

На семинарских занятиях мы покажем вам как обработать данные для этих планов с использованием программы бесповторностного двухфакторного опыта. Заметим, что в настоящее время больший объем качественно новых знаний получают постановкой многофакторных опытов. Новое качество появляется за счет взаимодействия факторов. Но не только взаимодействие ведет к постановке столь сложных экспериментов. Не редко получение информации о долевом участии факторов позволяет изменить стратегию поиска. Я напомню вам, что, как и для однофакторного, так и для многофакторного эксперимента разработаны многочисленные планы и адекватные алгоритмы. Но наша основная задача планирования числа повторений принципиально не меняется. Однако значительно усложняются требования к схемам. Понятно, что природа факторов и градация вариантов играет здесь ключевую роль. Особенно с количественными градациями. Отсюда, необходимо особу тщательно подходить к гипотезе много факторных экспериментов, чтобы попасть в зону оптимума. При дисперсионной модели необходимо включать в схему опыта , с известными способностями к аддитивности факторов.
|
|
|
|
|
|


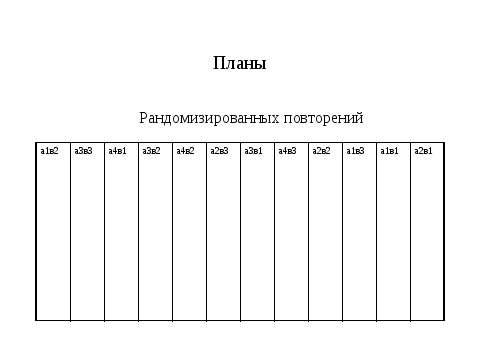
В настоящее время студенты не испытывают больших сложностей в обработке и интерпретации результатов двухфакторных опытов с организованными повторениями. Но большинство из них совершает агрономические ошибки при интерпретации долевого участия. Если в схеме опыта для одного фактора имеется нулевая градация (к примеру, без удобрений), а второго нет ( к примеру все варианты с обработкой почвы), то правильно нулевую при обработке градацию исключить.
|
|
|
|
|
|

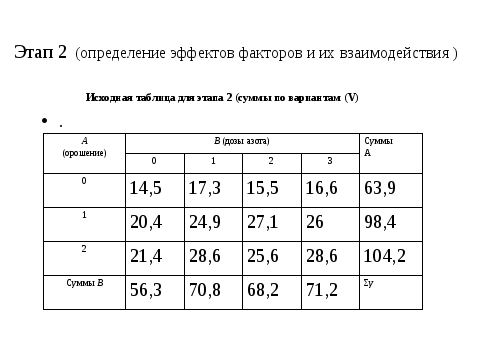
Уважаемые студенты, Вы познакомились с планированием экспериментов на основе дисперсионной модели. То есть с вариантами качественной природы. Но не менее значительный круг задач в агрономии решается на основе регрессионной модели. К сожалению, у нас мало лекционного времени и поэтому я ограничусь краткой информацией.
Прежде всего, важно правильно определить шаг градации и максимально конкретизировать оптимальную зону кривой отклика. Это значит, что число градаций по фактору не может быть менее трех, при чем теоретически следует предполагать изгиб отклика в центральной части диапазона. Понятно, что увеличение числа градаций позволит точнее найти и количественно определить узкую зону оптимума. Если планировать эксперимент на основе регрессионной модели, то следует помнить, что реально точность модели будет определяться и числом пар и повторностей. При этом значительный разброс неоднородности отклика по повторностям нежелателен, так как приводит к смещениям от средних, которые, как правило, используются при оценке регрессии. Если теоретических знаний достаточно для предположения линейности связи, то соответственно используется линейная регрессионная модель. На практических и семинарских занятий мы посмотрим с вами зависимость точности и адекватности модели от вида средних (арифметической, медианы) а, также от вида квантилей. Все это доступно в программном комплексе EXEL. Тем же имеется возможность нелинейного парного моделирования.
Что касается планирования многофакторных опытов, то принципы остаются прежними, как и технологии компьютерного моделирования при планировании эксперимента.
Последней задачей, которую мы изучим на практических занятиях, это планирование исследований на основе геостатистических моделей. Речь идет также не о сравнительном эксперименте, а обосновании программы отбора проб (размещении точек опробования) в пространстве объекта с задачей будущего математического описания в виде уравнения, а при необходимости оформления карт. Понятно, что в этом случае, как и при предварительных исследованиях необходим отбор проб по сеткам. А затем каждая точка получает свое обозначение. К примеру, если используем декартовы системы координат и обозначаем направления (оси) символами z1 z2, то информация по сетке 3х3 оформляется следующим образом. Допустим, измеряли по сетке твердость пахотного слоя почвы (в ньютонах)
|
150 |
180 |
190 |
|
140 |
170 |
180 |
|
120 |
150 |
165 |
В электронной сетке следует информацию расположить следующим образом
|
у |
z1 |
z2, |
|
150 |
1 |
1 |
|
140 |
1 |
2 |
|
120 |
1 |
3 |
|
180 |
2 |
1 |
|
170 |
2 |
2 |
|
150 |
2 |
3 |
|
190 |
3 |
1 |
|
180 |
3 |
2 |
|
165 |
3 |
3 |
Уже сейчас можно говорить о высокой адекватности и приличной «предсказательности» линейной модели вида у= а+ в z1 - в z2
Завершая эту лекцию, я познакомлю вас еще с одной задачей, с которой начинают встречаться магистра на современном уровне исследований. Речь пойдет о многомерной статистике и ее использовании в агрономических исследованиях. Иными словами решение задач выбора по комплексу показателей. Это действительно высший уровень, поскольку здесь не идет о привычном вам сравнении вариантов по одному показателю (редукционизский подход), а одновременно нескольким. Это более сложные задачи и алгоритмы, с которыми вы будете больше работать в аспирантуре. Но среди этих методов (дискриминантный , факторный анализ, компонентный анализ) есть доступный для Вас. Он называется кластерный анализ или автоматическая классификация. Реализован в пакете программ страз, который имеется на кафедрах. Чаще всего этот анализ «любят» наши селекционеры, разделяя сортообразцы в группы (кластеры) по ряду признаков (длина колоса, число зерен в колосе, масса зерен в колосе и.т.п.). понятно, что число признаков может быть значительным, но состав признаков должен иметь содержательный смысл.
Литература
Интернет-ресурсы
Доспехов Б.А. Методика полевого опыта (с основами статистической обработки результатов исследований), М. Агропромиздат , 1985 (WWW pochva. Com./ studentu)
6.4. Программное обеспечение
-
Exel –при демонстрации познавательных приемов на частотно-структурном уровне
-
Straz при демонстрации познавательных приемов многомерной статистики (автоматической классификации)