

MRO / ТМРО_512
.docЛабораторная работа №2
ГЕНЕТИЧЕСКИЙ АЛГОРИТМ.
Цель: усвоить основы применения стохастических методов оптимизации.
Основные теоретические сведения.
Генетический алгоритм является самым известным на данный момент представителем эволюционных алгоритмов. Он заключается в параллельной обработке множества альтернативных решений. При этом поиск концентрируется на наиболее перспективных из них. Это говорит о возможности использования генетических алгоритмов при решении любых задач искусственного интеллекта, оптимизации, принятия решений.
Генетические Алгоритмы - адаптивные методы поиска, которые в последнее время часто используются для решения задач функциональной оптимизации. Они основаны на генетических процессах биологических организмов: биологические популяции развиваются в течении нескольких поколений, подчиняясь законам естественного отбора и по принципу "выживает наиболее приспособленный" (survival of the fittest).
В природе особи в популяции конкурируют друг с другом за различные ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного вида часто конкурируют за привлечение брачного партнера. Те особи, которые наиболее приспособлены к окружающим условиям, будут иметь относительно больше шансов воспроизвести потомков. Слабо приспособленные особи либо совсем не произведут потомства, либо их потомство будет очень немногочисленным. Это означает, что гены от высоко адаптированных или приспособленных особей будут распространятся в увеличивающемся количестве потомков на каждом последующем поколении. Комбинация хороших характеристик от различных родителей иногда может приводить к появлению "суперприспособленного" потомка, чья приспособленность больше, чем приспособленность любого из его родителя. Таким образом, вид развивается, лучше и лучше приспосабливаясь к среде обитания.
ГА используют прямую аналогию с таким механизмом. Они работают с совокупностью "особей" - популяцией, каждая из которых представляет возможное решение данной проблемы. Каждая особь оценивается мерой ее "приспособленности" согласно тому, насколько "хорошо" соответствующее ей решение задачи. Например, мерой приспособленности могло бы быть отношение силы/веса для данного проекта моста. (В природе это эквивалентно оценке того, насколько эффективен организм при конкуренции за ресурсы.) Наиболее приспособленные особи получают возможность "воспроизводит" потомство с помощью "перекрестного скрещивания" с другими особями популяции. Это приводит к появлению новых особей, которые сочетают в себе некоторые характеристики, наследуемые ими от родителей. Наименее приспособленные особи с меньшей вероятностью смогут воспроизвести потомков, так что те свойства, которыми они обладали, будут постепенно исчезать из популяции в процессе эволюции.
Так и воспроизводится вся новая популяция допустимых решений, выбирая лучших представителей предыдущего поколения, скрещивая их и получая множество новых особей. Это новое поколение содержит более высокое соотношение характеристик, которыми обладают хорошие члены предыдущего поколения. Таким образом, из поколения в поколение, хорошие характеристики распространяются по всей популяции. Скрещивание наиболее приспособленных особей приводит к тому, что исследуются наиболее перспективные участки пространства поиска. В конечном итоге, популяция будет сходиться к оптимальному решению задачи.
На рисунке изображена схема работы любого генетического алгоритма:
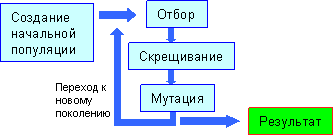
Общую схему генетических алгоритмов проще всего понять, рассматривая задачи безусловной оптимизации
max
{ f (i) | i![]() {0,1}n
}.
{0,1}n
}.
Примерами служат задачи размещения, стандартизации, выполнимости и другие. Стандартный генетический алгоритм начинает свою работу с формирования начальной популяции I0 = {i1, i2, …, is} — конечного набора допустимых решений задачи. Эти решения могут быть выбраны случайным образом или получены с помощью вероятностных жадных алгоритмов. Как мы увидим ниже, выбор начальной популяции не имеет значения для сходимости процесса в асимптотике, однако формирование "хорошей" начальной популяции (например, из множества локальных оптимумов) может заметно сократить время достижения глобального оптимума.
На каждом шаге эволюции с помощью вероятностного оператора селекции (отбора) выбираются два решения, родители i1, i2. Оператор скрещивания по решениям i1, i2 строит новое решение i' , которое затем подвергается небольшим случайным модификациям, которые принято называть мутациями. Затем решение добавляется в популяцию, а решение с наименьшим значением целевой функции удаляется из популяции. Общая схема такого алгоритма может быть записана следующим образом.
-
Выбрать начальную популяцию I0 и положить
f*=
max {
f (i)
| i
![]() I0},
k :
= 0.
I0},
k :
= 0.
2. Пока не выполнен критерий остановки делать следующее.
2.1. Выбрать родителей i1, i2 из популяции Ik. 2.2. Построить i' по i1, i2. 2.3. Модифицировать i' . 2.4. Если f* < f (i' ), то f* : = f (i' ). 2.5. Обновить популяцию и положить k : = k+1.
Остановимся подробнее на основных операторах этого алгоритма: селекции, скрещивании и мутации. Среди операторов селекции наиболее распространенными являются два вероятностных оператора пропорциональной и турнирной селекции. При пропорциональной селекции вероятность на k-м шаге выбрать решение i в качестве одного из родителей задается формулой
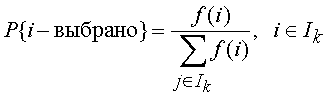
в предположении, что f (i) > 0 для всех i I. При турнирной селекции формируется случайное подмножество из элементов популяции и среди них выбирается один элемент с наибольшим значением целевой функции. Турнирная селекция имеет определенные преимущества перед пропорциональной, так как не теряет своей избирательности, когда в ходе эволюции все элементы популяции становятся примерно равными по значению целевой функции. Операторы селекции строятся таким образом, чтобы с ненулевой вероятностью любой элемент популяции мог бы быть выбран в качестве одного из родителей. Более того, допускается ситуация, когда оба родителя представлены одним и тем же элементом популяции.
После отбора особи промежуточной популяции случайным образом разбиваются на пары. Каждая из них с вероятностью pc скрещивается, т. е. к ней применяется оператор кроссовера, в результате чего получаются два потомка. Они записываются в новое поколение. Если же паре не выпало скрещиваться, в новое поколение записываются сами особи этой пары.
В классическом генетическом алгоритме применяется одноточечный оператор кроссовера (1-point crossover): для родительских хромосом (т. е. строк) случайным образом выбирается точка раздела, и они обмениваются отсеченными частями. Полученные две строки являются потомками:
11010 01100101101 → 10110 01100101101
10110 10011101001 → 11010 10011101001
К полученному в результате скрещивания новому поколению применяется оператор мутации. Каждый бит каждой особи популяции с вероятностью pm инвертируется. Эта вероятность обычно очень мала, менее 1%.
1011001100101101 → 1011001101101101
Двухточечный кроссинговер и равномерный кроссинговер - достойные альтернативы одноточечному оператору. В двухточечном кроссинговере выбираются две точки разрыва, и родительские хромосомы обмениваются сегментом, находящемся между этими точками. В равномерном кроссинговере, каждый бит первого родителя наследуется первым потомком с заданной вероятностью, в противном случае этот бит передается второму потомку. И наоборот.
Таким образом, процесс отбора, скрещивания и мутации приводит к формированию нового поколения. Шаг алгоритма завершается объявлением нового поколения текущим. Далее все действия повторяются.
Вообще говоря, такой процесс эволюции может продолжаться до бесконечности. Критерием останова может служить заданное количество поколений или схождение (convergence) популяции.
Схождением называется такое состояние популяции, когда все строки популяции почти одинаковы и находятся в области некоторого экстремума. В такой ситуации кроссовер практически никак не изменяет популяции. А вышедшие из этой области за счет мутации особи склонны вымирать, так как чаще имеют меньшую приспособленность, особенно если данный экстремум является глобальным максимумом. Таким образом, схождение популяции обычно означает, что найдено лучшее или близкое к нему решение.
Ответом на поставленную задачу может служить набор параметров, кодируемый наилучшей особью последнего поколения.
Генетические алгоритмы в разных формах применяются к решению многих задач, одной из которых является обучение нейронных сетей.
В теории нейронных сетей существуют две актуальных проблемы, одной из которых является выбор оптимальной структуры нейронной сети, а другой - построение эффективного алгоритма обучения нейронной сети.
Оптимизация нейронной сети направлена на уменьшение объёма вычислений при условии сохранения точности решения задачи на требуемом уровне. Параметрами оптимизации в нейронной сети могут быть:
-
размерность и структура входного сигнала нейросети;
-
синапсы нейронов сети. Они упрощаются с помощью удаления из сети или заданием "нужной" или "оптимальной" величины веса синапса;
-
количество нейронов каждого слоя сети: нейрон целиком удаляется из сети, с автоматическим удалением тех синапсов нейронов следующено слоя, по которым проходил его выходной сигнал;
-
количество слоёв сети.
Вторая проблема заключается в разработке качественных алгоритмов обучения нейросети, позволяющих за минимальное время настроить нейросеть на распознавание заданного набора входных образов. Моё сообщение посвящено именно этому вопросу.
Процесс обучения нейронной сети заключается в необходимости настройки сети таким образом, чтобы для некоторого множества входов давать желаемое (или, по крайней мере, близкое, сообразное с ним) множество выходов.
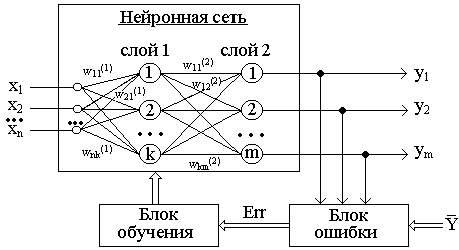
Рисунок 1 - Обучение "с учителем" многослойной нейронной сети
Стратегия "обучение с учителем" (рис. 1) предполагает, что есть обучающее множество {X,Y}.
Обучение осуществляется путем последовательного предъявления векторов обучающего множества, с одновременной подстройкой весов в соответствии с определенной процедурой, пока ошибка настройки по всему множеству не достигнет приемлемого низкого уровня.
![]()
Зависимость реального выходного сигнала Y от входного сигнала X можно записать в виде: Y = F(W,X)+Err, где:
F(W,X) - некоторая функция, вид которой задается алгоритмом обучения нейронной сети;
W - множество параметров, позволяющих настроить функцию на решение определенной задачи распознавания образов (количество слоев сети, количество нейронов в каждом слое сети, матрица синаптических весов сети);
Err - некоторая ошибка, возникающая из-за неполного соответствия реального значения выходного сигнала нейронной сети требуемому значению, а также погрешности в вычислениях.
В последнее время для обучения многослойного персептрона широко используется процедура, получившая название алгоритма с обратным распространением ошибки (error backpropagation).
Однако этому алгоритму свойственны недостатки:
-
возможность преждевременной остановки из-за попадания в область локального минимума;
-
необходимость многократного предъявления всего обучающего множества для получения заданного качества распознавания.
-
отсутствие сколько-нибудь приемлемых оценок времени обучения.
Проблемы, связанные с алгоритмом обратного распространения привели к разработке альтернативных методов расчета весовых коэффициентов нейронных сетей. Впервые в 1989 году Дэвид Монтана и Лоуренс Дэвис использовали генетические алгоритмы в качестве средства подстройки весов скрытых и выходных слоев для фиксированного набора связей.
Задание.
-
Произвести минимизацию функционала, имеющего локальные минимумы, с помощью стохастического алгоритма.
-
С помощью генетических алгоритма выполнить проектирование классификатора для решения задачи распознавания графической информации (текст, изображение).