

9.5. Суперскалярная обработка команд
Конвейеризация обеспечивает параллельную обработку команд. При использовании этой технологии конвейер содержит несколько команд, находящихся на разных ступенях выполнения. Пока первая команда производит операцию АЛУ, вторая декодируется, а третья выбирается из памяти. Команды поступают в конвейер в том порядке, в каком они располагаются в программе. При отсутствии конфликтов на каждом такте в конвейере завершается выполнение очередной команды и появляется новая команда. Таким образом, максимальная пропускная способность конвейера равна одной команде за такт.
С целью повышения производительности процессор может быть оборудован несколькими обрабатывающими устройствами, чтобы на каждом из них обрабатывалось параллельно несколько команд. При такой организации процессора на одном такте может быть запущено на выполнение нескольких команд. Процессоры такого типа называются суперскалярными. Суперскалярную архитектуру имеют многие современные высокопроизводительные процессоры.
Чтобы поддерживать очередь команд заполненной, процессор должен иметь возможность выбирать из кэша несколько команд за раз. Это особенно важно для суперскалярного режима выполнения команд, которому требуется более широкое соединение с кэш-памятью и несколько блоков выполнения. В частности, целочисленным командам и командам с плавающей запятой в суперскалярном процессоре отведены раздельные блоки выполнения.
На рис. 9.9 приведен пример процессора с двумя блоками выполнения: для целочисленных операций и операций с плавающей запятой. Блок выборки команд способен считывать из кэша по две команды за раз и сохранять их в очереди. На каждом такте блок диспетчеризации извлекает из очереди и декодирует одну или две команды. Если одна из команд обрабатывает целочисленные значения, а другая — числа с плавающей запятой, при отсутствии конфликтов обе команды диспетчеризируются на одном такте.
В суперскалярном процессоре конфликты сильнее влияют на производительность, чем в обычном конвейерном процессоре. Компилятор предотвращает многие конфликты, оптимальным образом выбирая и переупорядочивая команды. Например, для процессора, показанного на рис. 9.9, он может обеспечить чередование операций с плавающей запятой и целочисленных операций. Это позволит блоку диспетчеризации поддерживать непрерывную работу целочисленного арифметического устройства и арифметического устройства с плавающей запятой. В общем случае предельное повышение производительности достигается за счет такого переупорядочения команд компилятором, при котором максимально используются возможности всех доступных устройств.

Рис. 9.9. Процессор с двумя блоками выполнения
На рис. 9.10 вы видите временную диаграмму конвейера суперскалярного процессора. Тонкими линиями выделены операции, выполняемые в арифметическом устройстве с плавающей запятой. Для завершения операции, заданной в команде I1, арифметическому устройству с плавающей запятой требуются три такта. Целочисленное устройство заканчивает выполнение команды I2 за два такта. Предполагается, что арифметическое устройство с плавающей запятой организовано как трехступенчатый конвейер. Поэтому на каждом такте оно может принимать новую команду. Команды I3 и I4 поступают в блок диспетчеризации на такте 3 и диспетчеризируются на такте 4. Целочисленный блок в этот момент ожидает новую команду, так как команда I2 уже находится на ступени записи. Команда I1 хотя все еще остается на ступени выполнения, уже перемещена на вторую ступень внутреннего конвейера устройства с плавающей запятой. Поэтому на его первую ступень может поступить команда I3. Если предположить, что в ходе процесса не произойдет никаких конфликтов, выполнение команд завершится так, как показано на рис. 9.10.
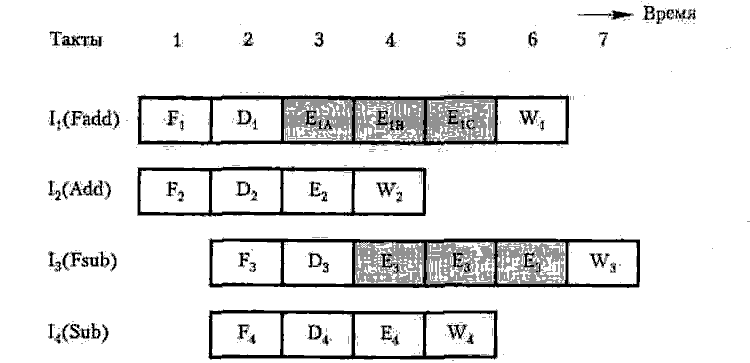
Рис. 9.10. Поток выполнения команд в процессоре с рис. 9.9 при отсутствии конфликтов