

Протокол маршрутизации rip
RIP - внутренний протокол маршрутизации ЮР (Interior Gateway Protocol, RFC-1074, -1371) определяет маршруты внутри автономной системы. Этот протокол маршрутизации предназначен для сравнительно небольших и относительно однородных сетей. В протоколе RIP сообщения инкапсулируются в UDP- дейтаграммы, при этом работает порт 520. В качестве метрики маршрутизации RIP использует число шагов (хопов) до цели. Если между отправителем и приемником расположено три маршрутизатора, считается, что между ними четыре шага. Такой вид метрики не учитывает различий в пропускной способности или загруженности отдельных сегментов сети. Таблица маршрутизации RIP содержит по одной записи на каждую обслуживаемую машину. Запись обычно содержит следующие поля:
-
сеть (IP-адрес сети);
-
расстояние до этой сети;
-
IP-адрес следующего маршрутизатора по пути к месту назначения;
-
таймеры маршрута.
Вектором расстояний будем называть набор пар («Сеть», «Расстояние до этой сети»), извлеченный из маршрутной таблицы, а каждую пару этого набора - элементом вектора расстояний.
Существует две версии протокола REP. RIP-1 - описан в документе RFC- 1058. RIP-2 (RFC-1721-24,1993 г.) - новая версия RIP, которая в дополнение к широковещательному режиму поддерживает групповую рассылку (multicast); позволяет работать с масками подсетей.
Формат сообщения протокола RIP показан на рис. 5.40.
Поле «Команда» (Command) определяет тип сообщения: 1 - запрос (request) на получение частичной или полной маршрутной информации; 2 - ответ (response), содержащий информацию о расстояниях из маршрутной таблицы отправителя; 3 - включение режима трассировки (устарело); 4 - выключение режима трассировки (устарело); 5,6 - зарезервированы для внутренних целей.
Поле «Версия» (Version) для RIP-1 равно 1 (для RIP-2 - 2).
Поле «Набор протоколов сети» (Address Family Identifier) определяет набор протоколов, которые используются в соответствующей сети (для Internet это поле имеет значение 2).
Поле «Расстояние до сети» (Metric) содержит целое число шагов (от 1 до 15) до данной сети. Если расстояние равно 16, то считается, что сеть недостижима.

Поле «Маршрутный домен» (Routing Domain) служит идентификатором RIP- системы, к которой принадлежит данное сообщение; часто это номер автономной системы, который используется, когда к одному физическому каналу подключены маршрутизаторы из нескольких автономных систем, в каждой автономной системе под держивается своя таблица маршрутов. Поскольку RIP- сообщения рассылаются всем маршрутизаторам, подключенным к сети, требуется различать сообщения, относящиеся к «своей» и «чужой» автономным системам.
Поле «Метка маршрута» (Route Tag) выполняет роль метки для внешних маршрутов при работе с протоколами внешней маршрутизации.
Поле «Маска подсети» (Subnet Mask) - маска сети, адрес которой содержится в поле IP-адрес. RIP-1 работает только с классовой моделью адресов.
Поле «IP-адрес следующего маршрутизатора» (Next Нор) содержит адрес следующего маршрутизатора для данного маршрута, если он отличается от адреса маршрутизатора, пославшего данное сообщение. Это поле используют, когда к одному физическому каналу подключены маршрутизаторы из нескольких автономных систем и, следовательно, некоторые маршрутизаторы «чужой» автономной системы могут быть достигнуты напрямую, минуя пограничный маршрутизатор. Об этом пограничный маршрутизатор и объявляет в поле «IP- адрес следующего маршрутизатора». Адрес 0.0.0.0 в сообщении типа «ответ» обозначает маршрут, ведущий за пределы RIP-системы. В сообщении типа «запрос» этот адрес означает запрос информации о всех маршрутах (полного вектора расстояний). Указание в сообщении типа «запрос» адреса конкретной сети означает запрос элемента вектора расстояний только для этой сети - такой режим используют обычно только в отладочных целях. Аутентификация может производиться протоколом RIP-2 для обработки только тех сообщений, которые содержат правильный аутентификационный код. При работе в таком режиме первый 20-октетный элемент вектора расстояний, следующий непосредственно за первым 32-битным словом RIP-сообщения, является сегментом аутентификации. Его определяют по значению поля «Набор протоколов сети» (Address Family Identifier), равному в этом случае (FFFF)h. Следующие
-
октета этого элемента определяют тип аутентификации, а остальные 16 октетов содержат аутентификационный код. Таким образом, в RIP-сообщении с аутентификацией может передаваться не 25, а только 24 элемента вектора расстояний, которые следуют за сегментом аутентификации. К настоящему моменту надежного алгоритма аутентификации для протокола RIP не разработано; стандартом определена только аутентификация с помощью обычного пароля (значение поля «Тип» равно 2).
Сообщение RIP состоит из 32-битного слова, определяющего тип сообщения и версию протокола (плюс «Маршрутный домен» в RIP-2), за которым следует набор из одного или более элементов вектора расстояний. Каждый элемент вектора расстояний занимает 5 слов (20 октетов) (см. рис. 5.40).
Максимальное число элементов вектора равно 25, если вектор длиннее, он может разбиваться на несколько сообщений. Таким образом, одно RJP-сообщение может содержать информацию о 25 маршрутах.
С точки зрения маршрутизации работа RIP-2 принципиально не отличается от первой версии протокола. Рассмотрим работу RDM подробнее.
Алгоритм построения таблицы маршрутов. Для более наглядного представления алгоритма введем следующие обозначения.
-
Строку в таблице маршрутов будем записывать в виде Л = 2 —> R3. Это означает, что расстояние от данного маршрутизатора до сети А равно 2, а дейтаграммы, следующие в сеть А, следует пересылать маршрутизатору R3.
-
Вектор расстояний будем записывать в виде (А = 2, В = 1). Это означает, что расстояние от данного маршрутизатора до сети А равно 2, до сети В равно 1.
-
Расстояние до сети, к которой маршрутизатор подключен непосредственно, примем равным 1.
Каждый маршрутизатор, на котором запущен модуль RIP, периодически широковещательно распространяет свой вектор расстояний. Вектор распространяется через все интерфейсы (порты) маршрутизатора, подключенные к сетям, входящим в RIP-систему. Каждый маршрутизатор также периодически получает векторы расстояний от других маршрутизаторов. Расстояния в этих векторах инкрементируются (увеличиваются на 1), после чего сравниваются с данными в таблице маршрутов, и, если расстояние до какой-то из сетей в полученном векторе оказывается меньше расстояния, указанного в таблице, значение из таблицы замещается новым (меньшим) значением, а адрес маршрутизатора, приславшего вектор с этим значением, записывается в поле «Следующий маршрутизатор» в этой строке таблицы. После этого вектор расстояний данного маршрутизатора соответственно изменится.
Рассмотрим построения маршрутной таблицы на примере сети, представленной на рис. 5.41 (компьютеры в сетях не показаны). Рассмотрим процесс формирования таблицы маршрутов применительно к узлу Л1.

В начальный момент времени (например, после подачи питания на маршрутизаторы) таблица маршрутов в узле /?1 (узел /?1 знает только о тех сетях, к которым подключен непосредственно) выглядит следующим образом:
Л = 1->Л1 5=1-»Л1
Следовательно, узел /?1 рассылает в сети А и В вектор расстояний (А = 1, 5=1). Аналогично узел R2 рассылает в сети А, С, D вектор (Л = 1,С=1,£>=1). Узел /?1 получает этот вектор из сети А, увеличивает расстояния на 1 (А = 2, С = 2, D = 2) и сравнивает с данными в своей таблице маршрутов. Новое расстояние до сети А оказывается больше, чем уже внесенное в таблицу (А = 1), следовательно, новое значение игнорируется. Поскольку сети С и D отсутствуют в его таблице маршрутов, они туда вносятся. В узле R1 имеем:
A = l -+RI 5=1->Л1 С=2->Л2 D=2-*R2
Узел R 4 в свою очередь рассылает вектор расстояний (D = 1 ,Е = 1)в сети D и Е. Узел R 2 получает этот вектор из сети D, увеличивает расстояния на 1, после чего добавляет себе в таблицу данные о сети Е (Е = 2 R4). Ранее из узла R1 он получил информацию о сети В и добавил себе в таблицу строку В = 2 —> R1. Узел R 2 рассылает в сети А, С, D свой обновленный вектор расстояний (А = 1,5 = 2, С= 1 ,D= 1,Е = 2). Узел/?1 получает этот вектор от R2 из сети А, увеличивает расстояния на 1: (А = 2, В = 3, С = 2, D = 2, Е = 3) и замечает, что все указанные расстояния, кроме расстояния до сети Е, больше либо равны значениям, имеющимся в его таблице. Сеть Е в таблице узла R1 отсутствует, следовательно, она туда вносится. В результате в узле /?1 таблица маршрутов имеет вид:
Л = 1->Л1 5=1 ->Л1 C=2-*R2 D=2-*R2
Далее маршрутизатор R3, ранее не работавший по каким-либо причинам, рассылает в сети В, С, Е свой вектор (В= l,C= l,E= I). Узел R1 получает этот вектор из сети В, увеличивает расстояния на 1 и обнаруживает, что расстояние Е = 2 меньше имеющегося в таблице Е = 3, следовательно запись о сети Е в таблице заменяется на Е = 2 R3. Остальные элементы полученного от R3 вектора не вызывают обновления таблицы. Итоговая таблица маршрутов маршрутизатора RI выглядит следующим образом:
Л = 1->Л1 5=1->.Л1 C=2-tR2 D=2—*R2 E=2^R3

На этом алгоритм сходится, т. е. при неизменной топологии системы никакие векторы расстояний, получаемые маршрутизатором R1, больше не внесут изменений в таблицу маршрутов. Аналогичным образом алгоритм составления таблицы маршрутов работает и сходится на других маршрутизаторах. Для оперативного реагирования на внезапные изменения топологии сети векторы расстояний периодически широковещательно рассылаются каждым маршрутизатором. Очевидно, что вид построенной таблицы маршрутов может зависеть от порядка получения маршрутизатором векторов расстояний.
Изменение состояния RIP-системы. Рассмотрим случай, когда состояние системы неожиданно изменяется, например, маршрутизатор 1 отключается от сети А (рис. 5.42).
Узел R1 обнаруживает свое отсоединение от сети А и меняет таблицу маршрутов, устанавливая бесконечное расстояние до всех сетей, ранее достижимых через маршрутизаторы, подключенные к сети А (т. е. R2). В протоколе RIP значение бесконечности равно 16.
Л = 16->Л1 Я=1->Л1 С— \6->R2 £>=16->Д2 E=2-+R3
Вектор расстоянии, построенный на основании этой таблицы, рассылается в сеть В, чтобы маршрутизаторы, направлявшие свои данные через RI в ставшие недоступными сети, если таковые маршрутизаторы существуют, соответственно изменили свои маршрутные таблицы. Допустим, в узле R3 имелась следующая таблица маршрутов:
A = 2-*R2 Я=1-»ЛЗ С=1-»ЛЗ Я=2-»Л4 Е= 1 ->R3
Узел
R3
периодически и широковещательно
рассылает в сети В,
С, Е
свой вектор расстояния (А
= 2, В = 1, С = 1, D
= 2, Е
= 1). Узел R1
получает этот вектор, увеличивает
расстояния на 1: (Л = 3, Б = 2, С = 2, Z)
= 3,2? = 2) и замечает, что расстояния A
= 3,C
= 2nD
= 3
меньше бесконечности, следовательно,
соответствующие записи таблицы маршрутов
модифицируются и она принимает вид: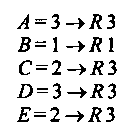
Таким образом, узел /?1 построил маршруты в обход поврежденного участка и восстановил достижимость всех сетей.
К сожалению, поведение дистанционно-векторных протоколов при изменении топологии системы не всегда корректно и предсказуемо. Рассмотрим вышеописанную ситуацию в отношении протокола RIP с отсоединением узла RI от сети А. Выше мы предполагали, что узел R3 не отправлял дейтаграмм через узел /?1 (и, следовательно, изменение таблицы маршрутов в узле Л1 не повлияло на таблицу узла R3 ). Предположим теперь, что R3 отправлял дейтаграммы в сеть А через RI, т. е. таблица в узле R3 имела вид:
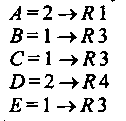
После отсоединения /?1 от сети А узел R3 получает от R\ вектор (А = 16, В = 1, С - 16, D = 16, Е = 2). Проанализировав этот вектор, узел R3 делает вывод, что все указанные в нем расстояния больше значений, содержащихся в его маршрутной таблице, на основании чего этот вектор узлом R3 игнорируется. В свою очередь, узел R3 рассылает в сети В, С, Е вектор (А = 2, В = 1, С = 1, D=2, Е= 1). Узел RI получает этот вектор, увеличивает расстояния на 1: (А = 3,
-
= 2, С = 2, Z) = 3, £ = 2) и замечает, что расстояния Л = 3, С = 2 и D = 3 меньше бесконечности, следовательно, соответствующие записи таблицы маршрутов в узле /?1 модифицируются и она принимает вид:
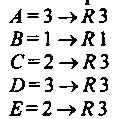
Очевидно, после этого содержимое таблиц узлов Л1 и R3 стабилизируется. Рассмотрим теперь записи о достижении сети А в таблицах маршрутизаторов RluR3.
В
узлеЛ1:![]()
Вузле/?3:
![]()
Таким образом, возникло зацикливание: данные, адресованные в сеть Л, будут пересылаться между узлами /?1 и R3 до тех пор, пока не истечет время жизни дейтаграмм и они не будут уничтожены.
Для того, чтобы избежать зацикливания, в алгоритм рассылки векторов расстояний вносятся дополнения.
-
Если дейтаграммы, адресованные в сеть X, посылаются через маршрутизатор G, находящийся в сети N, то в векторе расстояний, рассылаемом в сети N, расстояние до сети X не указывается.
В нашем примере узел R3 будет рассылать в сети В вектор (В= 1,С= 1,Z) = 2, Е = 1). Элемент А = 2 не будет включен в этот вектор, потому что дейтаграммы в сеть А отправлены узлом R3 через узел /?1, а узел /?1 расположен в сети В. При рассылке узлом R3 вектора расстояний в другие сети элемент А = 2 будет указан (но не будут указаны какие-то другие элементы).
Модификация дополнения 1 позволяет ликвидировать более сложные особые ситуации, в том числе, некоторые случаи счета до бесконечности.
1А. Если дейтаграммы, адресованные в сеть X, посылаются через маршрутизатор G, находящийся в сети N, то в векторе расстояний, рассылаемом в сети N, расстояние до сети X полагается равным бесконечности. Тем не менее, и в этом случае могут возникать особые ситуации.
-
Если маршрутизатор G объявляет новое расстояние до сети X, то это расстояние вносится в таблицы маршрутов узлов, отправляющих дейтаграммы в сеть X через G независимо от того, больше оно или меньше уже внесенного в таблицы расстояния.
В нашем примере это означает, что если в маршрутной таблице узла R3 записано А = 1 -»Л1 и/?3 получает от/?1 вектор с элементом А = 16, то несмотря на то, что 1 < оо, узел R3 модифицирует запись в таблице: Л = 16 —> RI. Однако таким образом устраняются далеко не все случаи зацикливания.
Счет до бесконечности. При отказе оборудования может сложиться ситуация, при которой сеть, например А, оказывается изолированной, а маршрутизаторы, следуя алгоритму RIP будут обмениваться векторами до тех пор, пока расстояние до этой сети не станет равным бесконечности в маршрутных таблицах всех маршрутизаторов. В течение «счета до бесконечности» сеть А считается достижимой, поскольку расстояние до нее считается конечным и все дейтаграммы, адресованные в сеть А, отправляются маршрутизаторами согласно их таблицам по кругу.
Чтобы уменьшить отрицательный эффект этого явления, значение бесконечности не должно быть велико. В протоколе RIP оно равно 16, что, в свою очередь, ограничивает размер RIP-системы.
Работа протокола RIP. Каждому маршруту ставится в соответствие таймер тайм-аута и «сборщика мусора».Тайм-аут-таймер сбрасывается каждый раз, когда маршрут инициализируется или корректируется. Если со времени последней коррекции прошло 3 мин или получено сообщение о том, что вектор расстояния равен 16, маршрут считается закрытым. Но запись о нем не стирается до тех пор, пока не истечет время «уборки мусора» (2 мин).
При получении сообщения типа «ответ» для каждого содержащегося в нем элемента вектора расстояний модуль RIP выполняет следующие действия:
-
проверяет корректность адреса сети и маски, указанных в сообщении;
-
проверяет, не превышает ли метрика (расстояние до сети) бесконечности:
-
некорректный элемент игнорируется;
-
если метрика меньше бесконечности, она увеличивается на 1;
-
производится поиск сети, указанной в рассматриваемом элементе вектора расстояний, в таблице маршрутов;
-
если запись о такой сети в таблице маршрутов отсутствует и метрика в полученном элементе вектора меньше бесконечности, сеть вносится в таблицу маршрутов с указанной метрикой; в поле «Следующий маршрутизатор» заносится адрес маршрутизатора, приславшего сообщение; запускается таймер для этой записи в таблице;
-
если искомая запись присутствует в таблице с метрикой больше, чем объявленная в полученном векторе, в таблицу вносятся новые метрика и, соответственно, адрес следующею маршрутизатора; таймер для этой записи перезапускается;
-
если искомая запись присутствует в таблице и отправителем полученного вектора был маршрутизатор, указанный в поле «Следующий маршрутизатор» этой записи, то таймер для этой записи перезапускается; более того, если при этом метрика в таблице отличается от метрики в полученном векторе расстояний, в таблицу вносится значение метрики из полученного вектора;
-
во всех прочих случаях рассматриваемый элемент вектора расстояний игнорируется.
Сообщения типа «ответ» модуль RIP рассылает каждые 30 с по широковещательному или групповому (только RIP-2) адресу. Рассылка «ответа» может происходить также вне графика, если была изменена маршрутная таблица. Стандарт требует, чтобы в этом случае «ответ» рассылался не немедленно после изменения таблицы маршрутов, а через случайный интервал длительностью от 1 до 5 с. Это позволяет несколько снизить нагрузку на сеть.
В каждую из сетей, подключенных к маршрутизатору, рассылается свой собственный вектор расстояний, построенный с учетом дополнения 1 (JA), сформулированного выше. Там, где это возможно, адреса сетей агрегируются (обобщаются), т. е. несколько подсетей с соседними адресами объединяются под одним, более общим адресом с соответствующим изменением маски.
В случае рассылки «ответа» вне графика (triggered response) посылается информация только о тех сетях, записи о которых были изменены. Информация о сетях с бесконечной метрикой посылается только в том случае, если она была недавно изменена.
При получении сообщения типа «запрос» с адресом 0.0.0.0 маршрутизатор рассылает в соответствующую сеть обычное сообщение типа ответ. При получении запроса с любым другим значением в поле (полях) «IP-адрес» посы-
лается ответ, содержащий информацию только о сетях, которые указаны. Такой ответ посылается только на адрес запросившего маршрутизатора (не широковещательно), при этом дополнение 1 (1А) не учитывается.
Конфигурирование RIP. Общий порядок действий при конфигурировании модуля RIP следующий:
-
указать, какие сети, подключенные к маршрутизатору, будут включены в RIP-систему;
-
указать nonbroadcast networks, т. е. сети со статической маршрутизацией (например, тупиковые сети, подсоединенные к внешнему миру через единственный шлюз), куда не нужно рассылать векторы расстояний;
-
указать permanent routes - статические маршруты, например, маршрут по умолчанию за пределы автономной системы.
Протокол RIP очень прост, но так как он разрабатывался для локальных сетей, ему присущи следующие недостатки:
-
малое значение бесконечности (из-за эффекта «счет до бесконечности») ограничивает размер RIP-системы четырнадцатью промежуточными маршрутизаторами в любом направлении. Кроме того, по той же причине весьма затруднительно использование сложных метрик, учитывающих не просто количество промежуточных маршрутизаторов, но и скорость и качество канала связи (чем медленнее канал, тем больше метрика);
-
само явление счета до бесконечности вызывает сбои в маршрутизации;
-
широковещательная рассылка векторов расстояний каждые 30 с ухудшает пропускную способность сети;
-
время схождения алгоритма при создании маршрутных таблиц достаточно велико (по крайней мере, по сравнению с протоколами состояния связей);
-
несмотря на то что каждый маршрутизатор начинает периодическую рассылку своих векторов, вообще говоря, в случайный момент времени (например, после включения), через некоторое время в системе наблюдается эффект синхронизации маршрутизаторов, сходный с эффектом синхронизации аплодисментов. Все маршрутизаторы рассылают свои вектора в один и тот же момент времени, что приводит к большим пикам трафика и отказам в маршрутизации дейтаграмм во время обработки большого количества одновременно полученных векторов;
-
при использовании RIP таблица каждого маршрутизатора содержит полный список всех сетевых идентификаторов и возможных путей к ним. Она включает сотни или даже тысячи записей для большой объединенной IP-сети с многочисленными путями. Поскольку максимальный размер одного RIP-пакета составляет 512 байт, то для отправления больших таблиц маршрутизации необходимо множество RIP-пакетов.
-
в таблице маршрутизации каждой записи о маршруте, полученном по RIP, назначен 3-минутный тайм-аут, по истечение которого не обновленные записи удаляются. Если маршрутизатор выходит из строя, распространение изменений по объединенной сети может занять несколько минут. Возникает проблема медленной конвергенции.
Протокол маршрутизации OSPF (Open Shortest Path First) представляет собой протокол состояния связей, использующий алгоритм SPF поиска кратчайшего пути в графе. OSPF применяют для внутренней маршрутизации в системах сетей любой сложности. Рассмотрим работу алгоритма SPF и построение маршрутов на примере OSPF-системы, состоящей из маршрутизаторов, соединенных линиями связи типа «точка-точка» (рис. 5.43).
Метрика представляет собой оценку качества связи в данной сети (на данном физическом канале); чем меньше метрика, тем лучше качество соединения. Метрика маршрута равна сумме метрик всех связей (сетей), входящих в маршрут. В простейшем случае, как это имеет место в протоколе RIP, метрика каждой сети равна единице, а метрика маршрута равна его длине в хопах.
Поскольку при работе алгоритма SPF ситуации, приводящие к счету до бесконечности, отсутствуют, значения метрик могут варьироваться в широком диапазоне. Кроме того, протокол OSPF позволяет определить для любой сети различные значения метрик в зависимости от типа сервиса (тип сервиса запрашивается дейтаграммой в соответствии со значением поля «Тип обслуживания» (ToS) ее заголовка.) Для каждого типа сервиса вычисляется свой маршрут, и дейтаграммы, затребовавшие наиболее скоростной канал, могут быть отправлены по одному маршруту, а затребовавшие наименее дорогостоящий канал - по другому.
Метрика сети, оценивающая пропускную способность, определяется как количество секунд, требуемое для передачи 100 Мбит через физическую среду данной сети. Например, метрика сети на базе 10Base-T Ethernet равна 10, а метрика выделенной линии 56 кбит/с - 1785. Метрика канала со скоростью передачи данных 100 М бит/с и выше равна единице.
Порядок расчета метрик, оценивающих надежность, задержку и стоимость, не определен. Администратор, желающий поддерживать маршрутизацию по этим типам сервисов, должен сам назначить разумные и согласованные метрики по этим параметоам.
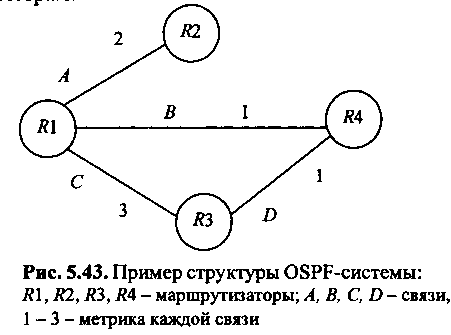
Если не требуется маршрутизация с учетом типа сервиса (или маршрутизатор ее не поддерживает), используют метрику по умолчанию, равную метрике по пропускной способности. Именно ее и будем использовать в дальнейшем.
Для
работы алгоритма SPF
на каждом маршрутизаторе строится
база данных состояния связей,
представляющая собой полное описание
графа OSPF-системы.
При этом вершинами графа являются
маршрутизаторы, а ребрами - соединяющие
их связи. Базы данных на всех маршрутизаторах
идентичны. За создание баз данных и
поддержку их взаимной синхронизации
при изменениях в структуре системы
сетей отвечают другие алгоритмы,
содержащиеся в протоколе OSPF.
Рассмотрим эти алгоритмы позже, а сейчас
будем считать, что базы данных на всех
маршрутизаторах каким-то образом
построены, синхронизированы и правильно
описывают граф системы в данный
момент времени.
База данных состояния связей (рис. 5.44) представляет собой таблицу, где для каждой пары смежных вершин графа (маршрутизаторов) указано ребро (связь), их соединяющее, и метрика этого ребра. Граф считается ориентированным, т. е. ребро, соединяющее вершину /?1 с вершиной R2, и ребро, соединяющее вершину R2 с вершиной Л1, могут быть различны или это может быть одно и то же ребро, но с разными метриками.
Алгоритм поиска кратчайшего пути. Рассмотрим алгоритм SPF поиска кратчайшего пути, предложенный Е.В. Дейкстрой (E.W. Dijkstra). Алгоритм SPF, основываясь на базе данных состояния связей, вычисляет кратчайшие пути между заданной вершиной S-графа и всеми остальными вершинами. Результатом работы алгоритма является таблица, где для каждой вершины V-графа указан список ребер, соединяющих заданную вершину S с вершиной V по кратчайшему пути.
Введем следующие обозначения:
Е - множество обработанных вершин, т. е. вершин, кратчайший путь к которым от заданной вершины S уже найден;
R — множество оставшихся вершин графа (т. е. множество вершин графа за вычетом множества Е);
О — упорядоченный список путей.
Шаг 1. Инициализировать E={S}, R={Bce вершины графа, кроме S}. Поместить в О все односегментные (длиной в одно ребро) пути, начинающиеся из S, отсортировав их в порядке возрастания метрик.
Шаг 2. Если О пуст или первый путь в О имеет бесконечную метрику, то отметить все вершины в R как недостижимые и закончить работу алгоритма.
Шаг 3. Рассмотрим Р - кратчайший путь в списке О. Удалить Р из О. Пусть V - последний узел в Р. Если V е Е, перейти на шаг 2; иначе Р является кратчайшим путем из S в V (будем записывать как V:P); перенести V из R в Е.
Шаг 4. Построить набор новых путей, подлежащих рассмотрению, путем добавления к пути Р всех односегментных путей, начинающихся из V. Метрика каждого нового пути равна сумме метрики Р и метрики соответствующего односегментного отрезка, начинающегося из V. Добавить новые пути в упорядоченный список О, поместив их на места в соответствии со значениями метрик. Перейти к шагу 2.
Все вычисления вычисляются локально по известной базе данных, а потому значительно быстрее по сравнению с дистанционно-векторными протоколами, при этом результаты получаются на основе полной, а не частичной информации о графе системы сетей.
Предположим, что к маршрутизатору /?4 подключена сеть N1 компьютеров (хостов) Нх - Нк. Следуя разобранной выше модели, каждый хост должен бьггь также вершиной графа OSPF-системы, хотя сам и не строит базу данных и не производит вычисления маршрутов. Тем не менее, информация о связях маршрутизатора /?4 с каждым из хостов сети М и о метриках этих связей должна быть внесена в базу данных, чтобы все остальные маршрутизаторы системы могли построить маршруты от себя до этих хостов. Очевидно, что такая процедура неэффективна. Вместо информации о связях с каждым хостом в базу данных вносится информация о связи с сетью, т. е. сама IP-сеть становится вершиной графа системы, соединенной с маршрутизатором R4 некоторой связью Р (рис. 5.45).
В данном случае сеть, точнее ее адрес, используется как обобщающий идентификатор группы хостов, находящихся в одной IP-сети, к которой маршрутизатор М непосредственно подключен. Вершина N1 называется тупиковой сетью (stub network)', все узлы сети, обозначаемые этой вершиной, являются хостами, у которых установлен маршрут по умолчанию, направленный на маршрутизатор R4.
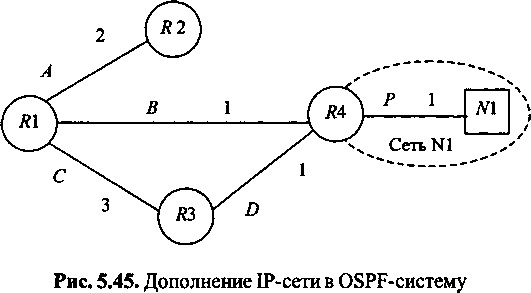
Протокол OSPF проводит разграничение хостов и маршрутизаторов. Если к 1Р-сети N1 подключен еще и один из интерфейсов маршрутизатора R2, то связь между R2 и R4 будет установлена отдельно, как если бы они были соединены двухточечной линией связи (при
этом
у маршрутизатора R2
также будет связь с тупиковой сетью
N1).
При подключении тупиковой сети N1 в базе данных состояния связей появится запись (рис. 5.46).
Связей, направленных из вершины N1, в базе данных нет и не будет, потому что вершина N1 не является маршрутизатором. Построение маршрутов до вершины N1 (т. е. фактически сразу до всех хостов сети N1) будет осуществлено каждым маршрутизатором обычным способом по алгоритму SPF.
Поддержка множественных маршрутов. Если между двумя узлами сети существует несколько маршрутов с одинаковыми или близкими по значению метриками, протокол OSPF позволяет направлять части трафика по этим маршрутам в пропорции, соответствующей значениям метрик. Например, если есть два альтернативных маршрута с метриками 1 и 2, то две трети трафика будет направлено по первому из них, а оставшаяся треть - по второму. Положительный эффект такого механизма заключается в уменьшении средней задержки прохождения дейтаграмм между отправителем и получателем, а также в уменьшении колебаний значения средней задержки.
Менее очевидное преимущество поддержки множественных маршрутов состоит в следующем. Если при использовании только одного из возможных маршрутов этот маршрут внезапно выходит из строя, весь трафик будет разом перемаршрутизирован на альтернативный маршрут, при этом во время процесса массового переключения больших объемов трафика с одного маршрута на другой весьма велика вероятность образования затора на новом маршруте. Если же до аварии использовалось разделение трафика по нескольким маршрутам, отказ одного из них вызовет перемаршрутизацию лишь части трафика, что существенно сгладит нежелательные эффекты.
Рассмотрим следующий пример (рис. 5.47). Узел /?1 отправляет данные в
узел
R3,
используя поддержку множественных
маршрутов, по маршрутам С
(2/3 трафика) и АВ
(1/3 трафика). Однако узел R2
тоже поддерживает механизм множественных
путей, и когда к нему пребывают
дейтаграммы, адресованные в R3
(в том числе, и отправленные из Л1), он
применяет к ним ту же логику, т. е. 2/3
из них отправляет в R3
по маршруту В,
а одну треть - по маршруту АС.
Следовательно,
1/9 дейтаграмм, отправленных узлом /?1 в
узел R3,
возвращаются опять в узел ‘ Л1, который
1/3 из них опять отправляет в R3
по
маршруту С, а 2/3 - по маршруту АВ
через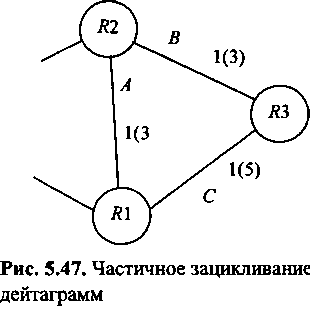
узел R2 и т. д. В итоге сформировался «частичный цикл» при посылке дейтаграмм из /?1 в R3, который, помимо частичного зацикливания дейтаграмм, ведет к быстрой перегрузке линии А.
Избежать зацикливание дейтаграмм позволяет следующее правило:
если узел X отправляет данные в узел Y, он может пересылать их через узел Q только в том случае, если Q ближе к Y, чем к X.
В приведенном примере, следуя этому правилу, Л1 не может посылать данные в R3 через R2, поскольку R2 не ближе к R3, чем R1. Однако такая посылка возможна, если связи между узлами имеют соответствующие метрики, на рис.5.47 эти значения приведены в скобках.
Для реализации построения дополнительных альтернативных маршрутов с учетом вышеприведенного правила в алгоритме SPF необходимо внести изменения в шаг 3 и добавить шаг За. Ниже приведена новая версия алгоритма SPF, в которой изменение и дополнение показаны курсивом.