

Имитационное моделирование
Третья технология Big Data – имитационное моделирование. Использование больших данных в сочетании с имитационными моделями определяет создание такой технологии, как цифровой двойник процесса или системы. Имитационная математическая модель представляет собой совокупность дифференциальных (в зависимости от времени и множества факторов) уравнений и неравенств, отражающих развитие какой-либо системы.
В сельском хозяйстве имитационные модели могут создаваться по отношению к таким объектам, как растение (сельхозкультура), отдельный производственный процесс (например, уборка зерновых культур), природа (климатические условия) и экосистема в целом.
Для реализации имитационных моделей наиболее широко используются такие программные средства, как Arena, GPSS, AnyLogiс, Ithink, Vensim и др.
Так, например, создана имитационная модель роста и развития кукурузы. В ней математически определяется влияние различных факторов на развитие кукурузы в различных стадиях вегетации растения (рисунок 34).
 Факторы,
включаемые
в
имитационную
модель
роста
кукурузы
Факторы,
включаемые
в
имитационную
модель
роста
кукурузы
Это делается для того, чтобы испытывать на модели, а не на реальной системе влияние различных факторов на рост кукурузы. То есть проводить опыты не в реальных условиях, а на модели, что приведет к значительной экономии времени и средств.
В сельском хозяйстве могут быть использованы имитационные модели, которые позволяют рационализировать или оптимизировать производственные процессы. Например, имитационная модель уборки зерновых культур, реализуемая в системе AnyLogiс. Эта модель отражает различные подпроцессы при уборке зерновых культур – намолот зерна комбайнами, перемещение зерна в бункер, подъезд машина к комбайну, транспортировка зерна до тока. Такая модель создается для того, чтобы оптимизировать процесс, выбрать наиболее подходящее количество техники для данных условий и данного поля с его конфигурацией и расстояниями до тока, гаража количество техники, учитывая ее себестоимость и производительность.
Это также ведет к экономии средств и является одним из инструментов системы поддержки принятия решений по рациональной организации процессов в отрасли.
Визуализация данных, статистический анализ
Четвертая технология Big Data – это технология визуализации данных.
Например, так выглядит динамика цен на пшеницу. Данные приведены для 9 регионов России с ноября 2018 по октябрь 2021 год – Краснодарский и Алтайский края, Ростовская область, Ставропольский край, Воронежская, Тамбовская, Саратовская, Самарская, Курганская, Новосибирская области. Каждый регион отражает отдельный цвет линии.
При разнородности поступающих больших данных и имеющихся колебаниях визуализация больших данных тем не менее позволяет уловить два неоспоримых факта – что скачки цен происходили во всех этих 9 регионах практически одновременно, и общим трендом является рост цен на озимую пшеницу за рассматриваемый период.
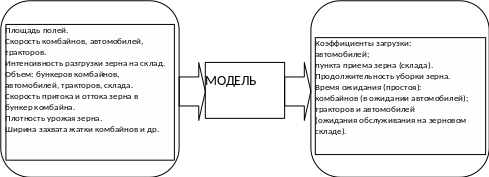 Входные
данные
модели Выходная
информация
Входные
данные
модели Выходная
информация
Входная и выходная информация имитационной модели процесса уборки зерновых культур
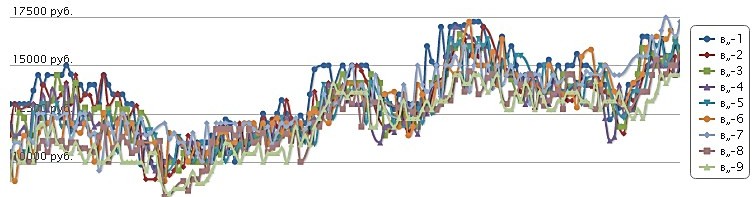
Динамика цен на пшеницу по 9 регионам Российской Федерации
(источник – сайт «Агроновости» https://agro-bursa.ru/prices/wheat/)
Пятая группа методов Big Data – это методы статистического анализа. Представляет собой практически все известные методы, так как статистика представляет собой науку о методах сбора и анализа именно массовых данных. В отношении Big Data используют такие статистические методы, как дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов, анализ выживаемости, анализ связей.