Подгон для зачёта ПЛИС FPGA
.docxПодгон для ПЛИС FPGA
Внутренняя структура FPGA
Что такое FPGA? - FPGA (field-programmable gate array, программируемая пользователем вентильная матрица, которая в свою очередь состоит из таких элементов как:
1) Logic cell(LC – логическая ячейка) –
1.1) LUT(Look Up Table) –
реализация Функций Алгебры Логики в
виде таблиц истинности
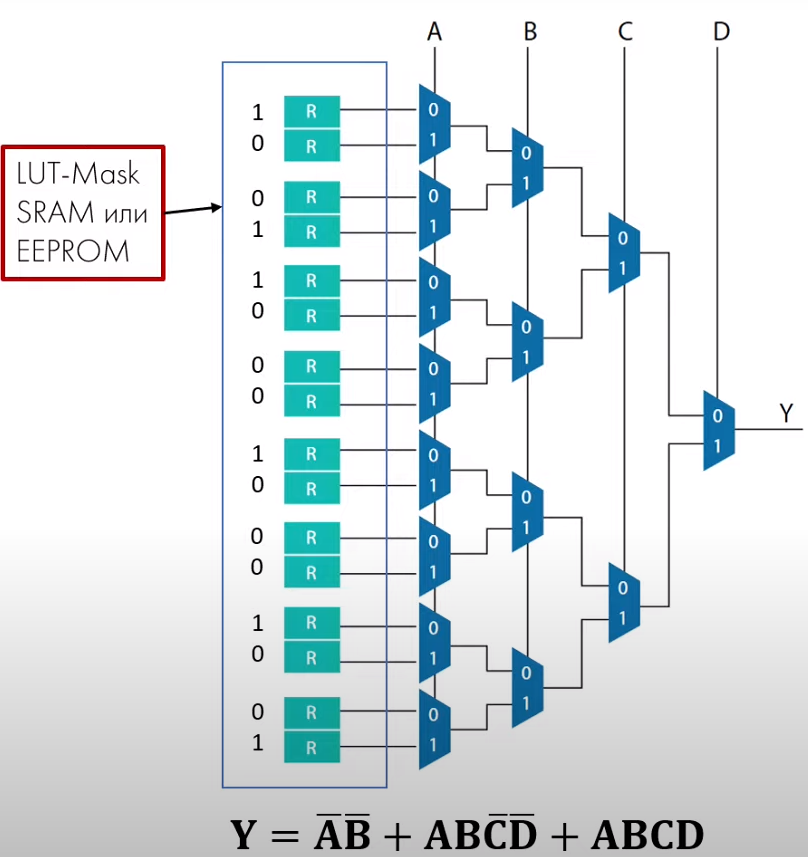
1.2) Регистры –
1.3) Мультиплексоры -
1.4) Цепи переноса –
2) Сеть межсоединений (Interconnect) –
3) Блочная распределительная память –
4) Порты ввода/вывода (I/O) –
5) Блоки генерации частота (ФАПЧ, PLL) –
6) Блоки цифровой обработки сигналов (DSP) -
7) Опционально; могут входить блоки для хранения данных, в которые входят буферы FIFO (First Input First Output)
2.
Что такое LE? Из каких частей состоит
простой LE? (Здесь имеется в виду LC)
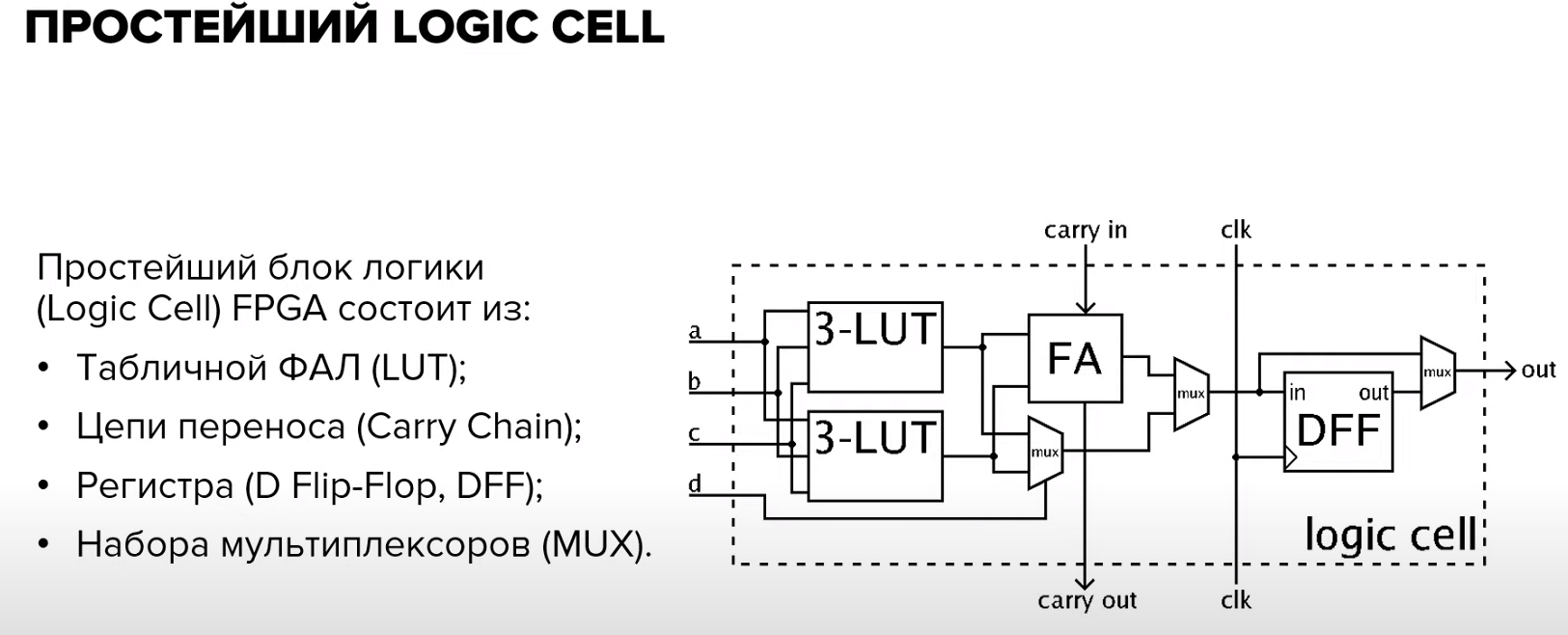
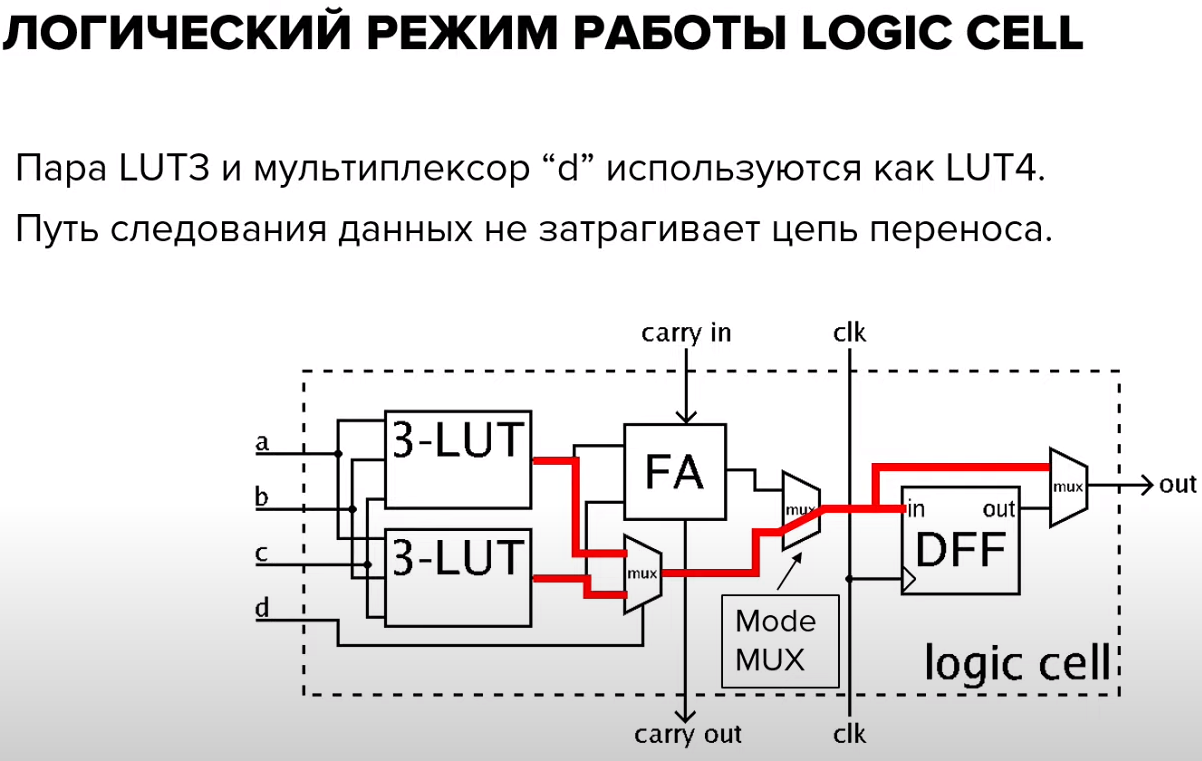
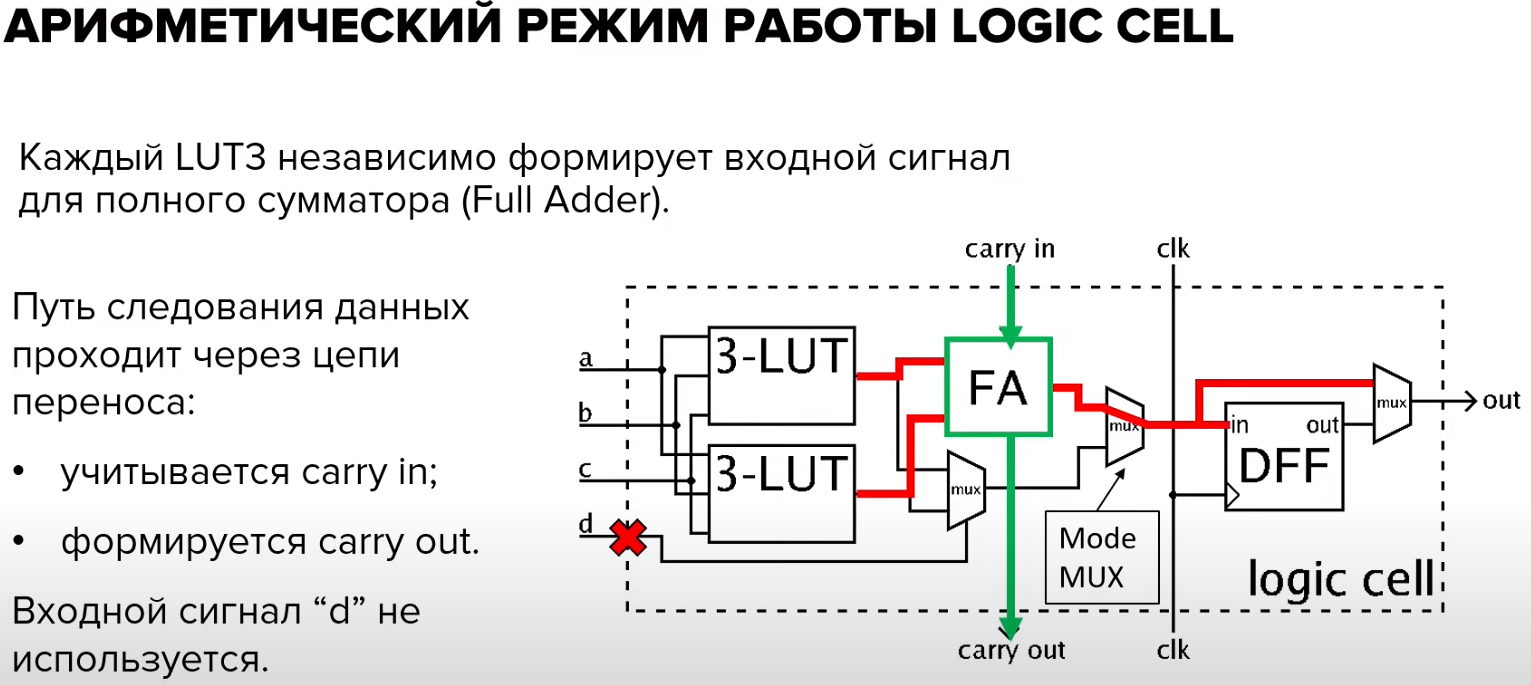
3. Какие режимы работы есть у LE?
Что такое Slice в Xilinx 7?
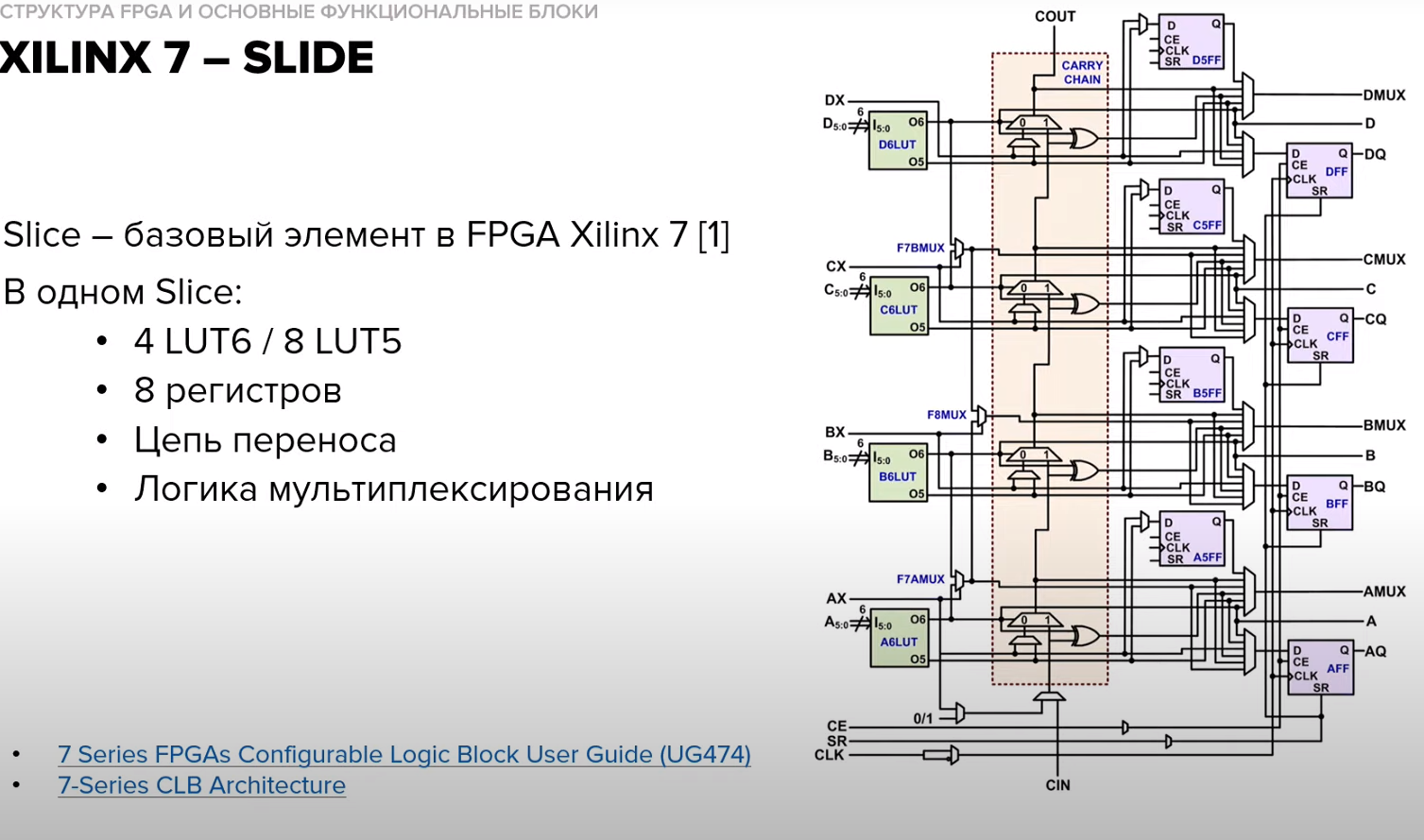
Слайс
это базовый элемент в семействе Xilinx
7

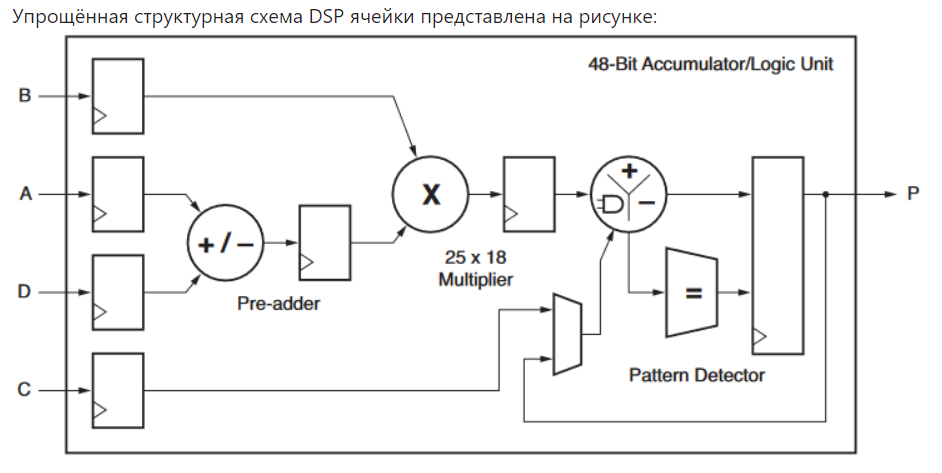
DSP ячейки
Что такое DSP ячейка, зачем она нужна?
Что эффективнее использовать для выполнения операции умножения: LUT или DSP? Почему?
Какие составные части есть у DSP ячейки Xilinx 7?
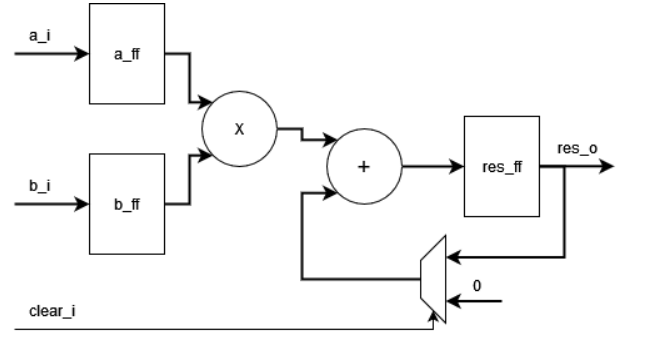
Как можно реализовать умножение с накоплением на базе DSP ячейки?
Что такое SIMD? Зачем такой режим нужен в DSP ячейке?
Какой тип сброса может быть реализован в регистрах DSP ячейки Xilinx 7?
Что такое обнаружитель паттернов и зачем он может быть использован?
DSP ячейка состоит из:
Умножителя разрядностью 25 x 18 бит (25x18 multiplier)
Предварительного сумматора (pre-adder), позволяющий не только выполнить умножение, но и просуммировать два числа, а сумму подать на один из входов умножителя.
Блока АЛУ, способного работать в режиме SIMD – single instruction multiple data, имеется возможность разбиения АЛУ на 2 или 4 "виртуальных", каждый шириной по 24 или 12 бит соответственно.
Определителя паттернов (pattern detector) . На самом деле это просто хитрый компаратор, который смотрит на выход DSP ячейки и позволяет реализовывать целый ряд полезных операций, таких как обнаружение переполнения или округление чисел.
Регистр-аккумулятор шириной 48 бит
Промежуточных регистров
Мультиплексоров данных
DSP ячейка предназначена для цифровой обработки сигналов
Эффективнее использовать DSP ячейки, поскольку они будут работать с большей частотой, что гарантирует большее количество операций за единицу времени
В DSP ячейках могут быть только регистры с синхронным сбросом, асинхронный сброс будет вынесен за пределы ячейки и использовать регистры из SLICE
Ещё более интересным примером использования DSP ячейки является реализация умножения с накоплением. Умножение с накоплением является основой целого ряда математических алгоритмов, в особенности, связанных с ЦОС.
Пример реализует схему, показанную на рисунке. Необходимо понимать, что в этом примере для суммирования-накопления используется АЛУ DSP ячейки, в то время как в предыдущем примере использовался предварительный сумматор. То есть в теории можно уместить в рамках одной DSP ячейки оба примера одновременно, так как они используют разные аппаратные ресурсы для сложения.
LUTRAM и BRAM
Что такое LUTRAM?
LUT как память (Distributed RAM, LUTRAM) - часть таблиц LUT в FPGA можно использовать для хранения данных. Максимальный объём памяти LUTRAM: 1.216.512 бит или 152.064 байт
Что такое BRAM?
Блочная память (BRAM) - специальные аппаратные блоки памяти. Максимальный объём памяти BRAM: 4.976.640 бит или 622.080 байт
Чем отличается LUTRAM от BRAM?
LUTRAM и регистры позволяют реализовать асинхронное чтение из памяти, а BRAM реализует только синхронное чтение.
Что такое синхронное и асинхронное чтение из памяти?
Кроме того, различают память с синхронным и асинхронным чтением. В первом случае, перед выходным сигналом шины данных ставится дополнительный регистр, в который по тактовому синхроимпульсу записываются запрашиваемые данные. Такой способ может очень сильно сократить критический путь цифровой схемы, но требует дополнительный такт на доступ в память. В свою очередь, асинхронное чтение позволяет получить данные, не дожидаясь очередного синхроимпульса, но такой способ увеличивает критический путь.
Что такое byte enable?
Часто при записи в память требуется перезаписывать не всё слово целиком, а только отдельные байты. Самым распространенным примером является обращение процессора в память данных при операциях над 8 и 16-битными данными. Мы видим, что сигнал we_i стал многобитным, появились параметры NB_COL - количество байтов, COL_WIDTH - ширина байта (на случай, если понадобится отличная от 8).
Чтение из памяти реализовано через отдельный always_ff блок:
Здесь используется конструкция generate, которая перебирает все байты, и для каждого i-го байта проверяет бит we_i[i]. Если этот бит равен 1, то в соответствующий байт происходит запись.
Что такое инициализация памяти?
Это определения типа записи, размера памяти, адресов, размера слова в ячейке памяти это момент объявления какого-либо начального установочного адреса или значения с целью предотвращения неопределённых ситуаций
Что такое политика чтения No Change?
Режим "No change" предполагает, что значение на выходе rdata_o после записи не будет меняться, по сути, там останется результат предыдущей операции чтения. Такой тип памяти встречается очень часто и считается наиболее энергоэффективными, причем как в FPGA, так и в ASIC, поскольку при записи не происходит переключения регистра чтения.
Что такое политика чтения Read First?
Существуют дизайны, где отступление от политики "No change" позволяет упростить логику или повысить её эффективность. Одной из альтернативных политик является "Read First". То есть память производит чтение всегда, когда активен сигнал en_i. Так как используется неблокирующее присваивание <=, то при записи в регистр data_out_ff попадёт значение, которое хранилось в памяти до записи (не то значение, которое записывается в данный момент).
Что такое политика чтения Write First?
Политика "Write First" реализует обратный "Read First" алгоритм. То есть в регистр data_out_ff попадает новое записываемое слово при записи и вычитанное из памяти значение при чтении.
Что такое однопортовая память?
BRAM - Однопортовая память. Самая простая память - это память с одним портом. Через один порт в один момент времени мы можем либо писать, либо читать данные. Одновременно можно производить только одну операцию.
Зачем может быть полезен дополнительный регистр на выходе чтения BRAM?
Для увеличения тактовой частоты работы BRAM можно добавить ещё один дополнительный регистр на выход чтения В таком примере регистр data_out_reg_ff защелкивает значение из уже знакомого нам data_out_ff. Таким образом, повышается тактовая частота, но увеличивается латентность памяти (память теперь выдаёт результат чтения не на следующий такт, а через такт)
Что такое простая двухпортовая память (Simple Dual Port)? Чем она отличается от однопортовой?
Ранее мы рассмотрели синхронные памяти с одним портом. Такие памяти позволяют одновременно читать или записывать только одно слово. Давайте теперь рассмотрим памяти с двумя портами. Начнём с так называемой "простой двухпортовой памяти" (Simple Dual Port). Эта память имеет два независимых порта, причём один порт используется только для записи данных, а второй порт используется только для чтения. Порты этой памяти мы будем называть "порт a" и "порт b". При этом порт a используется только для записи, а порт b только для чтения. В этом блоке между if (we_a_i) и if (en_b_i) отсутствует ключевое слово else, то есть обе проверки выполняются параллельно, и чтение никак не зависит от записи.
Что такое настоящая двухпортовая память (True Dual Port)? Чем она отличается от однопортовой?
Следующий тип памяти - настоящая двухпортовая (True Dual Port). В такой памяти каждый порт работает независимо от другого, при этом на каждом порту возможно как читать, так и записывать данные. Логика работы каждого порта памяти одинакова и полностью повторяет логику работы однопортовой памяти "No Change mode".
Что такое память с двумя тактовыми частотами? Как сделать такую память на базе двухпортовой памяти?
Двухпортовая память с двумя тактовыми частотами почти не отличается от своих аналогов с одной тактовой частотой. Не отходя далеко от настоящей двухпортовой памяти, давайте поменяем её так, чтобы каждый порт теперь работал на своей собственной тактовой частоте. Данный пример почти ничем не отличается от bram_dp_true_1clk, за исключением того, что теперь на вход подаются два сигнала тактовой частоты (clk_a_i и clk_b_i), и каждый из двух портов теперь тактируется от своей тактовой частоты. Давайте рассмотрим пример простой двухпортовой памяти с двумя тактовыми частотами. В данном примере есть два always_ff блока, причем один (запись в память по порту a) работает от тактовой частоты clk_a_i, а второй блок (чтение из памяти по порту b) работает от тактовой частоты clk_b_i.
Конвейеры и систолические массивы
Что такое критический путь?
Критический путь – максимально длинная цепочка комбинаторной логики в цифровой схеме, ограничивающая её тактовую частоту.
Что такое конвейер в цифровой технике?
Конвейер как труба с водой - чтобы получить воду на одном конце трубы, нужно заполнить трубу водой и дождаться момента, когда она протечёт до другого конца. Конвейер начинает выдавать выходные данные с некоторой задержкой, связанной с заполнением его промежуточных регистров данными. Как только конвейер заполнится, он может выдавать новые выходные данные каждый такт. Осуществляется это добавлением регистров после каждой логической операции для достижения большего количества полезных данных в единицу времени
Что такое латентность конвейера?
Латентностью (latency) конвейера называют задержку в тактах между подачей входных данных и получением соответственных выходных результатов. Если проще - это время на заполнение конвейера.
Из чего складывается энергопотребление цифровой микросхемы? Опишите составляющие.
Важной задачей инженера является оптимизация цифровых дизайнов по энергопотреблению, то есть снижение энергопотребления. А что такое энергопотребление цифровой микросхемы и из чего оно складывается? Существуют два фактора, в сумме почти целиком формирующих энергопотребление цифрового дизайна:
Статическое энергопотребление - некоторый ненулевой ток, всегда бежит через полевые транзисторы, даже если эти транзисторы закрыты. Этот ток определяется параметрами технологического процесса и в том числе степенью удачности конкретного экземпляра микросхемы. Мы, как цифровые инженеры, можем повлиять на этот параметр только уменьшением дизайна, и, как следствие, сокращением количества транзисторов.
Динамическое энергопотребление - расход энергии на зарядку и разрядку паразитных емкостей (конденсаторов). Мы не можем избавиться от таких емкостей в микросхеме (разве что уменьшать дизайн), но мы можем эффективно ограничить переключения логики только в те моменты, когда это действительно нужно.
Конвейеры включают в себя достаточно большое количество регистров, при этом регистры разделяют стадии конвейера. Таким образом, если мы ограничим переключение регистров, то снизится динамическое энергопотребление.
Что такое Clock gating? Какие виды Clock gating вы знаете?
Clock gating – механизм отключения тактирования фрагментов логики, когда она не нужна. Нет переключения тактовой частоты – нет динамического энергопотребления (но остаётся статическое). Реализация Clock gating возможна на нескольких уровнях иерархии:
«Fine grained» – автоматическое задействование Clock gating для отдельных регистров через «enable». Начиная с определенной ширины регистра (десятки бит для 130-180 нм и единицы бит для 7 нм и ниже) синтезатор автоматически конвертирует enable регистра в блок clock gating. Наиболее часто применяющийся на практике, его мы и будем использовать в этой лабораторной работе. Принцип работы показан на рисунке.
Использование вручную примитива (черного ящика) «Clock gating» для отключения тактирования средних фрагментов логики. Например, в GPU можно использовать незадействованные в данный момент шейдерные ядра.
Отключение тактирования крупных блоков на уровне СнК. Аналогично предыдущему, но распространяется на более крупные узлы: отключение процессорных ядер или кластеров из ядер и так далее.
Что такое free running регистры?
Регистры, которые всегда переключаются (их сигнал enable в явном или неявном виде выставлен всегда в "1") называются free running.
Зачем может быть полезен флаг валидности данных в конвейере?
Давайте добавим в конвейер флаг валидности данных valid, перемещающийся вместе с данными. Если валидных данных на входе регистра нет, то и защелкивать ничего не нужно – в такой момент можно убрать enable на соответствующей стадии конвейера. Мы видим, что регистры, хранящие флаг valid, переключаются каждый такт. В то же время, разрядность этих регистров 1 бит на стадию, и существенного влияния на энергопотребление они не оказывают. Регистры, хранящие промежуточные результаты вычислений и x теперь стали переключаться только тогда, когда необходимо. При этом разрядность таких регистров может достигать десятков бит. Таким образом, добавив в конвейер небольшое (единицы) количество неограниченно переключающихся регистров с valid, мы смогли ограничивать переключение десятков и сотен других регистров в моменты, когда в этом нет необходимости.
Чем синхронный сброс отличается от асинхронного?
Синхронный сброс - мультиплексор перед входом данных регистра, увеличивает собой комбинаторную логику перед входом регистра, часто ухудшает критический путь. Собственно, такой тип сброса называется синхронным, поскольку данные сброса на вход регистра поступают по цепочке входных данных по фронту сигнала синхронизации.
Асинхронный сброс - вход reset/clear/set регистра, моментальный асинхронный сброс регистра, использующий дополнительную логику в регистре. Такой сброс не увеличивает комбинаторную цепочку перед входом данных регистра.
Почему в ASIC лучше использовать регистры без асинхронного сброса там, где это возможно?
Размер регистров на кристалле ASIC может отличаться не только в зависимости от их ширины. В частности, на размер регистра влияет наличие или отсутствие у него асинхронного сброса. Наличие сброса увеличивает площадь одного регистра приблизительно на 25-35%.
Что такое систолический массив? Зачем он может применяться?
Систолический
массив –
однородная сеть тесно связанных блоков
обработки данных, узлов. Каждый узел
сохраняет результат как функцию данных,
полученных от его соседей, и передает
его другим узлам. Таким образом получается
избежать многочисленных пересылок
промежуточных данных в память и из неё
при вычислении целого ряда математических
алгоритмов, в частности, при перемножении
матриц и вычислении сверток в нейронных
сетях. Систолические массивы являются
основой современных ускорителей
нейронных сетей, например, Google TPU.
Рассмотрим пример систолического
массива, реализующего вычисления со
статичными весами "weight stationary".
Систолические массивы состоят из
однотипных элементов, называемых
"узлами".
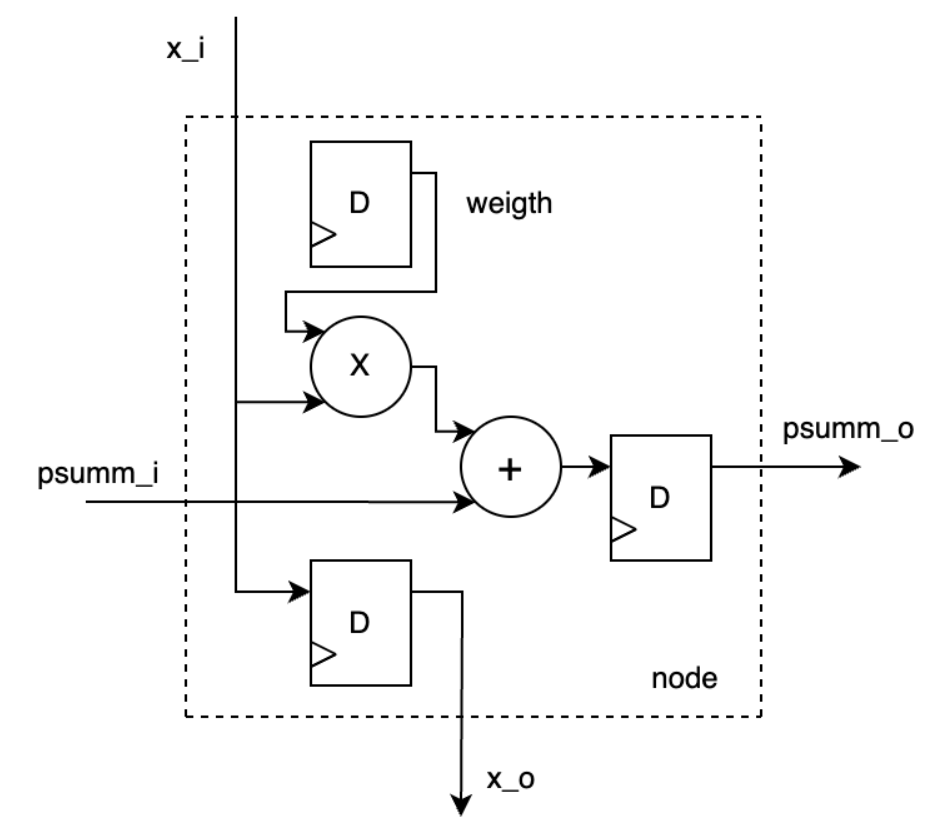
Что такое узел систолического массива? Как он работает?
Представленный узел выполняет следующие операции:
Хранит значение коэффициента-множителя weight.
Принимает на вход значение x_i от ячейки выше, сохраняет его в регистр, значение регистра выводит на выход x_o к ячейке ниже (вертикальное распространение данных).
Принимает частичную сумму от соседней слева ячейки, прибавляет к ней произведение x_i * weight, результат сохраняет в регистр, выводит содержимое регистра на выход summ_o к ячейке справа.
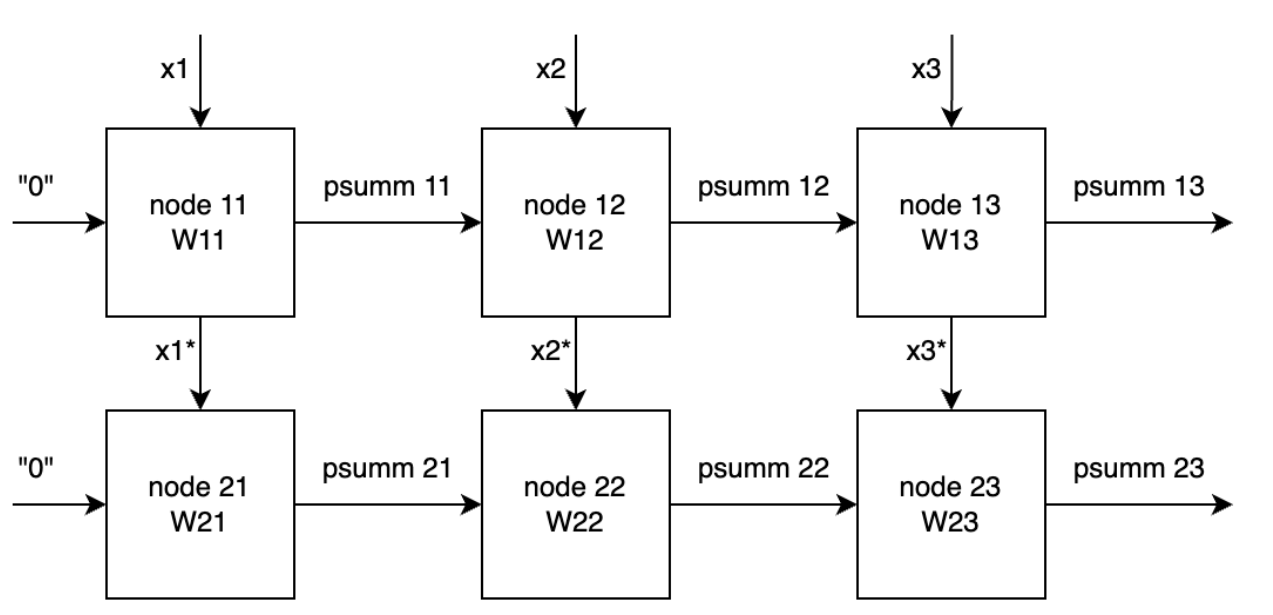
Как происходит распространение данных и результатов вычислений в систолическом массиве?
Входные данные распространяются сверху-вниз через линии x1, x2, x3. Частичные суммы (промежуточные результаты вычислений) распространяются слева-направо. В левом столбце на входы частичных сумм подаются нулевые значения. Результаты вычисления появляются на выходах psumm13 и psumm23 по мере продвижения данных по систолическому массиву. Обратите внимание на то, что вычисления в массиве выполняются как-бы диагональными волнами, которые распространяются направо-вниз. Это характерная особенность работы систолических массивов со статичными весами.
APB
Дайте определение системной шины. Назначение системной шины.
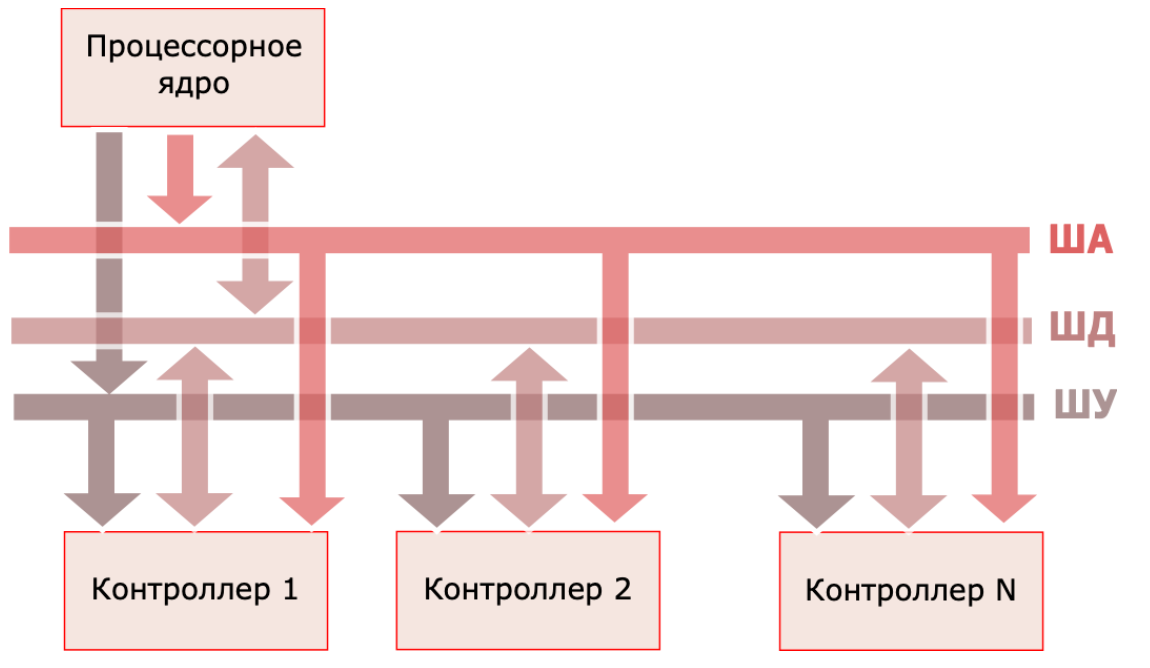
Системная шина (system bus) - совокупность сигнальных линий, служащих для обмена информацией между элементами системы на кристалле или на печатной плате. Сигналы системной шины в зависимости от назначения можно разделить на три группы. Линии системной шины, отвечающие за передачу данных, называется шиной данных. Линии, передающие адрес, называются шиной адреса, а прочие управляющие сигналы - шиной управления. Как было замечено ранее, основной функцией системной шины является обмен информацией. В простейшем случае происходит обмен информацией между одним процессорным ядром и множеством контроллеров.
Обобщённая
структурная схема подключения процессора
и контроллеров к системной шине показана
на рисунке.
Классификация системных шин.
Используемые в настоящее время шины отличаются по:
Разрядности (8, 16, 32, 64 бит). Чем больше разрядность шины, тем больше информации может быть передано за один цикл чтения или записи по каналу. Разрядность шины адреса можно определять независимо от разрядности шины данных. Разрядность шины адреса показывает, сколько ячеек памяти можно адресовать при передаче данных.
Способу передачи сигнала (последовательные или параллельные)
Пропускной способности. Ширина полосы пропускания называется также пропускной способностью и показывает общий объем данных, который можно передать по шине за данную единицу времени.
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени).
Далее рассмотрим существующие стандарты системных шин.
Advanced Microcontroller Bus Architecture (AMBA) - это открытый стандарт требований к внутрикристальным межсоединениям для соединения и управления функциональными блоками в системах на кристалле. Она облегчает развитие многопроцессорных разработок с большим числом контроллеров и периферии. Несмотря на название, с самого своего начала, AMBA имела виды, уходящие далеко за границы микроконтроллерных устройств. Сегодня AMBA широко применяется в ряде частей ASIC и SoC, включая прикладные процессоры, применяемые в современных небольших переносных устройствах вроде смартфонов. Еще одним из популярных на текущий день стандартов является Wishbone. Шина Wishbone - параллельная шина для объединения модулей в системе на кристалле. Шина описана в открытой спецификации, и широко используется в проектах цифровых систем с открытым исходным кодом на сайте OpenCores.org. Стандарт допускает присутствие нескольких ведущих устройств в системе, а также различные топологии соединения модулей.
Общие характеристики:
ширина шин адреса и данных: 8, 16, 32, 64 бит;
тип шины: параллельная;
внутренняя шина, используется только для соединения модулей на кристалле.
Каким образом различаются контроллеры в адресном пространстве? Что такое базовый адрес контроллера? Что такое карта памяти (memory map)?
При подключении различных периферийных устройств к системной шине возникает вопрос, каким образом различать эти контроллеры между собой? Решением данной проблемы является присвоение индивидуального диапазона адресов каждому из контроллеров. Таким образом, взаимодействие процессора с конкретным контроллером происходит посредством обращения по адресам заданного диапазона. Весь доступный диапазон адресов называется адресным пространством (Memory Map) системы на кристалле, а диапазон адресов, выделенный для отдельно взятого контроллера, - адресным пространством контроллера. Базовым адресом контроллера называется адрес начала выделенного диапазона. Структурная схема адресного пространства системы на кристалле приведена на рисунке.
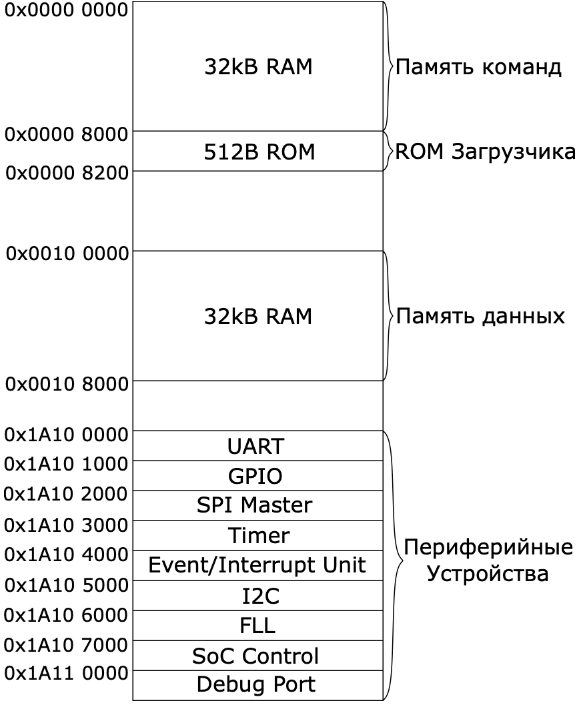 Адресное
пространство, выделенное под каждое
периферийное устройство, определяется
его стартовым (базовым) адресом и размером
адресного пространства. Для обмена
данными в периферийном устройстве
(контроллере или вычислительном блоке)
существует набор регистров, каждый из
которых имеет уникальный адрес. Регистры
адресуются относительно стартового
адреса. Абсолютный адрес регистра в
адресном пространстве системы на
кристалле определяется как сумма
базового адреса периферийного устройства
и смещения (относительного адреса).
Адресное
пространство, выделенное под каждое
периферийное устройство, определяется
его стартовым (базовым) адресом и размером
адресного пространства. Для обмена
данными в периферийном устройстве
(контроллере или вычислительном блоке)
существует набор регистров, каждый из
которых имеет уникальный адрес. Регистры
адресуются относительно стартового
адреса. Абсолютный адрес регистра в
адресном пространстве системы на
кристалле определяется как сумма
базового адреса периферийного устройства
и смещения (относительного адреса).
Так как архитектура RISC-V является load-store архитектурой, то для обращения к ячейке адресного пространства используются инструкции load и store для загрузки данных в регистры процессора и записи данных из регистра в ячейку памяти соответственно.
Следует отметить, что в RISC-V используется побайтовая адресация. Так как шина данных является 32-разрядной, то при обращении по адресу ноль происходит считывание или запись первых четырех байт (0,1,2,3). Этот факт необходимо учитывать при проектировании вычислительных блоков и при назначении регистрам адресов.
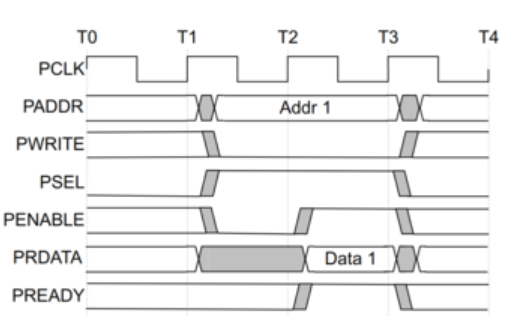
Системная шина APB. Каково назначение каждого из сигналов системной шины?
В
нашей системе на кристалле мы используем
системную шину APB
(Advanced Peripheral Bus).
Шина
APB - это часть семейства шин AMBA 3 фирмы
ARM. Она представляет собой универсальный
интерфейс для подключения периферийных
устройств. Декодер управляется ведущим
устройством, которое выставляет на
системную шину адрес одного из ведомых
устройств. По адресу декодер определяет,
какое из устройств выбрано для обмена
данными и формирует сигнал PSEL.
Декодер формирует сигнал Select для
мультиплексора, который указывает,
данные какого из ведомых устройств
должны быть выставлены на системную
шину. Передача
данных по шине APB состоит из двух фаз:
фазы адреса и фазы данных. Фаза адреса
всегда занимает один такт шины, а фаза
данных может содержать состояния
ожидания и длиться несколько тактов.

Системная шина APB. Изобразить цикл записи с задержкой.
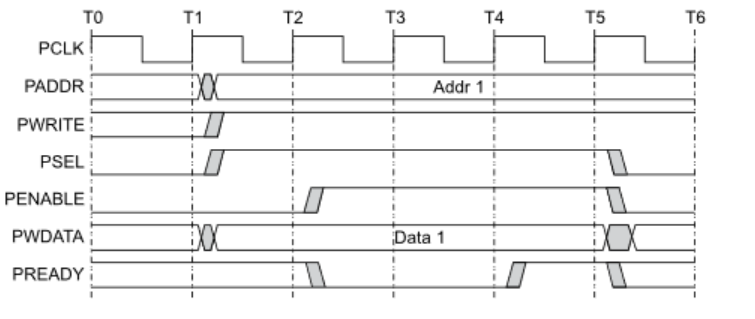
Системная шина APB. Изобразить цикл чтения без задержки.