


|
|
|
|
hang |
e |
|
|
|
|
|
|
|
|
|
|
hang |
e |
|
|
|
|
|
||
|
|
|
C |
|
E |
|
|
|
|
|
|
|
C |
|
E |
|
|
|
||||||
|
|
X |
|
|
|
|
|
|
|
|
|
X |
|
|
|
|
|
|
||||||
|
- |
|
|
|
|
|
d |
|
|
|
- |
|
|
|
|
|
d |
|
||||||
|
F |
|
|
|
|
|
|
|
t |
|
|
F |
|
|
|
|
|
|
|
t |
|
|||
|
D |
|
|
|
|
|
|
|
|
i |
|
|
D |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
r |
||||
P |
|
|
|
|
|
NOW! |
|
o |
P |
|
|
|
|
|
NOW! |
o |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
BUY |
|
|
|
Обработка инцидента 43to |
BUY |
|
|
||||||||||||
|
|
|
|
to |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
w Click |
|
|
|
|
|
|
|
|
m |
w Click |
|
|
|
|
|
|
|
m |
||||||
w |
|
|
|
|
|
|
|
|
|
|
|
w |
|
|
|
|
|
|
|
|
|
|
||
|
w |
|
|
|
|
|
|
|
|
|
o |
|
|
w |
|
|
|
|
|
|
|
|
o |
|
|
. |
|
|
|
|
g |
.c |
|
|
. |
|
|
|
|
g |
.c |
|
|||||||
|
|
p |
|
|
|
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
||||
|
|
|
df |
|
|
n |
e |
|
|
|
|
|
df |
|
|
n |
e |
|
||||||
|
|
|
|
-xcha |
|
|
|
|
Это возвращает нас к теме, которую мы обсуждали в предыдущей главе. |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-x cha |
|
|
|
|
|
|||||
Обнаружение становится одним из наиболее важных элементов управления безопасностью для компании. Датчики, расположенные по всей сети (локаль- ные и облачные), будут играть важную роль при выявлении подозрительной активности и создании оповещений. Растущая тенденция в области кибер безопасности заключается в использовании разведывательных данных и рас- ширенной аналитики для более быстрого обнаружения угроз и уменьшения количества ложных срабатываний. Это может сэкономить время и повысить общую точность.
Видеале система мониторинга должна быть интегрирована с датчиками, чтобы вы могли визуализировать все события на одной панели. Ситуация мо- жетбытьиной,есливыиспользуетеразныеплатформы,которыенепозволяют взаимодействовать друг с другом.
Всценарии, аналогичном тому, что мы рассматривали ранее, интеграция между системами обнаружения и мониторинга можетпомочьсвязатьвоедино множество вредоносных действий, которые были выполнены для достижения конечной цели – извлечения данных и передачи их командно-контрольному серверу.
Как только инцидент обнаружен и подтвержден как истинно положитель- ный, вам нужно либо собрать больше данных, либо проанализировать то, что
увас уже есть. Если существует постоянная проблема, когда атака происходит именно в этотмомент,вам необходимо быстро получитьоперативныеданные о ней и обеспечить способ ее остановить.
По этой причине обнаружение и анализ иногда выполняются почти парал- лельно,чтобы сэкономитьвремя,а затем это время используетсядля быстрого реагирования. При этом важно отметить, что существует отдельная фаза для сдерживания, удаления и восстановления. Об этом пойдет речь в следующем разделе данной главы.
Наибольшая проблема возникает, когда у вас недостаточно доказательств того,что произошел инцидентв области информационной безопасности и не- обходимо продолжать сбор данных, чтобы подтвердить достоверность. Иног да система обнаружения не видит инцидент. Возможно, о нем сообщает ко- нечный пользователь, но он не может воспроизвести проблему именно в этот момент времени. Нет материальных данных для анализа, и проблема не воз- никает в момент вашего прибытия. В подобных сценариях вам нужно будет настроить среду для сбора данных и дать пользователю указание обратиться в службу поддержки в тот момент, когда проблема проявляется.
Передовые методы оптимизации обработки компьютерных инцидентов
Нельзя определить, что является ненормальным, если вы не знаете, что нор- мально. Другими словами, если пользователь обнаруживает новый инцидент, утверждая, что производительность сервера низкая, вы должны знать все об-

|
|
|
|
hang |
e |
|
|
|
|
|
|
|
|
|
|
hang |
e |
|
|
|
|
|
||
|
|
|
C |
|
E |
|
|
|
|
|
|
|
C |
|
E |
|
|
|
||||||
|
|
X |
|
|
|
|
|
|
|
|
|
X |
|
|
|
|
|
|
||||||
|
- |
|
|
|
|
|
d |
|
|
|
- |
|
|
|
|
|
d |
|
||||||
|
F |
|
|
|
|
|
|
|
t |
|
|
|
F |
|
|
|
|
|
|
|
t |
|
||
|
D |
|
|
|
|
|
|
|
|
i |
|
|
|
D |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
|
r |
||||
P |
|
|
|
|
|
NOW! |
o |
|
P |
|
|
|
|
|
NOW! |
o |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
BUY |
|
|
|
|
|
|
|
|
BUY |
|
|
||||||||
|
|
|
|
to |
44 Процесс реагирования на компьютерные инциденты |
|
|
|
|
to |
|
|
|
|
|
|
||||||||
w Click |
|
w Click |
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
m |
||||||||
w |
|
|
|
|
|
|
|
|
|
|
|
w |
|
|
|
|
|
|
|
|
|
|
||
|
w |
|
|
|
|
|
|
|
|
o |
|
|
|
w |
|
|
|
|
|
|
|
|
o |
|
|
. |
|
|
|
|
g |
.c |
|
|
|
. |
|
|
|
|
g |
.c |
|
||||||
|
|
p |
|
|
|
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
||||
|
|
|
df |
|
|
n |
e |
|
|
|
|
|
df |
|
|
n |
e |
|
||||||
|
|
|
|
|
|
стоятельства,прежде чем делать поспешный вывод.Чтобы знать,медленно ли |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
-xcha |
|
|
|
|
|
|
|
|
|
|
-x cha |
|
|
|
|
|
||||
|
|
|
|
|
|
работает сервер, для начала нужно выяснить, какая скорость считается нор- |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
мальной.Этотакже относится к сетям,приборам идругим устройствам.Чтобы |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
нейтрализовать подобные сценарии, убедитесь, что у вас есть: |
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
системный профиль; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
сетевой профиль / базовый уровень; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
политика хранения логов; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
синхронизация часов во всех системах. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Исходя из этого, вы сможете установить, что является нормальным во всех |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
системах и сетях. Это будет очень полезно, когда происходит инцидент. Вам |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
необходимоопределить,чтоявляетсянормой,преждечемприступитькустра- |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
нению проблемы с точки зрения безопасности. |
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Деятельность после инцидента
Приоритет инцидента может диктовать стратегию сдерживания. Например, если вы имеете дело с DDoS-атакой, которая была выявлена как инцидент
свысоким приоритетом, стратегия сдерживания должна рассматриваться
стем же уровнем критичности. Редко бывает, когда ситуациям, при которых инциденту, классифицированному как очень серьезный, предписывают меры сдерживания со средним приоритетом,если проблема не была каким-либо об- разом решена между фазами.
Реальный сценарий
В качестве реального примера возьмем эпидемию, вызванную WannaCry, ис- пользуя вымышленную компанию «Diogenes & Ozkaya Inc.», чтобы продемон- стрировать сквозной процесс реагирования на компьютерные инциденты.
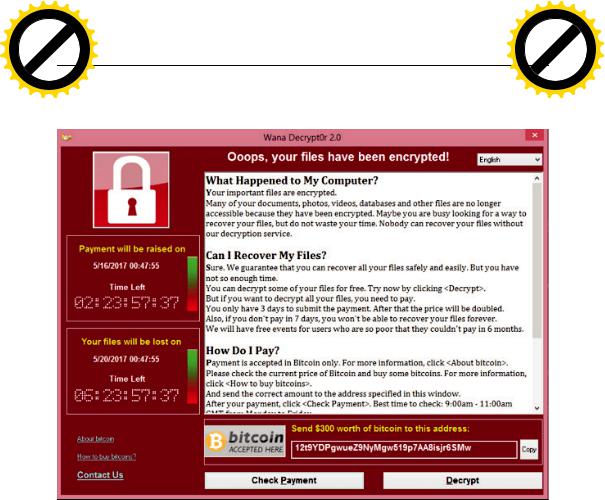
12 мая 2017 г. некоторые пользователи позвонили в службу поддержки, со- общив, что видят у себя на экране это – рис. 2.5.
После первоначальной оценки и подтверждения проблемы (этап обнаруже- ния) была задействована команда безопасности и создан инцидент.Поскольку многие системы сталкивались с одной и той же проблемой, степень серьез- ности этого инцидента повысили до высокой. Они использовали свой анализ угроз, чтобы быстро идентифицировать, что это было заражение, вызванное программой-вымогателем. Для того чтобы предотвратить заражение других систем, им пришлось применить патч MS17-00 (3).
На этом этапе группа реагирования работала по трем различным направ- лениям: одни пытались сломать шифрование программы-вымогателя,другие стремились выявить иные системы, которые были уязвимы для этого типа атак, а третьи работали, чтобы сообщить о проблеме прессе.
Они проконсультировались со своей системой управления уязвимостями и определили множестводругих систем,в которых отсутствовало это обновле- ние, запустили процесс управления изменениями и повысили приоритет это-
|
|
|
|
hang |
e |
|
|
|
|
|
|
|
|
|
hang |
e |
|
|
|
|
|
||
|
|
|
C |
|
E |
|
|
|
|
|
|
C |
|
E |
|
|
|
||||||
|
|
X |
|
|
|
|
|
|
|
|
X |
|
|
|
|
|
|
||||||
|
- |
|
|
|
|
|
d |
|
|
- |
|
|
|
|
|
d |
|
||||||
|
F |
|
|
|
|
|
|
|
t |
|
|
F |
|
|
|
|
|
|
|
t |
|
||
|
D |
|
|
|
|
|
|
|
|
i |
|
|
D |
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
r |
||||
P |
|
|
|
|
|
NOW! |
o |
P |
|
|
|
|
|
NOW! |
o |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
BUY |
|
|
Деятельность после инцидента 45to |
BUY |
|
|
||||||||||||
|
|
|
|
to |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
w Click |
|
|
|
|
|
|
|
m |
w Click |
|
|
|
|
|
|
|
m |
||||||
w |
|
|
|
|
|
|
|
|
|
|
w |
|
|
|
|
|
|
|
|
|
|
||
|
w |
|
|
|
|
|
|
|
|
o |
|
|
w |
|
|
|
|
|
|
|
|
o |
|
|
. |
|
|
|
|
g |
.c |
|
|
. |
|
|
|
|
g |
.c |
|
||||||
|
|
p |
|
|
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
||||
|
|
|
df |
|
|
n |
e |
|
|
|
|
df |
|
|
n |
e |
|
||||||
|
|
|
|
|
|
го изменения до критического. Команда системы управления развернула этот |
|
|
|
|
|
|
|
||||||||||
|
|
|
|
-xcha |
|
|
|
|
|
|
|
|
|
-x cha |
|
|
|
|
|
||||
патч на остальных системах.
Рис.2.5
Команда реагирования работала со своим поставщиком антивирусного ПО, чтобы сломатьшифрование и снова получитьдоступ кданным.Наданном моменте все остальные системы были исправлены и работали без проблем. На этом этап сдерживания, удаления и восстановления был завершен.
Выводы
Благодаря прочтению данного сценария вы узнали примеры из многих областей,которые были рассмотрены в этой главе и объединены воедино во время инцидента. Но инцидент не завершается тогда, когда проблема уже решена. На самом деле это только начало совершенно другого уровня работы, которую необходимо выполнить для каждого отдельного инцидента, – документации выводов.
Одна из наиболее ценных частей информации, которой вы располагаете на этапе после инцидента,–это выводы.Они помогутвам продолжатьсовершен-

|
|
|
|
hang |
e |
|
|
|
|
|
|
|
|
|
|
|
hang |
e |
|
|
|
|
|
||
|
|
|
C |
|
E |
|
|
|
|
|
|
|
|
C |
|
E |
|
|
|
||||||
|
|
X |
|
|
|
|
|
|
|
|
|
X |
|
|
|
|
|
|
|||||||
|
- |
|
|
|
|
|
d |
|
|
|
- |
|
|
|
|
|
|
d |
|
||||||
|
F |
|
|
|
|
|
|
|
t |
|
|
|
F |
|
|
|
|
|
|
|
|
t |
|
||
|
D |
|
|
|
|
|
|
|
|
i |
|
|
|
D |
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
|
|
r |
||||
P |
|
|
|
|
|
NOW! |
o |
|
P |
|
|
|
|
|
|
NOW! |
o |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
BUY |
|
|
|
|
|
|
|
|
|
BUY |
|
|
||||||||
|
|
|
|
to |
46 Процесс реагирования на компьютерные инциденты |
|
|
|
|
|
to |
|
|
|
|
|
|
||||||||
w Click |
|
w Click |
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
m |
|||||||||
w |
|
|
|
|
|
|
|
|
|
|
|
w |
|
|
|
|
|
|
|
|
|
|
|
||
|
w |
|
|
|
|
|
|
|
|
o |
|
|
|
w |
|
|
|
|
|
|
|
|
|
o |
|
|
. |
|
|
|
|
g |
.c |
|
|
|
. |
|
|
|
|
|
g |
.c |
|
||||||
|
|
p |
|
|
|
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
|
||||
|
|
|
df |
|
|
n |
e |
|
|
|
|
|
df |
|
|
n |
e |
|
|||||||
|
|
|
|
|
|
ствовать процесс путем выявления пробелов и определения областей улучше- |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
-xcha |
|
|
|
|
|
|
|
|
|
|
|
-x cha |
|
|
|
|
|
||||
|
|
|
|
|
|
ния. Когда инцидент будет полностью закрыт, его следует задокументировать. |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
Этадокументациядолжна бытьоченьдетальной,с подробным описанием гра- |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
фика инцидента, шагов, которые были предприняты для решения проблемы, |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
того, что происходило на каждом этапе, и как проблема была окончательно |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
решена. |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
Подобнаядокументация будетиспользоваться в качестве основыдля ответа |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
на следующие вопросы: |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
кто выявил проблему безопасности: пользователь или система обнару- |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
жения; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
был ли инцидент открыт с правильным приоритетом; |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
правильно ли выполнила начальную оценку команда по безопасности; |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
есть ли что-либо, что можно улучшить на этом этапе; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
правильно ли был выполнен анализ данных; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
правильно ли было проведено сдерживание; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
есть ли что-либо, что можно улучшить на этом этапе; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
сколько времени понадобилось, чтобы разрешить этот инцидент. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ответы на эти вопросы помогут уточнить процесс реагирования на инци- |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
денты, а также обогатить базу данных инцидентов. В системе управления ин- |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
цидентами они вседолжны бытьполностьюдокументированы идоступныдля |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
поиска.Цельсостоитвтом,чтобысоздатьбазузнаний,котораяможетбытьис- |
|
|
|
|
|
|
|
||||||||||||
пользована при работе с будущими инцидентами.Часто инцидентможетбыть разрешен с использованием тех же шагов, которые были применены ранее.
Еще один важный момент,о котором необходимо рассказать,–это сохране- ние улик. Все артефакты, которые были собраны во время инцидента,должны храниться в соответствии с политикой хранения компании, если только нет конкретных указаний. Имейте в виду, что если злоумышленник должен быть привлечен к ответственности,улики следует сохранять до тех пор, пока судеб- ные иски не будут полностью урегулированы.
Реагирование на компьютерные инциденты в облаке
Когда мы говорим об облачных вычислениях, то ведем речь о разделении от- ветственности(4)междуоблачнымпровайдеромикомпанией,котораязаклю- чаетконтрактнаобслуживание.Уровеньответственностибудетварьироваться
взависимости от модели обслуживания, как показано на рис. 2.6.
Вслучае с моделью SaaS (англ. software as a service – программное обеспече- ниекакуслуга)большаячастьответственностилежитнаоблачномпровайдере. Действительно,ответственностьклиентазаключаетсявтом,чтобыобеспечить защитусвоейинфраструктурылокально(включаяконечнуюточку,котораяоб- ращается к облачному ресурсу). В случае с моделью IaaS (англ. Infrastructure as a service–инфраструктура как услуга) большая частьответственностилежитна
стороне клиента, включая уязвимости и управление исправлениями.

|
|
|
|
hang |
e |
|
|
|
|
|
|
|
|
C |
|
E |
|
|
|||
|
|
X |
|
|
|
|
|
|||
|
- |
|
|
|
|
|
d |
|
||
|
F |
|
|
|
|
|
|
t |
|
|
|
D |
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
r |
||
P |
|
|
|
|
|
NOW! |
o |
|||
|
|
|
|
|
|
|
||||
|
|
|
|
|
BUY |
|
|
|||
|
|
|
|
to |
|
|
|
|
|
|
w Click |
|
|
|
|
|
m |
||||
|
|
|
|
|
|
|||||
w |
|
|
|
|
|
|
|
|
|
|
|
w |
|
|
|
|
|
|
|
o |
|
|
. |
|
|
|
|
|
.c |
|
||
|
|
p |
|
|
|
|
g |
|
|
|
|
|
|
df |
|
|
n |
e |
|
||
|
|
|
|
-xcha |
|
|
|
|
||
|
|
|
|
|
hang |
e |
|
|
|
|
|
|
|
|
|
C |
|
E |
|
|
|||
|
|
|
X |
|
|
|
|
|
|||
|
|
- |
|
|
|
|
|
d |
|
||
|
|
F |
|
|
|
|
|
|
t |
|
|
|
|
D |
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
r |
||
|
P |
|
|
|
|
|
NOW! |
o |
|||
|
|
|
|
|
|
|
|
||||
Реагирование на компьютерные инциденты в облаке 47to |
BUY |
|
|
||||||||
|
|
|
|
|
|||||||
|
|
|
|
|
m |
||||||
|
w Click |
|
|
|
|
|
|
||||
|
w |
|
|
|
|
|
|
|
|
|
|
|
|
w |
|
|
|
|
|
|
|
o |
|
|
|
. |
|
|
|
|
|
.c |
|
||
|
|
|
p |
|
|
|
|
g |
|
|
|
|
|
|
|
df |
|
|
n |
e |
|
||
Облачный провайдер |
|
|
|
-x cha |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
||
Saas
Paas
Iaas
Клиент
Рис.2.6
Пониманиеобязанностейважнодляопределенияграницсбораданныхвце- лях реагирования на инциденты. В среде IaaS у вас есть полный контроль над виртуальной машиной и полный доступ ко всем журналам, предоставляемым операционной системой. Единственная недостающая информация в этой мо- дели–базовая сетевая инфраструктура и журналы гипервизора.Укаждого об- лачного провайдера (5) будетсвоя собственная политика сбораданных в целях реагирования на инциденты, поэтому обязательно ознакомьтесь с политикой облачного провайдера, прежде чем запрашивать какие-либо данные.
Для модели SaaS подавляющее большинство информации, относящейся к реагированию на инциденты, принадлежит облачному провайдеру. Если в службе SaaS обнаружены подозрительные действия, вам следует связаться напрямую с провайдером или сообщитьоб инциденте через портал (6).Обяза- тельно ознакомьтесь со своим соглашением об уровне предоставления услуги, чтобы лучше понять правила участия в сценарии реагирования на инцидент.
Обновление процесса реагирования,чтобы включить облако
В идеале у вас должен быть единый процесс реагирования на компьютерные инциденты, охватывающий оба основных сценария – локальный и облачный. Этоозначает,чтовамнеобходимообновитьтекущийпроцесс,чтобывключить всю соответствующую информацию, связанную с облаком.
Обязательнопросмотритевесьжизненныйциклреагирования,чтобывклю- чить аспекты, связанные с облачными вычислениями. Например, во время подготовки необходимо обновить список контактов, включив в него контакт- ную информацию поставщика облачных услуг, дежурный процесс и т. д. То же самое относится и к другим этапам,таким как:
обнаружение. В зависимости от используемой вами облачной модели можно включить решение облачного провайдера для обнаружения, что- бы помочь вам во время расследования (7);