

0721_Hairullina_Ekonometrika_ProdUroven_Praktik_2021
.pdf-выполнить корреляционный анализ, сделать вывод о тесноте и направлении связи между Y и X;
-вычислить коэффициент детерминации. Сделать вывод.
-выполнить дисперсионный анализ. Протестировать статистическую гипотезу о достоверности уравнения регрессии при уровнях значимости а=0,05;
-протестировать статистические гипотезы о достоверности коэффициента корреляции r и коэффициентов регрессии a0, а1 при уровне значимости а=0,05;
-построить доверительные интервалы для статистически значимых параметров;
-вычислить среднюю ошибку аппроксимации.
Задание 2.2.10
Исходные данные. Имеется официальная статистическая информация о среднемесячной номинальной начисленной заработной плате работников и об инвестициях в основной капитал, таблица 10.
|
|
Таблица 10 |
|
|
Данные для расчета |
|
|
|
|
|
|
Год |
Среднемесячная номинальная начисленная |
Инвестиции в основной |
|
|
заработная плата работников, тыс. руб. (У) |
капитал, трлн руб. (Х) |
|
2009 |
18,64 |
7,98 |
|
2010 |
20,95 |
9,15 |
|
2011 |
23,37 |
11,04 |
|
2012 |
26,63 |
12,59 |
|
2013 |
29,79 |
13,45 |
|
2014 |
32,50 |
13,90 |
|
2015 |
34,03 |
13,90 |
|
2016 |
36,71 |
14,75 |
|
2017 |
39,17 |
16,03 |
|
2018 |
43,72 |
17,78 |
|
Справочно. Многие экономические зависимости не являются линейными по своей сути, поэтому использование для их изучения линейных моделей может привести к неадекватным
21
результатам. Для преобразования нелинейной модели к линейному виду необходимо линеаризовать модель, обычно с помощью преобразований переменных нелинейную модель представляют в виде линейного соотношения между преобразованными переменными. Далее оценивают коэффициенты этого соотношения и затем с помощью обратного преобразования находят оценки параметров исходной нелинейной модели. Однако, в ряде случаев невозможно подобрать подходящее преобразование. В этом случае приходится использовать методы нелинейной оптимизации.
Выделяются следующие модели:
-нелинейные по переменным (но линейные относительно параметров);
-модели нелинейные по оцениваемым параметрам. Оценка параметров моделей, нелинейных по объясняю-
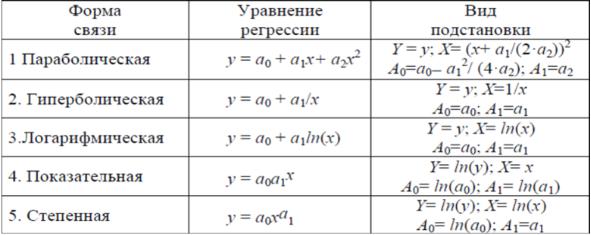
щим переменным, но линейных по оцениваемым параметрам, не представляет особой сложности: в этом случае обычно используют замену переменных для сведения модели к линейной и оценки параметров с помощью обычного МНК (примененного к модели с замененными переменными), рисунок 3.
Рисунок 3. Преобразование нелинейных зависимостей к линейному виду Y = а0 + a1X + ε.
22
Требуется:
-построить следующие уравнения регрессии с одной объясняющей переменной: линейное, гиперболическое, логарифмическое;
-дать экономическую интерпретацию коэффициентам регрессий;
-вычислить коэффициент детерминации. Сделать вывод;
-вычислить среднюю относительную ошибку аппроксимации;
-сделать вывод о возможности использования регрессионной модели для прогнозирования;
-выбрать наилучшую модель для прогнозирования, используя для ранжирования моделей два критерия: коэффициент детерминации и среднюю относительную ошибку аппроксимации.
Задание 2.2.11
Исходные данные. Имеется официальная статистическая информация о среднемесячной номинальной начисленной заработной плате работников и об инвестициях в основной капитал, таблица 10 (задание 2.2.10). На основе использования программы Gretl были построены четыре модели, результаты которых представлены в таблицах 11-18.
Таблица 11
Результат расчёта по модели 1 (основные показатели)
Переменная |
Коэффици- |
Ст. ошибка |
t-стати- |
P-значение |
Значи- |
|
ент |
|
стика |
|
мость |
const |
−4427,64 |
2466,42 |
−1,795 |
0,1104 |
|
INV |
2,67913 |
0,184581 |
14,51 |
<0,0001 |
*** |
Таблица 12
Результат расчёта по модели 1 (дополнительные показатели)
Показатель |
Значение |
Показатель |
Значение |
Среднее зав. перемен |
30550,52 |
Ст. откл. зав. перемен |
8186,473 |
Сумма кв. остатков |
22066141 |
Ст. ошибка модели |
1660,803 |
R-квадрат |
0,963416 |
Испр. R-квадрат |
0,958843 |
F(1, 8) |
210,6753 |
Р-значение (F) |
4,97e-07 |
Лог. правдоподобие |
−87,22423 |
Крит. Акаике |
178,4485 |
Крит. Шварца |
179,0536 |
Крит. Хеннана-Куинна |
177,7846 |
23
Таблица 13
Результат расчёта по модели 2 (основные показатели)
|
Коэффициент |
Ст. ошибка |
t-статистика |
P-значение |
|
const |
−269193 |
30813,9 |
−8,736 |
<0,0001 |
*** |
l_INV |
31716,1 |
3259,44 |
9,731 |
<0,0001 |
*** |
Таблица 14
Результат расчёта по модели 2 (дополнительные показатели)
Показатель |
Значение |
Показатель |
Значение |
Среднее зав. перемен |
30550,52 |
Ст. откл. зав. перемен |
8186,473 |
Сумма кв. остатков |
46992162 |
Ст. ошибка модели |
2423,638 |
R-квадрат |
0,922091 |
Испр. R-квадрат |
0,912352 |
F(1, 8) |
94,68351 |
Р-значение (F) |
0,000010 |
Лог. правдоподобие |
−91,00392 |
Крит. Акаике |
186,0078 |
Крит. Шварца |
186,6130 |
Крит. Хеннана-Куинна |
185,3440 |
Таблица 15
Результат расчёта по модели 3 (основные показатели)
|
Коэффициент |
Ст. ошибка |
t-статистика |
P-значение |
|
const |
−0,178530 |
0,735049 |
−0,2429 |
0,8142 |
|
l_INV |
1,10800 |
0,077752 |
14,25 |
<0,0001 |
*** |
Таблица 16
Результат расчёта по модели 3 (дополнительные показатели)
Показатель |
Значение |
|
Показатель |
|
|
Значение |
||||
Среднее зав. перемен |
10,29297 |
Ст. откл. зав. перемен |
|
0,279984 |
||||||
Сумма кв. остатков |
0,026740 |
Ст. ошибка модели |
|
|
0,057815 |
|||||
R-квадрат |
0,962099 |
Испр. R-квадрат |
|
|
0,957361 |
|||||
F(1, 8) |
|
|
203,0741 |
Р-значение (F) |
|
|
5,73e-07 |
|||
Лог. правдоподобие |
15,43148 |
Крит. Акаике |
|
|
−26,86296 |
|||||
Крит. Шварца |
−26,25779 |
Крит. Хеннана-Куинна |
|
−27,52683 |
||||||
|
|
|
|
|
|
|
|
Таблица 17 |
||
Результат расчёта по модели 4 (основные показатели) |
||||||||||
|
Коэффициент |
|
Ст. ошибка |
|
t-статистика |
|
P-значение |
|
||
const |
11731,0 |
|
1182,95 |
|
9,917 |
|
<0,0001 |
*** |
||
sq_INV |
0,000105402 |
|
6,13610e-06 |
|
17,18 |
|
<0,0001 |
*** |
||
|
|
|
|
|
|
|
|
Таблица 18 |
||
Результат расчёта по модели 4 (дополнительные показатели)
Показатель |
Значение |
Показатель |
Значение |
Среднее зав. перемен |
30550,52 |
Ст. откл. зав. перемен |
8186,473 |
Сумма кв. остатков |
15921916 |
Ст. ошибка модели |
1410,758 |
R-квадрат |
0,973603 |
Испр. R-квадрат |
0,970303 |
F(1, 8) |
295,0615 |
Р-значение (F) |
1,34e-07 |
Лог. правдоподобие |
−85,59250 |
Крит. Акаике |
175,1850 |
Крит. Шварца |
175,7902 |
Крит. Хеннана-Куинна |
174,5211 |
24

Требуется: заполнить таблицу 19 и сделать вывод о наиболее подходящей модели для практического применения.
Таблица 19
Основные характеристики моделей для анализа
Модель |
Уравнение |
R2 |
Скор R2 |
AIC |
BIC |
1 |
|
|
|
|
|
2 |
|
|
|
|
|
3 |
|
|
|
|
|
4 |
|
|
|
|
|
Задание 2.2.12
Исходные данные. Имеется официальная статистическая информация о среднемесячной номинальной начисленной заработной плате работников и об инвестициях в основной капитал (задание 10). На основе использования программы Gretl была построена вспомогательная регрессия и проведен тест Рамсея, таблицы 20-23.
Таблица 20
Результат теста Рамсея по модели 1
|
Коэффициент |
Ст. ошибка t-статистика |
P-значение |
||
|
|
|
|
|
|
const |
80656,3 |
35130,7 |
2,296 |
0,0614 |
* |
|
|
|
|
|
|
INV |
−13,5024 |
6,89999 |
−1,957 |
0,0981 |
* |
yhat^2 |
0,000195411 |
8,81472e-05 |
2,217 |
0,0685 |
* |
|
|
|
|
|
|
yhat^3 |
−2,00340e-09 |
9,62768e-010 |
−2,081 |
0,0826 |
* |
Тестовая статистика: F = 4,255639,
р-значение = P(F(2,6) > 4,25564) = 0,0707
Таблица 21
Результат теста Рамсея по модели 2
|
Коэффициент |
Ст. ошибка t-статистика |
P-значение |
|
|
|
|
|
|
const |
931746 |
776078 |
1,201 |
0,2752 |
|
|
|
|
|
l_INV |
−104490 |
88569,6 |
−1,180 |
0,2828 |
|
|
|
|
|
yhat^2 |
0,000121977 |
0,000100255 |
1,217 |
0,2694 |
yhat^3 |
−1,02912e-09 |
1,14909e-09 |
−0,8956 |
0,4050 |
Тестовая статистика: F = 9,307849,
р-значение = P(F(2,6) > 9,30785) = 0,0145
25

Таблица 22
Результат теста Рамсея по модели 3
Коэффициент |
Ст. ошибка |
t-статистика P-значение |
||||||
|
|
|
|
|
|
|||
const |
−1865,56 |
5699,32 |
−0,3273 |
0,7545 |
|
|||
|
|
|
|
|
||||
sq_INV |
−0,000496918 |
0,000274107 |
−1,813 |
0,1198 |
||||
|
|
|
|
|
|
|
||
yhat^2 |
0,000192814 |
8,51637e-05 |
2,264 |
|
0,0642 |
* |
||
|
|
|
|
|
|
|
||
yhat^3 |
−2,06509e-09 |
8,90719e-010 |
−2,318 |
|
0,0596 |
* |
||
Тестовая статистика: F = 3,005859,
р-значение = P(F(2,6) > 3,00586) = 0,125
Таблица 23
Результат теста Рамсея по модели 4
|
Коэффициент Ст. ошибка |
t-статистика P-значение |
||
|
|
|
|
|
const |
1406,15 |
1000,27 |
1,406 |
0,2094 |
|
|
|
|
|
l_INV |
−428,166 |
308,836 |
−1,386 |
0,2149 |
yhat^2 |
37,3919 |
27,2340 |
1,373 |
0,2189 |
|
|
|
|
|
yhat^3 |
−1,20209 |
0,886609 |
−1,356 |
0,2240 |
ВНИМАНИЕ: матрица данных близка к сингулярной!
Тестовая статистика: F = 3,471503,
р-значение = P(F(2,6) > 3,4715) = 0,0996
Требуется: сформулировать вывод о наиболее подходящей модели для практического применения и обосновать.
Задание 2.2.13
Исходные данные: имеется официальная статистическая информация о среднемесячной номинальной начисленной заработной плате работников и об инвестициях в основной капитал (задание 2.2.10). На основе использования программы Gretl была построена вспомогательная регрессия и проведен тест на гетероскедастичность (тест Вайта), таблицы 24-27.
Таблица 24 – Результат теста Вайта по модели 1
|
Коэффициент |
Ст. ошибка t-статистика |
P-значение |
|
|
|
|
|
|
const |
−8,91178e+06 |
1,15943e+07 |
−0,7686 |
0,4672 |
|
|
|
|
|
INV |
2102,25 |
1872,73 |
1,123 |
0,2986 |
|
|
|
|
|
sq_INV |
−0,0914486 |
0,0732902 |
−1,248 |
0,2522 |
Неисправленный R-квадрат = 0,258656
Тестовая статистика: TR^2 = 2,586559,
р-значение = P(Хи-квадрат(2) > 2,586559) = 0,274369
26

|
|
|
|
Таблица 25 |
|
Результат теста Вайта по модели 2 |
|
||
|
|
|
|
|
|
Коэффициент |
Ст. ошибка t-статистика |
P-значение |
|
|
|
|
|
|
const |
1,22481e+08 |
2,28404e+09 |
0,05362 |
0,9587 |
|
|
|
|
|
l_INV |
−2,15750e+07 |
4,87546e+08 |
−0,04425 |
0,9659 |
|
|
|
|
|
sq_l_INV |
963596 |
2,60039e+07 |
0,03706 |
0,9715 |
Неисправленный R-квадрат = 0,043333
Тестовая статистика: TR^2 = 0,433331,
р-значение = P(Хи-квадрат(2) > 0,433331) = 0,805199
|
|
|
|
Таблица 26 |
|
Результат теста Вайта по модели 3 |
|
||
|
|
|
|
|
|
Коэффициент |
Ст. ошибка t-статистика |
P-значение |
|
|
|
|
|
|
const |
−2,33593e+06 |
2,68850e+06 |
−0,8689 |
0,4137 |
|
|
|
|
|
sq_INV |
0,0428933 |
0,0308583 |
1,390 |
0,2071 |
|
|
|
|
|
sq_sq_INV −1,00373e-010 |
8,16523e-011 |
−1,229 |
0,2587 |
|
Неисправленный R-квадрат = 0,242887
Тестовая статистика: TR^2 = 2,428875,
р-значение = P(Хи-квадрат(2) > 2,428875) = 0,296877
Таблица 27
Результат теста Вайта по модели 4
|
Коэффициент |
Ст. ошибка |
t-статистика |
P-значение |
|
|
|
|
|
const |
−1,78836 |
1,27144 |
−1,407 |
0,2024 |
|
|
|
|
|
l_INV |
0,385205 |
0,271398 |
1,419 |
0,1988 |
sq_l_INV |
−0,0206938 |
0,0144754 |
−1,430 |
0,1959 |
Неисправленный R-квадрат = 0,276034
Тестовая статистика: TR^2 = 2,760337,
р-значение = P(Хи-квадрат(2) > 2,760337) = 0,251536
Требуется: сформулировать вывод о наличии гетероскедастичности моделей.
Задание 2.2.14
Исходные данные. Имеются следующие данные, представленные в таблице 28.
27
|
|
|
Таблица 28 |
|
Исходные данные |
|
|
|
|
|
|
Наблюдения |
|
У |
Х |
|
|
|
|
1 |
|
199,49 |
310,26 |
2 |
|
234,15 |
400,10 |
3 |
|
242,79 |
220,43 |
4 |
|
253,23 |
373,35 |
5 |
|
256,90 |
340,47 |
6 |
|
235,45 |
349,50 |
7 |
|
304,74 |
353,11 |
8 |
|
273,29 |
343,51 |
9 |
|
384,70 |
401,62 |
10 |
|
440,27 |
408,31 |
11 |
|
448,57 |
405,25 |
12 |
|
322,65 |
417,52 |
13 |
|
533,07 |
515,34 |
14 |
|
563,24 |
510,77 |
15 |
|
550,44 |
519,34 |
16 |
|
530,46 |
498,03 |
17 |
|
636,86 |
461,52 |
18 |
|
626,61 |
642,07 |
19 |
|
647,75 |
488,62 |
20 |
|
636,04 |
638,97 |
Требуется:
-проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Спирмена на уровне значимости 0,05 и 0,01;
-построить график зависимости остатков от фактора Х;
-проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Гольдфельда-Квандта на уровне значимости 0,05 и 0,01.
Задание 2.2.15
Исходные данные. Имеются данные о дисперсионном анализе выборки (всего наблюдений 20), представленном в таблице 29.
28
Таблица 29
Дисперсионный анализ по верхней выборке
Показатель |
|
df |
SS |
MS |
|
Верхняя выборка |
|
||
Регрессия |
|
2 |
1157,837 |
578,9187 |
Остаток |
|
4 |
357,5073 |
89,37682 |
Итого |
|
6 |
1515,345 |
|
|
Нижняя выборка |
|
||
Регрессия |
|
2 |
1884,397 |
942,1986 |
Остаток |
|
4 |
1824,397 |
456,0992 |
Итого |
|
6 |
3708,794 |
|
Имеются также данные по регрессионной статистике, таблица 30.
Таблица 30
Результаты регрессионной статистики по выборкам
Переменные |
Коэффициенты |
Стандартная ошибка |
t-статистика |
|
P-Значение |
Нижние 95% |
Верхние 95% |
|
Нижние 95,0% |
Верхние 95,0% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Верхняя выборка |
|
|
|
|
|||
Y-пе- |
-34,303 |
44,710 |
-0,767 |
0,486 |
-158,437 |
89,831 |
|
158,437 |
89,831 |
|
ресе- |
|
|
|
|
|
|
|
|
|
|
че- |
|
|
|
|
|
|
|
|
|
|
ние |
|
|
|
|
|
|
|
|
|
|
X1 |
0,641 |
0,202 |
3,177 |
0,034 |
0,081 |
1,202 |
|
0,081 |
1,202 |
|
X2 |
1132,054 |
340,824 |
3,322 |
0,029 |
185,775 |
2078,334 |
|
185,775 |
2078,334 |
|
|
|
|
Нижняя выборка |
|
|
|
|
|||
Y-пе- |
213,602 |
78,308 |
2,728 |
0,053 |
-3,817 |
431,021 |
|
-3,817 |
431,021 |
|
ресе- |
|
|
|
|
|
|
|
|
|
|
че- |
|
|
|
|
|
|
|
|
|
|
ние |
|
|
|
|
|
|
|
|
|
|
X1 |
0,577 |
0,296 |
1,952 |
0,123 |
-0,244 |
1,398 |
|
-0,244 |
1,398 |
|
X2 |
-1106,870 |
842,418 |
-1,314 |
0,259 |
-3445,800 |
1232,055 |
445,800 |
1232,055 |
||
Требуется:
1.Определить по каким уравнениям линейной регрессии осуществляется дисперсионный анализ.
2.Проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста ГольдфельдаКвандта на уровне значимости 0,05.
29
3. Модели множественной регрессии и корреляции
Цель практического занятия: получить навыки построе-
ния множественных уравнений регрессии и корреляции.
3.1.Изучаемые вопросы
1.Классический метод наименьших квадратов (МНК).
2.Основная характеристика качества модели, ее прогностической силы.
3.Коэффициент детерминации и расчетное или наблюдаемое значение F –статистики.
4.Экономическая интерпретация оценки множественной регрессии.
5.Значимость коэффициентов регрессии.
6.Проверка гипотез о значимости уравнения множественной регрессии и построение доверительных интервалов.
7.Коэффициент детерминации и F-критерий Фишера.
8.Полная коллинеарность и мультиколлинеарность факторов. Признаки мультиколлинеарности.
9.Фиктивные переменные.
10.Тесты на гетероскедастичность и тесты на спецификацию модели.
3.2.Практические задания
Задание 3.2.1
Исходные данные. Уравнение регрессии с одной объясняющей переменной уравнение вида:
Y = f (Х1, Х2, Х3…, Хm) + ε,
где Y – зависимая, объясняемая, результирующая, эндогенная переменная (показатель). Y-случайная (стохастичная) величина;
30