

Санкт-Петербургский государственный университет телекоммуникаций
им. проф. М.А. Бонч-Бруевича
факультет Информационных систем и технологий
Отчёт по лабораторной работе №3
Тема: «Алгоритмы поиска в тексте»
Предмет: Структуры и алгоритмы обработки данных в ИС и С
Выполнил: студент группы ИСТ-03
Брынский А.О.
Санкт-Петербург
2012
Цель работы: изучить основные алгоритмы поиска в тексте и научиться решать задачи поиска в тексте на основе алгоритмов прямого поиска; Кнута, Морриса и Пратта; Боуера и Мура.
При выполнении лабораторной работы для каждого задания требуется написать программу на языке С++, которая получает на данные с клавиатуры, выполняет их обработку в соответствии с требованиями задания и выводит результат на экран. Для обработки данных необходимо реализовать любой из алгоритмов поиска в тексте. Ограничениями на входные данные является максимальный размер строковых данных, допустимый диапазон значений используемых числовых типов в языке С++.
1. Постановка задачи
Постановка задачи состоит в следующем.
Пусть задан текст, состоящий из символов. Необходимо определить, входит ли некоторая заданная последовательность символов в текст. Если входит, то найти номер символа, начиная с которого заданная последовательность начинается в тексте.
Данная задача возникает при поиске информации в текстовых редакторах, при индексации страниц поисковыми роботами, при работе спам – фильтров и др. При больших объёмах информации актуальным является скорость поиска информации.
Поэтому важным критерием алгоритмов является минимизация количества операций для нахождения информации в тексте.
2. Математическая модель
Для математической постановки и решения задачи поиска в тексте используются следующие определения, понятия и обозначения:
Алфавит – конечное множество символов.
Строка (слово) – это последовательность символов из некоторого алфавита.
Длина строки– количество символов в строке.
Строки обозначаются символами алфавита. Например, X=x[1]x[2]...x[n] – строка длиной n, где x[i]– i -ый символ строки Х, принадлежащий алфавиту. Строка, не содержащая ни одного символа, называется пустой строкой.
Строка X называется подстрокой строки Y, если существуют такие строки Z1 и Z2, что Y=Z1XZ2. При этом Z1 и Z2 называют, соответственно, левым, а правым крыльями подстроки.
Подстрока X называется префиксом строки Y, если существует подстрока Z, что Y = XZ.
Подстрока X называется суффиксом строки Y, если существует подстрока Z, что Y = ZX.
Математическая постановка задачи состоит в следующем.
Пусть y[1],y[2],...,y[n] и x[1],x[2],...,x[m] – две строки идущих друг за другом символов некоторого алфавита.
Требуется определить, имеются ли в строке y[1],y[2],...,y[n] подстрока y[k],y[k+1],...,y[k+m] совпадающая со строкой x[1],x[2],...,x[m] и если такая подстрока есть, то найти минимальное значение номера k определяющего первое вхождения подстроки в строку.
3. Алгоритм решения задачи
3.1 В процедуре-функции main() вводятся посимвольно с клавиатуры исходные данные задачи строка string и подстрока substring. Затем поочередно вызываются подпрограммы DirectSearch, KMPSearch, BMSearch, соответственно реализующие:
- алгоритм прямого поиска; - алгоритм Кнута, Морриса и Пратта; - алгоритм Боуера и Мура.
После вызова каждой из подпрограмм выводятся на консоль результаты расчетов: номер элемента строки с которого начинается первое вхождение подстроки в строку; количество сдвигов, используемых в каждом алгоритме для нахождения подстроки. Блок схема процедуры-функции main() представлена на рисунке 1.

Ввод исходных данных задачи
(строки string и подстроки substring)

Вызов подпрограммы DirectSearch алгоритма прямого поиска и выод результатов расчета
Вызов подпрограммы KMPSearch алгоритма Кнута, Морриса, Пратта и выод результатов расчета


Вызов подпрограммы BMSearch Боуера, Мура и выод результатов расчета

Конец
Рис. 1 - Блок схема процедуры-функции main().
3.2 В процедуре-функции DirectSearch запрограммирован алгоритм прямого поиска подстроки в строке.
Алгоритм прямого поиска заключается в посимвольном сравнении строки с подстрокой. В начальный момент происходит сравнение первого символа строки с первым символом подстроки, второго символа строки со вторым символом подстроки и т. д. Если произошло совпадение всех символов, то фиксируется факт нахождения подстроки. В противном случае производится сдвиг подстроки на одну позицию вправо и повторяется посимвольное сравнение, то есть сравнивается второй символ строки с первым символом подстроки, третий символ строки со вторым символом подстроки и т. д. Сдвиги подстроки повторяются до тех пор, пока не произошло полное совпадение символов подстроки со строкой, либо не достигнут конец строки. На рисунке 2 показана демонстрация алгоритма прямого поиска. Символы, которые сравниваются, на рисунке выделены жирным.
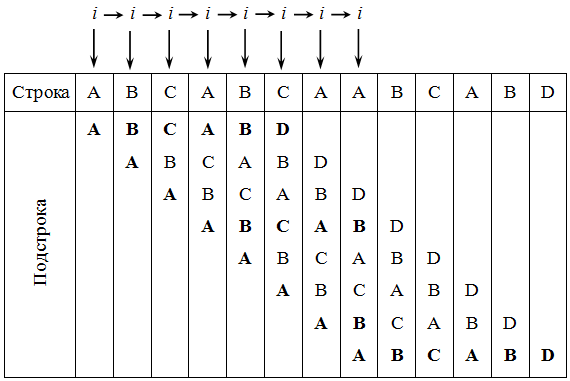
Рис. 2 - Демонстрация алгоритма прямого поиска
Процедура-функция DirectSearch алгоритма прямого поиска подстроки в строке возвращает номер найденного символа, начиная с которого подстрока входит в исходную строку. Функция DirectSearch имеет формат
int DirectSearch(char *string, char *substring, int &Sdvig1) ,
где string – заданная строка ; substring - заданная подстрока; Sdvig1 – количество сдвигов при поиске.
Блок схема процедуры-функции DirectSearch алгоритма прямого поиска подстроки в строке представлена на рисунке 3.

Вычисляются длина sl = strlen(string) строки string
длина ssl = strlen(substring) подстроки substring
Инициализация I = 0 j = 0

I =i+1





substring[j] ≠ string[i+j]
j == ssl


J=j+1
i=0
Sdvig++

нет
нет
res = I
return res;

i < sl - ssl + 1
res =- 1
return res;
да
да






нет
да
Конец
Рис. 3.Блок схема процедуры-функции DirectSearch алгоритма прямого поиска подстроки в строке
3.3 В процедуре-функции KMPSearch запрограммирован алгоритм Кнута, Морриса и Пратта поиска подстроки в строке.
Алгоритм Кнута, Морриса и Пратта основывается на том, что после сравнения и частичного совпадения начальной части подстроки с соответствующими символами строки фактически известна пройденная часть строки и можно быстро продвинуться по строке. Отличие алгоритма Кнута, Морриса и Пратта от алгоритма прямого поиска заключается в том, что сдвиг подстроки выполняется не на один символ на каждом шаге, а на большее количество символов. Перед каждым сдвигом определяется его величина. Для повышения эффективности алгоритма необходимо, чтобы сдвиг на каждом шаге был бы как можно большим.
Если для произвольной подстроки определить все ее начала, одновременно являющиеся ее концами, и выбрать из них самую длинную (не считая саму строку), то такую процедуру принято называть префикс-функцией. В реализации алгоритма Кнута, Морриса и Пратта используется предобработка искомой подстроки, которая заключается в создании префикс-функции на ее основе. Если префикс (он же суффикс) строки длиной i длиннее одного символа, то он одновременно и префикс подстроки длиной i-1. Таким образом, проверяем префикс предыдущей подстроки, если же тот не подходит, то префикс ее префикса, и т.д. Действуя так, находим наибольший искомый префикс. На рисунке 4 продемонстрирован алгоритм Кнута, Морриса и Пратта. Символы, подвергшиеся сравнению, выделены жирным шрифтом.
|
|

Рис. 4 - Демонстрация алгоритма Кнута, Морриса и Пратта
Процедура-функция KMPSearch алгоритма Кнута, Морриса и Пратта поиска подстроки в строке возвращает номер найденного символа, начиная с которого подстрока входит в исходную строку. Функция KMPSearch имеет формат
int KMPSearch(char *string, char *substring, int &Sdvig1) ,
где string – заданная строка ; substring - заданная подстрока; Sdvig1 – количество сдвигов при поиске.
Блок схема процедуры-функции KMPSearch алгоритма Кнута, Морриса и Пратта поиска подстроки в строке представлена на рисунке 5.
Начало

Вычисляются длина sl = strlen(string) строки string
длина ssl = strlen(substring) подстроки substring
Вычисление префикс-функции d[j]
Инициализация I = 0 j = 0


I =i+1





substring[j] ≠ string[i+j]
j == ssl


J=j+d[j]
i=0
Sdvig++

нет
нет
res = I
return res;

i < sl - ssl + 1
res =- 1
return res;
да
да






нет
да
Конец
Рис. 5.Блок схема процедуры-функции KMPSearch алгоритма Кнута, Морриса и Пратта поиска подстроки в строке
3.4 В процедуре-функции BMSearch запрограммирован алгоритм Бойера и Мура поиска подстроки в строке.
Алгоритм Бойера и Мура предусматривает предварительные вычисления над подстрокой, чтобы сравнение подстроки с исходной строкой осуществлять не во всех позициях. Первоначально строится таблица стоп-символов (BMT) (таблица смещений) для искомой подстроки. Далее идет совмещение начала строки и подстроки и начинается проверка с последнего символа подстроки. Если последний символ подстроки и соответствующий ему при наложении символ строки не совпадают, подстрока сдвигается относительно строки на величину, полученную из таблицы смещений, и снова проводится сравнение, начиная с последнего символа подстроки. Если же символы совпадают, производится сравнение предпоследнего символа подстроки и т.д. Если все символы подстроки совпали с наложенными символами строки, значит, найдена подстрока и поиск окончен. Если же какой-то (не последний) символ подстроки не совпадает с соответствующим символом строки, далее производим сдвиг подстроки на величину, определяемую таблицейсуффиксов. Таблица суффиксов определяет величину сдвигов в зависимости от количества совпавших символов. Вычисление таблицы суффиксов (BMS) производится для подстроки предварительно до начала поиска.
Весь алгоритм выполняется до тех пор, пока либо не будет найдено вхождение искомой подстроки, либо не будет достигнут конец строки.
Величина сдвига в случае несовпадения последнего символа вычисляется, исходя из следующего: сдвиг подстроки должен быть минимальным, таким, чтобы не пропустить вхождение подстроки в строке. Если данный символ строки встречается в подстроке, то смещаем подстроку таким образом, чтобы символ строки совпал с самым правым вхождением этого символа в подстроке. Если же подстрока вообще не содержит этого символа, то сдвигаем подстроку на величину, равную ее длине, так что первый символ подстроки накладывается на следующий за проверявшимся символом строки.
Величина смещения для каждого символа подстроки зависит только от порядка символов в подстроке, поэтому смещения удобно вычислить заранее и хранить в виде одномерного массива, где каждому символу алфавита соответствует смещение относительно последнего символа подстроки.
На рисунке 6 демонстрируется алгоритм Бойера и Мура.

Рис. 6 - Демонстрация алгоритма Бойера и Мура
Процедура-функция BMSearch алгоритма Бойера и Мура поиска подстроки в строке возвращает номер найденного символа, начиная с которого подстрока входит в исходную строку. Функция BMSearch имеет формат
Int BMSearch (char *string, char *substring, int &Sdvig1) ,
где string – заданная строка ; substring - заданная подстрока; Sdvig1 – количество сдвигов при поиске.
Блок схема процедуры-функции BMSearch алгоритма Бойера и Мура поиска подстроки в строке представлена на рисунке 7.
Начало

Вычисляются длина sl = strlen(string) строки string
длина ssl = strlen(substring) подстроки substring

Вычисление таблицы стоп-символов (BMT)

Вычисление префикс-функции р1[j] обратной строки и таблицы суффиксов (BMS)


Инициализация j = ss1-1Pos= 0
Po s = Po s +
+ max(BMS[j], BMT[string[Pos]]
Sdvig++
j=j+1




substring[j] ≠ string[i+j]
j = = 0l




нет
нет
Return
Pos-ssl+1

i < sl - ssl + 1
res =- 1
return res;
да
да




нет
да
Конец

Рис. 7.Блок схема процедуры-функции функции BMSearch алгоритма Бойера и Мура поиска подстроки в строке
3.5 Ожидаемыми результатами является то, что трудоемкость алгоритма Кнута, Морриса и Пратта будет лучше, чем трудоемкость алгоритма прямого поиска.
Алгоритм Бойера и Мура на хороших данных будет очень быстр, а вероятность появления плохих данных мала. Поэтому можно ожидать, что он будет оптимален в большинстве случаев, когда нет возможности провести предварительную обработку текста, в котором проводится поиск. Таким образом, данный алгоритм может быть наиболее эффективным.
Можно также ожидать, что каждый алгоритм поиска позволяет эффективно действовать лишь для своего класса задач. Алгоритм поиска подстроки в строке следует выбирать после точной постановки задачи, которую должна выполнять программа.