

книги / Теория вероятностей и математическая статистика. Прикладная статистика с использованием MS EXCEL
.pdf– выборочный эксцесс (оценка островершинности (E > 0) или плосковершинности (E < 0) статистического распределения
по отношению к нормальному распределению, для которого он равен 0):
μ
E = 4 4 −3; (2.15) (σx )
– выборочный квантиль xp порядка р – корень уравнения
F (x ) = p, |
(2.16) |
x p |
|
то есть абсцисса xp точки, лежащей на эмпирической функции распределения Fx (x) и имеющей ординату р; порядок р квантиля xp определяет долю общего числа наблюдений в выборке, результаты которых не превосходят xp .
Выборочную дисперсию аналогично соответствующей дисперсии в теории вероятности также можно представить в виде
D = μ |
= ν |
−(ν )2 . |
(2.17) |
|
x |
2 |
2 |
1 |
|
Еще раз подчеркнем, что главным отличием числовых характеристик случайных величин от аналогичных им выборочных характеристик, определенных формулами (2.3)–(2.16), состоит в том, что первые являются детерминированными (неслучайными) величинами, а вторые сами являются случайными величинами со своими специфическими законами распределения.
Добавление элементов к выборке или осуществление новой выборки из той же генеральной совокупности приводит к вычислению отличающихся друг от друга числовых характеристик выборок, к изменению эмпирической функции распределения, к изменению вида гистограмм.
Поэтому числовые характеристики эмпирического распределения являются оценками соответствующих числовых характеристик случайной величины.
51
Значение выборочных характеристик состоит в том, что согласно предельным теоремам при n → ∞ они в качестве оценок числовых характеристик изучаемой случайной величины стремятся к истинным значениям этих характеристик, определяемых функцией распределения F(х).
Оценки имеют разброс, поэтому принято различать точечные и интервальные оценки. Если оценка выражается одним числом (приближенным значением параметра), она называется точечной. Оценка, выражаемая двумя числами – концами интервала, накрывающего оцениваемый параметр, называ-
ется интервальной.
Точечных оценок для неизвестной числовой характеристики может быть несколько. Например, в качестве приближенного значения для математического ожидания может быть выбрано и среднее арифметическое, и среднее геометрическое статистического распределения, и медиана.
Получив статистические оценки числовых характеристик распределения изучаемой случайной величины Х (выборочное среднее, выборочную дисперсию и т.д.), нужно убедиться, что они в достаточной степени служат приближением соответствующих характеристик генеральной совокупности. Определим требования, которые должны при этом выполняться.
Наибольший интерес среди статистических оценок числовых характеристик представляют оценки неизвестных параметров теоретического распределения, которое выбирается в качестве возможной вероятностной модели полученного эмпирического распределения (например, по виду гистограммы относительных частот).
Пусть Θ – статистическая оценка неизвестного параметра Θ теоретического распределения. Извлечем из генеральной со-
вокупности |
несколько выборок одного и того же объема п |
|
ивычислим |
для каждой из них оценку параметра Θ: |
|
Θ* , Θ* |
, ...,Θ* |
.Тогда оценку Θ можно рассматривать как случай- |
1 2 |
k |
|
ную величину, принимающуювозможныезначения Θ1* ,Θ*2 , ...,Θ*k .
52
Если математическое ожидание Θ не равно оцениваемому параметру, мы будем получать при вычислении оценок систематические ошибки одного знака (с избытком, если M (Θ ) > Θ,
и с недостатком, если M (Θ ) < Θ). Следовательно, необходимым
условием отсутствия систематических ошибок является требование M (Θ ) = Θ.
Статистическая оценка Θ называется несмещенной, если ее математическое ожидание равно оцениваемому параметру Θ при любом объеме выборки:
M (Θ ) = Θ.
Смещенной называют оценку, математическое ожидание которой не равно оцениваемому параметру.
Однако несмещенность не является достаточным условием хорошего приближения к истинному значению оцениваемого параметра. Если при этом возможные значения Θ могут значительно отклоняться от среднего значения, то есть дисперсия Θ велика, то значение, найденное по данным одной выборки, может значительно отличаться от оцениваемого параметра. Следовательно, требуется наложить ограничения на дисперсию.
Статистическая оценка называется эффективной, если она при заданном объеме выборки п имеет наименьшую возможную дисперсию.
При рассмотрении выборок большого объема к статистическим оценкам предъявляется ещеитребование состоятельности.
Состоятельной называется статистическая оценка, которая при п→∞ стремится по вероятности к оцениваемому параметру (если эта оценка несмещенная, то она будет состоятельной, если при п → ∞ ее дисперсия стремится к 0).
Например, относительная частота p = nA / n появления
события А в n независимых испытаниях является несмещенной состоятельной и эффективной оценкой вероятности р = Р{А} этого события (р – вероятность наступления события А в каждом испытании).
53

Легко доказывается, что х представляет собой несмещенную состоятельную и эффективную оценку математического ожиданияM (X ) .
В отличие от выборочного среднего, выборочная дисперсия является смещенной оценкой дисперсии генеральной совокупности. Доказано, что
М(Dx* ) = n n−1 D (X ) ,
где D(X) – истинное значение дисперсии генеральной совокупности.
Поэтому часто используют другую, несмещенную, оцен-
ку дисперсии – исправленную дисперсию Dx* испр = s2 (2.7).
Состоятельность – обязательное свойство используемых оценок. Свойство несмещенности является желательным, но многие применяемые оценки этим свойством не обладают.
Результаты математической статистики по точечным оценкам для вероятности события в схеме Бернулли и наиболее распространенного нормального распределения приведены в табл. 2.7.
|
|
|
|
|
|
Таблица 2.7 |
||
Оцениваемый |
|
|
|
|
|
Условия, при |
||
|
Оценка |
|
Свойства оценки |
которых оценка |
||||
параметр |
|
|
обладает указан- |
|||||
|
|
|
|
|
|
ным свойством |
||
Вероятность |
|
|
|
|
Состоятельна, |
|
|
|
|
nA |
|
|
|
|
|
||
события р |
|
n |
|
|
не смещена, |
|
|
|
|
|
|
|
эффективна |
|
|
|
|
|
|
|
|
|
|
|
|
|
Математиче- |
|
|
|
|
Состоятельна, |
|
|
|
|
n |
|
|
|
|
|
||
ское ожида- |
|
1n ∑i=1 |
xi |
|
не смещена, |
X N (mx ,σ2 ) |
||
ние mx |
|
|
|
|
эффективна |
|
|
|
Дисперсия |
|
|
|
|
Состоятельна, |
|
|
|
1 |
n |
|
2 |
X N (m |
|
,σ2 ) |
||
2 |
∑(xi −mx ) |
|
не смещена, |
x |
||||
σх , mx |
n i=1 |
|
|
эффективна |
|
|
||
известно |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
54 |
|
|
|
|
|
|
|
|
Окончание табл. 2.7
Диспер- |
1 |
n |
2 |
|
Состоятельна, |
X N (mx ,σ |
2 |
|
2 |
∑(xi −mx ) |
|
|
смещена, |
|
) |
||
сияσх , |
n i=1 |
|
|
асимптотически |
n → ∞ |
|
|
|
mx не из- |
|
|
|
|
||||
|
|
|
|
эффективна |
|
|
|
|
вестно |
|
|
|
|
|
|
|
|
Диспер- |
|
|
|
|
Состоятельна, |
|
|
|
1 |
n |
|
2 |
X N (mx ,σ |
2 |
|
||
2 |
∑(xi −mx ) |
|
не смещена, |
|
) |
|||
сияσх , |
n −1 i=1 |
|
|
асимптотически |
n → ∞ |
|
|
|
mx не из- |
|
|
|
|
||||
|
|
|
|
эффективна |
|
|
|
|
вестно |
|
|
|
|
|
|
|
|
Указанные в этой таблице свойства оценок для других распределений необходимо заново исследовать.
2.2.1. Вычисление числовых характеристик выборки в MS Excel
Для вычисления точечных оценок основных числовых характеристик выборки Xn ={x1, x2 , x3 , ..., xn }, n ≤ 30, MS Excel
имеет следующие статистические функции (см. прил. 2):
– СРЗНАЧ (число1; число2; ...) – выборочное среднее, см. формулу (2.3);
– МЕДИАНА (число1; число2; . . . ) – медиана, см. (2.4);
– МОДА (число1; число2; . . . ) – мода;
–ДИСП (число1; число2; ...) – исправленная оценка дисперсии, см. (2.7);
–ДИСПР (число1; число2; ...) – смещенная оценка дисперсии, см. (2.5);
–СТАНДОТКЛОН (число1; число2; ... ) – исправленное среднеквадратичное отклонение, см. (2.8);
–СТАНДОТКЛОНП (число1; число2; ... ) – смещенное среднеквадратичное отклонение, см. (2.6);
–СКОС (число1; число2; ...) – коэффициент асиммет-
рии, см. (2.14);
–ЭКСЦЕСС (число1; число2; ...) – эксцесс, см. (2.15).
55

Пример 2.4. Найти оценки числовых характеристик случайной величины по выборке, заданной статистическим рядом
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi |
2 |
|
|
5 |
|
7 |
|
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ni |
3 |
|
|
8 |
|
7 |
|
2 |
|
k |
|
4 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
Решение. Число элементов выборки n = ∑nj = ∑nj = 20, |
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
j=1 |
|
j=1 |
||
по формулам (2.3), (2.17), (2.7), (2.6), (28) находим |
|
|||||||||||||||||||||||||||||
|
1 |
|
|
|
k |
|
|
|
|
|
|
1 |
4 |
|
|
|
2 |
3 +5 8 |
+7 7 +8 2 |
|
|
|
||||||||
х = |
|
|
∑nj xj |
= |
∑nj xj |
= |
= 5,55; |
|||||||||||||||||||||||
n |
20 |
|
|
|
|
|
20 |
|
|
|
||||||||||||||||||||
|
j=1 |
|
|
|
|
j=1 |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
1 |
|
k |
|
|
|
|
|
|
|
|
4 3 + 25 8 + 49 7 + 64 2 |
|
|
|
|
|||||||||||||
Dx = |
∑nj x2j |
− х |
2 = |
|
−5,552 |
= 3,3475; |
||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||
|
|
|
n |
j=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|||||
D |
|
|
|
= |
|
|
n |
|
D = |
|
20 |
3,3475 = 3,237; |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
n −1 |
19 |
|
|
|
|
|
|
|
||||||||||||||||||
x испр |
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
σ = |
|
D |
= |
|
3,3475 =1,83; |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
x |
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
s = |
3,5237 =1,88. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
Эти же оценки характеристик можно подсчитать в MS Excel, задав в ячейках А2:А21 значения 20 заданных вариант, в ячейках С2:С6 – текстовые названия характеристик, а D2:D6 – соответствующие статистические функции для их вычисления. Результат такоговычисления приведен в табл. 2.8.
|
Таблица 2.8 |
|
|
|
|
Статистика |
Функция Excel |
Значение |
|
|
|
Среднее |
СРЗНАЧ (А2:А21) |
5,55 |
Дисперсия |
ДИСПР (А2:А21) |
3,3475 |
Дисперсия исправленная |
ДИСП (А2:А21) |
3,5236 |
Среднеквадратичное от- |
|
|
клонение |
СТАНДОТКЛОНП (А2:А21) |
1,8296 |
Исправленное среднеквад- |
СТАНДОТКЛОН (А2:А21) |
1,8771 |
ратичное отклонение |
||
56 |
|
|
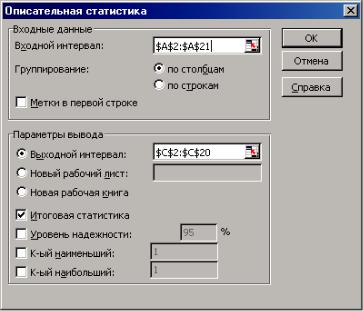
В MS Excel представление выборки с помощью числовых точечных оценок дает также инструмент «Описательная статистика», доступный из окна «Анализ данных». Для рассматриваемого примера входим в меню «Сервис» → «Анализ данных» → «Описательная статистика» (см. рис. 2.9), где в качестве входного интервала указываем нужные ячейки столбца А с вариантами выборки, указываем выходной интервал ячеек для результатов и заказываем «Итоговую статистику», результаты приведены в табл. 2.9.
Рис. 2.9. Задание данных в меню «Описательная статистика»
Пример 2.5. Для 5 выборок, полученных в примере 2.2, оценить числовые характеристики с помощью MS Excel.
Решение. Для таблицы, изображенной на рис. 2.2, задаемданные в меню «Описательная статистика» согласно рис. 2.9, получаемрезультатыввидеотредактированнойтаблицы2.10.
57

|
|
Таблица 2.9 |
|
|
|
|
|
Оценка числовой |
Значение |
Примечание |
|
характеристики |
|||
|
|
||
Среднее |
5,55 |
См. формулу (2.3) |
|
|
|
|
|
Стандартная ошибка |
0,41974 |
См. (2.11) |
|
Медиана |
5 |
См. (2.4) |
|
|
|
|
|
Мода |
5 |
|
|
Стандартное отклонение |
1,87715 |
См. (2.8) |
|
|
|
|
|
Дисперсия выборки |
3,52368 |
См. (2.7) |
|
Эксцесс |
–0,1635 |
См. (2.15) |
|
|
|
|
|
Асимметричность |
–0,7497 |
См. (2.14) |
|
|
|
|
|
Интервал |
6 |
См. (2.10) |
|
|
|
|
|
Минимум |
2 |
Минимальное значение |
|
xmin |
|||
|
|
||
Максимум |
8 |
Максимальное значение |
|
xmax |
|||
|
|
||
Сумма |
111 |
Сумма всех вариант |
|
|
|
|
|
Счет |
20 |
Объем выборки n |
Их анализ показывает, что мы действительно нашли только оценки заданных в примере 2.2 параметров нормального закона распределения: а = 2,1, σ = 0,1. Их выборочные зна-
чения среднего (2.0794, 2.0257, 2.1185, 2.1223, 2.1003) и стандартного отклонения (0.1195, 0.1145, 0.1237, 0.1206, 0.0978)
имеют разброс и эти оценки сами являются случайными величинами.
Таблица 2.10
Выборка |
X10(1) |
X10(2) |
X10(3) |
X10(4) |
X10(5) |
Среднее |
2,0794 |
2,0257 |
2,1185 |
2,1223 |
2,1003 |
Стандартная ошибка |
0,0378 |
0,0362 |
0,0391 |
0,0381 |
0,0309 |
Медиана |
2,0686 |
2,0292 |
2,1391 |
2,1024 |
2,0724 |
Стандартное отклонение |
0,1195 |
0,1145 |
0,1237 |
0,1206 |
0,0978 |
58 |
|
|
|
|
|

Окончание табл. 2.10
Дисперсия выборки |
0,0143 |
0,0131 |
0,0153 |
0,0145 |
0,0095 |
Эксцесс |
0,1593 |
3,3056 |
–0,2324 |
–0,1290 |
–0,0259 |
Асимметричность |
0,3876 |
1,4341 |
–0,2576 |
0,1844 |
0,9850 |
Интервал |
0,3851 |
0,4156 |
0,4041 |
0,4118 |
0,3006 |
Минимум |
1,8882 |
1,8816 |
1,9153 |
1,9257 |
1.9913 |
Максимум |
2,2733 |
2,2972 |
2,3194 |
2,3375 |
2,2918 |
Сумма |
20,794 |
20,258 |
21,185 |
21,223 |
21,003 |
Счет |
10 |
10 |
10 |
10 |
10 |
2.3. Точечная оценка неизвестных параметров распределения
Из статистических оценок числовых характеристик распределения случайной величины Х важную роль играет их частная разновидность– точечные оценки неизвестных параметров распределения F(x).
Предположим, что экспериментатору из каких-либо соображений или по виду гистограммы относительных частот известен класс функций распределения (нормальных, показательных, биномиальных и т.д.), к которому может принадлежать функция распределения вероятностей выборочно исследуемой случайной величины, а параметры, определяющие этот закон, неизвестны.
Требуется по результатам выборочного эксперимента оценить эти параметры, то есть найти их приближенные значения. Рассмотрим два наиболее распространенных метода построения приближенных значений параметров в виде точечных оценок (каждый параметр оценивается одним числом – точкой на оси его возможных значений): метод максимального правдоподобия и метод моментов.
2.3.1. Метод наибольшего правдоподобия
Пусть Х – дискретная случайная величина, которая в результате п испытаний приняла значения х1, х2, …, хп, среди которых могут быть одинаковые значения, тогда вероятность по-
59

явления каждого значения равна 1/n. Предположим, что нам известен закон распределения этой величины, определяемый параметром Θ, но неизвестно численное значение этого параметра. Найдем его точечную оценку.
Пусть р(хi, Θ) – вероятность того, что в результате испытания величина Х примет значение хi. Назовем функцией правдоподобия дискретной случайной величины Х функцию аргумента Θ, определяемую по формуле
L (х1, х2, …, хп; Θ) = p(x1,Θ)p(x2,Θ)…p(xn,Θ), |
(2.18) |
где p(xi,Θ) – вероятность реализации значения xi (i = 1, 2, …, n) согласно рассматриваемому закону распределения дискретной случайной величины.
Тогда в качестве точечной оценки параметра Θ принимают такое его значение Θ = Θ(х1, х2, …, хп), при котором функция правдоподобия достигает максимума. Оценку Θ называ-
ют оценкой наибольшего правдоподобия.
Поскольку функции L и ln(L) достигают максимума при одном и том же значении Θ, удобнее искать максимум ln(L) –
логарифмической функции правдоподобия. Для этого нужно:
1) найти производную dln (L) ; dΘ
2)приравнять ее нулю (получим так называемое уравнение правдоподобия) и найти корни этого уравнения;
3)выбрать решение, которое соответствует максимуму функции правдоподобия, для чего найти вторую производную
d2 ln (L) : если она отрицательна для рассматриваемого корня, d Θ2
то это – точка максимума.
Пример 2.6. Для выборки, содержащей n целочисленных положительных значений xi, найти оценку параметра а распределения Пуассона методом максимального правдоподобия.
60