

книги / Теория вероятностей и математическая статистика. Прикладная статистика с использованием MS EXCEL
.pdfПостроенную величину Х можно трактовать, например, как количество колес, ежедневно поступавших на шиноремонтный участок автопредприятия в течение 50 дней.
Этот пример демонстрирует, что имеющиеся здесь 3 элемента со значениями х > 13 являются естественными для данного распределения и их нельзя отбрасывать в ходе рецензирования выборки, хотя среднее выборочное значение за время наблюдения приближенно равно 4.
Гладкой сплошной линией на рис. 2.1 также показана теоретическая кривая f(x) плотности показательного распределения с параметром λ = 0,2337, аппроксимирующая (сглаживающая) построенную гистограмму.
По аналогии с функцией распределения F(x) случайная величина X для выборки Xn = {x1, x2 , x3 , ..., xn } можно задать
некоторую функцию, определяющую относительную частоту события X < x.
Выборочной (эмпирической) функцией распределения
называют функциюFn (x), определяющую для каждого значения х относительную частоту события X < x. Таким образом,
F (x) = |
nx |
, |
(2.2) |
|
|||
n |
n |
|
|
|
|
||
где пх – число вариант, меньших х; п – объем выборки.
В отличие от эмпирической функции распределенияFn (x), найденной опытным путем согласно (2.2), гипотети-
чески существующую функцию распределения F(x) гипотетической генеральной совокупности называют теоретической функцией распределения. F(x) определяет вероятность события X < x, а Fn (x) – его относительную частоту в выборке объема n. При достаточно больших п из теорем Бернулли и Гливенко следует, что Fn (x) стремится по вероятности к F(x).
41

Из определения эмпирической функции распределения видно, что ее свойства совпадают со свойствами F(x), а именно:
1.0 ≤ Fn (x) ≤ 1.
2.Fn (x) – неубывающая функция.
3.Если х1 – наименьшая варианта, то Fn (x) = 0 при х≤ х1;
если хk – наибольшая варианта, то Fn (x) = 1 при х > хk.
Эмпирическая функция распределения для непрерывной случайной величины графически изображается гистограммой накопленных частот – ступенчатой фигурой (рис. 2.2), состоящей из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высотами – отрезки длиной
i
nsi = ∑nj j=1
i
или wsi = ∑wj .
j=1
Рис. 2.2. Гистограмма накопленных частот – функция эмпирического распределения
42

В MS Excel для графического представления выборок в виде гистограмм используется инструмент «Гистограмма», доступный из окна «Анализ данных». Подробный пример использования этогоинструмента описан в нижеследующем примере.
2.1.1. Построение гистограмм вручную и в MS Excel
Рассмотрим практическое построение гистограмм. Пример 2.3. Представить выборку 55 наблюдений в виде
статистического ряда, используя 7 интервалов:
17 19 23 18 21 15 16 13 20 18 15 20 14 20 16 14 20 19 15 19
16 19 15 22 21 12 10 21 18 14 14 17 16 13 19 18 20 24 16 20
19 17 18 18 21 17 19 17 13 17 11 18 19 19 17
Построить гистограммы относительных и накопленных частот.
Решение. Размах выборки: R = 24 – 10 = 14. Длина разряда h = 14/7 = 2. Результаты группировки сведем в табл. 2.4:
Таблица 2.4
Номер разряда j |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
|
|
|
|
|
|
|
|
Границы разрядов |
10÷12 |
12÷14 |
14÷16 |
16÷18 |
18÷20 |
20÷22 |
22÷24 |
|
|
|
|
|
|
|
|
|
|
Частота nj |
2 |
4 |
8 |
12 |
16 |
10 |
3 |
|
|
|
|
|
|
|
|
|
|
Относительная |
0,0364 |
0,0727 |
0,1455 |
0,2182 |
0,2909 |
0,1818 |
0,0545 |
|
частота wj |
||||||||
|
|
|
|
|
|
|
||
Накопленная |
2 |
6 |
14 |
26 |
42 |
52 |
55 |
|
частота |
||||||||
|
|
|
|
|
|
|
||
Накопленная отно- |
0,0364 |
0,1091 |
0,2546 |
0,4728 |
0,7637 |
0,9455 |
1,000 |
|
сительная частота |
||||||||
F (x) |
0 |
0,0364 |
0,1091 |
0,2546 |
0,4728 |
0,7637 |
0,9455 |
F (x) = 1 при x > 24.
Проанализируем данные этого примера с помощью табличного процессора MS Excel, построим группированный статистический ряд и графики: введем все данные в столбец А
43
(см. прил. 1), затем отсортируем их в порядке возрастания («Данные» → «Сортировка», рис. 2.3).
|
В результате сразу получим |
|
вариационный ряд, по первому |
|
и последнему вариантам кото- |
|
рого определяем размах выбор- |
|
киR = 24 – 10 = 14 (рис. 2.4). |
|
После этого в столбец В |
|
таблицы с 1-й по 7-ю ячейки |
Рис. 2.3. Меню сортировки |
вводим в порядке возрастания |
|
координаты границ «карма- |
нов» = разрядов = частичных интервалов (их можно не задавать совсем и здесь и в диалоге построения гистограммы – процессор сам ихназначит), полученная таблица представлена нарис. 2.5.
Рис. 2.4. Полученный вариационный ряд
44
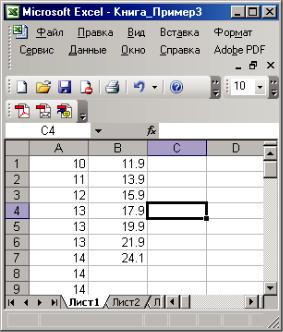
Рис. 2.5. Таблица с заданными «карманами»
Теперь все готово для построения гистограммы относительных частот и кумулятивной кривой (в Excel – интегрального процента). Входим в меню «Сервис» → «Анализ данных» → «Гистограмма» (рис. 2.6), где в качестве входного интервала указываем нужные ячейки столбца А, указываем нужный интервал «карманов» – ячейки столбца В.
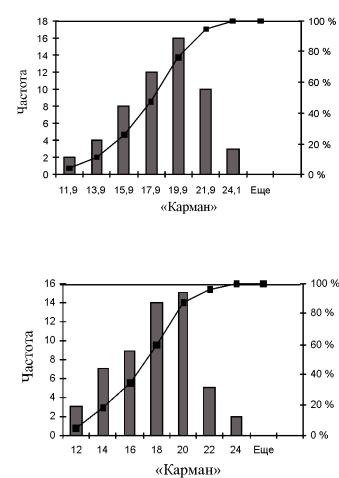
Получаем следующий группированный статистический ряд (табл. 2.5 с транспонированной матрицей относительно матрицы табл. 2.4) в ячейках таблицы F1:H9, совпадающий по частотам с приведенным выше рядом при ручном счете (см. левые три столбца табл. 2.5), гистограмму частот и кумулятивную кривую (накопленный процент) (рис. 2.7). Но для обеспечения этого совпадения пришлось сдвинуть границы «карманов» от целых значений (на практике рекомендуется
45

брать середины «карманов», отличающиеся только в последних значениях результаты для этого случая приведены в трех правых столбцах табл. 2.5).
Рис. 2.6. Диалог определения гистограммы
|
|
|
|
|
Таблица 2.5 |
|
|
|
|
|
|
«Кар- |
Часто- |
Интегральный |
«Кар- |
Часто- |
Интегральный |
ман» |
та |
% |
ман» |
та |
% |
11,9 |
2 |
3,64 % |
11 |
2 |
3,64 % |
13,9 |
4 |
10,91 % |
13 |
4 |
10,91 % |
15,9 |
8 |
25,45 % |
15 |
8 |
25,45 % |
17,9 |
12 |
47,27 % |
17 |
12 |
47,27 % |
19,9 |
16 |
76,36 % |
19 |
16 |
76,36 % |
21,9 |
10 |
94,55 % |
21 |
10 |
94,55 % |
24,1 |
3 |
100,00 % |
23 |
2 |
98,18 % |
Еще |
0 |
100,00 % |
Еще |
1 |
100,00 % |
46
Если же задать реальные границы карманов целыми числами, то получим существенно отличающийся статистический ряд (табл. 2.6) и соответственно отличающиеся графики гистограмм (рис. 2.8).
Рис. 2.7. Гистограмма частот и кумулятивная кривая:
 – частота;
– частота;  – интегральный процент
– интегральный процент
Рис. 2.8. Вариант гистограммы частот и кумулятивной кривой:  – частота;
– частота;  – интегральный процент
– интегральный процент
47
|
|
Таблица 2.6 |
|
|
|
«Карман» |
Частота |
Интегральный процент |
12 |
3 |
5,45 |
14 |
7 |
18,18 |
16 |
9 |
34,55 |
18 |
14 |
60,00 |
20 |
15 |
87,27 |
22 |
5 |
96,36 |
24 |
2 |
100,00 |
Еще |
0 |
100,00 |
Приведенный пример неоднозначности построения статистического ряда связан со следующими обстоятельствами:
1.Случайная переменная принимает целые значения, совпадающие с границами «карманов».
2.В отечественной литературе в основном используется определение функции распределения и эмпирической функции
распределения как вероятности события {X < x}, см. (2.2). Часто в иностранной литературе (и в Excel) используется неравенство {X ≤ x}. Поэтому по разному решается вопрос, включать или не включать попадание в «карман» значений, совпадающих с правой границей «кармана».
3.При построении статистического ряда вручную для последнего варианта и последнего «кармана» было нарушено условие X < x, фактически использовано X ≤ x, что свидетельствует о преимуществе использования этого события.
4.Для целочисленных границ «карманов» предпочтительнее в качестве таковых указывать координаты середин «карманов».
В практическом анализе статистических данных эти отличия редко проявляются так значительно. Кроме этого, нужно принимать во внимание, что мы имеем дело с приближенными случайными данными.
48
2.2. Числовые характеристики статистического (выборочного) распределения
Числовые характеристики случайных величин играют важную роль в их интерпретации, являясь детерминированными (неслучайными) величинами, характеризующими центр случайного рассеяния, показатели рассеяния, вид кривой плотности распределения и т.п.
Каждой числовой характеристике случайной величины можно поставить в соответствие ее статистическую аналогию (статистическую оценку), которая в силу случайности выборки сама являетсяслучайнойвеличинойсосвоимзакономраспределения.
Чаще всего в качестве таких статистических аналогий ис-
пользуются следующие выборочные числовые характери-
стики (статистики) – величины, вычисляемые по выборке (ниже даны формулы для негруппированных и группированных данных, для отличия выборочных характеристик от аналогичных теоретических числовых характеристик будем в основном использовать в качестве верхнего индекса символ
«*», делая исключение для оценки mx ≡ x):
– выборочное среднее (статистическое среднее – оценка математического ожидания):
|
1 |
n |
1 |
k |
k |
|
|
mx ≡ x = |
∑xi = |
∑nj xj = ∑wj xj ; |
(2.3) |
||||
|
|
||||||
|
n i=1 |
n j=1 |
j=1 |
|
|||
–мода статистического распределения– такое значение случайной величины, которому соответствуетнаибольшаячастотапоявления;
–медиана – такое значение xмед, для которого
P {X < x |
} = P {X > x }; |
(2.4) |
мед |
мед |
|
– выборочная дисперсия (смещенная оценка):
|
1 |
n |
|
1 |
k |
k |
|
Dx ≡ (σx )2 = |
∑(xi − x)2 |
= |
∑nj (xj − x)2 |
= ∑wj (xj − x)2 ; (2.5) |
|||
|
n |
||||||
|
n i=1 |
|
j=1 |
j=1 |
|||
49

– выборочное среднеквадратическое отклонение:
|
|
|
|
|
|
σ = |
D ; |
|
|
|
|
(2.6) |
|||
|
|
|
|
|
|
|
x |
|
x |
|
|
|
|
|
|
– исправленная выборочная дисперсия: |
|
|
|
||||||||||||
|
n |
|
|
|
|
|
1 |
n |
|
|
|
|
1 |
k |
|
Dx* испр = s2 = |
|
|
Dx* = |
∑(xi |
− x)2 = |
∑nj (xj − x )2 ; |
(2.7) |
||||||||
n −1 |
|
|
|
||||||||||||
|
|
|
|
n −1 i=1 |
|
|
|
|
n −1 j=1 |
|
|||||
– исправленное среднеквадратическое отклонение: |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
1 |
n |
|
|
|
|
|
s = |
Dx* испр = |
|
|
∑(xi − x)2 ; |
(2.8) |
||||||||
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
n −1 i=1 |
|
|
|
||
– выборочный коэффициент вариации – безразмерная относи-
тельная квадратичная оценки рассеяния:
ν = |
s |
; |
(2.9) |
|
x |
||||
|
|
|
– размах выборочный – простейшая размерная оценка рассеяния:
R = x |
− x ; |
(2.10) |
max |
min |
|
– выборочное среднеквадратическое отклонение среднего |
||
(стандартная ошибка среднего): |
|
|
σx = σx / n; |
(2.11) |
|
– выборочный начальный момент порядка k (k = 1, 2, 3, …):
|
|
1 |
n |
|
|
νk |
= |
∑xi k ; |
(2.12) |
||
|
|||||
|
|
n i=1 |
|
||
– выборочный центральный момент порядка k (k = 1, 2, 3, …):
|
|
1 |
n |
|
|
μk |
= |
∑(xi − x)k ; |
(2.13) |
||
|
|||||
|
|
n i=1 |
|
||
– выборочный коэффициент асимметрии (для симметричных распределений равен 0):
μ
As = (σ 3)3 ; (2.14)
x
50