

Практична частина
Виконаємо побудову, навчання і використання нейронної мережі автоматизованим способом за допомогою програми Statistica Neural Networks.
1. Переписати дані варіанту в текстовий файл. Як роздільник використовувати пробіл. В кінці файлу вставити пустий рядок. У першому рядку файлу набрати через пробіл назви вхідних і вихідної змінних. Зберегти файл з ім'ям Data.txt (Рис. 3).

Рис. 3. Текстовий файл з вихідними даними
2. Відкрити програму Statistica Neural Networks (SNN).
3. Виконати команду File->Close для закриття всіх непотрібних вікон.
4. Імпортуємо вихідні дані з текстового файлу в середу SNN.
Для цього треба виконати команду File->Open. У вікні вибору файлу (Рис. 4), яке відкрилося, виберіть файл Data.txt. Натисніть кнопку Open (Відкрити).

Рис. 4. Діалогове вікно відкриття файлу з даними

Рис. 5. Вікно помічника імпорту текстових файлів
У вікні помічника імпорту текстових файлів, що відкрилося, встановіть опції як показано на рис. 5, і натисніть кнопку Open.
SNN виконує імпорт даних у файл специфічного формату і видає попередження про необхідність його збереження в спеціальному вікні. Натисніть кнопку Да. Відкривається вікно редактора даних. У ньому ви бачите імпортовані дані.
5. Підготуємо вихідні дані до застосування. Відповідно до варіанту завдання розіб'ємо їх на тренувальний (чорний), перевірочний (червоний) і тестовий (синій) піднабори. Для цього в середньому полі області Cases встановимо значення рівним 3, потім в правому полі встановимо значення 1. При цьому шестірка зліва зміниться на трійку, а трійка в центрі заміниться двійкою. Визначимо тип змінних (Рис. 6). Для цього на заголовку стовпця змінної (сіра смужка) клацнути правою кнопкою миші і в контекстному меню вибрати тип Input (вхідні) для змінних INPUT1 і INPUT2 (чорні), і Output (вихідні) для змінної OUTPUT (синя). Виконаємо команду File->Save As і збережемо зміни.

Рис. 6. Вікно редактора даних
6. Виконаємо команду File->Network Set->New і створимо мережевий набір – контейнер, в якому зберігатимуться створювані мережі і мережі, модифіковані нами.
7. Побудуємо мережу з архітектурою [2:2-2-2-1:1], тобто з двома вхідними змінними (2:) і відповідними їм вхідними елементами, двома прихованими шарами по два нейрони в кожному і одним вихідним шаром з єдиним нейроном, що відповідає виходу мережі і однієї вихідної змінної (:1), пов'язаної з цим виходом. Виконайте команду File->New->Network. Проведіть настройки, як показано на рис. 7, і натисніть кнопку Create.
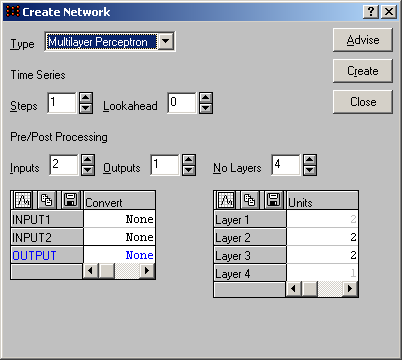
Рис. 7. Вікно помічника створення мережі
У вікні запиту на збереження мережі в мережевому наборі натисніть кнопку Нет (ми збережемо мережу пізніше). Відкрийте вікно редактора мережі командою Edit->Network і проведіть настройки як показано на рис. 8–11. Для переходу до потрібного шару набирайте його номер в полі Layer або користуйтеся стрілками праворуч від нього. Після закінчення настройки закрийте вікно.

Рис. 8. Настройки першого шару мережі і його елементів. Початкові значення вагів і порогів

Рис. 9. Настройки другого шару мережі (першого прихованого шару) і його елементів

Рис. 10. Настройки третього шару мережі (другого прихованого шару) і його елементів

Рис. 11. Настройки четвертого шару мережі і його елементів
Виконайте команду Edit->Pre/Post Processing і введіть додаткові настройки мережі у відміченій області так, як показано на рис. 12. Missing = Mean означає, що пусті значення в стовпцях набору даних будуть замінені на середні значення для цих стовпців (крім цього можна використовувати опції Median, Zero, Min, Max для заміни пустот медіаною по стовпцю, нулем, мінімальним або максимальним значенням стовпця відповідно).
У стовпці Convert вказується метод перетворення для відповідної змінної. Convert = None означає, що перетворення по відношенню до змінної не застосовується. У SNN реалізовані алгоритми мінімакса і середнього/стандартного відхилення, які автоматично знаходять параметри для перетворення числових значень в потрібний діапазон. Це корисно, якщо вихідні дані наперед не були масштабовані.
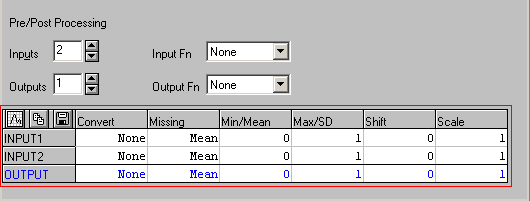
Рис. 12. Вікно редактора настройок пре/пост обробки входів і виходів мережі
Попередня обробка вхідних значень мережі проводиться таким чином. Для кожного елементу вхідного вектора виконується наступне: якщо його значення дорівнює NULL, то воно замінюється по методу, вказаному в стовпці Missing; далі застосовується метод перетворення, вказаний в стовпці Convert; множення на коефіцієнт вказаний в стовпці Scale і збільшення значення, вказаного в стовпці Shift. Далі, якщо в секції Input Fn не вказано значення None, виконується нормалізація всього вектора раніше перетворених значень, після чого набутого числового значення входів прямує в мережу. Попередня обробка на виході мережі проводиться аналогічним способом, тільки в зворотному порядку. При цьому спочатку використовується функція денормалізації, вказана в секції Output Fn, а потім проводиться решта дій по зворотному масштабуванню вихідних значень мережі. При рішенні задач регресії вихідне значення мережі має числовий тип.
Відкрийте вікно з ілюстрацією мережі (рис. 13) командою Statistics->Network Illustration.

Рис. 13. Ілюстрація мережі
Збережіть цю мережу в мережевому наборі. Для цього відкрийте вікно редактора мережевого набору (рис. 14) командою Edit->Network Set. У області Detail Shown виберіть опцію Verbose (докладна інформація). Додайте створену мережу в мережевий набір. Для цього натисніть кнопку Options і у вікні настройок мережевого набору, що відкрилося (рис. 15), натисніть кнопку Add. Виконайте команду File->Network Set->Save. Вікно на рисунку показує кількість мереж в наборі (Current), і дає можливість: встановити максимальну кількість мереж в наборі (Maximum) і автоматична дія при переповнюванні набору у момент додавання в нього нової мережі (у нашому випадку Keep Diverse); за допомогою кнопки Replace виконати заміну мережі з вказаним номером поточною мережею; за допомогою кнопки Best зробити мережу з найменшою величиною помилки поточною.
Закрийте вікно настройок. У списку мереж у вікні редактора мережевого набору з'являється рядок з інформацією про нашу мережу, яка стала поточною і позначається зірочкою «*». Надалі, після виконання будь-яких змін мережі, наприклад, після її тренування, реструктурування, ініціалізації і т.п., мережу необхідно наново зберегти в мережевому наборі, використовуючи можливості додавання (Add) або заміни (Replace) мереж, що надаються вікном настройок мережевого набору. Наприклад, після виконання даного прикладу ваш мережевий набір повинен містити мінімум дві мережі – вихідну (першу) і навчену (другу) як показано на рис. 14.

Рис. 14. Редактор мережевого набору
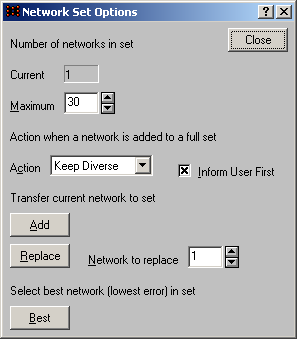
Рис. 15. Настройки редактора мережевого набору
Отже, ми побудували мережу і додали її в мережевий набір. Збережемо його командою File->Network Set->Save As в спеціальний файл з розширенням bnt (робіть так після кожної зміни в наборі).
8. Виконайте командою Train->Auxiliary->Set weights і настройку методу ініціалізації вагів і порогів поточної мережі так, як показано на рис. 16.

Рис. 16. Настройки методу ініціалізації вагів і порогів мережі
Значення All в полі Layers означає, що для всіх шарів встановлюється метод ініціалізації, вказаний в полі Method. Ми застосовуватимемо два методи: Gaussian – використовується генератор випадкових чисел з нормальним розподілом, для якого середнє Mean=0, а стандартне відхилення SD = 1 (скорочено позначатимемо як [Gaussian(0,1)]); Uniform – використовується генератор випадкових чисел з рівномірним розподілом, для якого нижня межа Min=0, а верхня межа Max=1 (скорочено позначатимемо як [Uniform(0,1)]). Натисніть на кнопку Set. Початкові значення вагів і порогів мережі будуть встановлені.
Виконайте команду Statistics->Weight Distribution і у вікні, що відкрилося (рис. 17), відобразіть гістограму розподілу частот значень вагів і порогів мережі натисненням кнопки Update (Обновити). Опція real-time update дозволяє спостерігати динаміку змін в процесі навчання мережі, у момент припинення або при закінченні якого графік відображає кінцевий стан вагів і порогів мережі.

Рис. 17. Гістограма розподілу частот значень вагів і порогів мережі
9. Значення вагових коефіцієнтів (а не їх частоти) можна побачити у вікні редактора мережі (рис. 18). Відкрийте його Командою Edit->Network і у області Connection Shown (відображувані зв'язки) виберіть опцію All layers (всі шари). У заголовках таблиці внизу вікна будуть відображені назви вхідних елементів (INPUT1 і INPUT2), вихідного елемента (OUTPUT) і нейронів прихованих шарів (h1#01, h1#02, відповідають першому і другому нейронам першого прихованого шару; h2#01, h2#02 – аналогічно для другого прихованого шару). Область даних таблиці містить ваги і пороги (Threshold). Стовпець відповідає нейрону прихованого шару або вихідному елементу і містить значення вагових коефіцієнтів для порогу і всіх зв'язків даного елементу з елементами попереднього шару. Рядок містить значення порогів для елементів мережі (окрім вхідних) і вагових коефіцієнтів зв'язків, витікаючих з елемента, якому відповідає рядок. Пуста клітинка на перетині рядка h1 і стовпця h1 означає, що перший нейрон першого прихованого шару не має рекурсивного зв'язку. Пуста клітинка на перетині рядка h1 і стовпця h1 (зв'язки, що відображаються) означає, що нейрони першого прихованого шару не зв'язані між собою. Порожня клітинка на перетині рядка h1 і стовпця OUTPUT означає, що нейрон h1 не зв'язаний з елементом вихідного шару. Ми також бачимо, що вхідні елементи не мають порогів, оскільки вони не являються нейронами, а служать для розподілу значень вхідного зразка між нейронами першого прихованого шару. Вихідний елемент на відміну від вхідних являється нейроном і має поріг. Крім того, він пов'язаний з нейронами h2 і h2 (зв'язки, що відображаються) зв'язками, вагові коефіцієнти яких рівні відповідно 3.012252 і 1.073128 відповідно. Нейрон h1 пов'язаний з вхідними елементами. Те ж відноситься і до нейрона h1 (зв'язки, що відображаються). Нейрони першого прихованого шару пов'язані з нейронами другого прихованого шару, а ті, у свою чергу, пов'язані з вихідним елементом.
Область даних таблиці допускає редагування, так що значення вагів і порогів можуть бути змінені, скопійовані або видалені вами, що дуже зручно при виконанні пункту 2 розрахункового завдання. При цьому ви можете спостерігати як вихідні (після ініціалізації), так і кінцеві (після навчання мережі) значення вагів і порогів.

Рис. 18. Початкові значення вагів і порогів мережі
Отже, ми провели ініціалізацію вагів і порогів мережі. Виконаємо декілька підготовчих дій і приступимо до її навчання.
10. Приберіть всі непотрібні вікна з екрану. Відкрийте командою Statistics->Training Graph вікно з графіком зміни тренувальної (сині) перевірочної (червоної) помилок, натисніть на кнопку Clear, щоб очистити біле полотно графіка і встановити малювання ліній з його початку (вагові коефіцієнти порогів і міжнейронних зв'язків мережі при цьому не змінюються). Встановіть значення Interval = 1 (Interval це частота малювання точок, вимірювана в епохах: наприклад Interval=2 означає, що точки малюються для кожної другої епохи).
11. Відкрийте командою Statistics->Case Errors вікно, в якому відображатиметься стовбчаста діаграма з помилками мережі на конкретних зразках (кожному зразку відповідає окремий стовпчик: його висота відповідатиме величині помилки, а його номер – порядковому номеру зразка в епосі навчання, що тільки-но закінчилася). Так відображаються всі зразки – тренувальні, перевірочні і тестові. Встановіть опцію Real-time update.
12. Відкрийте командою Statistics->Weight Distribution вікно, описане в пункті 8, і встановіть в ньому опцію Real-time update.
13. Визначте умови останову алгоритму навчання мережі. Для цього виконайте команду Train->Auxiliary->Stopping Conditions і проведіть настройки так, як показано на рис. 19.

Рис. 19. Умови останову алгоритму навчання
14. Встановіть параметри алгоритму навчання і проведіть навчання мережі. Для цього виконайте команду Train-> Multilayer Perceptrons->Back Propagation і проведіть настройки так, як показано на рис. 20.

Рис. 20. Настройки алгоритму зворотного поширення помилки
Опція Cross verification дозволяє виконувати крос-перевірку, якщо існує і використовується (не перебуває в стані Ignored) перевірочний піднабір зразків.
Опція Shuffle Cases дозволяє виконувати перемішування зразків тренувального і перевірочного (за наявності і використанні) наборів даних в процесі навчання перед початком кожної наступної епохи.
Призначення кнопок даного вікна наступне: Reinitialize – дозволяє ініціалізувати значення вагів і порогів мережі методом, установленим у вікні Set Weights і використовується перед навчанням мережі; Train – ініціює виконання алгоритму навчання; Stop – зупиняє процес навчання (для цього можна використовувати клавішу Escape); Jog Weights – додає до всіх вагів і порогів мережі випадкові малі значення і використовується для виведення алгоритму з локальних мінімумів (її можна натискати кілька разів підряд); Close – закриває вікно (в процесі роботи алгоритму недоступна).
Отже, встановіть параметри алгоритму, натисніть кнопку Reinitialize (якщо не натискали раніше кнопку Set у вікні Set Weights), ініціюйте виконання алгоритму навчання натисненням кнопки Train.
Поле Epochs містить кількість епох навчання. Після їх закінчення робота алгоритму припиняється. Якщо інші умови останову не виконалися, то навчання можна продовжити. Для цього не натискайте кнопку Reinitialize (вона призведе до скидання вагів і порогів мережі в нові випадкові значення), а вкажіть додаткову кількість епох в полі Epochs і натисніть кнопку Train. При необхідності використовуйте кнопку Jog Weights.
Робіть так доти, поки не виконається хоча б одна з вказаних вами умов останову або поки не трапиться перенавчання мережі (SNN автоматично зупинить процес навчання мережі).
При цьому спостерігайте за зміною вмісту вікон, описаних в пунктах 10 – 12. Їх вигляд після закінчення процесу навчання мережі представлений на рис. 21 – 22 і 25 – 26.
Помилки для окремих зразків однорідні і невисокі, що говорить і про успішне навчання і про вдалий підбір даних.

Рис. 21. Стовбчаста діаграма з помилками мережі на конкретних зразках відразу після закінчення останньої епохи навчання
Дивлячись на рис. 22, можна зробити висновок, що після закінчення семи епох навчання було зупинено, оскільки помилка на перевірочному наборі (позначається червоним кольором) стала менше значення, заданого у вікні умов останову (у секції Error V = 0.1692, а за умовою V = 0.2). Також можна припустити, що перенавчання не відбулося, оскільки тренувальна і перевірочна помилки синхронно зменшувалися.

Рис. 22. Підсумковий графік помилок
А от приклад випадку, коли на дев'ятій епосі відбулося перенавчання мережі (рис. 23).
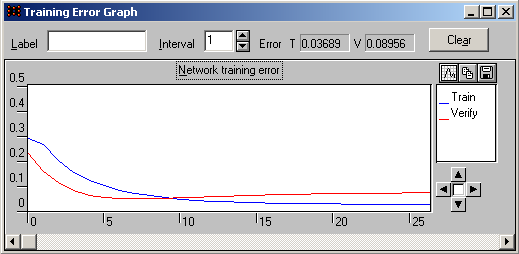
Рис. 23. Ефект перенавчання
В даному випадку помилки змінюються синхронно, з деякою осциляцією, що не являється ознакою перенавчання.

Рис. 24. Незначні синхронні коливання помилок не являються ознакою перенавчання мережі
Характер розподілу вагів і порогів на рис. 25 не змінився в порівнянні з тим, що спостерігався на малюнку 17. Зменшилися лише значення частот.

Рис. 25. Гістограма розподілу частот значень вагів і порогів мережі після навчання
У вікні мережевого редактора можна бачити нові значення вагових коефіцієнтів (рис. 26).

Рис. 26. Кінцеві значення вагів і порогів мережі після навчання
15. Після того, як мережа була успішно навчена (тобто виконалися задані нами умови останову, і при цьому не відбулося перенавчання мережі або попадання в локальний мінімум), збережіть її в мережевому наборі так, як показано в пункті 7, і проглянете значення вагів і порогів. Для цього відкрийте вікно редактора мережі, описане в пункті 9.
Навчена нами мережа моделює нелінійну залежність і може бути використана для вирішення задачі прогнозування.
16. Визначимо показники ефективності мережі. Виконайте команду Statistics->Regression.
У вікні (рис. 27), що з'явилося, можна спостерігати ряд числових оцінок.

Рис. 27. Вікно перегляду статистик регресії
Data Mean – середнє значення вихідної змінної OUTPUT.
Data S.D. – стандартне відхилення цієї ж змінної.
Error Mean – середнє значення помилки на виході мережі (різниця між цільовим і дійсним значеннями на виході мережі).
Error S.D. – стандартне відхилення помилок для вихідної змінної.
Abs E. Mean – середня абсолютних відхилень реального виходу від цільового.
Correlation – це коефіцієнт лінійної кореляції Пірсона між цільовими зразками і прогнозами мережі. Він є показником продуктивності мережі. Чим ближче він до 1 тим краща продуктивність.
S.D.Ratio = Помилка / Стандартне відхилення. Рекомендоване значення 0.1 і менше.
У нашому випадку для тренувального і перевірочного наборів мережа передбачає трохи краще, ніж оцінка на основі середнього і стандартного відхилення. Для тестового набору результати незадовільні. Це пов'язано з малим обсягом навчального набору даних для задачі регресії.
Скільки ж має бути зразків? Скористаємося наступними рекомендаціями [3].
Так, відповідно до 4 знаходимо:
для тренувального піднабору ε = 0.1, W = 15, N = 15 / 0.1 = 150;
для перевірочного піднабору ε = 0.2, W = 15, N = 15 / 0.2 = 75;
для тренувального піднабору ε = 0.2, W = 15, N = 15 / 0.2 = 75;
Разом 300 зразків. У нас в наявності було лише 6.
Отже, необхідно зібрати додаткові дані, забезпечивши при цьому їх якість (однорідність, погодженість, повноту, адекватність вирішуваній задачі)
17. Виконайте команду Run->Response Graph. У вікні, що відкрилося (рис. 28), ви можете візуально вивчити поведінку мережі по спеціальному графіку. Він показує, як активація нейрона (у секції Type вибрана опція Activation) або значення вихідної змінної (у секції Type вибрана опція Prediction), що прогнозується мережею, змінюється у відповідь на зміну вибраної вами вхідної змінної. При цьому вся решта вхідних змінних залишається незмінною. На рис. 28 досліджується залежність зміни прогнозів змінної OUTPUT від зміни значень вхідної змінної INPUT1. У полях Min і Max відображений діапазон зміни значень змінної INPUT1. Для установки діапазону можна використовувати кнопку Range (автоматична установка за даними навчальної вибірки) або ж поля Min і Max для установки діапазона вручну. Значення інших вхідних змінних встановлюються у вікні «Run One-Off Case». Кнопка Mean ініціює їх заміну на середні значення цих змінних. Щоб нарисувати графік задайте значення змінної Steps (визначає, як багато точок використовуватиметься для побудови графіка) і натисніть кнопку Plot. Чим більше значення матиме змінна Steps, тим більша кількість значень змінної INPUT1 генеруватиметься програмою SNN і тим гладшим буде графік відгуку.

Рис. 28. Графік відгуку
18. Виконайте команду Run->Response Surface і проведіть аналіз, аналогічний попередньому. Встановіть X в INPUT1, Y в INPUT2, Z в OUTPUT Layer=2, Type = Prediction Steps=10. Натисніть кнопки Range і Plot. При цьому досліджується зміна змінної OUTPUT у відповідь на зміни двох вхідних змінних. Поверхня відгуку представлена на рис. 29.

Рис. 29. Поверхня відгуку
19. Відкрийте вікно, показане на рис. 30, виконавши команду Run->Activations. Прогляньте значення активації елементів мережі. Для будь-якого зразка встановіть в полі Case No відповідний йому порядковий номер в наборі даних, потім вибирайте шар, змінюючи поле Layer від 1 до 4. У таблиці відображаються числові значення активації елементів поточного шару. Справа, на діаграмі, показані ті ж значення, але в графічній формі. Якщо активація менше нуля, вона позначається червоним кольором, інакше – чорним. Поле Maximum дозволяє задати максимальне значення, характерне для функції активації елементів мережі. Ми використовували логістичну функцію, тому значення за замовчуванням, рівне 1 нас влаштовує. Використовуйте дане вікно при виконанні другого пункту розрахункового завдання.

Рис. 30. Активації елементів першого шару мережі (шару вхідних елементів)
Тут ви можете побачити значення на виході вхідних елементів, отримані після застосування процедур попередньої обробки даних вхідного зразка (у нашому випадку п'ятого). Далі прогляньте активації нейронів прихованих шарів мережі як показано на рис. 31 – 34.

Рис. 31. Активації нейронів другого шару мережі (першого прихованого шару)
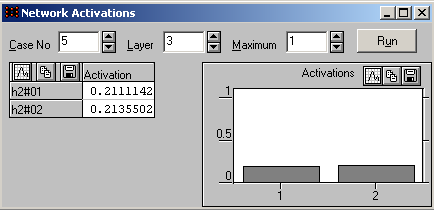
Рис. 32. Активації нейронів третього шару мережі (другого прихованого шару)
Щоб побачити значення активації нейрона у вихідному шарі перейдіть до шару 4. У рядку OUTPUT відображається значення активації до застосування до неї процедур пост-обробки.

Рис. 33. Активація нейрона четвертого шару мережі (шару вихідних елементів)
Відкрийте меню Options і поставте відмітку навпроти пункту Activations in color. Відкрийте вікно з ілюстрацією мережі командою Statistics->Network Illustration. Повторіть наново роботу з вікном Network Activations. Тепер активації для кожного елементу відображаються на схемі мережі кольором з відтінками різної інтенсивності: для негативних значень зеленим, позитивних – червоним, нульових – білим.

Рис. 34. Ілюстрація мережі з колірним кодуванням значень активації
Це дозволяє досліджувати поведінку мережі і роль її окремих прихованих елементів в розпізнаванні вхідних зразків.
20. Протестуйте роботу мережі на вихідному наборі даних. Для цього виконайте команду Run->Data Set. У вікні, що з'явилося (рис. 35), у області Outputs Shown виберіть опцію Variables і натисніть кнопку Run. В результаті всі зразки набору даних (крім Ignored) будуть по черзі подані на входи мережі. Результати роботи мережі на кожному зразку показані в таблиці: колонка OUTPUT відповідає реальним значенням на виході мережі; колонка T.OUTPUT містить цільові значення для вхідних зразків з набору даних; колонка E.OUTPUT містить значення різниці першої і другої колонок; колонка Error показує середньоквадратичну помилку для всіх вихідних змінних (у нас одна така змінна, тому значення в даному стовпці по модулю збігаються з відповідними значеннями в стовпці E.OUTPUT). Результати роботи мережі (середньоквадратичної помилки) на тренувальному, перевірочному і тестовому наборах даних показані в секції RMS Error в полях Train, Verify і Test відповідно.

Рис. 35. Вікно застосування мережі для роботи з безліччю зразків з поточного набору даних
Пропуск всіх зразків через мережу еквівалентний окремій епосі на всіх зразках всіх типів. Якщо не вносити змін в набір даних, то результати роботи мережі збігатимуться з такими відразу після навчання мережі. Ви можете створити новий набір даних і використовувати мережу для його обробки. Часто так роблять на етапі передобробки даних. Створюють мережу, за допомогою якої заздалегідь отримують результат в даному вікні. Потім копіюють його в інший набір даних і використовують далі для роботи з іншою мережею. Кнопка Data Set дозволяє скопіювати результати з даного вікна в набір даних. У ньому з'являться нові змінні з типом Ignored. Ви можете використовувати їх для порівняння з вихідними даними або ж провести обчислення і отримати залишкові значення реальних і цільових виходів і використовувати їх в навчанні або застосуванні іншої мережі.
За допомогою даного вікна ви можете перевірити узагальнюючу здатність мережі на незнайомому їй наборі даних.
21. Щоб протестувати роботу мережі на окремо взятому зразку даних, виконайте команду Run->Single Case. У вікні, що відкрилося (Рис. 36), виберіть зразок, що цікавить вас, використовуючи область Case No. Натисніть кнопку Run. Щоб проглянути результати, використовуйте секцію Outputs Shown. Якщо вас цікавлять значення вихідних змінних, виберіть опцію Variables. Якщо вас цікавлять значення активації на нейронах вихідного шару, виберіть опцію Activations. У даному вікні ви можете тестувати зразки всіх типів, включаючи й ті, що позначені як Ignored. Перелік результатів і їх зміст аналогічний тим, що були розглянуті при роботі з вікном Run Data Set і відносяться до окремого узятого зразка даних. Після навчання мережі ви можете використовувати довільний набір даних, відповідний тій задачі, для вирішення якої ви побудували і навчили мережу.

Рис. 36. Вікно застосування мережі для роботи з окремо взятим зразком з поточного набору даних
22. Для обробки мережею не знайомого їй зразка, що не входить в поточний набір даних, виконайте команду Run->One-Off Case. У вікні, що відкрилося (рис. 37), введіть значення входів в рядку Input і виберіть опцію Variables в секції Outputs Shown. Натисніть кнопку Run. У рядку Output буде показаний результат – реальне значення виходу мережі для заданих значень її входів. Одержаний зразок (сукупність входів і виходу мережі) не буде доданий в поточний набір даних. Для очищення області Input використовуйте кнопку Clear.

Рис. 37. Вікно перевірки узагальнюючої здібності мережі на незнайомих зразках
При рішенні реальних задач дослідник не знає наперед, яка архітектура мережі є найбільш придатною для вирішення його задачі. Тому він змушений проводити експерименти з різною архітектурою. Це досить стомлююче заняття, якщо проводити його вручну. Для цього необхідно досконально знати теоретичні основи нейронних мереж конкретних досліджуваних типів, мати великий практичний досвід у сфері їх побудови, навчання і використання, знати й уміти застосовувати критерії порівняння мереж і звичайно ж розуміти природу і специфіку вихідних даних вирішуваної задачі. Все це, зібране воєдино може бути застосоване в деякій евристичній послідовності (стратегії) дослідження. SNN багато в чому полегшує нам цю роботу.
Отже, створимо набір нейронних мереж і виберемо найефективнішу з них для вирішення задачі моделювання регресійної залежності змінної PWIDTH від змінних SLENGTH, SWIDTH і PLENGTH.
Збережіть поточний набір даних, виконавши команду File->Save.
Збережіть поточний мережевий набір, виконавши команду File->Network Set->Save As.
Закрийте вікно Data Set командою File->Close.
Закрийте вікна, що залишилися, крім головного вікна програми.
Відкрийте набір даних з файлу S:\Statistica\SNN\Irirs.dat
Виконайте команду Edit->Cases->Shuffle->Group Sets щоб зібрати учбові зразки в групи, відповідні тренувальному, перевірочному і тестовому піднаборам даних.
Для змінної FLOWER встановіть тип IGNORE.
Виконайте команду File->New->Intelligent Problem Solver. З'явиться вікно спеціального майстра настройок процесу рішення задачі і пошуку множини мереж (IPS) (рис. 38).

Рис. 38. Вікно вибору версії майстра IPS
Версія Standard більшість настройок встановлюються автоматично. Від користувача потрібно ввести лише основні з них. Версія Advanced дозволяє проводити вручну тоншу настройку процесу пошуку мереж. Виберіть Basic і натисніть кнопку Next.
У наступному вікні (рис. 39), виберіть Standard (зразки з набору даних будуть розглядатися як незалежні один від одного в часі), натисніть кнопку Next.

Рис. 39. Вікно вибору типу вирішуваної задачі
Задайте залежну (вихідну) змінну – виберіть змінну PWIDTH. Натисніть кнопку Next.

Рис. 40. Вікно вибору залежної змінної
Виберіть незалежні змінні як показано на рис. 41. Зніміть прапорець над ними (якщо він встановлений, то автоматично виконається аналіз впливу вхідних змінних на ефективність мережі або т.з. аналіз чутливості, ми проведемо його вручну пізніше). Натисніть кнопку Next.

Рис. 41. Вікно вибору незалежних змінних
У наступному вікні (рис. 42), виберіть середню тривалість процедури пошуку нейронних мереж, встановивши опцію Medium (швидкий пошук мереж з характеристиками, близькими до оптимальних). Опція Quick у версії Standard автоматично знаходить одну-дві однотипні мережі (за замовчуванням це MLP), а у версії Advanced – одну-дві мережі для кожного з вказаних типів мереж. Опція Thorough задає розширений пошук, який застосовується при великій кількості вхідних змінних, наприклад, більше 10, і при великій кількості повчальних зразків (більше 1000), а також при використанні опції автоматичного визначення складності мережі і/або кількості вхідних змінних. Опція Timed дозволяє задавати фіксований час процесу пошуку мереж.
Натисніть кнопку Next для переходу до наступного вікна.

Рис. 42. Вікно вибору тривалості процедури пошуку нейронних мереж
Задайте місткість мережевого набору рівним 10. Виберіть критерій, відповідно до якого в мережевому наборі зберігатимуться мережі. Вкажіть тип реакції програми на переповнювання мережевого набору (збільшити його обсяг або ж замінити існуючі мережі при знаходженні нових мереж з кращими показниками якості). Для цього проведіть настройки так, як показано на рис. 43. Для переходу до наступного вікна натисніть на кнопку Next.

Рис. 43. Вікно вибору настройок мережевого набору і процедури відбору і збереження в ньому знайдених мереж
Для відображення результатів пошуку, загальної статистики для знайдених мереж і для кращої з них, проведіть установки так, як показано на рис. 44.
Для запуску процесу пошуку мереж натисніть на кнопку Finish. У рядку стану головного вікна програми внизу справа з'явиться індикатор процесу роботи IPS (рис. 45), що дозволить вам оцінити час, необхідний на виконання процесу пошуку. Почекайте, доки IPS знайде і проаналізує мережі, сформує набір з кращих мереж. При цьому у вікні, зображеному на рис. 46, кожного разу при знаходженні мережі з кращими показниками якості, з'являтиметься строчка з коротким описом цієї мережі.
Після закінчення процесу пошуку, на екрані разом з іншими з'явиться вікно редактора мережевого набору (рис. 47), в якому поточна мережа позначена знаком «*» (зазвичай, ця мережа остання в списку). Проаналізуйте типи мереж (RBF, MLP, Linear).

Рис. 44. Вікно вибору переліку результатів, що відображаються відразу після закінчення роботи майстра IPS
![]()
Рис. 45. Рядок індикації процесу обчислень

Рис. 46. Вікно із списком повідомлень про знайдені і проаналізовані мережі

Рис. 47. Вікно мережевого набору з переліком і характеристиками мереж
Таблиця може мати два представлення – Basic і Verbose, які складаються з безлічі колонок і дають повне уявлення про мережу.
Колонка Type відображає тип мережі: MLP (багатошаровий персептрон), RBF (радіальна мережа), Linear (лінійна мережа), PNN (імовірнісна мережа), GRNN (узагальнена регресійна мережа).
Inputs – кількість вхідних змінних в мережі.
Hidden, Hidden(2) – кількість прихованих елементів в мережі (або «-», якщо мережа не має прихованих елементів).
Кількість прихованих елементів разом з кількістю входів визначають складність мережі.
Колонка Training містить умовні позначення про три останні алгоритми, які використовувалися для навчання мережі. Наприклад BP50bsс означає: BP – для навчання мережі використовувався алгоритм зворотного поширення помилки (Back Propagation), при навчанні було пройдено 50 епох, s – виконалася умова останову і було витрачено менше епох ніж задавалося спочатку, b – мережа є кращою в мережевому наборі, с – відбулася збіжність алгоритму (був досягнутий локальний або глобальний мінімум).
Колонки TPerf, VPerf, TePerf показують продуктивність мережі (коефіцієнт S.D.Ratio) на тренувальному, перевірочному і тестовому наборах відповідно.
Колонки TError, VError, TeError показують середньоквадратичну помилку роботи мережі на тренувальному, перевірочному і тестовому наборах відповідно. Значні відмінності в їх значеннях вказують на ненадійність оцінки продуктивності мережі, що пов'язано з невдалим розподілом зразків по піднаборах або недостатністю даних для навчання. Тренувальна помилка може бути набагато меншою за дві інші. Однак, це ні про що не говорить. Перевірочна помилка також може виявитися маленькою, меншою за тестову помилку. Проте, якщо при інших розподілах зразків перевірочна помилка як і раніше набагато менша за тестову, то її маленьке значення вважається «випадково вдалим», а обсяг даних – недостатнім для навчання. Навпаки, якщо значення цих помилок залишаються близькими і так відбувається впродовж великого числа експериментів, то мережа має хорошу передбачувальну здатність. Після такого аналізу застосовують критерій вибору найкращої мережі – складність має бути якомога меншою, а продуктивність – якомога більшою. Найкращою є мережа з мінімальною помилкою на перевірочному наборі даних (колонка V.Error). Якщо ж він не використовується, то з мінімальною помилкою на тренувальному наборі даних (колонка T.Error). Дані повинні бути в достатньому обсязі і репрезентативними у всіх піднаборах.
У представленні Basic колонки Error і Performance відповідають колонкам V.Error і V.Perf у представленні Verbose, якщо мережа тестувалася за допомогою набору даних, який включав перевірочні зразки. Інакше, вони відповідають колонкам T.Error і T.Perf.

Рис. 48. Ілюстрація кращої мережі

Рис. 49. Вікно перегляду статистик регресії для кращої мережі

Рис. 50. Вікно застосування мережі для роботи з безліччю зразків з поточного набору даних