

Лабораторна робота № 1
Тема: Рішення задач регресії за допомогою нейронних мереж типу «багатошаровий персептрон» (MLP) з використанням навчального алгоритму зворотного поширення помилок і інструментальних засобів пакету Statistica Neural Networks.
Мета роботи: закріпити теоретичний лекційний матеріал, засвоїти методику побудови, навчання, оцінки і застосування нейронної мережі типу MLP з використанням навчального алгоритму зворотного поширення помилок (Back Propagation) при рішенні задач регресії в пакеті Statistica Neural Networks.
Завдання роботи.
1. Визначити та ввести (імпортувати) дані щодо аналізу на основі використання штучної мережі.
2. Розробити структуру (архітектуру) нейроної мережі.
3. Визначити функції активації нейронів.
4. Здійснити процес навчання мережі.
5. Проаналізувати результати навчання мережі та оцінити помилку її експлуатації.
Загальні положення
Нейронні
мережі складаються з нейронів, міжнейронних
зв'язків, вхідних і вихідних елементів.
Кожен нейрон мережі описується своєю
PSP-функцією
 ,
функцією активації
,
функцією активації
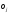 ,
сукупністю своїх входів
,
сукупністю своїх входів ,
, і вагами входів
і вагами входів (рис. 1).
(рис. 1).
Нейрон отримує сигнали з своїх вхідних каналів. Кожен сигнал проходить через з'єднання – синапс, що має певну інтенсивність, або вагу, яка відповідає синаптичній активності нейрона.
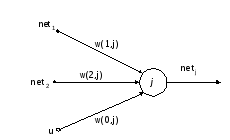
Рис 1. Штучний нейрон
Поточний стан нейрона визначається його пост-синаптичною потенційною функцією (PSP). Це функція, яка застосовується до вхідних сигналів елементу, його вагів і порогів і видає рівень активації цього елементу. Оскільки в даній лабораторній роботі ми вивчатимемо мережу типу багатошарового персептрона (MLP), то використовуватимемо лінійну PSP-функцію.
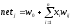 , (1)
, (1)
де
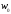 –
порогове значення,
–
порогове значення,
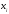 –
вхідні сигнали (
–
вхідні сигнали ( ),
),
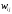 –
ваги синаптичних зв'язків (додатні
значення відповідають збуджуючим
синапсам, від’ємні значення – гальмуючим
синапсам, нульові значення означають,
що зв'язок між нейроном
–
ваги синаптичних зв'язків (додатні
значення відповідають збуджуючим
синапсам, від’ємні значення – гальмуючим
синапсам, нульові значення означають,
що зв'язок між нейроном
 і
нейроном
і
нейроном
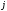 відсутній).
відсутній).
Таким
чином, нейрон бере зважену суму своїх
входів і зміщує її на порогове значення
(Threshold).
Такий елемент прагне здійснити
класифікацію, розбиваючи простір входів
на класи за допомогою системи гіперплощин.
Зазвичай, поріг (його ще називають
зсувом)
задається як нульовий або
 -й
вхід нейрона, який має власну вагу
(позначається як
-й
вхід нейрона, який має власну вагу
(позначається як або
або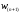 ).
Дуга, що відповідає зсуву, не пов'язана
з виходом будь-якого іншого нейрона,
тому значення входу по даній дузі
береться за постійне, найчастіше рівне
–1.
).
Дуга, що відповідає зсуву, не пов'язана
з виходом будь-якого іншого нейрона,
тому значення входу по даній дузі
береться за постійне, найчастіше рівне
–1.
Функція активації або передавальна функція перетворить значення PSP-функції (отриманий нейроном сигнал) у вихідний сигнал нейрона. Використовують наступні види функцій активації (табл.1)
Таблиця 1
Функції активації
|
№ |
Назва |
Формула |
Значення |
|
1 |
Лінійна |
x |
(-U,+U) |
|
2 |
Логістична |
|
(0,+1) |
|
3 |
Гіперболічна |
|
(-1,+1) |
|
4 |
Експоненціальна |
|
(0,+ <) |
|
5 |
Софтмакс |
|
(0,+1) |
|
6 |
Квадратний корінь |
|
[0,+ ;) |
|
7 |
Синус |
Sin(x) |
[-1,+1] |
|
8 |
Шматково-лінійна |
|
[-1,+1] |
|
9 |
Ступінчаста |
|
[0,+1] |
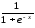
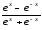
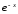
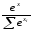
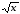
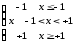
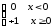
Перед навчанням мережі необхідно проводити етап ретельної попередньої підготовки вихідних даних. У даній лабораторній роботі для цих цілей рекомендується використовувати засоби пакету STATISTICA.
Вся інформація, яку мережа має про задачу, міститься в наборі зразків. Тому якість навчання мережі безпосередньо залежить від кількості зразків в навчальній вибірці, а також від того, наскільки повно ці зразки описують дану задачу. Вважається, що для повноцінного тренування потрібно хоча б декілька десятків (а краще за сотні) зразків.
На рис. 2 дана укрупнена схема навчання мережі з використанням алгоритму зворотного поширення помилки.
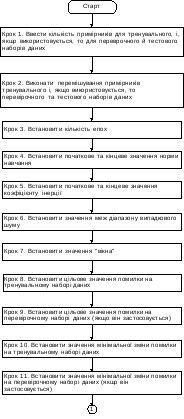
Рис.2. Схема навчання мережі з використанням алгоритму зворотного поширення помилок

Рис.2. Схема навчання мережі з використанням алгоритму зворотного поширення помилок (продовження)

Рис.2. Схема навчання мережі з використанням алгоритму зворотного поширення помилок (продовження)

Рис.2. Схема навчання мережі з використанням алгоритму зворотного поширення помилок (закінчення)
Перед застосуванням алгоритму необхідно задати значення низки управляючих параметрів. Найбільш важливими параметрами є кількість епох, швидкість навчання, інерція, шум і перемішування спостережень в процесі навчання.
Кількість епох (Epochs) – це та кількість циклів, на кожному з яких всі зразки з тренувального набору пропускаються через мережу, змінюються ваги і пороги мережі.
Швидкість
навчання (Learning
rate)
або
норма навчання
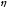 впливає
на величину кроку при зміні вагів, тобто
величину змін, що вносяться алгоритмом
в значення вагів: в разі недостатньої
швидкості алгоритм повільно сходиться,
а при дуже великій швидкості алгоритм
нестійкий. Величина якнайкращої швидкості
залежить від конкретної задачі. Для
швидкого і грубого навчання підійдуть
значення від 0,1 до 0,6. Для досягнення
точної збіжності потрібні набагато
менші значення (0,01 або навіть 0,001, коли
кількість епох сягає багатьох тисяч).
Висока швидкість навчання прискорює
навчання, але може ввести нестійкість
процесу навчання, особливо, якщо в даних
присутній шум.
впливає
на величину кроку при зміні вагів, тобто
величину змін, що вносяться алгоритмом
в значення вагів: в разі недостатньої
швидкості алгоритм повільно сходиться,
а при дуже великій швидкості алгоритм
нестійкий. Величина якнайкращої швидкості
залежить від конкретної задачі. Для
швидкого і грубого навчання підійдуть
значення від 0,1 до 0,6. Для досягнення
точної збіжності потрібні набагато
менші значення (0,01 або навіть 0,001, коли
кількість епох сягає багатьох тисяч).
Висока швидкість навчання прискорює
навчання, але може ввести нестійкість
процесу навчання, особливо, якщо в даних
присутній шум.
Інерція (Momentum) служить для надання процесу корекції вагів деякої інерційності, що згладжує різкі скачки при переміщенні по поверхні цільової функції. Дякуючи їй приріст ваги на поточному кроці доповнюється значенням, пропорційним зміні ваги на попередній ітерації. Допомагає алгоритму, коли він застряє в низинах (сідловин точках) і локальних мінімумах. Зменшує ймовірність того, що зміни вагів набудуть осцилюючого характеру. Цей коефіцієнт повинен приймати значення в інтервалі [0,+1). Він також може змінюватися в часі шляхом інтерполяції його початкового і кінцевого значень, і обчислення шуканого значення для конкретної епохи. Покращує продуктивність шляхом прискорення навчання там, де відбувається мала зміна помилки. Збільшує стабільність. Рекомендується використовувати мале значення при високій швидкості навчання і навпаки.
Перемішування спостережень (Shuffling) додає деякий випадковий шум в процес навчання за допомогою зміни порядку проходження спостережень в наборах на кожній епосі, тому помилка може трохи коливатися вгору-вниз. Зменшує ймовірність того, що алгоритм застрягне в локальному мінімумі, а також зменшує ефект перенавчання. Не дає процесу навчання «забути» про особливості, приховані в зразках наборів даних і виробити шаблонну поведінку на окремих послідовних підмножинах зразків, тобто забути одні зразки при запам'ятовуванні інших.
Шум (Noise) – це випадкова величина, рівномірно розподілена в діапазоні (-n,+n). Він додається до кожної вхідної змінної в ході навчання. Це дозволяє поліпшити здібність мережі до узагальнення, запобігаючи перенавчанню мережі на даних тренувального набору, а також зменшує ймовірність того, що алгоритм застрягне в локальному мінімумі.
Для останову алгоритму можна використовувати наступні умови:
максимальна кількість епох, після закінчення якої алгоритм зупиняється;
мінімальний рівень помилки, досягши якого алгоритм зупиняється;
величина зменшення помилки і кількість епох (вікно), протягом яких це зменшення повинно бути досягнуто інакше алгоритму зупиняється. Іноді покращення помилки може на деякий час припинитися або ж помилка навіть може тимчасово зрости (особливо якщо використовується перемішування або визначений не нульовий, випадковий шум – в обох випадках в процес тренування вноситься елемент шуму). Щоб запобігти передчасному останову, потрібно вказати величину вікна, більшу одиниці. Якщо ж величина вікна рівна 0, то дана умова не застосовується.