

Методы статистического и интеллектуального анализа данных. Минаева Ю.В
.pdfМИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФГБОУ ВО «Воронежский государственный технический университет»
Ю.В. Минаева
МЕТОДЫ СТАТИСТИЧЕСКОГО И ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА ДАННЫХ
Утверждено учебно–методическим советом университета в качестве учебного пособия
Воронеж 2017
УДК 681.3.(075.8)
ББК 22.172 я 7 М613
Минаева Ю.В. Методы статистического и интеллектуального анализа данных: учеб. пособие / Ю.В. Минаева. – Воронеж: ФГБОУ ВО «Воронежский государственный технический университет», 2017. 90 с.
В учебном пособии рассматриваются теоретические сведения о классических статистических методах анализа данных (корреляционный, регрессионный, дисперсионный и др. виды анализа) и о современных методах интеллектуальной обработки накопленной информации, используемых для получения новых полезных знаний (OLAP–анализ и Data Mining).
Издание соответствует требованиям Федерального государственного образовательного стандарта высшего образования по направлению 09.03.01 «Информатика и вычислительная техника» (направленность «Системы автоматизированного проектирования»), дисциплине «Методы обработки данных».
Ил. 18. Табл. 12. Библиогр.: 11 назв.
Рецензенты: кафедра программирования и информационных технологий
Воронежского государственного университета (зав. кафедрой, канд. физ.–мат. наук, доц. Н.А. Тюкачев); канд. техн. наук, доц. Ю.В. Литвиненко
©Минаева Ю.В., 2017
©ФГБОУ ВО «Воронежский государственный технический университет», 2017
ВВЕДЕНИЕ
С развитием науки и техники все более актуальной становится задача обработки накопленной информации с целью получения новых знаний. Для решения этой задачи к настоящему времени разработано большое количество методов, относящихся как к классической теории статистики, так и к современному популярному направлению интеллектуальной обработки многомерных данных.
Методы математической статистики (корреляционный, регрессионный, дисперсионный и др. виды анализа) позволяют специалистам–аналитикам выявлять закономерности и делать обоснованные выводы и прогнозы и оценивать вероятности их выполнения. Развивающиеся в настоящее время методы обработки многомерных данных, такие как OLAP–анализ и Data Mining, предполагают активное использование средств искусственного интеллекта для получения новых полезных знаний, скрытых в больших объемах накопленной информации.
В современных условиях функционирование практически любого предприятия немыслимо без процессов сбора и хранения данных, поэтому методы анализа информации являются общеупотребительным инструментом, используемым в плановых, аналитических и маркетинговых отделах производственных и торговых предприятий, банков и страховых компаний, правительственных и медицинских учреждений.
Учебное пособие содержит теоретические сведения о типовых задачах анализа информации и методах их решения. Для удобства изучения все рассматриваемых методы обработки данных объединены в следующие группы: методы описательной статистики, методы анализа статистических связей, методы классификации и редукции данных, технологии многомерного анализа данных.
3
1. ОБРАБОТКА ДАННЫХ С ПОМОЩЬЮ МЕТОДОВ ОПИСАТЕЛЬНОЙ СТАТИСТИКИ
1.1. Основные понятия и задачи математической статистики
При исследовании различных технических и экономических процессов часто приходится сталкиваться с событиями, имеющими случайную природу. Как известно, для описания случайных величин с заданными вероятностными характеристиками (например, законом распределения, математическим ожиданием и дисперсией) эффективно используется аппарат теории вероятности, однако, если статистические характеристики исследуемого объекта неизвестны, а есть только результаты наблюдений над ним, то для их обработки используются методы математической статистики.
Математическая статистика – наука, изучающая методы исследования закономерностей в массовых случайных явлениях и процессах по данным, полученным из конечного числа наблюдений за ними.
Основными задачами математической статистики являются:
–оценка неизвестных характеристик случайной
величины;
–проверка статистических гипотез, т.е. предположений
ораспределении вероятностей наблюдаемой случайной величины;
–установление формы и степени связи между случайными величинами.
Приведем основные определения, необходимые для дальнейшего изучения методов обработки данных наблюдений за исследуемым объектом.
В зависимости от характера принимаемых значений случайная величина может быть дискретной, т.е. принимать
4
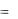
только значения из определенного набора, или непрерывной, т.е. принимать любые значения.
Генеральная совокупность – все множество возможных значений исследуемой случайной величины X.
Случайная выборка из генеральной совокупности X
– совокупность случайных величин x1, x2 ,..., xn , полученных
в результате n наблюдений за случайной величиной X, при этом число n – объем случайной выборки.
Целью изучения любой выборки является получение информации о генеральной совокупности, поэтому выборка должна быть репрезентативной (представительной), т.е.
правильно отражать пропорции генеральной совокупности. Это достигается с помощью выполнения следующих требований:
–каждый элемент xi , i 1,...,n , выбирается случайно и независимо от других;
–все элементы xi имеют одинаковую вероятность
попасть в случайную выборку;
– объем выборки n должен быть настолько велик, чтобы позволять решать задачу с требуемой точностью.
Характеристики случайных величин, полученные по генеральной совокупности, называются теоретическими (генеральными); характеристики, полученные по выборке из генеральной совокупности – эмпирическими (выборочными)
Статистические показатели, характеризующие случайную выборку, могут быть абсолютными и относительными.
Абсолютные показатели представляют собой суммарные значения тех или иных признаков, вычисленных по выборке (или генеральной совокупности) в целом или по ее части.
Относительные показатели определяются как отношение одного абсолютного показателя к другому.
Исследование случайных величин с помощью методов математической статистики проводится в три этапа:
5

–статистическое наблюдение – включает в себя сбор первичной статистической информации;
–обработка первичной информации;
–анализ первичной информации и интерпретация полученных результатов.
1.2. Методы предварительной обработки результатов наблюдений
Перед тем, как перейти к детальному анализу полученных в результате наблюдений данных, их приводят к одному из следующих видов:
1. Вариационный ряд – элементы выборки располагаются в порядке возрастания (неубывания):
x (1) , x(2) ,..., x(n) ,
где x(1) x (2) ... x (n) , .
Переход от случайной выборки к ее вариационному ряду не приводит к потере информации, поскольку функции распределения остается такой же, однако происходит искажение исходных данных, поскольку элементы упорядоченной выборки уже не являются взаимно независимыми.
Данные, приведенные к вариационному ряду,
называются негруппированными.
2. Статистический ряд – преобразование выборки с повторяющимися элементами в таблицу. Данные, представленные в виде статистического ряда, являются
группированными.
Пусть |
выборка |
X n |
x1, x2 ,..., xn |
содержит m |
|
различных элементов z(1) , z(2) ,..., z(m) , каждый из |
которых |
||||
повторяется, |
соответственно, |
n1, n2 ,..., nm |
раз, |
причем |
|
m |
|
|
|
|
|
ni n . |
|
|
|
|
|
i 1 |
|
|
|
|
|
6
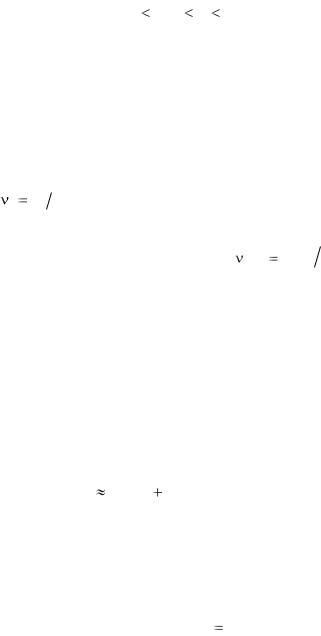
Врезультате группировки исходная выборка
преобразуется в таблицу, где z(1) |
z(2) |
... z(m) (табл. 1). |
|||||
|
|
|
|
|
|
Таблица 1 |
|
|
|
|
|
|
|
|
|
|
z(1) |
z (2) |
|
… |
|
z(m) |
|
|
n1 |
n2 |
|
… |
|
nm |
|
Числа ni , показывающие, сколько раз элемент z(i) встречается в выборке, называются частотами значения z(i) , а
величины |
i ni n |
– относительными |
|
частотами. |
||
Накопленной |
частотой |
nнак |
называется число |
элементов |
||
|
|
i |
|
|
|
|
выборки, меньших значения z |
(i) , отношение |
нак |
нак |
n – |
||
i |
ni |
|||||
относительной накопленной частотой.
Статистический ряд, как правило, применяется для группировки небольших выборок с дискретными элементами. Для выборок большого объема из непрерывных генеральных совокупностей используется интервальный статистический ряд. В этом случае область задания выборки X разбивается на m интервалов, а числа ni указывают количество элементов
выборки, попавших в i–й интервал.
Число интервалов m может быть задано природой исследуемого явления, условиями проведения наблюдений или определяться по формуле Старджеса:
m log 2 n 1.
При подсчете частот ni для однозначности считают, что
каждый интервал включает свою левую границу и не включает правую, за исключением последнего интервала, включающего и левую, и правую границы.
Пример. При тестировании СУБД проводились измерения времени выполнения запросов к базе данных. Получилась следующая выборка объемом n 20 элементов:
7

2.92 |
6.28 |
3.12 |
5.46 |
5.02 |
3.54 |
4.64 |
3.54 |
5.30 |
4.08 |
|
|
|||||||||||||||||
4.08 |
4.52 |
4.64 |
5.02 |
3.12 |
5.02 |
4.08 |
2.92 |
5.30 |
6.28 |
|
||||||||||||||||||
|
|
|
Вариационный ряд для данной выборки имеет вид: |
|||||||||||||||||||||||||
2.92 |
2.92 |
3.12 |
3.12 |
3.54 |
3.54 |
4.08 |
4.08 |
4.08 |
4.52 |
|
||||||||||||||||||
4.64 |
4.64 |
5.02 |
5.02 |
5.02 |
5.30 |
5.30 |
5.46 |
6.28 |
6.28 |
|
||||||||||||||||||
|
|
|
Сформируем статистический ряд для выборки (табл. 2). |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
z(i) |
|
2.92 |
|
3.12 |
3.54 |
4.08 |
4.52 |
|
4.64 |
5.02 |
5.30 |
5.46 |
6.28 |
|
|
|||||||||||
|
|
ni |
|
2 |
|
2 |
2 |
3 |
|
1 |
|
|
2 |
|
3 |
|
2 |
|
1 |
2 |
|
|
||||||
|
|
|
Далее построим интервальный статистический ряд. Для |
|||||||||||||||||||||||||
наглядности число интервалов примем m |
6 . |
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
Определим длину интервала: |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
L |
|
|
xmax xmin |
|
6.28 |
2.92 |
0.56. |
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
m |
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
где xmax |
|
и xmin – максимальный и минимальный элементы |
||||||||||||||||||||||||||
выборки, соответственно. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
С учетом значения L определим границы интервалов |
|||||||||||||||||||||||||
Li , найдем их середины |
z(i) |
|
и |
вычислим |
для |
каждого |
||||||||||||||||||||||
интервала частотные характеристики (табл. 3). |
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 3 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Li |
|
[2.92, 3.48) |
|
[3.48, 4.04) |
[4.04, 4.60) |
|
[4.60, 5.16) |
[5.16, 5.72) |
|
[5.72, 6.28] |
|
||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
z(i) |
|
|
3.20 |
|
|
3.76 |
4.32 |
|
|
|
4.88 |
|
5.44 |
|
|
|
6.00 |
|
|
||||||||
|
ni |
|
|
4 |
|
|
|
|
2 |
4 |
|
|
|
|
5 |
|
|
3 |
|
|
|
2 |
|
|
||||
|
|
i |
|
|
0.2 |
|
|
0.1 |
0.2 |
|
|
|
0.25 |
|
0.15 |
|
|
|
0.1 |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
нак |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ni |
|
|
4 |
|
|
|
|
6 |
10 |
|
|
|
|
15 |
|
18 |
|
|
|
20 |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
нак |
|
|
0.2 |
|
|
0.3 |
0.5 |
|
|
|
0.75 |
|
0.90 |
|
|
|
1.00 |
|
|
||||||||
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
8

1.3. Графическое |
изображение |
статистических |
||
данных |
|
|
|
|
Для |
визуализации |
статистической |
информации |
|
используются следующие виды графиков:
1. Полигон частот представляет собой ломаную линию, вершинами которой являются точки с координатами (xi , i ) , и
применяется, в основном, для наглядного изображения выборки из дискретной генеральной совокупности.
|
2. |
Гистограмма – диаграмма, состоящая из |
|||
прямоугольников с шириной, равной интервалу L, и высотой |
|||||
ni , |
применяется |
для |
визуализации |
интервального |
|
статистического ряда. |
|
|
|
||
|
3. |
Кривая накопленных частот (кумулятивная кривая) |
|||
|
|
|
|
нак |
|
– ломаная линия с вершинами в точках (xi , i |
) . |
||||
Пример. Построим графики для выборки из табл. 3 (рис.
1–3).
Рис. 1. Полигон частот для случайной выборки
9

Рис. 2. Гистограмма частот для случайной выборки
Рис. 3. Кривая накопленных частот для случайной выборки
10