

2117
.pdfполучить математическое описание такой зависимости. Для этого используются методы регрессионного анализа.
Регрессионный анализ – это метод статистического анализа данных, позволяющий выразить в аналитической форме зависимость среднего значения результативного признака от значений одной или нескольких факторных переменных.
Задачами регрессионного анализа являются:
–подбор класса функций, наилучшим образом аппроксимирующих искомую зависимость;
–поиск значений неизвестных параметров, входящих в уравнение искомой зависимости;
–установление адекватности полученного уравнения;
–выявление наиболее информативных факторных переменных.
Пусть в процессе предварительного анализа экспериментальных данных выделен результативный признак y
инекоторая совокупность объясняющих его факторных
признаков x x1, x2 ,..., xk , k – количество выделенных
признаков. Тогда искомая математическая модель, выражающая зависимость среднего значения результативной переменной y от влияющих на нее переменных x1, x2,...,xk , записывается следующим образом:
y f (x) .
Данное уравнение называется уравнением регрессии (или просто регрессией). В этом уравнении значения x1, x2,...,xk являются детерминированными (определенными,
не случайными), а в качестве y выступает среднее значение результативного случайного признака с нормальным распределением.
По количеству факторных переменных регрессия может быть парной (однофакторной) и множественной (многофакторной).
31

Парная регрессия характеризует связь между двумя признаками – факторным и результативным. Аналитическая зависимость между данными признаками может быть:
– линейная – выражается линейной функцией (уравнением прямой):
y a0 a1x ;
– нелинейная – выражается уравнениями вида:
y |
a |
0 |
a x |
a |
2 |
x2 |
– парабола; |
||
|
|
1 |
|
|
|
|
|||
y |
a0 |
|
a1 |
|
– гипербола и т.д. |
||||
|
x |
||||||||
|
|
|
|
|
|
|
|
||
Вуравнении регрессии параметр a0 показывает
усредненное влияние на результативный признак неучтенных в математической модели факторов, а параметры a1,a2,...
являются множителями, определяющими, насколько изменяется в среднем значение результативного признака при увеличении факторных на единицу измерения.
Выбор вида уравнения определяют путем визуального сравнения корреляционного поля и графиков уравнений.
Поскольку на практике на распределение результативной переменной y влияют как значения факторных переменных x, так и различные неучтенные факторы, в т.ч. помехи при измерении результатов наблюдений, то любая теоретическая кривая будет описывать ее только приблизительно. Для восстановления неизвестной функции регрессии по имеющимся экспериментальным данным коэффициенты уравнения регрессии a0,a1,... выбираются
таким образом, чтобы теоретическая кривая наилучшим образом аппроксимировала наблюдаемые значения переменной y.
Для определения неизвестных коэффициентов a0,a1,...
могут использоваться несколько методов, наиболее распространенным из которых является метод наименьших квадратов.
32

Суть метода заключается в нахождении таких параметров a0,a1,..., при которых сумма квадратов отклонений
фактических значений результативного признака от теоретических, полученных по уравнению регрессии, стремится к минимуму:
|
|
|
|
n |
y 2 |
|
|
|
|
|
|
|
S |
y |
min , |
|
|
||
|
|
|
|
i |
i |
|
|
|
|
|
|
|
|
i 1 |
|
|
|
|
|
~ |
– значения результативного признака, |
полученные по |
|||||||
где yi |
|||||||||
уравнению регрессии. |
|
|
|
|
|
|
|||
|
Графическая |
|
иллюстрация |
|
метода |
наименьших |
|||
квадратов представлена на рис. 8, где |
|
yi |
~ |
|
|||||
i |
yi . |
|
|||||||
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y4 |
|
|
~ |
a1x |
|
|
|
|
|
~ |
|
|
y a0 |
|
|
|
|
|
~ |
y4 |
|
4 |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
y2 |
|
|
|
|
|
|
|
|
|
y3 |
|
|
|
|
|
|
|
|
~ |
|
2 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
~ |
y2 |
y3 |
|
|
|
|
|
|
|
y1 |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
y1 |
|
|
|
|
|
|
|
|
|
x1 |
|
x2 |
|
x3 |
x4 |
… |
x |
|
|
Рис. 8. Графическая иллюстрация метода |
|
|||||||
|
|
|
наименьших квадратов |
|
|
||||
|
Для отыскания минимума целевой функции необходимо |
||||||||
найти |
ее частные |
производные по |
параметрам |
a0,a1,..., |
|||||
приравнять их нулю и решить полученную систему уравнений:
33

dS |
0, |
|
|
||
da 0 |
||
|
dS 0, da1
...
Пример. Составить уравнение регрессии по данным табл. 5.
Как видно из рис. 7, между данными существует линейная зависимость, следовательно, уравнение регрессии имеет вид
y a0 a1x .
Тогда целевая функция для метода наименьших квадратов запишется в виде
|
n |
|
a x 2 |
|
S |
y |
a |
min . |
|
|
i |
0 |
1 i |
|
|
i 1 |
|
|
|
Найдем частные производные функции по неизвестным параметрам a0 и a1:
dS |
n |
|
|
|
||
2 yi |
a0 |
a1 xi |
0, |
|||
|
|
|||||
da0 |
||||||
i 1 |
|
|
|
|||
dS |
n |
|
|
|
||
2 yi |
a0 |
a1xi xi |
0. |
|||
|
|
|||||
da1 |
||||||
i 1 |
|
|
|
|||
Преобразуем систему уравнений следующим образом:
|
|
n |
|
n |
|
na 0 |
a1 |
xi |
|
|
yi , |
|
i |
1 |
|
i |
1 |
n |
|
n |
x 2 |
n |
|
a 0 |
xi |
a1 |
xi yi . |
||
i |
1 |
i |
1 |
i |
i 1 |
Подставим числа, получим уравнения
5  a 0 275
a 0 275  a1 104,
a1 104,
275  a 0 15375
a 0 15375  a1 5870.
a1 5870.
34

|
Решением данной системы уравнений будут значения |
a0 |
12.2 , a1 0.6 . Подставим их в уравнение регрессии: |
y  12.2 0.6
12.2 0.6  x .
x .
Множественная регрессия изучает связь между тремя и более признаками.
Задачей множественной регрессии является построение уравнения регрессии, связывающего среднее значение
результативного признака |
y и факторные признаки |
x1, x2,...,xk : |
|
y1,2,...,k |
f (x1, x2 ,...,xk ) . |
Построение модели множественной регрессии включает два основных этапа:
–выбор вида уравнения регрессии;
–определение размерности модели связи – отбор наиболее значимых факторных признаков.
Для описания зависимостей между исследуемыми признаками чаще всего используются следующие модели:
–линейная:
y1,2,...,k |
a0 |
|
a1x1 |
a2x2 |
... |
|
ak xk ; |
|||||||||||||
– степенная: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y |
|
|
a |
0 |
xa1 |
xa 2 |
... xa k |
; |
|
|
||||||||||
1,2,...,k |
|
|
|
1 |
|
|
|
2 |
|
|
|
k |
|
|
|
|
||||
– показательная: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y |
|
ea 0 |
a1x1 |
a 2 x 2 |
... |
a k x k ; |
|
|||||||||||||
1,2,...,k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
– параболическая: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
y |
a |
0 |
|
a x2 |
a |
2 |
x2 |
... a |
k |
x2 |
; |
|||||||||
1,2,...,k |
|
|
|
1 |
1 |
|
|
|
2 |
|
|
|
k |
|
||||||
– гиперболическая: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
y |
|
|
a |
0 |
|
a1 |
|
|
|
a 2 |
|
... |
|
a k |
. |
|
||||
|
|
|
|
|
|
|
|
|
||||||||||||
1,2,...,k |
|
|
|
x1 |
|
|
x 2 |
|
|
x k |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
В случае множественной регрессии, как правило, строят несколько моделей, затем каждая из них проверяется с помощью статистических критериев (например, с помощью t–
35
критерия Стьюдента или критерия Фишера) и выбирается наилучшая.
Одной из основных проблем построения модели множественной регрессии является определение оптимального числа факторных признаков, используемых в уравнении регрессии. С одной стороны, чем больше факторных признаков включено в модель, тем лучше оно аппроксимирует имеющиеся результаты наблюдений. С другой стороны, слишком большое число учитываемых признаков чрезмерно усложняет модель, что затрудняет ее построение и дальнейшее практическое использование.
Сокращение размерности модели производится за счет исключения второстепенных, статистически незначимых факторов. Это делает модель менее сложной, однако есть опасность, что при исключении большого количества факторов модель будет недостаточно полно описывать исследуемое явление.
Для отбора наиболее значимых факторных признаков могут использоваться следующие методы:
–метод экспертных оценок на основе расчета и анализа показателей связи исследуемых переменных (например, коэффициентов корреляции);
–метод шаговой регрессии заключается в последовательном включении в модель факторных признаков и анализе их значимости.
При исследовании сложных объектов, на которые влияют большое число взаимосвязанных факторов, может возникнуть такое явление, как мультиколлинеарность – тесная зависимость между факторными признаками модели. В этом случае осложняется процесс определения наиболее существенных факторных признаков.
На возникновение мультиколлинеарности влияют следующие причины:
–факторные признаки характеризуют одну и ту же сторону исследуемого процесса или явления;
36

–в качестве факторных признаков используются показатели, суммарное значение которых представляет собой постоянную величину;
–факторные признаки являются составляющими элементами друг друга;
–факторные признаки по экономическому смыслу дублируют друг друга.
Устранение мультиколлинеарности может выполняться путем исключения из модели линейно–связанных факторных признаков или их преобразования в новые укрупненные факторы.
Последним этапом регрессионного анализа является интерпретация его результатов.
Оценка значимости факторных признаков, входящих в модель, проводится по соответствующим коэффициентам регрессии. Чем больше величина коэффициента регрессии, тем значительнее влияние данного признака на результативный. Направление влияния (прямое или обратное) определяется по знаку коэффициента.
Для более подробной интерпретации уравнения регрессии определяются следующие параметры:
1. Коэффициенты эластичности показывают, на сколько процентов изменится значение результативного признака при изменении факторного признака на 1%, определяются по формуле:
Эi |
ai |
xi |
, |
|
|
y |
|||
|
|
|
|
|
где xi – среднее значение |
i–го |
факторного признака, y – |
||
среднее значение результативного признака, ai – коэффициент
регрессии при i–м факторном признаке.
2. Множественный коэффициент детерминации
характеризует, какая доля вариации результативного признака обусловлена изменением факторных признаков, входящих в многофакторную модель, равен квадрату множественного
коэффициента корреляции r 2 .
37
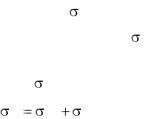
2.4. Дисперсионный анализ
Методы корреляционного и регрессионного анализа позволяют оценить влияние одного или нескольких факторных признаков на результативный в том случае, если исследуются зависимости между количественными или порядковыми переменными, однако провести анализ влияния качественных (классификационных) факторов эти методы не позволяют.
Дисперсионный анализ – это метод статистического анализа, применяемый для исследования влияния на результативную переменную одного или нескольких качественных признаков.
В зависимости от числа рассматриваемых факторных переменных дисперсионный анализ может быть однофакторным и многофакторным.
Однофакторный дисперсионный анализ устанавливает значимость влияния факторного признака на результативный. При этом проверяется гипотеза о равенстве средних значений в нескольких независимых выборках. Если гипотеза не подтверждается, то проверяемый признак существенно влияет на результативный, в противном случае зависимостей не найдено. Для проверки гипотезы обычно используется критерий Фишера.
Общая дисперсия выборки 2 подразделяется на часть,
объясняющую различия между группами |
2 |
(межгрупповая |
A |
дисперсия) и часть, объясняющую различия между единицами
совокупности внутри группы |
z2 (внутригрупповая дисперсия): |
|
2 |
2 |
2 |
|
A |
z . |
Межгрупповая дисперсия объясняет изменчивость значений выборки с разными значениями факторного признака, а внутригрупповая дисперсия объясняет вариацию результативной переменной при одинаковых значениях факторов из–за неучтенных в модели воздействий.
38

Пусть исследуется влияние фактора А на вариацию признака Y, при этом переменная А принимает k значений, называемых уровнями фактора. На каждом уровне получено по m значений признака Y. Тогда вся совокупность из n k  m наблюдений может быть записана в виде табл. 6.
m наблюдений может быть записана в виде табл. 6.
Таблица 6
Уровни фактора А |
Отдельные значения |
|
признака Y |
||
|
|
1 |
|
|
y11, y12,..., y1m |
|
||
|
2 |
|
|
y21, y22 ,..., y2m |
|
||
|
… |
|
|
|
|
… |
|
|
k |
|
|
yk1, yk2,..., ykm |
|
||
С учетом введенных обозначений запишем следующие |
|||||||
соотношения: |
|
|
|
|
|
|
|
2 |
1 |
k |
m |
2 |
|
|
|
|
yij y |
, |
|
||||
|
|
|
|
|
|||
|
|
|
|
|
|
||
|
|
k m i 1 |
|
|
|||
|
|
j 1 |
|
|
|
||
2
A
1
k
k
yi y 2 ,
i 1
2 |
1 |
k |
m |
2 |
|
|
|
|
|||
z |
|
|
|
yij yi |
, |
k m i 1 |
|
||||
|
j 1 |
|
|
||
где y – общее среднее значение результативного признака, y i
– средние значения факторного признака на каждом из уровней.
Для интерпретации результатов можно использовать
коэффициент детерминации, отражающий долю межгрупповой дисперсии в общей:
2 a2 .
Чем ближе значение коэффициента детерминации к 1, тем больше степень влияния исследуемого фактора на
39

результативный признак. Величина 1 |
показывает степень |
влияния неучтенных в модели случайных факторов.
Пример. Проверяется надежность телефонных аппаратов, произведенных 3 разными фирмами. Для этого измеряется время работы до появления первой неисправности. Необходимо проверить значимость влияния производителя на надежность телефона. Исходные данные приведены в табл. 7.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
Производитель |
|
Время работы телефонов до первой |
|
Среднее |
|
|||||||||||||||
|
|
|
неисправности (лет) |
|
|
значение |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Фирма А |
|
|
|
|
2.4 |
|
|
|
2.8 |
3.5 |
|
|
4.2 |
|
3.225 |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Фирма Б |
|
|
|
|
4.5 |
|
|
|
3.8 |
3.4 |
|
|
2.2 |
|
3.475 |
|
||||
|
Фирма В |
|
|
|
|
3.1 |
|
|
|
4.2 |
4.8 |
|
|
3.7 |
|
3.95 |
|
||||
|
Среднее |
|
|
|
|
– |
|
|
|
|
– |
– |
|
|
– |
|
3.55 |
|
|||
|
значение |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
Определим значения общей, межгрупповой и |
||||||||||||||||||||
внутригрупповой дисперсий: |
|
|
|
|
|
|
|
|
|
|
|||||||||||
2 |
|
1 |
|
|
2.4 3.55 |
|
2 |
|
... |
3.7 |
3.55 |
2 |
0.61 , |
|
|||||||
|
|
3 4 |
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
2 |
1 |
3.225 |
3.55 |
2 |
|
|
... |
3.95 |
3.55 |
2 |
0.09 , |
|
|||||||||
|
a |
|
|
|
|
|
|
|
|
||||||||||||
|
3 |
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
2 |
1 |
|
|
2.4 |
3.225 |
2 |
... |
3.7 |
3.95 |
2 |
0.52 . |
|
|||||||||
|
z |
3 4 |
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Определим коэффициент детерминации:
0.09 0.14 .
0.61
По данному коэффициенту можно сделать вывод, что надежность телефона не зависит от производителя.
40