

554
.pdf2.6. Адаптивный нейрон. Алгоритмы адаптации
Рассмотрим нечеткое управление с применением нейронной технологии. Постоянно растущая сложность и разнообразие задач, решение которых возлагается на автоматические системы, в последнее время определяют повышенную потребность в системах управления с более универсальными свойствами. Подходящими для решения большинства задач являются системы, основанные на нечеткой логике и ИНС [16]. Нейронные сети выполняют решения, используя предшествующий опыт, что дает возможность приспособиться к изменениям в системе. Объединение элементов нечеткой логики (фаззификация) и НС позволит исключить недостатки нечеткой логики и НС и проектировать адаптивные нечеткие регуляторы.
По сравнению с традиционными методами анализа и вероятностным подходом нечеткое управление с применением нейронной технологии позволяет проводить анализ задачи и получать результаты с заданной точностью, обеспечивать значительное повышение быстродействия процессов управления при использовании нейро-нечетких контроллеров и создании систем управления для объектов, где нецелесообразно применять методы традиционной математики. Мощь НС как методологии разрешения проблем гарантирует ее успешное использование в нечетких регуляторах.
Нечеткое регулирование с применением нейронной технологии повышает быстродействие, точность и качество регулирования. Позволяет работать с контурами, которыми раньше можно было управлять только вручную, в которых возможно лишь нелинейное регулирование.
Регулирование на основе нечеткой логики с применением ИНС на базе адаптивных нейронов является простым и надежным в реализации. На рис. 2.14 в качестве примера приведен адаптивный нейрон с активационной функцией.
111

Рис. 2.14. Адаптивный фаззификатор
В качестве алгоритма адаптации могут выступать градиентные алгоритмы:
–итерационный алгоритм адаптации Уидроу–Хоффа с переменным шагом;
–модифицированный метод наименьших квадратов;
–метод последовательного обучения и т.д.
Алгоритм адаптации Уидроу–Хоффа
Уидроу и Хофф модифицировали персептронный алгоритм Ф. Розенблатта, дополнительно введясигмоидальную функциюактивации[6].
Их модели «Адлин» (с одним выходным нейроном) и «Мадалин» (много выходных нейронов) получили широкое распространение. Они доказали, что сеть при определенных условиях будет сходиться к любой функции, которую она может представить. Процедура УидроуХоффа разработана применительно к «черному ящику», в котором между входами и выходами существуют только прямые связи. Процедура обучения «Мадалин» состоит в том, что веса внутренних связей между нейронами подстраиваются до тех пор, пока не установится требуемое соотношение между входными и выходными векторами. Процесс состоит из двух чередующих фаз. В первой фазе на входах задается входной вектор, а на выходах – нужный выходной вектор. Затем веса всех связей, соединяющих активные входы и выходы, увеличиваются на малую величину . Во второй фазе на входе формируется тот же входной вектор, однако теперь «черный ящик» решает, какой вектор сформиро-
112
вать на выходе. При этом должно соблюдаться следующее правило: выход активизируется только тогда, когда сумма весов его связей с активными входами положительна. После этого веса всех связей, соединяющих активные входные и выходные элементы, уменьшаются на величину . Если сеть выработала правильный выходной вектор, то эти уменьшения весов в точности компенсируют их увеличение, произведенные в первой фазе, поскольку в обеих фазах активны одни и те же пары вход-выход. Если же сеть выработала не тот выходной вектор, который нужен, то изменение весов, рассчитанных в первой фазе, сохраняется. При реализации алгоритма обучения персептрона «Адалин» появляются отличие от классического персептронного алгоритма в четвертом шаге, где используются непрерывные сигналы вместо бинарных сигналов. Недостатком процедуры Уидроу–Хоффа является требование наличия в «черном ящике» промежуточных слоев, которые бы выделяли из входного вектора иерархию тех его признаков, которые и определяли бы в конечном счете выбор выходного вектора. На практике с целью обучения нейрона его охватывают обратной связью через блок алгоритма адаптации.
Элемент сравнения в цепи обратной связи сравнивает фактический сигнал с выхода сумматора нейрона с желаемым сигналом d (это может быть ошибка регулирования в САР или производная ошибки регулирования). Алгоритм адаптации подстраивает коэффициенты вектора
входных сигналов так, чтобы свести к нулю ошибку d r . Процедурно это организуется сведением к минимуму квадрата ошибки
|
2 d r 2 , |
(2.1) |
|
n |
|
где |
r wi xi . |
(2.2) |
i 1
Для решения данной безусловной оптимизационной задачи используем градиентный метод (дельта-метод). В этом методе следующая
k 1 -итерация для значения i -го весового коэффициента wi находится по формуле
|
|
|
|
|
|
d |
2 |
|
|
w |
k 1 |
w |
k |
|
|
C , |
(2.3) |
||
dw |
|
||||||||
i |
|
i |
|
|
|
|
|
||
|
|
|
|
|
|
i |
|
k |
|
113
где С – положительная константа.
Из (2.1) с учетом (2.2) следует, что
d |
|
|
2 |
|
|
dr |
|
|
|
|
|
|
2 |
|
|
2 xi . |
(2.4) |
||
dwi |
|
|
|||||||
|
|
|
dwi |
|
|
||||
Тогда окончательное выражение для алгоритма адаптации будет иметь вид
wi k 1 wi k 2C k xi k , |
(2.5) |
где 2С – скорость обучения нейрона, определяемая скоростью сходимости итерационного процесса оптимизации.
Суть адаптации нейрона заключается в следующем. На базе адаптивного нейрона создана следящая система, заданием которой является случайная величина, например отклонение напряжения от заданного значения. Задача следящей системы, меняя коэффициенты (синапсы) нейрона, отрабатывать отклонения между выходом сумматора соответствующего нейрона и заданием его следящей системы с помощью итерационной процедуры с переменным шагом (алгоритм адаптации Уид- роу–Хоффа). Алгоритм адаптации подстраивает коэффициенты входной матрицы так, чтобы свести к нулю ошибку ε. Процедурно это организуется сведением к минимуму квадрата ошибки. Воздействие выхода адаптивного нейрона через активационную функцию F парирует текущее отклонение от заданного значения с учетом инерционности системы. В процессе адаптации происходит коррекция синапсов адаптивного нейрона до тех пор, пока желаемый сигнал не станет равным нулю. Это значит, что нейрон, исключая ошибку в статике, полностью адаптировался.
Достоинством алгоритма Уидроу–Хоффа является отсутствие ограничения на вид функции принадлежности (терма) и ее расположение в нормированном интервале, а недостатком – сравнительно низкое быстродействие.
Модифицированный метод наименьших квадратов
Для повышения быстродействия рассмотрим алгоритм адаптации, основанный на модификации метода наименьших квадратов [8]. Данный алгоритм в отличие от алгоритма Уидроу–Хоффа рассчитывает
114
синаптические веса Wkj нейрона за одну итерацию из условия линей-
ных терм-множеств фаззификатора лингвистической переменной (например, отклонение текущего параметра).
Пример 2.3. Вывести формулы расчета синапсов согласно модифицированному методу наименьших квадратов.
1.Выбираем терм-множество из линейных функций принадлежности в нормированном интервале –1…+1.
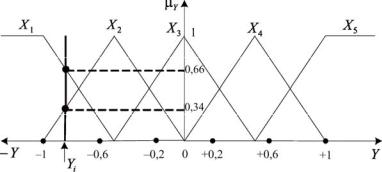
2.Разбиваем нормированный интервал, например, на пять подынтервалов (рис. 2.15):
Y1 |
1; 0,6 , |
Y1 |
0,6; 0,2 , |
Y1 |
0,2; 0,2 , |
Y1 |
0,2; 0,6 , |
Y1 0,6; 1 .
3. Записываем функционал согласно методу наименьших квадратов для данного примера:
F W1 X1 W2 X2 W3 X3 W4 X4 W5 X5 Yi 2 .
Рис. 2.15. К разбиению на подынтервалы нормированного интервала
4. Взяв производную от функции F по каждому синапсу на каждом из 5 интервалов и приравняв их к нулю, получим
F |
2(W X |
W X |
|
W |
0 W |
0 W |
0 Y ) 0, |
|
|
2 |
|||||||
1 |
1 |
2 |
3 |
4 |
5 |
i |
||
W1 |
|
|
|
|
|
|
|
|
115
|
|
F |
|
|
2(W X |
W X |
|
W |
X |
|
|
W 0 W |
0 Y ) 0, |
||||||||||||||||||||||||||
|
|
|
|
2 |
3 |
||||||||||||||||||||||||||||||||||
1 |
|
1 |
|
|
|
2 |
|
|
|
|
3 |
|
|
|
|
|
4 |
|
|
|
|
5 |
|
|
i |
||||||||||||||
|
W2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
F |
|
|
2(W 0 W X |
|
W X |
|
|
W |
X |
|
|
W |
0 Y ) 0, |
||||||||||||||||||||||||
|
|
|
2 |
3 |
4 |
||||||||||||||||||||||||||||||||||
1 |
|
|
|
|
|
|
|
2 |
|
|
|
|
3 |
|
|
|
|
4 |
|
|
|
5 |
|
|
i |
||||||||||||||
|
W3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
F |
|
2(W |
0 W |
|
0 W X |
|
|
|
W X |
|
|
W X |
|
Y ) 0, |
|||||||||||||||||||||||
|
|
|
|
3 |
|
4 |
5 |
||||||||||||||||||||||||||||||||
1 |
|
|
|
|
|
|
2 |
|
|
|
|
|
3 |
|
|
|
|
|
4 |
|
|
5 |
|
i |
|||||||||||||||
|
W4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
F |
2(W |
|
|
0 W |
|
0 W 0 W X |
|
|
W X |
|
Y ) 0, . |
||||||||||||||||||||||||||
|
|
|
|
4 |
|
5 |
|||||||||||||||||||||||||||||||||
1 |
|
|
|
|
|
|
2 |
|
|
|
|
3 |
|
|
|
|
|
|
4 |
|
|
|
|
5 |
|
i |
|||||||||||||
|
|
W5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
5. После преобразований получим |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
F |
W X |
1 |
W |
|
X |
2 |
Y 0 , |
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
W1 |
|
|
|
1 |
|
|
|
|
2 |
|
|
|
|
i |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
F |
|
|
W X |
1 |
W |
X |
2 |
|
W X |
3 |
Y 0 , |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
W2 |
|
|
|
1 |
|
|
|
2 |
|
|
|
|
|
|
3 |
|
|
|
|
i |
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
F |
|
|
W |
X |
2 |
W X |
3 |
|
W |
X |
4 |
Y 0 , |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
W3 |
|
|
|
2 |
|
|
|
3 |
|
|
|
|
|
|
4 |
|
|
|
|
i |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
F |
W X |
3 |
|
W |
X |
4 |
|
W X |
5 |
Y 0 , |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
W4 |
|
|
|
3 |
|
|
|
|
4 |
|
|
|
|
|
5 |
|
|
i |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
F |
W |
X |
4 |
W |
5 |
|
X |
5 |
Y 0 . |
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
W5 |
|
|
|
4 |
|
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
6. Выразим синапсы (весовые коэффициенты) следующим обра-
зом:
W1 Yi W2 X2 , X1
W 2 Yi W1 X 1 W3 X 3 , X 2
W |
Yi W2 X 2 W4 X 4 , |
(2.6) |
3 |
X 3 |
|
|
|
116
W4 |
|
Yi W3 X 3 W5 X 5 |
, |
|||
|
|
|
||||
|
|
|
|
X 4 |
||
|
W |
|
Yi W4 X 4 |
. |
||
|
|
|||||
|
5 |
|
X 5 |
|||
|
|
|
|
|||
Здесь Yi – текущее значение переменной величины, подаваемое на вход
фаззификатора, и в то же время задание следящей системы, которые должны изменяться синхронно.
При первом отсчете начальные значения синапсов задаются случайным образом, а в дальнейшем за исходные принимаются значения синапсов предыдущего отсчета. При этом каждый раз значения синапсов (в зависимости от того, какому интервалу принадлежит желаемый Y) автоматически подстраиваются согласно (2.6) под новые значения. В случае если отклонение вышло за нормированный диапазон, то
W1 Y1 и W5 Y1 .
Модифицированный алгоритм наименьших квадратов применим только для линейных терм, поддиапазоны которых равны и равномерно расположены в нормированном интервале.
Число терм терм-множества фаззификатора всегда должно быть равно числу подынтервалов разбиения нормированного интервала. В случае включения регулятора терм модификация метода наименьших квадратов недопустима. В дальнейшем предлагается метод адаптации с минимальными итерациями или метод с последовательным обучением (рассмотренный выше).
Алгоритм последовательного обучения
Рассмотрим метод адаптации с последовательным обучением [17]. Данный метод относится к методам последовательной идентификации линейных систем в реальном времени, который основан на принципе обучения с моделью и в котором получена модель импульсной характеристики. Аналогично методам стохастической аппроксимации метод последовательного обучения не дает оценки параметров по методу наименьших квадратов на различных последовательных шагах, вследствие чего сходимость этого метода несколько ниже, чем метод последовательной регрессии. При этом оценки постепенно сходятся (в сред-
117
нем) к истинным значениям параметров. Метод последовательного обучения отличается от метода стохастической аппроксимации характеристиками сходимости и его удобно применять для процессов с медленно изменяющимися параметрами. Основное преимущество метода последовательного обучения состоит в простоте алгоритма адаптации.
В методе последовательного обучения рассматривается линейная система со случайным входом u t , выходом x t и импульсной характеристикой g t . Связь между входом и выходом описывается интегра-
лом свертки, который для нулевых начальных условий записывается в виде
|
|
|
x t t |
g u t d , |
|
|
(2.7) |
||
|
|
|
0 |
|
|
|
|
|
|
где u t |
– измеряемая величина. |
|
|
|
|
|
|||
Дискретная форма интеграла свертки |
|
|
|
|
|
||||
|
|
|
|
N |
|
|
|
|
|
|
|
|
xj giu j i . |
|
|
|
(2.8) |
||
|
|
|
|
i 1 |
|
|
|
|
|
Определение импульсной реакции gi |
выполняется путем итераци- |
||||||||
онных |
вычислений |
множества |
величин: |
j |
j |
j |
, |
||
1 |
, 2 |
, ... N |
|||||||
j N 1, |
N 2, ... , которые должны, соответственно, приближаться к |
||||||||
g1 ,..,g N |
в уравнении (2.8), где j обозначает номер итерации. Тогда |
||||||||
оценка выхода модели (нейрона) xjм при использовании i j
N |
j |
u j i . |
(2.9) |
xjм i |
|||
i 1
Обозначая
g g1,...,gN T ,
j 1 j ,..., N j T ,
u j u j 1,...,u j N T ,
118
преобразуем (2.8) и (2.9) соответственно к виду xj gT uj ,
xjм Tj uj .
Определяем разность:
xj xjм g j T u j uTj g j uTj j .
Рассмотрим вектор j 1 j , который будем использовать для
коррекции вектора следующей идентификацией j 1 |
относительно j |
|||||
с учетом ошибки x j xjм в оценкеx j . |
|
|
|
|
||
Полагая j xj xjм |
u j |
, где |
j 1, 2,.... , получим рекуррент- |
|||
T |
||||||
|
u j u j |
|
|
|
|
|
ную формулу |
|
|
|
|
|
|
j 1 j xj xjм |
uj |
. |
(2.10) |
|||
T |
||||||
|
|
|
|
u j uj |
|
|
Чтобы начать процедуру оценивания ошибки согласно (2.10) (при j = 1), можно подставить x jм 0 .
Если в (2.10) ввести коэффициент коррекции ошибки С, то получим окончательное выражение рекуррентной формулы:
j 1 j С xj xjм |
u j |
, при 0 С 2 . |
(2.11) |
T |
|||
|
uj u j |
|
|
Пример 2.4. Рассмотреть применение рекуррентной формулы (2.11) для адаптации искусственного нейрона.
Пусть терм-множество фаззификатора имеет вид, где при текущем отклонении u j 0,4 активизировались термы H и ПС с формирова-
нием степеней принадлежности μПБ 0,4 и μПС 0,6 . Запишем (2.11) в новых обозначениях при условии С = 1:
119
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C j |
μ |
ПБ |
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
j 1 j |
|
|
|
|
μПС |
|
|
|
|
, |
|
|
|
||||||||||||||
|
|
|
|
|
μОБ2 |
μОС2 μПС2 |
μПБ2 |
|
|
|
||||||||||||||||||||||
где u j ( ПБμПБ ПСμПС) . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
Расчет первой итерации: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
|
|
|
μПБ |
|
|
|||
|
|
1 |
|
|
|
|
0 |
|
|
uj ПБ μ |
ПБ |
ПС μ |
ПС |
|
|
|
||||||||||||||||
ПБ |
|
ПБ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
μПС |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
0 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
2 |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
μ |
|
|
μ |
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
ПС |
|
|
|
ПС |
|
|
|
|
|
|
|
|
ПБ |
|
|
|
|
|
|
|
ПС |
|
|
|
|
|
||||
|
|
|
|
|
0, 4 |
0, 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
0 |
|
|
|
|
|
|
0,3077 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
0,6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
0, 4 |
2 |
0,6 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
0 |
|
|
|
|
0, 4615 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
Расчет второй итерации:
|
|
|
|
|
|
|
|
1 |
μПБ |
1 |
|
μ |
|
μПБ |
|
|
|
|
||
|
|
2 |
|
|
1 |
|
|
uj ПБ |
ПС |
ПС |
|
|
|
|
|
|||||
ПБ |
ПБ |
|
|
|
|
|
|
|
|
μПС |
|
|
|
|||||||
|
|
21 |
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
μ |
|
2 |
μПС |
2 |
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
ПС |
|
|
|
ПБ |
|
|
|
|
|
|
|
|||||||||
|
|
|
|
ПС |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
0, 4 0,3077 0, 4 0, 4615 |
|
0, 4 |
|
|||||||||||
|
0,3077 |
|
0,6 |
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
0,6 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
0, 4 |
2 |
0,6 |
2 |
|
|
|
|
|
||||||||
|
0, 4615 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
0,3077 |
|
0 |
0,3077 |
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
||
|
0, |
4615 |
|
0 |
0, 4615 |
|
|
|
|
|
|
|
|
|
|
|
||||
Таким образом, потребовалась одна итерация на данном шаге, вторая итерация приведена только для доказательства, подтверждающая повторяемость результата.
Из анализа рассмотренных алгоритмов предпочтение следует отдать методу с последовательным обучением за его быстродействие и возможность использования как линейных, так и нелинейных терм.
В настоящее время наблюдается интенсивное развитие и практическое применение адаптивных систем для целей управления и регулирования многих технических объектов, в частности авиационного двигателя.
120