

223996
.pdfГрафик, построенный аналогично по накопленным частотам Si называ-
ется кумулятой (рис. 4).
60 |
|
|
|
|
|
50 |
|
|
|
|
|
40 |
|
|
|
|
|
30 |
|
|
|
|
|
20 |
|
|
|
|
|
10 |
|
|
|
|
|
0 |
|
|
|
|
|
0,5-1,0 |
1,0-1,5 |
1,5-2,0 |
2,0-2,5 |
2,5-3,0 |
3,0-3,5 |
Рисунок 4 – Кумулята распределения предприятий по площади посева яровой пшеницы
Для определения числовых характеристик интервального ряда распределения рассчитываются 3-8 колонки таблица 1.2.
Средняя арифметическая определяется по формуле:
|
|
|
xi ni |
|
|
0,75 10 1,25 15 1,75 |
12 |
2,25 |
5 |
2,75 |
6 |
3,25 |
2 |
1,63 тыс. га. |
||||||||
|
x |
|||||||||||||||||||||
|
ni |
|
|
|
|
|
|
|
50 |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
Средняя площадь посева 1,63 тыс. га или 1630 га. |
|
|
|
||||||||||||||||
|
|
|
Мода в интервальных рядах распределения определяется по |
|||||||||||||||||||
формуле: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
Мо |
хо |
|
i |
|
|
nMo |
nMo 1 |
|
|
, |
(8) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(nMo |
nMo 1) (nMo |
nMo 1 ) |
|
|
|||
|
|
|
где хо |
– нижняя граница модального интервала, т.е. интервал, |
которому |
|||||||||||||||||
соответствует наибольшая частота; i |
– величина (шаг) интервала; nMo |
– частота |
||||||||||||||||||||
модального |
интервала; |
nMo 1 |
|
– |
частота |
интервала, |
|
предшествующего |
||||||||||||||
модальному; nMo 1 – частота интервала, последующего за модальным. |
|
|||||||||||||||||||||
|
|
|
В нашем примере мода равна: |
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
Мо |
1 |
0,5 |
|
15 |
10 |
|
|
1,3125 тыс. га или 1315,5 га. |
|
||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
(15 |
10) |
(15 |
12) |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11 |

Значит, в исследуемой совокупности сельскохозяйственных предприятий наиболее часто встречаются предприятия с площадью посевов яровой пшеницы равной 1315,5 га.
Медиана в интервальных рядах распределения определяется по формуле:
|
|
ni |
SMe 1 |
|
|
М у хо i |
|
2 |
, |
(9) |
|
|
|
||||
|
nMe |
||||
|
|
|
|
||
где M e – медиана; x0 – нижняя граница медианного интервала (таковым называется первый интервал, накопленная частота которого превышает половину общей суммы частот); i – величина медианного интервала; SMe 1 –
накопленная частота интервала, предшествующего медианному; nM e –
частота медианного интервала.
В нашем примере медиана равна:
М у |
1,5 0,5 |
25 |
25 |
1,5 |
тыс. га или 1500 га. |
|
|
|
|||||
15 |
||||||
|
|
|
|
|||
Данный показатель говорит о том, что половина предприятий имеют площадь посева яровой пшеницы до 1500 га, а другая половина – свыше 1500 га.
Дисперсия вариационного ряда:
|
xi |
|
2ni |
|
|
|
2 |
x |
|
24,78 |
0,4956 |
||
|
ni |
50 |
||||
|
|
|||||
Среднее квадратическое отклонение: |
|
2 |
|
|
0,4956 |
0,704 . |
||||||
|
|
|
|
|
|
|
|
|
|
|||
Коэффициент вариации: V |
|
|
|
100 |
0,704 |
100 |
43,19 %. |
|||||
|
|
|
1,63 |
|||||||||
x |
||||||||||||
|
|
|
|
|
|
|
|
|
||||
Обобщая полученные статистические характеристики можно сделать следующий вывод. Средняя площадь посева яровой пшеницы на одно предприятие составляет 1630 га. Площадь посева по предприятиям в среднем колеблется в промежутке 1,63 ± 0,704 тыс. гa, т.е. от 926 га до 2334 га. Этот интервал и коэффициент вариации показывают, что имеются большие различия в площади посева яровой пшеницы между предприятиями зоны.
12
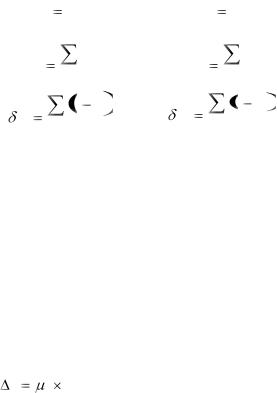
1.2 Выборочное наблюдение
Сбор данных для исследования явлений может быть проведен сплош-
ным и выборочным способом. При сплошном наблюдении обследуются все единицы изучаемой совокупности. При выборочном наблюдении по специ-
ально организованной программе на основе научно-разработанных принципов, обеспечивающих получение объективных обобщающих показателей для характеристики всей совокупности в целом, отбирают часть единиц совокупности. Основные характеристики параметров генеральной совокупности и оценок выборочной совокупности представлены в таблице 4.
Таблица 4 – Основные характеристики параметров генеральной совокупности и оценок выборочной совокупности
Характеристики |
|
Генеральная |
|
|
|
Выборочная |
|||||||||||||||||||
совокупность |
|
совокупность |
|||||||||||||||||||||||
|
|
||||||||||||||||||||||||
Объем совокупности |
|
|
|
|
|
|
N |
|
|
|
|
|
|
n |
|
|
|
||||||||
(численность единиц) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Численность единиц, обладающих |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
обследуемым качеством |
|
|
|
|
|
|
M |
|
|
|
|
|
|
m |
|
|
|
||||||||
(признаком) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Доля единиц, обладающих |
|
|
|
|
|
|
|
|
M |
|
|
|
|
|
|
|
|
m |
|
|
|
||||
обследуемым качеством |
|
|
|
p |
|
|
|
|
|
|
w |
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
N |
|
|
|
|
|
|
n |
|
|
|
||||||||||
(признаком), выборочная доля |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Среднее значение признака |
|
|
|
|
|
|
|
|
x |
|
|
|
|
~ |
|
|
|
|
x |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
||||
|
|
|
|
|
N |
|
|
|
|
|
|
N |
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Дисперсия количественного |
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
x |
~ 2 |
|
|
|
|
|
|
|
|
|
|
x x |
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
x |
||||||||
признака |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
N |
|
|
~ 2 |
|
|
|
|
N |
||||||||
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В процессе проведения выборочного наблюдения возникают ошибки регистрации, связанные с неточностью измерения, счета и ошибки репрезентативности, которые представляют собой расхождения между числовыми характеристиками выборочной и генеральной совокупностей.
Различают среднюю и предельную ошибку выборки, они связаны сле-
дующим соотношением:
x |
x t , |
(10) |
13
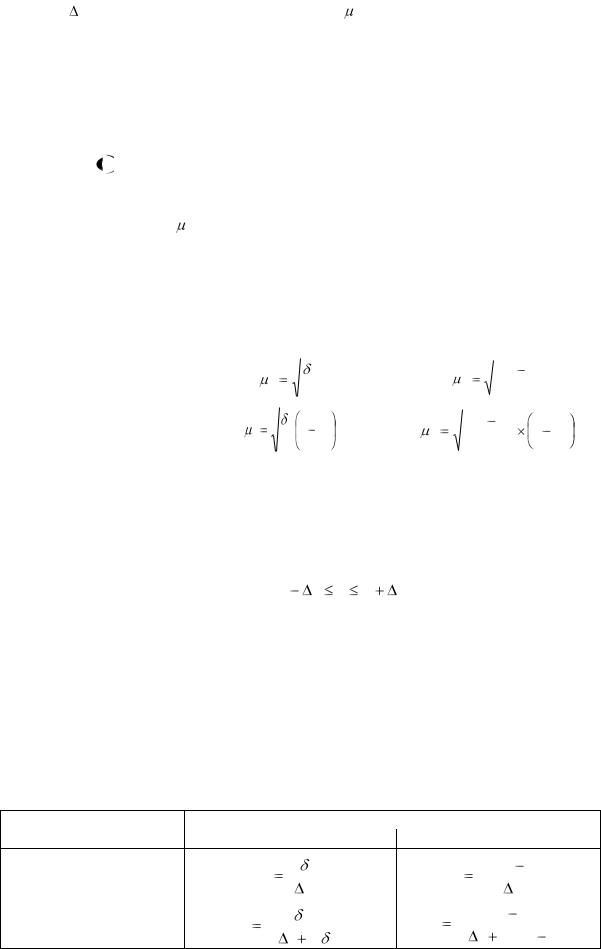
где x – предельная ошибка выборки; x |
– средняя ошибка выборки; t – |
|||||||||||
коэффициент, зависящий от уровня доверительной вероятности F(t). |
||||||||||||
Уровни |
вероятности |
дается |
в |
|
специально |
составленных |
||||||
математических таблицах, и чаще всего используют следующие уровни: |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t |
1,0 |
1,5 |
|
1,96 |
2,0 |
2,5 |
|
2,58 |
3,0 |
3,5 |
|
|
F t |
0,683 |
0,866 |
0,950 |
0,954 |
0,988 |
0,990 |
0,997 |
0,999 |
|
||
|
|
|
|
|
|
|
|
|
|
|
||
Средняя ошибка |
x зависит от способа и вида отбора (табл. 5). |
|||||||||||
Таблица 5 – Формулы расчета средней ошибки выборки при различных способах отбора
Вид отбора |
Вид выборки: собственно-случайная (простая) выборка |
|||||||||||||||||||
для средней |
|
|
для доли |
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
w(1 |
w) |
|
|
|
|
||
Повторный |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
x |
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
||
|
|
|
n |
|
|
|
n |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
w(1 w) |
|
|
n |
||||||||||
Бесповторный |
|
|
|
1 |
|
|
|
1 |
|
|||||||||||
x |
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
||||
|
n |
|
|
N |
|
n |
|
N |
||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Доверительный интервал, который покрывает неизвестное значение средней в генеральной совокупности с заданной доверительной вероятностью, определяется неравенствами:
~ |
|
|
~ |
x . |
(11) |
|
|||||
x |
x x x |
||||
При проведении выборочного исследования важным является обеспе-
чение достаточно большого объема выборки, чтобы достигалась приемлемая точность результатов выборки. Необходимый объем выборки при заданной точности определяется по формулам, представленным в таблице 6.
Таблица 6 – Формулы расчета средней ошибки выборки при различных способах отбора
Вид отбора |
Вид выборки: собственно-случайная (простая) выборка |
||
для средней |
для доли |
||
|
|||
Повторный |
n |
|
t 2 |
2 |
|
n |
|
t 2 w(1 w) |
|
|
||
|
|
2 |
|
2 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|||||
Бесповторный |
n |
|
t 2 2 N |
n |
|
t 2 w(1 w)N |
|
|||||
|
|
|
|
|
|
|
2 t 2 w(1 w) |
|
||||
N |
2 |
t 2 2 |
N |
|
|
|||||||
|
|
|
|
|
||||||||
14
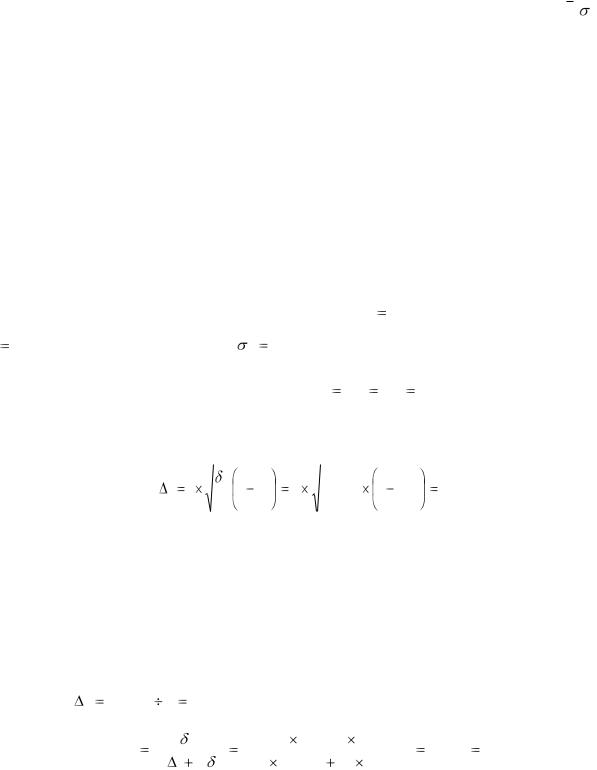
Пример 3. Предположим, что числовые характеристики ( x, 2 )
интервального ряда распределения в примере 2 есть результат случайной
бесповторной выборки. Определите с доверительной вероятностью 0,954:
а) доверительный интервал средней площади посева яровой пшеницы
для всей совокупности предприятий;
б) необходимый объем выборки, если предельная ошибка будет
уменьшена в 2 раза. |
|
|
|
|
|
|
|
|
|
Решение: |
|
|
|
|
|
|
|
|
а) Средняя площадь посева по выборке n |
50 предприятий составила |
||||||
~ |
1,63 тыс. га, при дисперсии |
2 |
0,4956. |
|
|
|
|
|
x |
|
|
|
|
|
|||
|
Объем генеральной совокупности: |
N |
n |
50 |
500. |
|||
|
|
|
|
|||||
|
0,1 |
0,1 |
||||||
|
|
|
|
|
|
|||
Предельная ошибка выборки рассчитывается по формуле:
|
|
|
2 |
|
n |
|
|
|
0,4956 |
|
50 |
|
|
|
t |
|
1 |
2 |
|
1 |
|
0,1889 |
|||||
x |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|||||||||
|
|
n |
N |
|
|
|
50 |
|
500 |
|
|||
|
|
|
|
|
|
|
|
||||||
Т.о. средняя площадь посева озимой пшеницы на одно хозяйство во всей генеральной совокупности при доверительной вероятности 0,954
определяется промежутком 1,63 ±0,189 тыс. га, т.е. покрывается интервалом
от 1441 до 1819 га.
б) Необходимый объем выборки при предельной ошибке, уменьшенной
в два раза ( x 0,1889 2 |
0,094 ) будет равен: |
|
|
|
|
|||||
n |
|
t 2 |
2 N |
|
22 0,4956 |
500 |
|
991,2 |
155 |
|
N |
2 |
t 2 2 |
500 0,0942 22 |
0,4956 |
6,4 |
|||||
|
|
|||||||||
Таким образом, необходимый объем выборки увеличивается до 155
предприятий, т.е. при уменьшении предельной ошибки в 2 раза, объем выборки увеличивается в 3 раза.
15
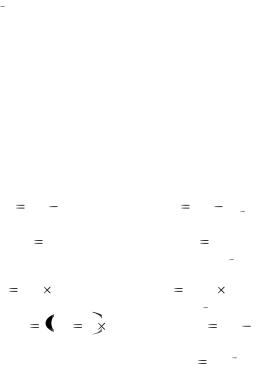
1.3 Ряды динамики
Ряд динамики (динамический ряд, временной ряд) – ряд
расположенных в хронологической последовательности статистических величин, которые отражают развитие изучаемых явлений.
Каждый ряд динамики имеет два основных элемента:
-показатель времени (t);
-уровень развития изучаемого явления ( yt ).
В результате сопоставления уровней динамических рядов вычисляются аналитические производные показатели. Они могут быть определены цепным и базисным способом.
При цепном способе каждый последующий уровень сопоставляется с предыдущим ( yn 1 ), при базисном – с одним и тем же уровнем, принятым за базу сравнения ( y0 ).
Выделяют следующие аналитические производные показатели (табл. 7).
Таблица 7 – Формулы расчета показателей динамики при базисном и цепном способах
|
Наименование показателя |
|
|
|
|
|
|
Вид показателя |
|
|
|
|
|
|
|
|
||||
|
Базисные |
|
|
|
Цепные |
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||
1. |
Абсолютный прирост |
А |
|
yn |
y0 |
|
|
|
А yn |
|
|
|
yn |
1 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
2. |
Коэффициент роста |
К р |
yn |
|
|
|
|
К р |
|
|
|
yn |
|
|
|
|
||||
y0 |
|
|
|
|
|
|
yn 1 |
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
3. |
Темп роста |
Т р |
|
yn |
100% |
|
Т |
|
|
yn |
|
|
|
100% |
|
|||||
|
|
|
|
р |
|
|
|
|
|
|||||||||||
|
|
|
|
y0 |
|
|
|
|
|
|
yn 1 |
|
|
|
||||||
4. |
Темп прироста |
Тпр |
К р 1 |
|
100% или Т пр |
|
|
|
Т р |
100% |
|
|||||||||
5. |
Абсолютное значение 1% |
|
|
|
|
|
|
|
|
|
К1% |
|
|
|
yn 1 |
|
|
|
||
прироста |
|
|
|
|
|
|
|
|
|
100% |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
Для получений обобщающей |
характеристики динамики |
изучаемых |
|||||||||||||||||
явлений рассчитываются средние показатели динамики (табл. 8).
16

Таблица 8 – Формулы расчета средних показателей динамики
Наименование показателя |
|
|
|
|
|
|
|
|
|
|
|
|
Формула |
|
|
|
|
|
|
|
|
|
||||||||||
1. Средний уровень ряда: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
а) по средней арифметической простой, если |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yi |
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
дан интервальный ряд с равностоящими уровнями |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
||||||||||
во времени |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
б) по средней арифметической взвешенной, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yi t |
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
если дан интервальный ряд с не равностоящими |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t |
|
|
|
|
|
|
|
|
|
|||||||||
уровнями |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
в) по средней хронологической, если дан |
|
|
1 |
|
y |
|
|
|
y 2 ... |
|
|
y n 1 |
1 |
|
y n |
|||||||||||||||||
моментный ряд с равностоящими уровнями |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
||||||||||||||
|
|
2 |
|
|
|
|
|
2 |
|
|||||||||||||||||||||||
y |
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t |
1 |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
2. Средний абсолютный прирост |
|
|
|
|
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
yn |
y0 |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
А |
|
|
|
|
|
|
|
или А |
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
n |
1 |
|
|
n |
1 |
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
3. Средний коэффициент роста (темп) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yn |
|
|
|
|
К |
n |
k1 |
|
k2 |
... |
|
kn |
|
или К |
n 1 |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y0 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
4. Средний темп прироста |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т пр |
Т р |
100 |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рассмотрим расчет показателей ряда динамики.
Пример 4. Определить показатели ряда динамики урожайности зерновых культур базисным и цепным способом, а также средние значения.
Расчет показателей ряда динамики сведем в таблицу 9.
Таблица 9 – Урожайность зерновых культур в Иркутской области за период 2006-2010 гг.
Показатель |
|
|
Годы |
|
|
|
2006 |
2007 |
2008 |
2009 |
2010 |
||
|
||||||
Урожайность, ц/га |
16,0 |
18,2 |
20,5 |
21,0 |
22,0 |
|
|
Базисный способ |
|
|
|
||
Абсолютный прирост, ц/га |
- |
2,2 |
4,5 |
5,0 |
6,0 |
|
Коэффициент роста |
- |
1,138 |
1,281 |
1,313 |
1,375 |
|
Темп роста, % |
- |
113,8 |
128,1 |
131,3 |
137,5 |
|
Темп прироста, % |
- |
13,8 |
28,1 |
31,3 |
37,5 |
|
|
Цепной способ |
|
|
|
||
Абсолютный прирост, ц/га |
- |
2,2 |
2,3 |
0,5 |
1,0 |
|
Коэффициент роста |
- |
1,138 |
1,126 |
1,024 |
1,048 |
|
Темп роста, % |
- |
113,8 |
112,6 |
102,4 |
104,8 |
|
Темп прироста, % |
- |
13,8 |
12,6 |
2,4 |
4,8 |
|
Абсолютное значение 1% |
- |
0,16 |
0,18 |
0,21 |
0,21 |
|
прироста |
||||||
|
|
|
|
|
||
Среднегодовая урожайность зерновых культур:
17
|
|
|
yi |
|
16 |
|
18,2 |
|
20,5 |
21 |
|
22 |
|
|
19,54 ц/га. |
||||||||||||||||||||
|
y |
|
|||||||||||||||||||||||||||||||||
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yn |
|
y0 |
|
|
|
22 |
16 |
|
|
|||||
Средний абсолютный прирост: А |
|
|
1,5 |
ц/га. |
|||||||||||||||||||||||||||||||
|
|
|
n |
1 |
|
|
5 |
1 |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yn |
|
|
|
|
|
22 |
|
|
|
|
|||
Средний коэффициент роста: К |
n |
1 |
5 |
1 |
1,083. |
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y0 |
|
16 |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
Средний темп роста: Т з |
|
|
|
К |
100 |
|
1,083 |
100 |
108,3 %. |
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
Средний темп прироста: Т пр |
Т р |
1 |
108,3 |
|
100 |
8,3 %. |
|
||||||||||||||||||||||||||||
За период 2006-2010 гг. урожайность зерновых культур выросла на 6,0
ц/га или на 37,5%, причем среднегодовая урожайность составила 19,54 ц/га.
Наибольший прирост наблюдался в 2007, 2008 гг. Так, в 2007 г. по сравнению с 2006 г. урожайность зерновых культур выросла на 2,2 ц/га или на 13,8%, в 2008 г. по сравнению с 2007 г. – на 2,3 ц/га или на 12,6%. В 2009-
2010 гг. рост урожайности замедлился. В среднем ежегодно урожайность зерновых культур возрастала на 1,5 ц/га или на 8,3%.
4. Проверка статистических гипотез
Статистической гипотезой называется всякое высказывание о гене-
ральной совокупности, проверяемое по выборке. Статистические гипотезы
делятся на:
- параметрические – сформулированные относительно параметров
(среднего значения, доли, дисперсии и др.) распределения известного вида;
- непараметрические – сформулированные относительно вида распределения (например, генеральная совокупность распределяется по нормальному закону).
Выдвинутая гипотеза, называется основной или нулевой ( Н 0 ).
Гипотеза, противоположная нулевой, называется конкурирующей или альтернативной Н1 .
18

Поскольку проверка статистических гипотез осуществляется по выборочным данным, то возникает возможность принятия ошибочных решений. Различают ошибки первого и второго рода.
Ошибка первого рода заключается в том, что будет отвергнута правильная гипотеза. Вероятность ошибки первого рода называется уровнем
значимости и обозначается  Р Н1 Н0 .
Р Н1 Н0 .
Ошибка второго рода состоит в том, что будет принята неправильная
гипотеза. Вероятность ошибки второго рода обозначается  Р Н0 Н1 .
Р Н0 Н1 .
Статистическим критерием (К) называют случайную величину, с
помощью которой принимают решение о принятии или отклонении Н 0 .
Алгоритм проверки статистических гипотез:
1.Исходя из выборочных данных формулируют нулевую и конкурирующую гипотезы.
2.Задают уровень значимости  (обычно принимают
(обычно принимают  0,1; 0,01; 0,05; 0,001).
0,1; 0,01; 0,05; 0,001).
3.Выбирают критерий К, по которому будет проверяться выдвинутая гипотеза. Чаще всего используют следующие распределения критериев: u –
нормальное распределение; 2 – распределение Пирсона (Хи-квадрат); t –
распределение Стьюдента; F – распределение Фишера.
4.Определяют фактически наблюдаемое значение критерия Кф на основании выборочных данных.
5.В зависимости от вида альтернативной гипотезы находят по соответ-
ствующей |
таблице критические значения критерия для двусторонней |
|||
( К |
и К |
) или односторонней критической области ( К1 и К ). Если |
||
1 |
|
|
|
|
|
|
|
|
|
2 |
2 |
|
||
фактически наблюдаемые значения критерия попадают в критическую область, то Н 0 отвергается. В противном случае принимается гипотеза
19

Н 0 и считается, что она не противоречит выборочным данным (при этом существует возможность ошибки с вероятностью разной ).
Пример 5. Два сорта яровой пшеницы испытывались на одинаковом числе участков на протяжении семи лет (табл.10).
При уровне значимости  0,05 проверить нулевую гипотезу о равен-
0,05 проверить нулевую гипотезу о равен-
стве урожайностей двух сортов озимой пшеницы.
Решение. Поскольку имеются две зависимые выборки, т.е. существует определенная корреляция между урожайностью сортов по годам, то необходимо
оценить значимость не разности двух выборочных средних, а средней разности.
Выдвинем нулевую гипотезу – средняя величина различий в урожайно-
сти пшеницы равна нулю, Н0 : х у 0 при Н1 : х у 0 . Проверку гипотезы
Н 0 осуществляют с помощью критерия t-Стьюдента. Для определения
наблюдаемого значения tнабл. |
используем таблицу 10. |
|
|
|
|
|
||||||
Таблица 10 – Вспомогательная таблица для расчета ошибки средней |
||||||||||||
|
|
|
|
разности |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Годы |
Урожайность, ц/га |
Разность |
|
|
|
di |
|
2 |
|
||
|
di d |
|||||||||||
|
d |
|||||||||||
|
yi |
|
xi |
di xi yi |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
||
|
2005 |
17,0 |
|
16,8 |
-0,2 |
-0,8 |
|
0,6 |
|
|
||
|
2006 |
18,5 |
|
18 |
-0,5 |
-1,1 |
|
1,2 |
|
|
||
|
2007 |
20,9 |
|
21,2 |
0,3 |
-0,3 |
|
0,1 |
|
|
||
|
2008 |
21,4 |
|
24 |
2,6 |
2,0 |
|
4,1 |
|
|
||
|
2009 |
22 |
|
23,1 |
1,1 |
0,5 |
|
0,3 |
|
|
||
|
2010 |
23,4 |
|
24,1 |
0,7 |
0,1 |
|
0,0 |
|
|
||
|
2011 |
26,7 |
|
26,8 |
0,1 |
-0,5 |
|
0,2 |
|
|
||
|
Итого: |
149,9 |
|
154,0 |
4,1 |
3,5 |
|
12,4 |
|
|
||
Найдем среднюю разность d и ошибку средней разности Sd :
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
di |
|
|
|
|
|
di |
|
d |
|
|
|
|
|
||
|
|
|
4,1 |
|
; S |
|
|
|
|
3,5 |
0,289 |
; |
|||||
d |
0,586 |
|
|||||||||||||||
|
n |
7 |
d |
|
n n |
1 |
|
7(7 1) |
|||||||||
|
|
|
|
|
|
|
|
|
|
||||||||
20