

Статистическая обработка экспериментальных данных (110
..pdf(3)
где обозначения букв те же, что и в первом случае.
III. Сравнение двух малых групп с попарно-зависимыми вариантами:
(4)
или
, (5)
 . (6)
. (6)
Если разность и
и  обозначить через
обозначить через  , а разность
, а разность  , т.е
, т.е
то формула (5) упростится и примет вид: |
. (7) |
Пример 1. По числу подтягиваний две группы показали следующие результаты:
 = 10,0
= 10,0  = 35
= 35  = ±1,3
= ±1,3
 = 14,5
= 14,5  = 40
= 40  = ±1,5
= ±1,5
Определить достоверность различия этих групп по средним арифметическим.
Решение:
Задача на первый случай, так как группы по объему большие и варианты попарнонезависимы. Следовательно, решать нужно по формулам:
,
31

 .
.
,
k = 35 + 40 - 2 = 73.
По таблице t-критерия Стьюдента определим доверительную вероятность: 0,95< b <0,99. Итак, различие не случайно. Оно достоверно по I порогу доверительной вероятности.
Пример 2. Результаты лыжных гонок на 15 км (в мин):
Решение:
Задача на I случай, так как одна группа большая, вторая — малая, варианты попарно-независимы. Тогда, по формулам (1) и (2) получим:
, |
|
|
|
||||||
k = 29 + 43 - 2 = 70. |
|
||||||||
Вывод: т.к. |
из таблицы t-критерия Стьюдента, то можно |
||||||||
говорить о недостоверности различия выборок уже по I порогу доверительной |
|||||||||
вероятности. |
|
||||||||
Пример 3. Результаты бега на коньках у мужчин на 500 м (с): |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
X m |
|
44.2 0.9;Y m |
|
|
47.0 1.2;nx 25;ny 20. |
|||
|
x |
y |
|||||||
Найти оценку достоверности различия этих групп.
Решение:
Это задача на II случай, так как обе группы малы и варианты попарно-независимы. Следовательно, решать нужно по формулам:
,
 .
.
Для этого нужно определить  из формул:
из формул:
32
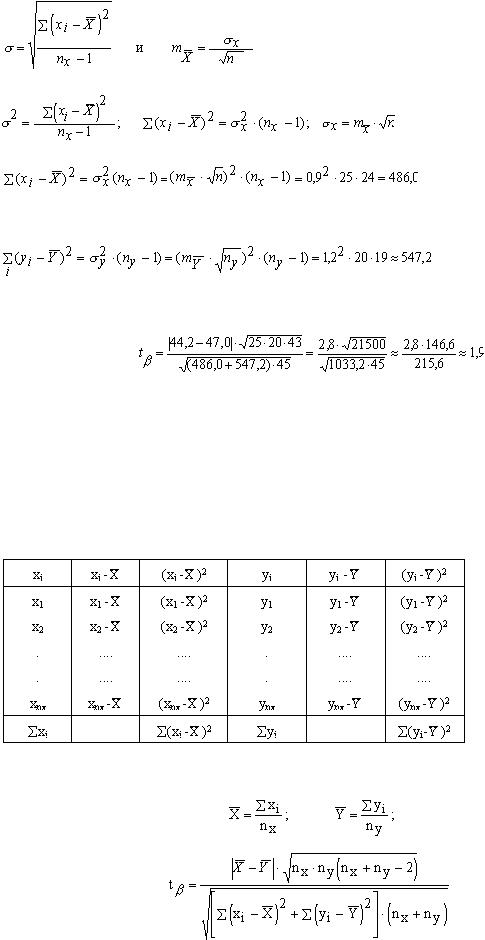
,
.
Аналогично
Тогда:
k = 25+20-2=43.
Вывод:  из таблицы t-критерия Стьюдента, то можно говорить о недостоверности различия выборок уже по I порогу доверительной вероятности.
из таблицы t-критерия Стьюдента, то можно говорить о недостоверности различия выборок уже по I порогу доверительной вероятности.
Замечание.
Если задача на II случай, то данные выборки следует записывать в рабочую таблицу следующего вида:
Найденные суммы подставляют в соответствующие формулы:
.
33
Приведенная рабочая форма применяется и в I случае, если выборки даны своими вариантами, а  ,
,  ,
,  и
и  — неизвестны.
— неизвестны.
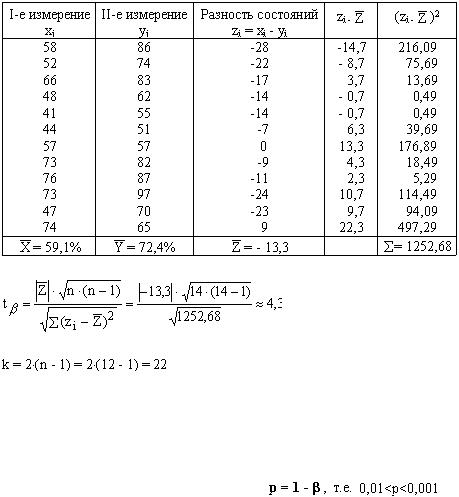
Пример 4. До начала и после подготовительного этапа тренировочного цикла в команде баскетболистов фиксировалась результативность выполнения бросков в %. Определить значимость различных состояний команды.
Решение:
Задача на третий случай, так как сравниваются два различных состояния одной и той же выборки. Решать следует по формулам (5), (6) или (5), (7).
Данные занесем в рабочую таблицу вида:
По таблице t-критерия определим, что различие достоверно (причем,  ) по II порогу доверительной вероятности.
) по II порогу доверительной вероятности.
Команда баскетболистов в результате проведенного цикла тренировок показала результаты значительно выше прежних.
Значимость определяется по формуле:
Пример 5. Целью педагогического эксперимента, проводимого на базе двух средних школ города, была проверка эффективности новой программы обучения, обеспечивающей предположительно более рациональное распределение времени на выполнение задания.
В эксперименте участвовали две группы испытуемых (контрольная и экспериментальная) численностью по 10 человек каждая. В качестве одного из тестов для оценки уровня подготовленности использовалось контрольное упражнение на время его выполнения (мин). Ниже приведены результаты выполнения контрольного задания в обеих группах в начале педагогического эксперимента.
Контр. гр. |
11 |
12 |
9 |
10 |
12 |
14 |
10 |
13 |
11 |
12 |
34

Экспер. гр. 10 13 8 9 |
13 10 11 12 14 11 |
С помощью t– критерия Стьюдента проверить на уровне значимости α = 0,05 следующую гипотезу:.до проведения эксперимента обе группы по исследуемому признаку однородны (средние результаты в указанном тесте для обеих групп не имеют статистически значимого различия).
Решение.
1. Обозначим множество значений для контрольной группы – Х, для экспериментальной – У. Для каждой выборки вычислим среднее значение и стандартное отклонение:
X11,4;Y 11,1; x 1.5; y 1.9.
2.Сформулируем нулевую гипотезу Но: Х Y , то есть средние значения для обеих групп не имеют статистически значимого различия.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3. Вычислим t-расчетное по формуле t расч. |
|
|
|
|
X Y |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
||
x |
2 |
|
|
y |
2 |
|
|
||||||
|
|
|
|
|
|
||||||||
|
|
|
n1 |
|
n2 |
|
|
|
|||||
n1=n2=10, tрасч=0,06.
4.По таблице «Критические значения t-критерия Стьюдента» находим tтеор. при заданном уровне значимости =0,05 и числе степеней ν = n1+n2-2=18: tтеор.= 2,101.
5.Сравним полученные значения: tрасч=0,06 < tтеор.= 2,101, гипотеза Но принимается с вероятностью 95%, то есть группы по исследуемому признаку являются однородными.
7.Справочная информация по технологии работы в среде Microsoft Excel
7.1. Построение диаграмм
Задача. Имеются данные изменения жирового компонента в составе тела у спортсменов. Построить диаграмму
Рис 14. Пример данных для диаграммы Шаг 1. Выделите интервал ячеек, содержащих данные для построения диаграммы
(диапазон A3:D6) с помощью указателя «белый крестик». При выделении данных желательно выделять и текст для подписей.
35

Рис 15. Вид окна после выделения данных.
Шаг 2. Щелкните по кнопке Мастер диаграмм  или выберите пункт меню Вставка, Диаграмма. Откроется диалоговое окно первого шага процедуры построения диаграммы. Мастер диаграмм первого шага содержит 14 стандартных и 20 нестандартных типов диаграмм. Выберите тип диаграммы, которую вы собираетесь построить. Например, Гистограмма и щелкните по кнопке Далее.
или выберите пункт меню Вставка, Диаграмма. Откроется диалоговое окно первого шага процедуры построения диаграммы. Мастер диаграмм первого шага содержит 14 стандартных и 20 нестандартных типов диаграмм. Выберите тип диаграммы, которую вы собираетесь построить. Например, Гистограмма и щелкните по кнопке Далее.
Рис 16. Первый шаг Мастера диаграмм: выбор типа диаграммы.
Шаг 3. На экране откроется диалоговое окно второго шага процедуры Мастера диаграмм. Если вы хотите построить диаграммы на основе другого интервала данных, введите его. Т.к. данные были выделены до вызова Мастера диаграмм, поле Диапазон уже содержит ссылку на выбранный интервал. Окно можно переместить, если навести указатель мыши на зону заголовка и удерживать левую кнопку мыши.
36
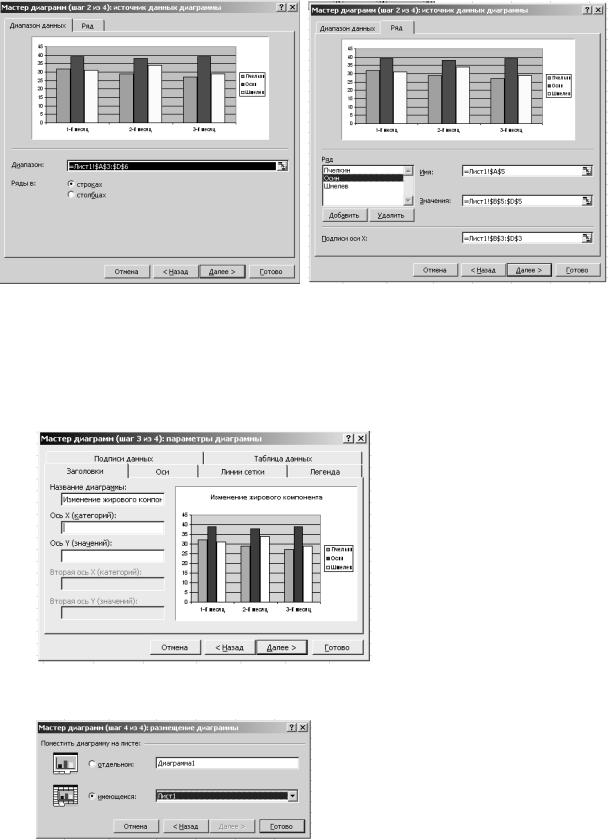
Рис 17. Второй шаг Мастера диаграмм: выбор диапазона данных.
Вы можете внести изменения в подписи данных, используя вкладку Ряд. Выбрав ряд в окне Ряд в окне Имя введите его имя или щелкните по ячейке, содержащей нужное название. В окне Подписи оси Х можно указать диапазон ячеек, содержащих необходимые подписи. После необходимого редактирования щелкните кнопку Далее.
Шаг 4. На третьем шаге работы с Мастером диаграмм нужно ввести необходимые дополнительные обозначения: название диаграммы, названия осей, подписи данных, расположение легенды.
Рис 18. Третий шаг Мастера диаграмм: указание параметров диаграммы.
Шаг 5. На данном шаге необходимо выбрать место размещения диаграммы: в имеющемся листе, или на отдельном.
Рис 19. Четвертый шаг Мастера диаграмм: выбор размещения диаграммы.
Для завершения работы выберите кнопку Готово. Результат работы отражен на рис.
7.
37
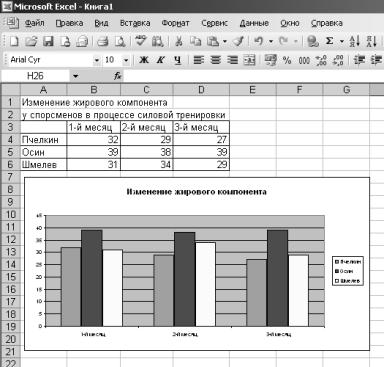
Рис 20. Пример рабочего листа с внедренной диаграммой.
Внедренная диаграмма может быть расположена в любом месте листа – поверх других данных или графиков. Для редактирования диаграммы нужно ее выделить щелчком левой клавиши мыши и выбрать кнопку Мастер диаграмм на панели инструментов. Для удаления диаграммы нужно ее выделить и нажать клавишу Del.
Для построения диаграммы по данным, находящимся в несмежных ячейках необходимо удерживать клавишу Ctrl при выделении второго и следующих диапазонов.
7.2.Статистические функции
Всостав Excel входит библиотека, содержащая 78 статистических функций. Часть этих функций входит в виде составляющих в Пакет анализа, часть является уникальными функциями, не дублирующимися в надстройке. Для работы необходимо вызвать мастер функций с помощью пункта Вставка, Функция… или щелчком по кнопке вызова мастера
функций на панели инструментов, или с помощью комбинации клавиш Shift+F3. В окне Категория выбрать Статистические, в окне Функция – указать нужную функцию. Названия функций расположены в алфавитном порядке. В нижней части окна выводится пример, иллюстрирующий способ задания функции и краткая информация о ней.
Функция СРЗНАЧ
Синтаксис: СРЗНАЧ(число1; число 2; …)
Результат: рассчитывает среднюю арифметическую значений, заданн ых в списке аргументов.
Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Среднее арифметическое рассчитывается по формуле:
|
|
x1 x2 ... xn |
|
x |
xi |
|
X |
или |
|||||
n |
n |
|||||
|
|
|
|
|||
Функция МЕДИАНА
Синтаксис: МЕДИАНА(число1; число 2; …)
38

Результат: рассчитывает медиану значений, заданных в списке аргументов (Медианой
(Me) называется значение признака, приходящееся на середину ранжированной совокупности)
Функция МЕДИАНА не требует предварительной ранжировки.
Функция МОДА
Синтаксис: МОДА(число1; число 2; …)
Результат: отображает наиболее часто встречающееся значение в интервале данных. Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Если множество не содержит одинаковых данных, то функция МОДА помещает в ячейку значение ошибки #H/Д.
Функция СТАНДОТКЛОН
Синтаксис: СТАНДОТКЛОН(число1; число 2; …)
Результат: оценивает генеральное стандартное отклонение по выборке.
Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Функция СТАНДОТКЛОН рассчитывает генеральное стандартное отклонение при условии, что исходные данные образуют выборочную совокупность. Если совокупность является генеральной, следует использовать функцию СТАНДОТКЛОНП.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Формула для расчета: x |
|
(x x)2 |
(x |
2 |
x)2 ... (x |
n |
x)2 |
||||||
1 |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
n |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
Функция ДИСП
Синтаксис: ДИСП(число1; число 2; …)
Результат: оценивает генеральную дисперсию по выборке.
Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Функция ДИСП рассчитывает генеральное стандартное отклонение при условии, что исходные данные образуют выборочную совокупность. Если совокупность является генеральной, следует использовать функцию ДИСПР.
Функция ЭКСЦЕСС
Синтаксис: ЭКСЦЕСС(число1; число 2; …) Результат: оценивает эксцесс по выборке.
Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Если задано менее четырех точек данных или если стандартное отклонение равно нулю, то функция ЭКСЦЕСС помещает в ячейку значение ошибки #ДЕЛ/0!
Эксцесс характеризует так называемую «крутость», т.е. островершинность или плосковершинность распределения. Если эксцесс E>0, то распределение островершинное, если E<0, то плосковершинное.
Функция СКОС
Синтаксис: СКОС(число1; число 2; …)
Результат: оценивает коэффициент ассиметрии по выборке.
39
Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Если задано менее трех точек данных или если стандартное отклонение равно нулю, то функция СКОС помещает в ячейку значение ошибки #ДЕЛ/0!
Данный показатель дает возможность определить величину ассиметрии в генеральной совокупности. Если эксцесс А>0, то ассиметрия правосторонняя (положительная), если E<0, то левосторонняя.
Функция МИН (МАКС)
Синтаксис: МИН(число1; число 2; …), МАКС(число1; число 2; …) Результат: находит наименьшее (наибольшее) значение в множестве данных.
Аргументы: число1; число 2; …от 1 до 30 аргументов. Аргументы должны быть числами, или именами, массивами или ссылками, содержащими числа. Пустые ячейки игнорируются при расчетах, ячейки с нулевыми значениями учитываются.
Функция СЧЕТ
Синтаксис: СЧЕТ(значение 1; значение 2; …)
Результат: рассчитывает количество чисел в списке аргументов.
Функция НАИБОЛЬШИЙ
Синтаксис: НАИБОЛЬШИЙ(массив; k)
Результат: Находит k-е по порядку (начиная с xmax) наибольшее значение в множестве данных.
Функция НАИМЕНЬШИЙ
Синтаксис: НАИМЕНЬШИЙ(массив; k)
Результат: Находит k-е по порядку (начиная с xmin) наименьшее значение в множестве данных.
7.3. Установка надстройки «Пакет анализа»
Установка надстройки «Пакет анализа» осуществляется с помощью меню Сервис. Возможные ситуации:
В меню Сервис присутствует команда Анализ данных… В этом случае достаточно выбрать данную команду
В меню Сервис нет команды Анализ данных… В этом случае необходимо в том же меню выполнить команду Надстройки… И в списке доступных надстроек поставить «галку» рядом с элементом Пакет анализа. После этого в меню Сервис появится команда Анализ данных…
В меню Сервис нет команды Анализ данных, а списке окна Надстройки нет
элемента Пакет |
анализа. В этом случае необходимо доустановить Excel с |
дистрибутивного |
компакт-диска Microsoft Office. |
7.4. Технология работы в режиме «Анализ данных»
Выбрать в меню Сервис пункт Анализ данных…, появится окно с таким же названием. Это окно – центр управления надстройки Пакет анализа, главным элементом которого является область Инструменты анализа:
Гистограмма
Выборка
Описательная статистика Ранг и персентиль
40